Cachelab 高速缓冲器模拟
实验报告
实 验(六)
题 目 Cachelab
高速缓冲器模拟
专 业 计算机科学与技术
csim.c和trans.c代码见文章末尾
目 录
第1章 实验基本信息... - 3 -
1.1 实验目的... - 3 -
1.2 实验环境与工具... - 3 -
1.2.1 硬件环境... - 3 -
1.2.2 软件环境... - 3 -
1.2.3 开发工具... - 3 -
1.3 实验预习... - 3 -
第2章 实验预习... - 5 -
2.1 画出存储器层级结构,标识容量价格速度等指标变化(5分)... - 5 -
2.2用CPUZ等查看你的计算机Cache各参数,写出各级Cache的C S E B s e b(5分)... - 6 -
2.3写出各类Cache的读策略与写策略(5分)... - 6 -
2.4 写出用gprof进行性能分析的方法(5分)... - 7 -
2.5写出用Valgrind进行性能分析的方法((5分)... - 7 -
第3章 Cache模拟与测试... - 9 -
3.1 Cache模拟器设计... - 9 -
3.2 矩阵转置设计... - 12 -
第4章 总结... - 20 -
4.1 请总结本次实验的收获... - 20 -
4.2 请给出对本次实验内容的建议... - 20 -
参考文献... - 21 -
第1章 实验基本信息
1.1 实验目的
理解现代计算机系统存储器层级结构
掌握Cache的功能结构与访问控制策略
培养Linux下的性能测试方法与技巧
深入理解Cache组成结构对C程序性能的影响
1.2 实验环境与工具
1.2.1 硬件环境
X64 CPU;2GHz;2G RAM;256GHD Disk 以上
1.2.2 软件环境
Windows7 64位以上;VirtualBox/Vmware 11以上;Ubuntu 16.04 LTS 64位/优麒麟 64位;
1.2.3 开发工具
Visual Studio 2010 64位以上;TestStudio;Gprof;Valgrind等
1.3 实验预习
上实验课前,必须认真预习实验指导书(PPT或PDF)
了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。
画出存储器的层级结构,标识其容量价格速度等指标变化
用CPUZ等查看你的计算机Cache各参数,写出C S E B s e b
写出Cache的基本结构与参数
写出各类Cache的读策略与写策略
掌握Valgrind与Gprof的使用方法
第2章 实验预习
2.1 画出存储器层级结构,标识容量价格速度等指标变化(5分)
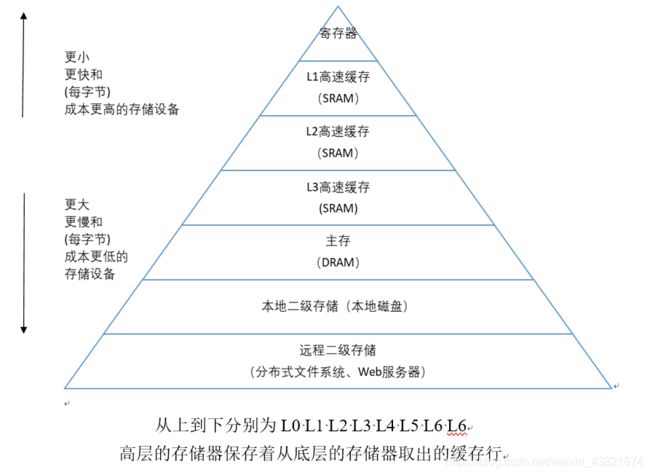
从上到下分别为L0 L1 L2 L3 L4 L5 L6 L6
高层的存储器保存着从底层的存储器取出的缓存行
2.2用CPUZ等查看你的计算机Cache各参数,写出各级Cache的C S E B s e b(5分)
2.3写出各类Cache的读策略与写策略(5分)
Cache读策略
1:缓存命中,则从cache中读相应数据到CPU或上一级cache中。
2:缓存不命中,则从主存或下一级cache中读取数据,并替换出一行数据。
Cache写策略
1、写回
当CPU写Cache命中时,只修改Cache的内容,而不是立即写入主存;只有当此块被换出时才写回主存。
2、直写
立即将一个已经缓存了的字w的高速缓存块写回到紧接着的第一层中。。
3、写分配
加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块。
4、非写分配
避开高速缓存,直接把这个字写到低一层中去。
2.4 写出用gprof进行性能分析的方法(5分)
gprof是GNU profile工具,可以运行于linux、AIX、Sun等操作系统进行C、C++、Pascal、Fortran程序的性能分析,用于程序的性能优化以及程序瓶颈问题的查找和解决。通过分析应用程序运行时产生的“flat profile”,可以得到每个函数的调用次数,每个函数消耗的处理器时间,也可以得到函数的“调用关系图”,包括函数调用的层次关系,每个函数调用花费了多少时间。使用步骤如下:
(1)用gcc、g++、xlC编译程序时,使用-pg参数,如:g++ -pg -o test.exe test.cpp编译器会自动在目标代码中插入用于性能测试的代码片断,这些代码在程序运行时采集并记录函数的调用关系和调用次数,并记录函数自身执行时间和被调用函数的执行时间。
(2)执行编译后的可执行程序,如:./test.exe。该步骤运行程序的时间会稍慢于正常编译的可执行程序的运行时间。程序运行结束后,会在程序所在路径下生成一个缺省文件名为gmon.out的文件,这个文件就是记录程序运行的性能、调用关系、调用次数等信息的数据文件。
(3)使用gprof命令来分析记录程序运行信息的gmon.out文件,如:gprof test.exe gmon.out则可以在显示器上看到函数调用相关的统计、分析信息。上述信息也可以采用gprof test.exe gmon.out> gprofresult.txt重定向到文本文件以便于后续分析。
2.5写出用Valgrind进行性能分析的方法((5分)
Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,它包含一个内核──一个软件合成的CPU,和一系列的小工具,每个工具都可以完成一项任务──调试,分析,或测试等。Valgrind可以检测内存泄漏和内存违例,还可以分析cache的使用等。Valgrind包含以下工具:Memcheck(用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获)、Callgrind(收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件,callgrind_annotate可以把这个文件的内容转化成可读的形式)、Cachegrind(模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数)、Helgrind(用来检查多线程程序中出现的竞争问题)、Massif(堆栈分析器,能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小)。Valgrind的使用非常简单,valgrind命令的格式如下:valgrind [valgrind-options] your-prog [your-prog options] 。一些常用的选项如下:
选项 作用
-h --help 显示帮助信息
--version 显示valgrind内核的版本,每个工具
都有各自的版本
-q --quiet 安静地运行,只打印错误信息
-v --verbose 打印更详细的信息。
--tool= [default: memcheck] 最常用的选项。运行valgrind中名为
toolname的工具。如果省略工具名,
默认运行memcheck。
--db-attach= [default: no] 绑定到调试器上,便于调试错误。
第3章 Cache模拟与测试
3.1 Cache模拟器设计
提交csim.c
程序设计思想:
1.首先介绍程序主要定义的变量和结构体:
typedef struct cache_line {
char valid; //有效位
mem_addr_t tag; //标识位
int lru; //最后的访问时间距离现在最远的块
} cache_line_t;
cache_set_t; //储存每一组包含的行
cache_t; //定义指向组的指针
还有s , E , hit_count , lru_counter等全局变量就不再多说。
2.下面分析程序主要的函数:
在主函数中从命令行参数计算S,E和B. 如下:
S = 1<
B = 1<
E = E;
initCache()函数 - 分配内存,写0表示有效和标记和LRU,为它们初始化
cache.sets = (cache_set_t*)malloc(S*sizeof(cache_set_t));
cache.sets = (cache_set_t*)malloc(S*sizeof(cache_set_t));//为组申请空间
cache.sets[i].lines = (cache_line_t*)malloc(E*sizeof(cache_line_t));//为行申请空间
freeCache()函数:为释放空间,根据申请空间的倒序来释放即可。
void replayTrace(char* trace_fn) :此函数基本已经全部给出,主要的就是从trace文件中读取数据,并且调用accessdata函数,操作类型若为 'L'或 'S',则调用一次accessdata,若为 'M' ,则多调用一次accessdata 。 另外在次函数中读取了地址addr之后,可以计算出组索引和标记:
set_index_mask =(addr>>b)&((1<
tag_mask = (addr>>b)>>s; //标记
3.单独介绍最重要的函数 accessdata
accessData - 访问内存地址addr的数据。
1)如果它已经在缓存中,则增加hit_count
2)如果它不在缓存中,请将其放入缓存中,增加错过次数。
3)如果一条线被驱逐,也会增加eviction_count
在函数中实现时,hit发生的情况:组索引找到的某一组,存在一行有效位为1,并且标记匹配。
若不hit ,则直接miss++。
再看是否驱逐,驱逐发生的情况为:组索引找到的某一组,有效位全部为1,此时发生evictions++ ,并且找到lru最小的那一行,驱逐。
另外,每次发生hit 或者只miss或者miss加上eviction ,都需要更新那一行的lru数值,具体的就是该行的lru取到最大,其他所有行的lru减一即可
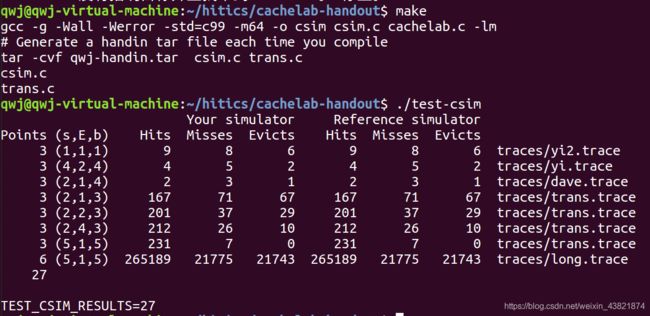
测试用例1的输出截图(5分):
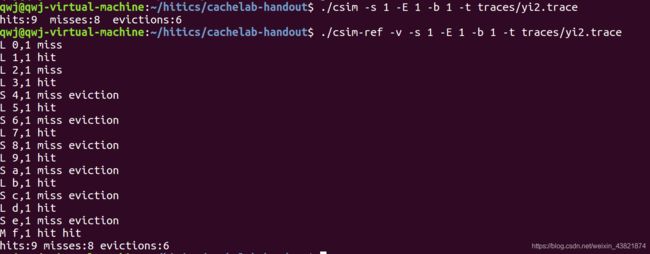
测试用例2的输出截图(5分):
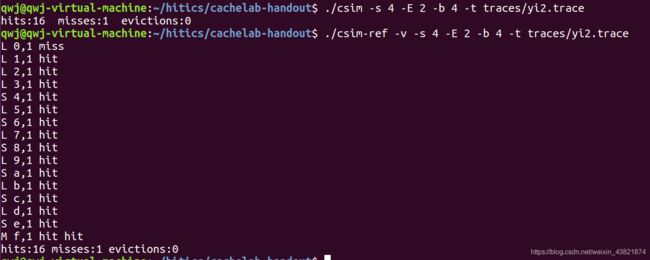
测试用例3的输出截图(5分):

测试用例4的输出截图(5分):
![]()
测试用例5的输出截图(5分):
![]()
测试用例6的输出截图(5分):
![]()
测试用例7的输出截图(5分):
![]()
测试用例8的输出截图(10分):
![]()
注:每个用例的每一指标5分(最后一个用例10)——与参考csim-ref模拟器输出指标相同则判为正确
3.2 矩阵转置设计
提交trans.c
程序设计思想:
如果说实验的cache模拟是冷盘,那么矩阵才是大餐。
首先 。根据ppt的提示,使用模拟的cache对trace[i]中对第i个函数的转置轨迹进行分析,这些访存轨迹文件对帮助调试和理解每一转置函数触发的缓存命中和缺失到底从何而来非常重要。至于为什么不适用 ./csim-ref ,是因为使用自己的模拟缓存,可以自定义函数的输出,打印组索引,标记位等关键信息。
通过对组索引和标记的查看,可以得出:A矩阵和B矩阵相同的下标映射到相同的组中,但是标记不同。这条结论是后面矩阵转置优化的前提。
第一步:32*32 。因为A矩阵和B矩阵中下标相同的元素会映射到一个块中,因此访问两个数组的过程中会发生很多的冲突不命中。因此要减少miss,必须减少冲突不命中。基于这个原因,可以想到,我们可以一次性访问一个块中的多个元素,访问完就不再访问这个块了。
因为cache一个block中可以存8个int数据,因此先考虑8*8将其分块,这样分块的一个更重要的原因是当我将8个int直接取出来,这样即使写入的时候替换了block也没关系,因为我们已经全部读入了。
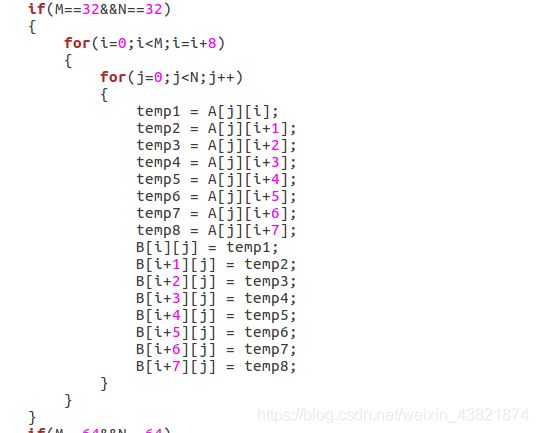
事实上,对于测试出来的287次miss,我们也能有如下的分析:对于A数组而言,每块只有第一个元素miss,这也是无法避免的;对于B数组而言,除了每块第一个元素不命中,矩阵对角线上的元素也会不命中。因此miss位287次依然有优化空间,在此没有展开。
第二步 64*64 。对于64*64的矩阵而言,每一行元素会占8个组,因此4行元素即可占满cache。
我先尝试着和32*32的矩阵相同的分块方法,发现miss总数达到了4000+,基本没什么优化。仔细分析应该有如下的原因:对A数组的访问依然是第一个不命中。对B数组的访问,可以看到前4行和后四行所映射的块是相同的,于是访问完前四行的第一列后,访问后四行的第一列会冲突不命中,导致原来的块被驱逐,再访问前四行的第二列,由于之前的块已经被驱逐,因此又会miss且驱逐,如此反复下去,B数组中所有的元素皆会不命中。
由以上否定了8*8的划分方式。
又因为4*4的分块方式无法充分利用每次加载后的块,故也将其否定。
由此可以想到一个折中的办法,就是将8*8和4*4相结合。
下面用示意图进行表示:
首先将红色块移至目的地,再将黄色块移至红色块左边“暂存”一下。此时移动是伴随着转置的。
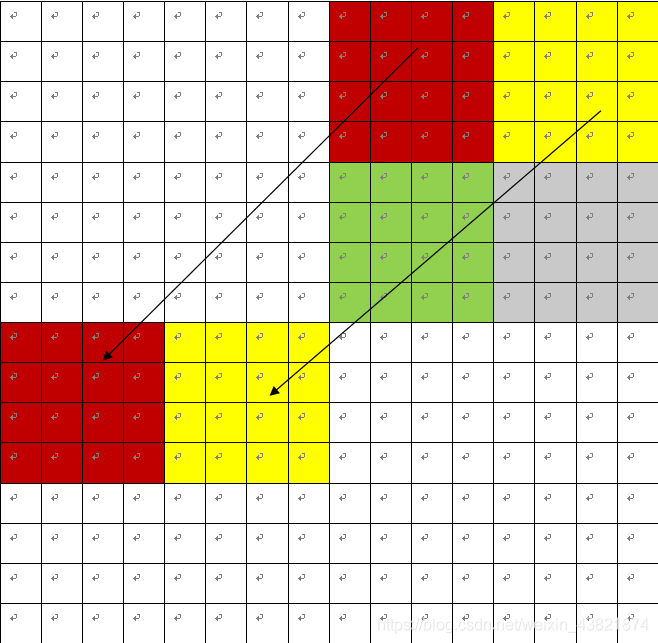
再实现图中的移动即可,将黄色块移到红色块的下面,在将绿色快移到之前“暂存”黄色块的地方,最后将灰色块移动到目的地即可。

根据以上的示意图可以写出如下的过程:

最后 61*67 。对于之前的两个矩阵,由于它们的每一行元素恰好占整数个块,因此分块的时候也会利用这一特性。但是根据之前的处理,由于这个测试的miss数允许到2000,这个限度相对较大,因此我们可以尝试不同的分块来处理即可。因此相当于64*64需要反复优化,这个还是比较好处理的。
根据反复调整分块的大小,发现分成17*17的块时miss数最小,代码如下:

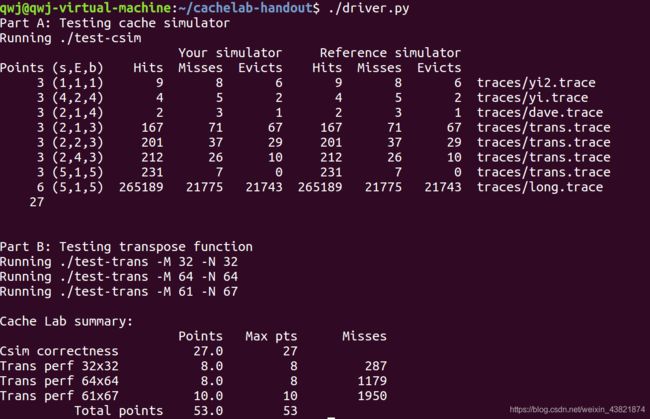
32×32(10分):运行结果截图
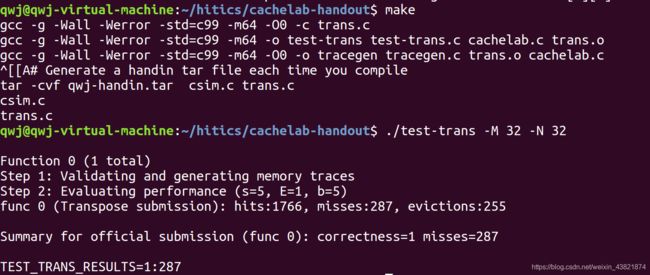
64×64(10分):运行结果截图

61×67(20分):运行结果截图

/*csim.c 源代码*/
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include "cachelab.h"
//#define DEBUG_ON
#define ADDRESS_LENGTH 64
/* Type: Memory address */
typedef unsigned long long int mem_addr_t;
/* Type: Cache line
LRU is a counter used to implement LRU replacement policy */
typedef struct cache_line {
char valid; //有效位
mem_addr_t tag; //标识位
int lru; //最后的访问时间距离现在最远的块
} cache_line_t;
typedef struct
{
cache_line_t *lines;
}cache_set_t; //储存每一组包含的行
typedef struct
{
cache_set_t *sets; //cache的空间,模拟cache
}cache_t;
/* Globals set by command line args */
int verbosity = 0; /* print trace if set */
int s = 0; /* set index bits */
int b = 0; /* block offset bits */
int E = 0; /* associativity */
char* trace_file = NULL;
/* Derived from command line args */
int S; /* number of sets */
int B; /* block size (bytes) */
/* Counters used to record cache statistics */
int miss_count = 0;
int hit_count = 0;
int eviction_count = 0;
unsigned long long int lru_counter = 1;
/* The cache we are simulating */
cache_t cache;
mem_addr_t set_index_mask; //组索引掩码
mem_addr_t tag_mask; //地址标记
/*
* initCache - Allocate memory, write 0's for valid and tag and LRU
* also computes the set_index_mask
initCache - 分配内存,写0表示有效和标记和LRU ,计算set_index_mask
*/
void initCache()
{
int i,j;
if(s<0)
{
printf("set number error!\n");
exit(0);
}
cache.sets = (cache_set_t*)malloc(S*sizeof(cache_set_t));//为组申请空间
if(!cache.sets)
{
printf("No set memory!\n");
exit(0);
}
for(i=0;icache.sets[set_index_mask].lines[j].lru)
{
minlru = cache.sets[set_index_mask].lines[j].lru;
flag = j;
}
}
cache.sets[set_index_mask].lines[flag].valid=1;
cache.sets[set_index_mask].lines[flag].tag = tag_mask;
cache.sets[set_index_mask].lines[flag].lru=lru_counter;
for(k=0;k>b)&((1<>b)>>s; //标记
if(verbosity) //赘言
printf("%c %llx,%u ", buf[1], addr, len);
accessData(addr);
/* If the instruction is R/W then access again */
if(buf[1]=='M')
accessData(addr);
if (verbosity) //赘言
printf("\n");
}
}
fclose(trace_fp);
}
/*
* printUsage - Print usage info
*/
void printUsage(char* argv[])
{
printf("Usage: %s [-hv] -s -E -b -t \n", argv[0]);
printf("Options:\n");
printf(" -h Print this help message.\n");
printf(" -v Optional verbose flag.\n");
printf(" -s Number of set index bits.\n");
printf(" -E Number of lines per set.\n");
printf(" -b Number of block offset bits.\n");
printf(" -t Trace file.\n");
printf("\nExamples:\n");
printf(" linux> %s -s 4 -E 1 -b 4 -t traces/yi.trace\n", argv[0]);
printf(" linux> %s -v -s 8 -E 2 -b 4 -t traces/yi.trace\n", argv[0]);
exit(0);
}
/*
* main - Main routine
*/
int main(int argc, char* argv[])
{
char c;
while( (c=getopt(argc,argv,"s:E:b:t:vh")) != -1){
switch(c){
case 's':
s = atoi(optarg);
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
trace_file = optarg;
break;
case 'v':
verbosity = 1;
break;
case 'h':
printUsage(argv);
exit(0);
default:
printUsage(argv);
exit(1);
}
}
/* Make sure that all required command line args were specified
确保指定了所有必需的命令行参数 */
if (s == 0 || E == 0 || b == 0 || trace_file == NULL) {
printf("%s: Missing required command line argument\n", argv[0]);
printUsage(argv);
exit(1);
}
/* Compute S, E and B from command line args
从命令行参数计算S,E和B. */
S = 1<
以下是矩阵转置trans.c
/*
* trans.c - Matrix transpose B = A^T
*
* Each transpose function must have a prototype of the form:
* void trans(int M, int N, int A[N][M], int B[M][N]);
*
* A transpose function is evaluated by counting the number of misses
* on a 1KB direct mapped cache with a block size of 32 bytes.
转置函数是通过对块大小为32字节的1KB直接映射高速缓存上的未命中次数进行计数来评估的。
*/
#include
#include "cachelab.h"
int is_transpose(int M, int N, int A[N][M], int B[M][N]);
/*
* transpose_submit - This is the solution transpose function that you
* will be graded on for Part B of the assignment. Do not change
* the description string "Transpose submission", as the driver
* searches for that string to identify the transpose function to
* be graded.
trans._submit——这是您将针对作业B部分进行评分的解决方案transpose函数
不要更改描述字符串“Transpose submission”,
因为驱动程序搜索该字符串以标识要分级的转置函数。
*/
char transpose_submit_desc[] = "Transpose submission";
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i,j,k,p,temp1,temp2,temp3,temp4,temp5,temp6,temp7,temp8;
if(M==32&&N==32)
{
for(i=0;i