Python算法笔记(2)-初识数据结构-数组、链表、栈、队列、哈希表

1.数组
什么是数组
数组是一种数据结构,用来存储多个相同类型的数据,数组中元素是有序,通过下标来进行访问,数组元素中具有相同数据类型,可以由不同的下标和统一数组名来确定数组的唯一元素。
数组怎么用
一般数组形式为:dataType arrayName[length];
其中datatype是数据类型比如,int、float这些数据类型
arrayname则是数组的名称
length是数组的长度
比如int abc[4]就是定义了一个数组名为abc,长度为4的整形数组
也可以给数组赋值例如abc[0] = 123,就是给abc中第一个元素赋值为123
也可以同时给数组内所有元素赋值int abc[2] = {0,1,2}
如果数组的元素个数少于数组长度会自动赋值和初始化。
1.读取数组
abc = [1,2,3,4,5]
读取元素
abc = [1,2,3,4]
print(abc[3])
更新元素
abc = [1,2,3,4]
abc[3] = 120
print(abc[3])

2.插入元素
尾部插入
abc = [1,2,3,4]
abc.append(150)
print(abc)

中间插入
abc = [1,2,3,4]
abc.insert(2,120)
print(abc)

超范围插入
当数组超过插入范围时,这时候如果继续往数组内插入元素,会出现数组越界,为了能让数组在超过范围内进行插入就叫做超范围插入,但在python中这样不会出现数组异常,因为python会将超范围的数组在尾部进行插入
当只有4个元素,向其中插入第五个元素


当只有4个元素,向其中第99插入第五个元素
abc= [1,2,3,4]
abc.insert(100,120)
print(abc)

删除元素
abc= [1,2,3,4]
abc.remove(4)
print(abc)

数组的优点和缺点
| 优点 | 缺点 |
|---|---|
| 1.按照索引查询速度快,可以实现随机访问 | 根据内容查找元素速度慢,需要遍历整个数组 |
| 2.能够储存大量数据,占用空间小 | 数组大小无法改变,会造成空间浪费 |
| 3.可以根据索引快速遍历引用,可以用循环语句 | 数组只能存储一种类型的数据,无法去适应各种类型数据的存储需求 |
| 4.数组定义简单,访问方便 | 增加和删除元素效率低,需要移动很多数据 |
2.链表
什么是链表
链表是一种数据结构,它由一系列的结点组成,每个结点包含一个数据域和一个指针域。数据域存储数据元素,指针域存储下一个结点的地址。链表的优点是可以动态地增加或删除结点,不需要连续的内存空间。链表的缺点是访问数据时需要从头结点开始遍历,效率较低
链表怎么用
下面以这四种为内容,分别简要介绍
class mylist:
def __init__(self,data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.size = 0
self.head = None
self.last = None
def get(self,index):
if index < 0 or index >= self.size:
raise Exception("超出链表范围")
p = self.head
for i in range(index):
p = p.next
return p
def insert(self,data,index):#插入节点
nodelist = mylist(data)
if self.size ==0:
# 空链
self.head =nodelist
self.last = nodelist
elif index == 0:
## 插入头部节点
nodelist.next = self.head
self.head = nodelist.next
def remove(self,index):#删除节点
if index == 0:
#删除头节点
remove_node = self.head
self.head = self.head.next
if self.size == 1:
self.last == mylist
elif index == self.size -1:
#删除尾节点
re_node = self.get(index-1)
remove_node = re_node.next
re_node.next = None
self.last = re_node
else:
#删除中间节点
re_node = self.get(index-1)
ne_node = re_node.next.next
remove_node = re_node.next
re_node.next = ne_node
self.size -=1
return remove_node
def find(self,data):#查找节点
node = self.head
while node:
if node.data ==data:
return node
else:
node = node.next
return None
def append(self, data):#添加一下新节点
new_nodelist = mylist(data)
if self.head is None:
self.head = new_nodelist
else:
bte = self.head
while bte.next:
bte = bte.next
bte.next = new_nodelist
def out(self):
p = self.head
while p is not None:
print(p.data)
p = p.next
linklist = LinkedList()
linklist.insert(100,0)
linklist.insert(2,1)
linklist.insert(3,2)
linklist.append(5)
linklist.remove(0)
linklist.out()
te=linklist.find(5)
print(te.data)
链表和数组对比
数组的优势在于快速定位元素,对于读操作多和写操作少的场景适合
链表能够灵活插入和删除,对于频繁插入和删除的用链表更好
3.栈和队列
什么是物理结构和逻辑结构
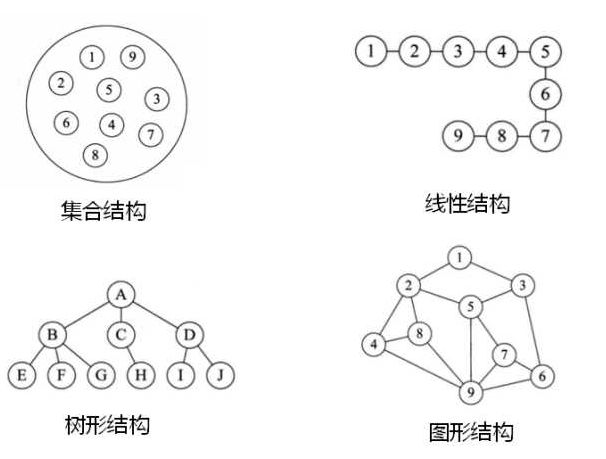
逻辑结构:数据与数据直接的关系,常见的有:集合结构、线性结构、树形结构、图形结构
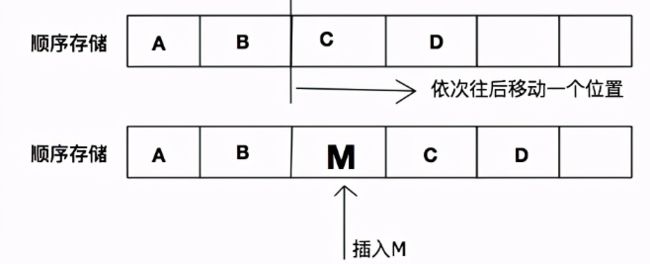
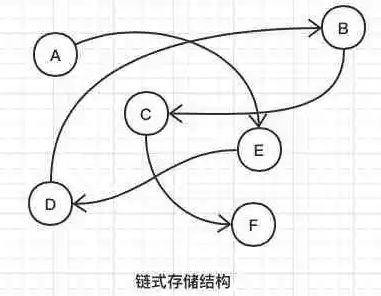
物理结构:一种是顺序存储结构、一种是链式存储结构
什么是栈
栈是一种线性结构,里面的元素只能先入后出最早进入的元素在栈底,最后进入的元素在栈顶
栈怎么用
入栈
入栈就是把新的元素放入栈中,新的元素称为栈顶
出栈
出栈就是把元素从栈中退出来,出栈的元素的前一个元素成为栈顶
什么是队列
队列是一种线性的数据结构,队列中的元素只能先进先出,队列的出口端叫做队头,入口端叫做队尾。
队列的基本操作
入队
入队就是把新元素放入队列中,只允许在队尾的位置放入元素,新元素的下一个位置就会成为新的队尾
出队
出队就是把元素移除队列,只允许队头的一侧移出元素,出队的元素最后一个元素就会成为新的队头。
栈和队列的使用方法
#使用collection.deque实现队列
from collections import deque
queue = deque() #创建一个空队列
#往队列里面添加元素
queue.append("1")
queue.append("2")
queue.append("3")
print(len(queue))#打印队列长度
print(queue)
#队列中移除元素
element = queue.popleft()
print(element)
print(queue)

4.哈希表
什么是哈希
哈希表通过key和值的映射即可快速找到相应的数据。哈希表也叫散列表,是储存key-value的映射集合,对于某个key,哈希表可以在接近O(1)内进行读写操作,哈希表通过哈希函数实现key和数组下标的转换,通过开放寻址法dict和链表法来解决哈希冲突。
什么是哈希函数
哈希把表对应的集合叫做字典,假设目前有一个很大的数据集在[1,2,3]中,如果每个都要按照最大值去开辟空间,那么就会造成空间浪费,所以我们需要将元素和数据的索引建立一个映射关系,这就是哈希函数。
什么是哈希冲突
由于数据越来越多,不同的key和数组下标,通过哈希函数获得下标有可能是相同的,所以造成数组下标变成同样的值,这也叫做哈希冲突。哈希冲突的处理方法主要有开放寻址法和链表法。
哈希表的使用方法
#创建一个空的哈希表
hashtable =dict()
hashtable["name"]="zhangsan"
hashtable["age"]=29
hashtable["gender"]="male"
hashtable["company"]="txxt"
#打印哈希表长度和内容
print(len(hashtable))
print(hashtable)
#读取哈希表中对应键值对的值
value = hashtable["name"]
print(value)
#删除键值对
del hashtable["company"]
print(hashtable)

使用开放寻址法实现哈希表
#定义一个哈希表
class hashtable:
def __init__(self):
self.size = 5
self.table = [None]*self.size
#定义一个哈希函数将字符串转化为整数
def hash_changed(self,key):
return sum(ord(c)for c in key)% self.size
#定义元素插入
def insert(self, key, value):
#计算哈希值
hash_cal = self.hash_changed(key)
if self.table[hash_cal] is None:#如果该位置为空则插入元素
self.table[hash_cal]=(key,value)
else:#反之出现哈希冲突
i = 1
while True:
#出现哈希冲突重新计算位置
newhashcal = (hash_cal+i)%self.size
#如果不再出现冲突,则插入元素
if self.table[newhashcal] is None:
self.table[newhashcal] =(key,value)
break
else:
i+=1
#创建一个哈希表对象
hash_table = hashtable()
# 向哈希表中插入元素
hash_table.insert("name", "zhangsan")
hash_table.insert("age", 29)
hash_table.insert("comany", "kkiu")
hash_table.insert("incom", "8000")
hash_table.insert("like", "play basketball")
# 打印哈希表的内容
print(hash_table.table)
