【数据治理】Atlas2.2.0基于HDP进行Hive的接入
Atlas2.2.0基于HDP进行Hive的接入
- 前言
- 正文
-
- 前提条件
- 操作步骤
-
- 导入离线数据
- 设置Hive-Hook
- 测试SQL触发血缘变化
-
- 创建数据库
- 创建数据表
- 插入数据,测试血缘
前言
本文记录了在HDP3.1.5下,对接Atlas2.2.0的相关操作步骤和注意事项
正文
前提条件
- 确认脚本运行的服务器存在hive客户端配置文件,且路径为
/etc/hive/conf/; - 将
atlas-application.properties配置文件拷贝到hive客户端配置路径; - 确保脚本运行的服务器存在hadoop服务和依赖包,简而言之,要有客户端程序;
操作步骤
导入离线数据
针对已经在Hive中存在的数据,要使用离线脚本进行导入,该脚本在Atlas中已经包含:
./import-hive.sh

设置Hive-Hook
如果使用的是Ambari,直接在Hive中进行设置或者修改hive-site.xml客户端配置:
<property>
<name>hive.exec.post.hooksname>
<value>org.apache.atlas.hive.hook.HiveHookvalue>
property>
<property>
<name>atlas.cluster.namename>
<value>atlasvalue>
property>
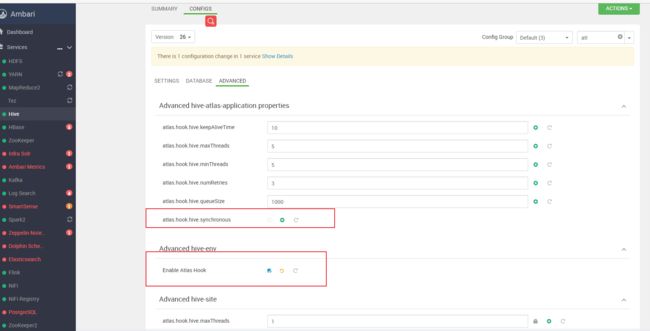
自定义atlas-application.properties配置:
# hive-hook相关的信息
atlas.hook.hive.keepAliveTime=10
atlas.hook.hive.maxThreads=5
atlas.hook.hive.minThreads=5
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=1000
atlas.hook.hive.synchronous=false
# 以下配置项保证和Server端一致
atlas.kafka.bootstrap.servers=172.18.2.11:6667,172.18.2.37:6667,172.18.2.19:6667
atlas.kafka.hook.group.id=atlas
atlas.kafka.zookeeper.connect=172.18.2.11:2181,172.18.2.37:2181,172.18.2.19:2181
atlas.kafka.zookeeper.connection.timeout.ms=200
atlas.kafka.zookeeper.session.timeout.ms=400
# 使用的kafkaTopic名称
atlas.notification.topics=ATLAS_HOOK,ATLAS_ENTITIES
# atlas对应的restapi地址
atlas.rest.address=http://172.18.0.25:21000
# 集群名称
atlas.cluster.name=dev


设置以后重启Hive服务,目前没有测试不重启是否能生效,估计是不能
测试SQL触发血缘变化
创建数据库
create database atlas_test;

创建数据表
create table `dept`(
`deptno` int,
`dname` varchar(14),
`loc` varchar(13)
) row format delimited fields terminated by '\t'
stored as textfile;

插入数据,测试血缘
# 插入原始数据
insert into dept values (10,'accounting','new york'),(20,'research','dallas'),(30,'sales','chicago'),(40,'operations','boston');
# 创建dept_two表,数据来自于dept
create table dept_two as select * from dept;
# 创建dept_three表,数据来自于dept_two
create table dept_three as select * from dept_two;
# 创建dept_four空表
CREATE TABLE `dept_four`(
`deptno` int,
`dname` varchar(14),
`loc` varchar(13))
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://node-4.datasw:8020/warehouse/tablespace/managed/hive/atlas_test.db/dept_four'
TBLPROPERTIES (
'bucketing_version'='2',
'transactional'='true',
'transactional_properties'='default',
'transient_lastDdlTime'='1667376408');
# 向dept_four表插入数据,数据来源于dept_three
insert into table dept_four select * from dept_three;
# 向dept_four表插入数据,数据来源于dept_two
insert into table dept_four select * from dept_two;
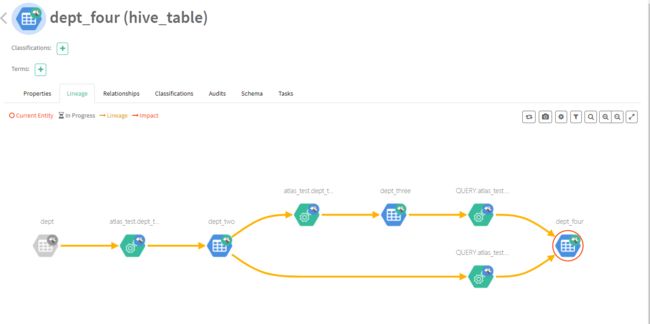
最终形成如下的血缘图: