【Linux】基础IO——文件描述符/缓冲区/重定向/文件系统
文章目录
- 一、文件描述符
- 二、缓冲区
- 三、重定向的原理
- 四、文件系统 (Linux Ext2)
-
- 1 认识磁盘的结构
-
- CHS
- LBA
- Block
- 2 认识文件系统
-
- 2.1 分区
- 2.2 文件系统的结构
- 2.3 剖析inode
- 2.4 文件的操作
- 3 软硬链接
-
- 3.1 软链接
- 3.2 硬链接
- 个人主页 :超人不会飞)
- 本文收录专栏:《Linux》
- 如果本文对您有帮助,不妨点赞、收藏、关注支持博主,我们一起进步,共同成长!
一、文件描述符
当一个进程打开一个文件时,有趣的事情就发生了。
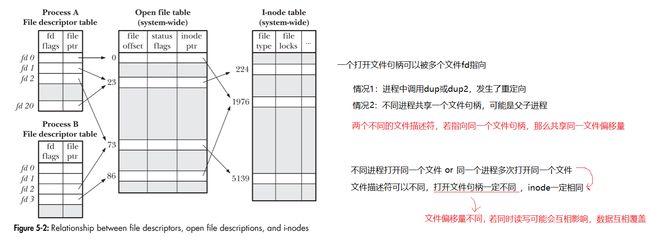
- OS会跟踪进程打开的文件,并为其创建一个结构体(struct_file),该结构体中维护着打开文件的状态和信息,如:文件指针、文件在磁盘中所在位置、访问权限、inode元信息等。
- 为了建立进程与文件的联系,进程PCB维护着一个结构体(struct_files),该结构体中最重要的就是包含了一个指针数组,数组中每个指针指向进程打开的文件(内核中的结构体)。多个这样的结构体,组成了打开文件表,每一个结构体称为打开文件句柄。
- 文件描述符(file descriptor)本质上就是该数组的下标,上面的过程,总结一下就是:进程每打开一个文件,都会为该文件分配一个文件描述符。因此,在OS层面,文件描述符是一个文件的唯一标识。
Linux的设计思想是,一切皆文件,当然也包括显示器和键盘这些设备。每个进程启动时,会默认打开三个文件流(内核中维护文件状态信息的结构体):标准输入、标准输出、标准错误。标准输入对应的是键盘,标准输出和标准错误对应的是显示器。(可以理解为,这些外设设备都有驱动程序,驱动程序一般是保存在磁盘中的文件,打开这些设备就是将对应的驱动程序文件打开到内存中)。
标准输入、标准输出、标准错误的文件描述符分别为0、1、2。

文件描述符的分配规则:最小未使用。
系统接口中的open,作用是打开一个文件,返回值就是文件描述符。这是系统调用打开文件的方法,各种语言中的打开文件接口底层都调用了open(如C语言的fopen)。
NAME
open, creat - open and possibly create a file or device
SYNOPSIS
#include 二、缓冲区
如果用户想要向一个文件中写入数据或读取数据,文件在磁盘中,进程维护在内存中,若每读写一次就要与磁盘进行一次IO,效率会十分低下。因此便有了缓冲区的概念。缓冲区将用户想要读写的数据先缓存起来,达到一定的条件时在与磁盘进行IO,而不是写一次IO一次,大大提高了读写效率。
缓冲区分为:用户级缓冲区和内核级缓冲区
用户级缓冲区: 用户级缓冲区一般是在进程的堆栈区中创建的,其存在的意义是减少系统调用次数,从而降低操作系统在用户态和内核态之间切换所耗费的时间。例如,在C语言中,FILE结构体用来维护文件的状态和信息,其中就维护了一个用户级的缓冲区,fwrite、fputs等接口都是将数据写入这个缓冲区里面,而不是直接写入文件。
内核级缓冲区: 每一个打开文件都会在内核中维护一个缓冲区,称为内核缓冲区。内核缓冲区存在的意义减少IO次数,提高向文件写数据的效率。当调用write时,会从用户级缓冲区的数据写入内核级缓冲区。调用read时,将数据从内核级缓冲区写入用户级缓冲区。调用write不一定会触发OS与磁盘的IO,当内核缓冲区中的数据达到一定数量,才会向磁盘中写入数据。
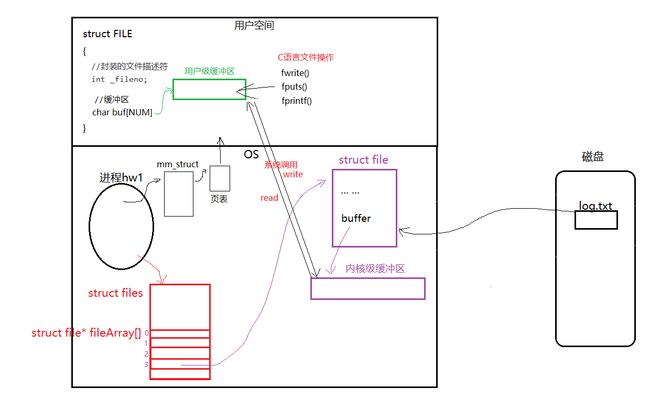
用户级缓冲区向内核级缓冲区刷新数据的策略:
- 对于显示器,行缓冲(遇到’\n’就刷新)
- 对于普通文件,全缓冲(缓冲区满再刷新)
- 无缓冲(有数据就刷新)
内核级缓冲区向文件刷新数据的策略一般由OS决定,用户不可见。
-
C语言的fclose接口,会刷新用户缓冲区再关闭文件。进程结束时,OS会将FILE维护的缓冲区中的数据刷新到内核。
-
有时候我们也需要强制刷新缓冲区,如C语言中用到了fflush函数,它实际上就是将FILE维护的用户级缓冲区中残余的数据刷新到内核缓冲区中。
-
如若需要将数据从内核缓冲区刷新到文件中,则是调用系统调用接口
void sync(void)(刷新全部缓冲区)或int syncfs(int fd)(刷新文件描述符为fd的文件的缓冲区)
NAME
sync, syncfs - commit buffer cache to disk
SYNOPSIS
#include 下面是我基于对C语言FILE结构体和文件操作函数的理解,仿写其实现。感兴趣的小伙伴可以看看
myfile_gitee地址
三、重定向的原理
关于重定向,bash下的部分指令:
| 类型 | 指令 | 作用 |
|---|---|---|
| 输入重定向 | file1 < file2 | 将file2的内容作为file1的输入 |
| 输出重定向 | file2 > file1 | 将file2的输出结果拷贝到file1中(file1原数据先清除) |
| 追加重定向 | file2 >> file1 | 将file2的输出结果追加拷贝到file1中 |
所谓重定向,其原理是改变文件描述符表中指针的指向,使对一个文件的操作变成对另一个文件的操作。
举例:若要把a.out程序的输出结果重定向到log.txt,即./a.out > log.txt
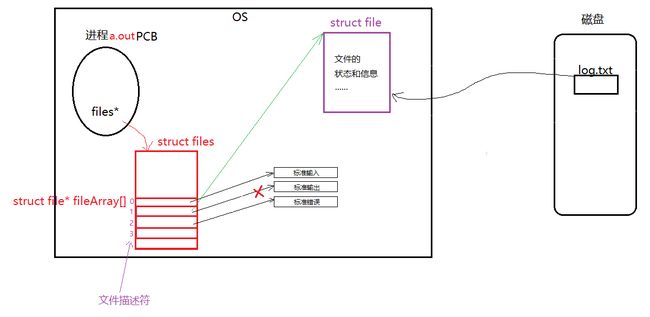
如图,将a.out进程维护的文件描述符表中指向标准输出的指针改为指向log.txt文件流,从而log.txt文件获得了文件描述符1。从语言层级,就拿C语言举例,若此时a.out中有printf函数,这是默认朝标准输出传递数据的,也就是文件描述符为1的文件,但此时OS层级已经修改了文件描述符1的指向,但是进程并不知道,所以就实现的输出重定向。
除了bash指令,实现重定向的方法
1️⃣先关闭再打开,根据文件描述符的分配规则即可分配到指定描述符。
int main()
{
umask(0);
close(1);
int fd = open("log1.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
printf("hello printf\n");
fprintf(stdout,"hello fprintf stdout\n");
return 0;
}
2️⃣dup系统接口
#include 常用的是dup2接口
**介绍:**在文件描述符表中,newfd对应指针成为oldfd对应指针的拷贝,最终留下oldfd,必要时先关闭newfd。若oldfd无效,则调用失败,newfd不会关闭;若oldfd有效,但oldfd与newfd相同,则不会发生任何事,并返回newfd。
**返回值:**成功返回newfd,失败返回-1。

一些补充知识的总结:
测试代码(同一个进程多次打开同一个文件)
int main()
{
int fd1 = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
int fd2 = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
printf("fd1=%d fd2=%d\n",fd1,fd2);
const char* msg1 = "hello fd1\n";
const char* msg2 = "hello fd2\n";
//先向fd1写入msg1,再向fd2写入msg2
//由于是不同打开文件句柄,文件偏移量不同,fd1写入msg1后文件偏移量改变,但fd2的文件偏移量不变
//因此msg2会覆盖msg1
write(fd1,msg1,strlen(msg1));
write(fd2,msg2,strlen(msg2));
//此时log.txt里的内容是"hello fd2\n"
//再次向fd1写入msg1
//由于fd1、fd2文件偏移量均已改变且相同,所以此时写入msg1不会发生覆盖
write(fd1,msg1,strlen(msg1));
//此时log.txt里的内容是:"hello fd2\nhello fd1\n"
close(fd1);
close(fd2);
return 0;
}
⭕检验结果
[ckf@VM-8-3-centos lesson4_file]$ gcc test4.c
[ckf@VM-8-3-centos lesson4_file]$ ./a.out
fd1=3 fd2=4
[ckf@VM-8-3-centos lesson4_file]$ cat log.txt
hello fd2
hello fd1
四、文件系统 (Linux Ext2)
1 认识磁盘的结构
CHS

-
磁头(head)数最大为255 (用 8 个二进制位存储)。从0开始编号。
-
柱面(cylinder)数最大为1023(用 10 个二进制位存储)。从0开始编号。
-
扇区(sector)数最大数 63(用 6个二进制位存储)。从1开始编号。
磁盘上,盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据
磁头用于读取盘面上的数据,一个盘面对应一个磁头,因此用磁头编号来标识某一个盘面。
磁盘的单位是扇区,一个扇区的存储空间大小是512字节。
⭕根据磁盘的物理结构,可以用“第x个盘面(磁头)第y个柱面第z个扇区”来定位数据存储位置,这种方法称为CHS定址法。
LBA
观察盘面的结构可以发现,每个磁道的扇区数相等,但外磁道的扇区面积大于内磁道扇区面积,而扇区的存储量却相同。这会导致外磁道扇区的存储密度低于内磁道扇区的存储密度,造成空间浪费。因此,后来工程师为了平衡内外磁道存储密度,增加了外磁道的扇区数量。这样一来,CHS地址就无法唯一确定一个扇区了,于是又将磁盘空间逻辑抽象成一个线性空间,单位是扇区,如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1eN42BsZ-1688355188465)(C:_data\博客\git_blog_pictures\基础IO\image-20230630095133112.png)]](http://img.e-com-net.com/image/info8/40413580822a4378a724c03f2f4b9d39.png)
在这个线性空间中,每个扇区都有一个地址,这个地址称为LBA(逻辑块地址,Logic Block Address)。
LBA由磁盘控制器维护
LBA和CHS可以按照一定的规则相互转换
Block
综上所述,磁盘的最小读写单位是扇区(512KB)。如果每次读取都以此作为最小单位,那么效率会非常低,因此,文件系统将磁盘空间又分为一个个块(Block),每个块由多个扇区组成,每个块的大小在格式化文件系统时决定(ext2中,1K/2K/4K,一般是4K,即八个扇区)。

Block大小在格式化文件系统时就确定,不可修改,在ext2文件系统一般为4KB
一个block只能存放一个文件的数据,因此block大小不合适很可能会导致空间浪费。
每一个Block都有自己的编号,本质上可以把这个空间看作是数组,Block编号就是数组下标
自此我们有了三种地址:CHS、LBA、Block号
2 认识文件系统
2.1 分区
文件系统是计算机系统中用于组织和管理数据的一种机制或软件。它提供了一种结构化的方法,用于存储、访问、检索和维护计算机系统上的文件和目录。文件系统应用于磁盘空间的不同分区上,通常一个分区会使用一套文件系统来组织和管理数据,那么分区是什么?
下面这张图应该都不陌生。我们平时经常会提及给电脑“分盘”的概念,实际上就是磁盘空间的分区。事实上,计算机只有一个磁盘,但是存储了不同类型的数据(如:内核数据、用户数据等),为了方便管理,OS将磁盘从逻辑上区分为多个部分,这就是分区,每个分区可以独立进行格式化和管理。

每个分区都有自己的文件系统,用于在该分区上创建、存储和操作文件和目录。不同的分区使用不同的文件系统,以适应不同的需求和操作系统的要求。

2.2 文件系统的结构

Block Group: ext2文件系统会按照分区的大小,将其划分为多个组(group)。每个组的大小和结构都相同,管理方法也相同,所以确定了一组的管理方式,就能管理所有组。
BootBlock: 系统的引导块,一般用于计算机开机时的初始化,例如在磁盘上找到OS内核,加载到内存中,然后跳转到初始地址开始执行OS。在磁盘中的位置是固定的,一般CHS地址为0号磁头0号柱面1号扇区。
SuperBlock: 超级块,用于存储整个文件系统的相关信息,如:block和inode的总理;未使用的block和inode的数量;block与inode的大小(block为1/2/4K,inode为128byte),对于文件系统来说十分重要,SuperBlock的信息被破坏,可以说整个文件系统结构就被破坏了。因此一般同一个文件系统的每个group中都在开头设置了SuperBlock,目的是拷贝多份防止数据损坏。如果group1的SuperBlock数据损坏了,则可以group2的SuperBlock中拷贝数据过去,它们的内容是一样的。
GDT,Group Descriptor Table:块组描述符,描述当前区段(block group)开始和结束的block号码,以及说明每个区段(inodemap、blockmap、inode table)分别介于哪些block号码之间。
Inode Table:
先介绍inode:inode(index node)是文件的索引节点,记录文件的各种信息,如:inode编号;文件属性、权限;硬链接引用计数;文件大小;文件数据所在块block的编号…
而Inode Table用于存储这些inode节点,本质就是一个数组
关于inode:一个文件系统中,每个文件的inode编号都是唯一的。每一个分组都有一个特定的inode编号范围,文件的inode编号 = 所属分组inode编号范围起始值 + inode节点在分组内Inode Table中的下标
Block BitMap: 标识Data Block中每一个数据块是否被占用的位图
Inode BitMap: 标识Inode Table中每一个位置是否被占用的位图
2.3 剖析inode
当用户访问一个文件时,必须通过该文件的inode才能找到对应的数据(实际上文件数据存储在block)。一个inode节点(语言层面可以理解为一个结构体)内部大致划分为两个区域,一个是存储文件权限、属性等其它信息,另一个则是一个记录文件数据所在的block编号的表。
而由于inode的大小只有128字节(ext2),如果一个文件太大,其占用的block数量可能会超过inode可记录的数量。为此,inode记录block号码的区域被设计为12个直接、一个间接、一个双间接、一个三间接记录区。所谓间接,就是拿一个block当作其它block的编号记录区,只有最后一个间接才会真正用来记录block号码,其他的间接层,都只是依次引用。
一个block = 4KB
block编号是一个整型,因此:一个编号的大小 = sizeof(int) = 4byte
故一个block能存储的编号数量 = 4KB / 4byte = 1024
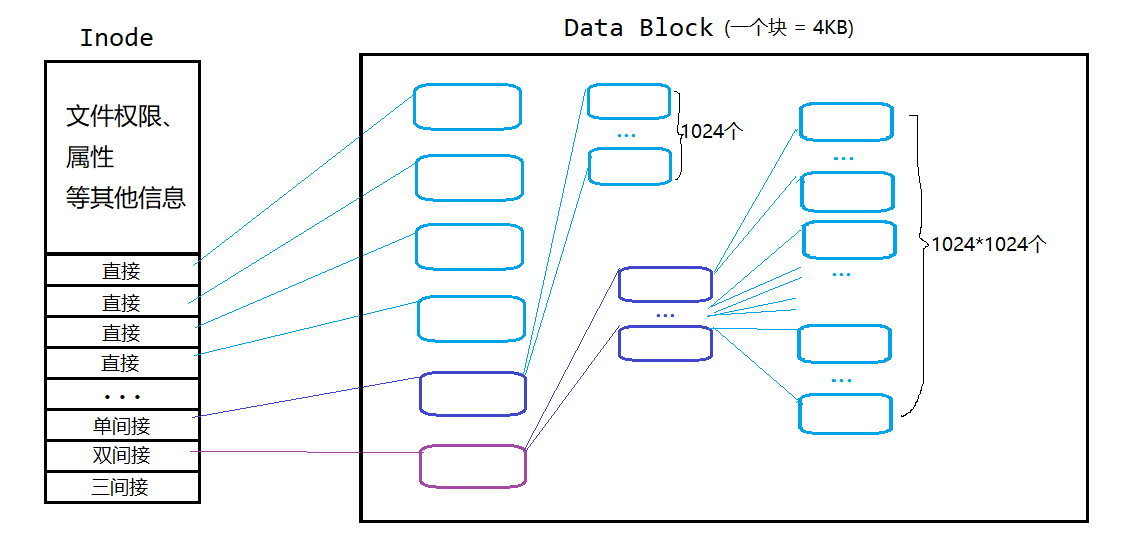
所以在当前文件系统(blocksize = 4KB)下,一个inode能索引的最大数据量(即单文件最大容量)为:
12 × 4 + 1024 × 4 + 1024 × 1024 × 4 + 1024 × 1024 × 1024 × 4 = 4 T B 12 \times 4 + 1024\times4 + 1024\times1024\times4 + 1024\times1024\times1024\times4 = 4TB 12×4+1024×4+1024×1024×4+1024×1024×1024×4=4TB
查看inode编号的bash指令:ls加上-i选项即可查看

2.4 文件的操作
文件的操作有访问文件、创建文件、删除文件。这些操作在底层是怎样实现的呢?要解决这个问题,先要弄懂目录的存储。
要想对一个文件进行操作,必须先找到他。知道了文件数据的存储在数据块中,那我们怎么找到文件?要知道,文件一定在目录中,而目录也是个文件。目录是一个特殊文件,那么同理他必然也会有对应的inode节点和block数据库,而**目录的block中存放的是目录中文件的文件名和inode的映射关系。**因此,知道文件名就能在目录中找到对应的inode,自然也能找到文件了。
因此可以得出一个结论:文件名不是文件的属性,不存储在文件inode中,而是存储在文件所在目录的数据块中,发挥与inode映射的作用。
例:假设有一个目录mydir,下面是其包含文件和block中存储数据的示意图

了解目录的存储后,就能从底层摸清访问文件、创建文件、删除文件的过程了。
假设我们要对一个名为"log.txt"的文件进行操作
- 访问文件:
(访问文件就是要找到文件,是操作文件最重要的一步,分为以下几步)- 找到当前目录的block数据块(通过内存中打开的目录对象)
- 根据文件名log.txt,找到文件名与文件inode号的映射关系
- 在当前文件系统中,先通过inode号确定文件所在分组,再确定文件在组内Inode Table的下标,最终找到inode
- 通过文件的inode与数块的映射关系,找到其block
- 最后将block中的数据load到内存中,成功访问log.txt文件
总过程:
文件名 → \rightarrow → inode号 → \rightarrow → inode → \rightarrow → block
-
创建文件:
- 在当前目录所在分区中,找到某个group中空闲的Inode Table位置(即扫描每个Inode BitMap,0即是空)。得到一个inode号。
- 在找到的Inode Table空位上新建一个inode,并写入文件属性(必须写入已经得到的node号,并且注意此时新文件(非目录)为空,没有数据块)
- 在当前目录的数据块中,写入新文件的文件名"log.txt"与inode号的映射关系。
-
向文件写入数据:
- 按照访问文件的步骤先找到文件的inode编号和inode
- 扫描文件所在group的Block BitMap,寻找空闲block,开始向这些block写入数据
- 写入完毕后,将这些block号对应Block BitMap位置中的0置为1,即标识这些block已被占用
- 建立文件inode与占用block的映射关系,并修改inode中的文件属性(如文件大小)
-
删除文件:
-
按照访问文件的步骤先找到文件的inode编号和inode
-
改位图:Inode BitMap对应位置1$\rightarrow 0 ; B l o c k B i t M a p 对应位置 1 0;Block BitMap对应位置 1 0;BlockBitMap对应位置1\rightarrow$0;
⭕注意:删除文件并没有直接清除block上的数据,而是在Inode BitMap和Block BitMap位图层级上取消占用。这也为恢复已删除文件提供了可能,只要已删文件曾用过的block未被其它文件写入数据,数据未被破坏,就有恢复的可能。
-
补充两个细节:
- 为了方便管理,一个目录和该目录下的文件会存储在同一个分区中;(这也能解释为何一个目录下不能有同名文件了,因为一个文件系统中,每个文件的inode编号都是唯一的,如果一个目录下出现同名文件,就无法建立文件名和inode一一对应的映射关系了)
- 为了提高访问速度,减少磁盘IO次数,OS把曾经使用过的和当前使用的目录文件缓存到内存中,形成一个个目录项(一个内存级的数据结构),目录项将文件名和对应的inode关联起来(每个目录项对应一个文件或子目录)。这样文件系统就能通过内存中的目录项,快速找到文件名和对应inode的映射关系,而不用每次都到磁盘中将目录的数据load到内存。
3 软硬链接
有时候我们希望对文件起别名,以达到某种效果。那么在Linux中,可以使用软链接(Symbolic Link)和硬链接(Hard Link)来实现。
3.1 软链接
概念:
软链接的本质是一个新文件,它与链接文件不是同一个文件,拥有独立的inode。软链接中存储的是链接文件的路径,所以访问软链接时,相当于访问另一个文件。
-
创建hello程序的软链接(ln -s 文件名 软链接名)
[ckf@VM-8-3-centos linkTest]$ ll total 16 -rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello -rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c [ckf@VM-8-3-centos linkTest]$ ./hello hello link [ckf@VM-8-3-centos linkTest]$ ln -s hello hello-soft -
查看当前目录,发现创建了一个新文件hello-soft与hello链接,且二者inode编号不同
[ckf@VM-8-3-centos linkTest]$ ll -i total 16 926892 -rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello 926891 -rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c 1058748 lrwxrwxrwx 1 ckf ckf 5 Jul 2 11:11 hello-soft -> hello -
运行hello-soft,发现结果与hello一致
[ckf@VM-8-3-centos linkTest]$ ./hello-soft hello link
由于软链接是独立的文件,因此,删除其链接的文件,软链接依然存在,只是找不到里面的文件了。

软链接示意图

应用场景:
对于一些路径较深,难以按路径访问的文件,可以用软链接作为快捷方式访问。
[ckf@VM-8-3-centos linkTest]$ ll
total 20
drwxrwxr-x 3 ckf ckf 4096 Jul 2 11:22 a
-rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello
-rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c
[ckf@VM-8-3-centos linkTest]$ tree a
a
`-- b
`-- c
`-- d
`-- hello
3 directories, 1 file
[ckf@VM-8-3-centos linkTest]$ ln -s a/b/c/d/hello hello-shortcut
[ckf@VM-8-3-centos linkTest]$ ll
total 20
drwxrwxr-x 3 ckf ckf 4096 Jul 2 11:22 a
-rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello
-rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c
lrwxrwxrwx 1 ckf ckf 13 Jul 2 11:24 hello-shortcut -> a/b/c/d/hello
[ckf@VM-8-3-centos linkTest]$ ./a/b/c/d/hello
hello link
[ckf@VM-8-3-centos linkTest]$ ./hello-shortcut
hello link
3.2 硬链接
概念:
硬链接是在目录中创建一对新的文件名与inode映射关系,文件名新起,inode是另一个文件的inode。硬链接和链接文件共享一个inode,相当于链接文件的别名。一个文件可以有多个硬链接。事实上,inode节点中有一个引用计数,新建一个硬链接时,引用计数自增1,删除时自减1,只有当引用计数清零时,文件才会被删除。
-
创建hello程序的硬链接hello-hard(ln 文件名 硬链接名),发现hello和hello-hard的inode编号相同
[ckf@VM-8-3-centos linkTest]$ ln hello hello-hard [ckf@VM-8-3-centos linkTest]$ ll -i total 32 1058749 drwxrwxr-x 3 ckf ckf 4096 Jul 2 11:22 a 926892 -rwxrwxr-x 2 ckf ckf 8360 Jul 2 10:45 hello 926892 -rwxrwxr-x 2 ckf ckf 8360 Jul 2 10:45 hello-hard 926891 -rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c 1058748 lrwxrwxrwx 1 ckf ckf 13 Jul 2 11:24 hello-shortcut -> a/b/c/d/hello -
文件属性一行的第三个数字是该文件的硬链接数(inode引用计数),若我们再给hello创建一个硬链接,可发现此数字会发生变化
[ckf@VM-8-3-centos linkTest]$ ln hello hello-hard2 [ckf@VM-8-3-centos linkTest]$ ll -i total 44 1058749 drwxrwxr-x 3 ckf ckf 4096 Jul 2 11:22 a 926892 -rwxrwxr-x 3 ckf ckf 8360 Jul 2 10:45 hello 926892 -rwxrwxr-x 3 ckf ckf 8360 Jul 2 10:45 hello-hard 926892 -rwxrwxr-x 3 ckf ckf 8360 Jul 2 10:45 hello-hard2 926891 -rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c 1058748 lrwxrwxrwx 1 ckf ckf 13 Jul 2 11:24 hello-shortcut -> a/b/c/d/hello -
运行硬链接,发现结果一致
[ckf@VM-8-3-centos linkTest]$ ./hello hello link [ckf@VM-8-3-centos linkTest]$ ./hello-hard hello link [ckf@VM-8-3-centos linkTest]$ ./hello-hard2 hello link
硬链接示意图

应用场景:
每个文件夹中,都至少会有 . 和 ..两个目录,分别代表当前目录和上级目录,它们的本质就是相应目录的硬链接
.
[ckf@VM-8-3-centos linkTest]$ ll -a
total 24
drwxrwxr-x 2 ckf ckf 4096 Jul 2 15:42 .
drwxrwxr-x 5 ckf ckf 4096 Jul 2 10:49 ..
-rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello
-rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c
[ckf@VM-8-3-centos linkTest]$ pwd
/home/ckf/NewBeginning/lesson4_file/linkTest
[ckf@VM-8-3-centos linkTest]$ ls -di .
1058747 .
[ckf@VM-8-3-centos linkTest]$ ls -di /home/ckf/NewBeginning/lesson4_file/linkTest
1058747 /home/ckf/NewBeginning/lesson4_file/linkTest
//第10和12行表明,.和/home/ckf/NewBeginning/lesson4_file/linkTest的inode号相同,.是硬链接
..
一个父目录下,每个子目录都有父目录的硬链接..,父目录除了自己的绝对路径和.硬链接,其它硬链接就是子目录的..,因此:
父目录下的子目录数量 = 父目录的硬链接数 − 2 父目录下的子目录数量 = 父目录的硬链接数 - 2 父目录下的子目录数量=父目录的硬链接数−2
利用硬链接,Linux的文件系统呈现出如下的树状结构,每个节点之间都存在一条路径

⭕值得注意的是,OS只允许用户对普通文件做硬链接,不允许对目录进行硬链接,否则可能会导致文件系统树状结构出现环路,结构一旦遭到破坏,对文件的访问就会出问题(如:一个文件有两个绝对路径)。
[ckf@VM-8-3-centos linkTest]$ ll
total 20
drwxrwxr-x 2 ckf ckf 4096 Jul 2 15:53 emptyDir
-rwxrwxr-x 1 ckf ckf 8360 Jul 2 10:45 hello
-rw-rw-r-- 1 ckf ckf 77 Jul 2 10:45 hello.c
[ckf@VM-8-3-centos linkTest]$ ln emptyDir hard-link
ln: ‘emptyDir’: hard link not allowed for directory

Ending