【HDFS】大数据集群坏盘问题的一种处理实践
大数据集群坏盘问题的一种处理实践
- 前言
- 正文
-
- 思路描述
- 实现记录
-
- 修复脚本
- 服务端脚本
- 试行结果
- 优化思路
- 结语
前言
在规模比较大的HDFS集群里,每天最容易出现的问题便是磁盘问题,我们的大集群1700+的DataNode节点,基本上每天都有磁盘损坏(虽然我也不知道是不是和磁盘的质量有关),有时候是磁盘直接读写错误,有时候是磁盘直接报废,无论怎样,这种情况都需要人工介入处理,如果某几天维护人员都很忙,或者碰到那种恶心的客户天天逮着你做他们的事情,这种坏盘的处理就有可能被搁置。一旦搁置久了,就可能像我们这个屎坑集群一样,积少成多成上百个的坏盘:

基于这个长期存在在我们集群的问题(其他的同行可能也会有这样的烦恼),我们的维护哥们从磁盘的挂载参数到内核参数再到服务器复用的调整等方面尝试进行调整,最后都是无功而返,磁盘该坏还是坏,针对这种局面,想到一种可能能够在一定程度上缓解此问题的方法进行了实践并进行记录。
正文
思路描述
整体思路其实并不难,就是在DN节点上部署脚本,定期通过JMX查询本机的DN坏盘情况,原始数据如下:
{
"beans" : [ {
"name" : "Hadoop:service=DataNode,name=FSDatasetState-null",
"modelerType" : "org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl",
"Remaining" : 15951380725116,
"StorageInfo" : "FSDataset{dirpath='[/data2/hdfs/dfs/data/current, /data3/hdfs/dfs/data/current, /data4/hdfs/dfs/data/current, /data5/hdfs/dfs/data/current, /data6/hdfs/dfs/data/current, /data9/hdfs/dfs/data/current, /data10/hdfs/dfs/data/current, /data11/hdfs/dfs/data/current, /data12/hdfs/dfs/data/current]'}",
"Capacity" : 35017755598848,
"DfsUsed" : 16210350135628,
"CacheCapacity" : 0,
"CacheUsed" : 0,
"NumFailedVolumes" : 2,
"FailedStorageLocations" : [ "/data7/hdfs/dfs/data", "/data8/hdfs/dfs/data" ],
"LastVolumeFailureDate" : 1663317244368,
"EstimatedCapacityLostTotal" : 0,
"NumBlocksCached" : 0,
"NumBlocksFailedToCache" : 0,
"NumBlocksFailedToUncache" : 3152478
} ]
}
这段JSON的请求地址为,别的平台可能会有稍许不同:
curl http://${datanode_ip}:${dfs.datanode.http.address}/jmx?qry=Hadoop:service=DataNode,name=FSDatasetState-null
通过返回的数据我们能够得到FailedStorageLocations值,也就是本地的坏盘统计,根据该值,和当前使用的配置进行比对,将异常磁盘从配置中剔除,然后对服务进行重启,这样就能解决NameNode那边总数统计了大量的坏盘的情况了。
注意: 这一切的操作都建立在公司有特定的人员进行磁盘保障上,不然你就会发现一年以后你们HDFS集群容量越来越少了,而且有上千块磁盘不能用。
当完成了配置项的修改后,就要考虑怎么把散落在各个DN本地的坏盘信息采集过来,提交给报障人员进行统一的报障,总不能指望人家能够去每台服务器采回来吧?不存在的。
上报这块只需要写一个简单的Server端,长期运行,提供POST请求的API,在DN节点运行处理脚本后,脚本根据处理结果调用POST请求,将数据上报到Server端,然后提供一个GET请求的API,方便报障人员直接拉取json格式的数据:

实现记录
修复脚本
首先是实际的修复脚本,大概要实现的功能如下:
- 获取JMX监控数据并处理
- 读取当前使用的配置文件
- 实现处理逻辑,剔除坏盘路径
- 将新的配置写入到配置文件
- 服务的启停
- 最终结果上报
这里因为我们的环境操作系统跨了centos6-7这两个版本,python版本以及默认安装库存在差异,因此在建立网络请求的方法上存在差异,因此写了两个方法分别适用于6和7的操作系统版本:
# 适用于Centos7的请求函数
def get_failvolume_info_c7():
import requests
log.info("Use request package to get the jmx data.")
url="http://{hostname}:port/jmx?qry=Hadoop:service=DataNode,name=FSDatasetState-null".format(hostname=hostname)
try:
rep = eval(str(requests.get(url).json()))
except Exception as e:
log.error("Get the DataNode JMX data error.May be the service is stop? %s".format(e))
exit(1)
return rep
# 适用于Centos6的请求函数
def get_failvolume_info_c6():
import urllib
log.info("Use urllib package to get the jmx data.")
url="http://{hostname}:port/jmx?qry=Hadoop:service=DataNode,name=FSDatasetState-null".format(hostname=hostname)
try:
rep=eval(str(urllib.urlopen(url).read()))
except Exception as e:
log.error("Get the DataNode JMX data error.May be the service is stop? %s".format(e))
exit(1)
return rep
而在区分操作系统版本的时候使用platform库进行:
if __name__ == "__main__":
os_version=platform.platform()
if 'el6' in os_version:
# centos6
data=get_failvolume_info_c6()
elif 'el7' in os_version:
# centos7
data=get_failvolume_info_c7()
else:
log.info("Unsupport os version.")
exit(1)
同样的,在进行数据上报的实现上,也要区分具体的操作系统,因为python2.6默认是没有requests库的:
def report_message(hostname, ip, disk):
log.info("Report the node message to Server.")
disk=",".join(disk)
data={"node": hostname, "ip": ip, "mount": disk}
data=json.dumps(data)
if 'el6' in os_version:
# centos6
import urllib2
req=urllib2.Request(url=REPORT_URL, data=data)
response=urllib2.urlopen(req)
code = response.code
elif 'el7' in os_version:
# centos7
import requests
req=requests.post(url=REPORT_URL, data=data)
code=req.status_code
else:
log.info("Unsupport os version.")
exit(1)
if code == 200:
log.info("The node message report \033[1;32mSUCCESS\033[0m.")
else:
log.error("The node message report \033[1;31mFAILED\033[0m.")
其他部分的实现并没有什么难度。
服务端脚本
接下来是服务端的部分,这部分主要实现这几个功能:
- 使用SQLite存储数据,要创建数据表
- 负责更新节点上报的信息
- 提供接口,允许节点进行上报
只有一个地方要注意,那就是建表添加主键并且更新使用REPLACE语句,比较省事:
def create_table():
logger.info("Create the table repair_nodes.")
conn = sqlite3.connect(DATABASE_FILE)
try:
conn.execute("CREATE TABLE IF NOT EXISTS repair_nodes (node TEXT, ip TEXT, mount TEXT, PRIMARY KEY(node))")
except sqlite3.DatabaseError as e:
logger.warning("Database error. {e}".format(e=e))
except Exception as e:
logger.error("Create table exception. {e}".format(e=e))
conn.close()
def query_db(query, args=(), one=False):
cur = g.db.execute(query, args)
rv = [dict((cur.description[idx][0], value)
for idx, value in enumerate(row)) for row in cur.fetchall()]
return (rv[0] if rv else None) if one else rv
@app.route("/report", methods=["POST"])
def report():
# 数据上报接口
data=request.get_data()
json_data=json.loads(data)
node = json_data['node']
ip = json_data['ip']
mount = json_data['mount']
logger.info("Update database begin, request from {r}".format(r=request.remote_addr))
try:
with sqlite3.connect(DATABASE_FILE) as conn:
cur = conn.cursor()
cur.execute("REPLACE INTO repair_nodes(node, ip, mount) values(?,?,?)", (node,ip,mount))
conn.commit()
except Exception as e:
logger.error("Update data to databases failed.{e}".format(e=e))
return json_data
试行结果
经过两天的测试和各方面的调整,在生产环境正式应用了这套处理脚本,在这个过程中首先要观察的就是存量坏盘的减少情况,通过监控图表能够很明显的看出数量呈现飞速的下降趋势:

除此之外,要观察坏块、HDFS存储容量已经DN存活情况,可以看到HDFS存储总容量是不断往好的方向发展的(之所以上升这么多是因为同步处理了另一个问题)
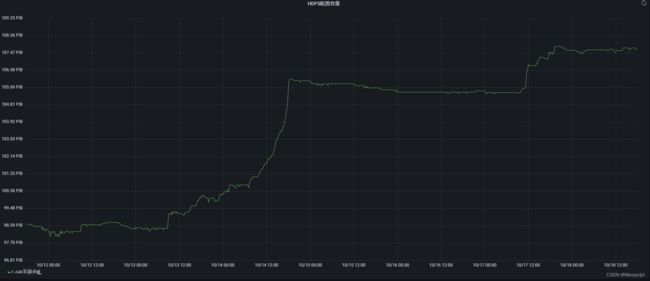

优化思路
当前,若是人工对服务器磁盘进行报障修复以后,服务端还没有更新方式,后续可以在修复脚本中增加对应的逻辑,定时运行的时候检查本机磁盘,若是已经修复,就对Server端进行上报,同时提供面向维护人员的接口,能够手动进行更新。
结语
磁盘问题已困扰了我们的维护人员很久,虽然这种处理方式有些治标不治本,但是在没找到降低磁盘损坏率的方法之前,这种处理方式最大程度上能够保证业务的高效运行,也算是一点安慰吧。