ggplot2包可视化——折线图
参考文献:
张杰.R 语言数据可视化之美:专业图表绘制指南:增强版 —北京:电子工业出版社,2019
Winston chang.R数据可视化手册—北京:人民邮电出版社,2014
一.简单折线图
折线图通常用来对两个连续变量之间的相互依存关系进行可视化,其中,x轴对应于自变量,y轴对应于因变量。一般来说,折线图的x轴对应的是时间变量,但也可以用来表示诸如实验对象的药剂量等连续型变量。而在ggplot2中,我们可以使用geom_line()函数绘制,下面是绘制简单折线图的一个案例
library(ggplot2)
#BOD数据集
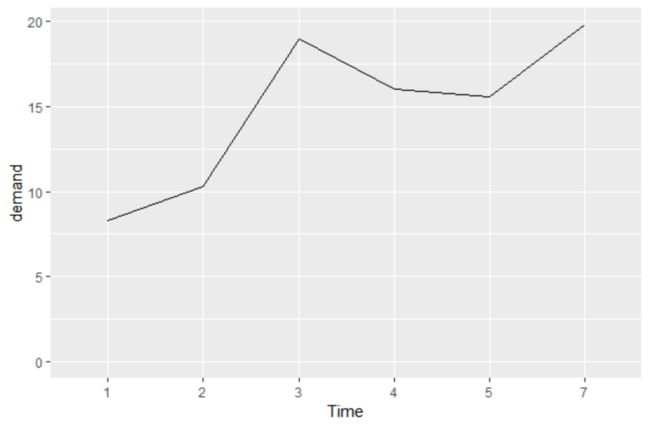
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8
BOD$Time<-factor(BOD$Time) #将time转为因子变量
ggplot(BOD,aes(x=Time,y=demand,group=1))+geom_line()+ylim(0,max(BOD$demand))注:当x对应于因子型变量时,必须使用命令aes(group=1)以确保ggplot()知道这些数据点属于同一个分组,从而应该用一条折线连在一起。而ylim则可以限制y轴的取值范围,使数据表示更加直观。
如果需要在折线图中添加数据标记(点)时,可以使用geom_point()函数。
下面介绍几种不同的折线图绘制。
二.多重折线图
#ToothGrowth数据集
len supp dose
1 4.2 VC 0.5
2 11.5 VC 0.5
3 7.3 VC 0.5
4 5.8 VC 0.5
5 6.4 VC 0.5
…
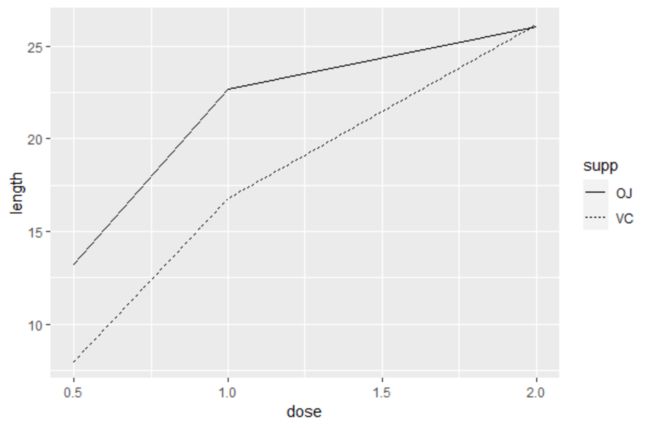
library(plyr)
tg<-ddply(ToothGrowth,c("supp","dose"),summarise,length=mean(len))
ggplot(tg,aes(x=dose,y=length,linetype=supp))+geom_line()例子中的数据集是supp(维C)的dose(剂量)对牙齿生长的实验,因为数据本身并不容易画折线图,因此这里使用plyr包中的ddply()函数进行数据处理,具体是以dose和supp两个变量为分类依据,对满足不同len的一些数值进行平均处理,最后生成新的一列length。最后画图,结果如下:
若要讲does这个变量转为因子,那必须要加入group=supp语句,这时输出的图像如下
ggplot(tg,aes(x=factor(dose),y=length,colour=supp,group=supp))+geom_line()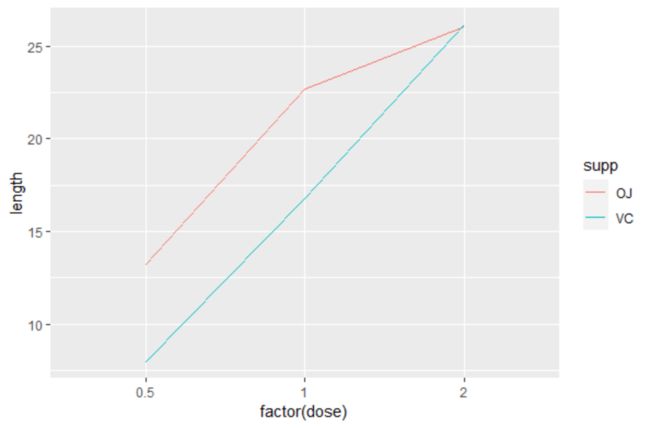
如果折线图上有数据标记,可以将分组变量映射在标记属性上,如shape=supp就是不同组对应不同的数据点形(如一个圆形一个菱形),fill就是对应不同颜色的线型。
有时候数据标记有可能会相互重叠,需要彼此错开,用此例举个例子
ggplot(tg,aes(x=dose,y=length,shape=supp))+
geom_line(position = position_dodge(0.2))+ #将连接线左右移动0.2
geom_point(position = position_dodge(0.2),size=4) #将点的位置移动0.2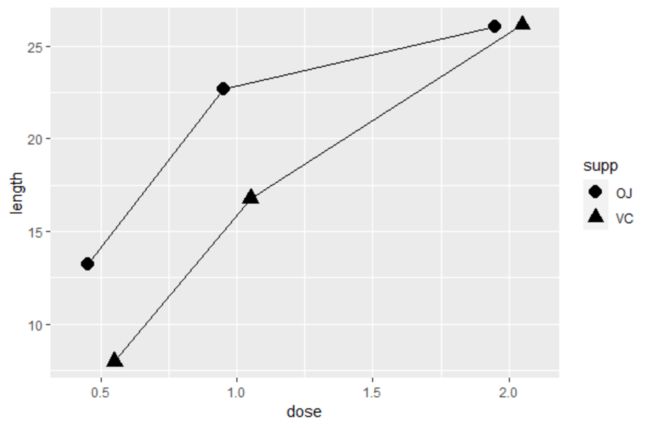
三.面积图
使用geom_area()函数可绘制面积图,以下面的例子为例:
sunspotyear<-data.frame(
Year = as.numeric(time(sunspot.year)), #提取时间,作为第一列
Sunspots = as.numeric(sunspot.year)) #提取数据的值
#展示sunspotyear数据
Year Sunspots
1 1700 5
2 1701 11
3 1702 16
…
288 1987 29.2
289 1988 100.2
ggplot(sunspotyear,aes(x=Year,y=Sunspots))+
geom_area(fill ="blue",alpha=0.2)+geom_line()其中geom_area()函数中的参数fill表示面积填充的颜色,alpha=0.2表示将面积图的透明度设定为80%,geom_line()为空表示仅绘制轨迹线,不绘制边框线,最后输出结果如下:
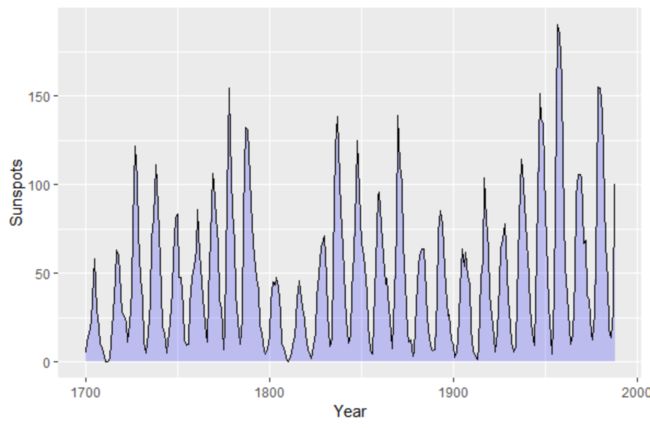
四.堆积面积图
同样使用geom_area()函数,不过此时需要加入参数fill映射一个因子型变量即可
library(gcookbook)
ggplot(uspopage,aes(x=Year,y=Thousands,fill=AgeGroup))+geom_area()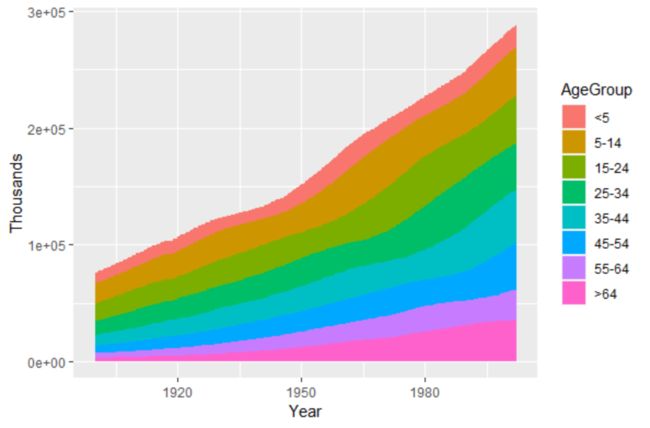
在默认情况下,图例的堆积顺序与面积图的堆积顺序是相反的,可通过设定标度中的切分(breaks)参数可翻转堆积顺序,下面进行这一调整,并在各个区域之间添加细线(size=0.2),填充区域设定为半透明(alpha=0.4)
ggplot(uspopage,aes(x=Year,y=Thousands,fill=AgeGroup))+
geom_area(colour="black", size=.2, alpha=.4) +
scale_fill_brewer(palette="Blues", breaks=rev(levels(uspopage$AgeGroup)))
而若要反转堆积面积图的堆积顺序时,可在aes()函数内部设定order=desc()指令,这里就可以放入AgeGroup。
若想绘制百分比堆积面积图,可用ddply()函数,产生一列新列,便于绘图
library(plyr)
uspopage_prop<-ddply(uspopage,"Year",
transform,Percent=Thousands/sum(Thousands)*100)
ggplot(uspopage_prop,aes(x=Year,y=Percent,fill=AgeGroup))+
geom_area(colour="black", size=0.2, alpha=0.4) +
scale_fill_brewer(palette="Blues", breaks=rev(levels(uspopage$AgeGroup)))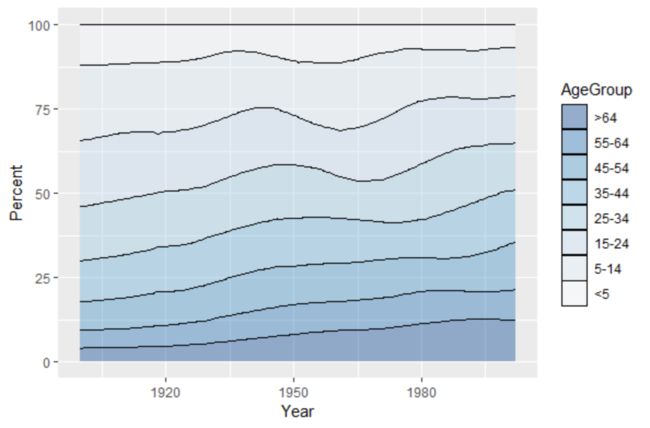
这里是调用ddply()函数,按照变量Year 将数据集拆分为多个独立的数据框,对所有数据框执行transform()函数并计算每个数据框对应的Percent 。最后再将所有数据框重组在一起,对于不同的问题,还需要具体分析。
五.图形调整
1.修改线条样式
设置线型(linetype)、线宽(size)、颜色(colour)等参数时,将对应参数的值传递给geom_line()函数就可对应的修改
例如想得到一个线宽为1的蓝色虚线图,就可使用以下代码:
ggplot(BOD,aes(x=Time,y=demand))+geom_line(linetype="dashed",size=1,colour="blue")2.修改数据标记样式
而修改数据标记的样式时,可在geom_point()函数之下进行,如下例所示:
ggplot(BOD,aes(x=Time,y=demand))+geom_line()+
geom_point(shape=22,size=4,colour="darkred",fill="white")在shape参数中可选择不同的点形,点形种类如下所示:

3.添加置信区域
使用geom_ribbon()函数,然后分别映射一个变量给ymin和ymax
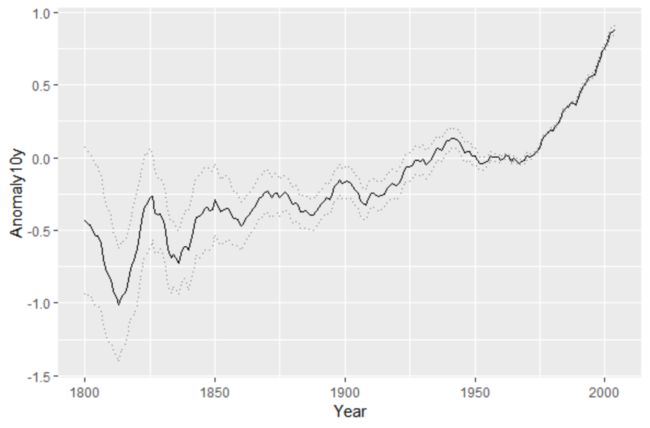
climate
数据集中的Anomaly10y 变量表示了各年温度相对于1950—1980平均水平变异(以摄氏度衡量)的10年移动平均。变量Unc10y表示其95%置信水平下的置信区间。我们令ymax和ymin分别设定为Anomaly10y加减Unc10y
clim<-subset(climate,Source=="Berkeley",select = c("Year","Anomaly10y","Unc10y")
# clim数据展示
Year Anomaly10y Unc10y
1 1800 -0.435 0.505
2 1801 -0.453 0.493
3 1802 -0.460 0.486
…
203 2002 0.856 0.028
204 2003 0.869 0.028
205 2004 0.884 0.029
ggplot(clim, aes(x=Year, y=Anomaly10y)) +
geom_ribbon(aes(ymin=Anomaly10y-Unc10y, ymax=Anomaly10y+Unc10y),alpha=0.2) +
geom_line()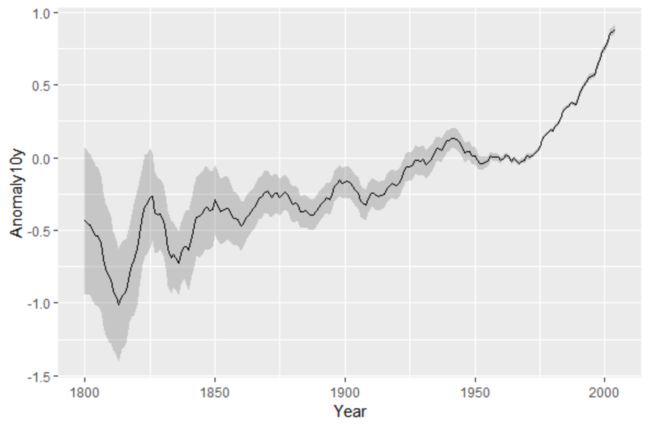
注意,上面的绘图命令中geom_ribbon()函数的调用顺序在geom_line() 函数之前,因而,折线被绘制在阴影区域上面的图层上。如果颠倒调用顺序的话,阴影区域的颜色有可能使折线模糊不清。
同样,对于此例,也可使用虚线作为置信域的上下边界
ggplot(clim, aes(x=Year, y=Anomaly10y)) +
geom_line(aes(y=Anomaly10y-Unc10y), colour="grey50", linetype="dotted") +
geom_line(aes(y=Anomaly10y+Unc10y), colour="grey50", linetype="dotted") +
geom_line()