SpringCloud系列:负载均衡组件-Ribbon
作者平台:
| CSDN:blog.csdn.net/qq_41153943
| 掘金:juejin.cn/user/651387…
| 知乎:www.zhihu.com/people/1024…
| GitHub:github.com/JiangXia-10…
本文一共4529字,预计阅读12分钟
前言
前面几篇文章介绍了微服务相关的内容,比如什么是微服务,常见的一些服务注册中心组件,以及微服务之间是如何进行服务通信的。
在微服务架构中还有常见的一种场景就是服务的负载均衡。今天就一起学习SpringCloud提供的负载均衡组件-Ribbon。
什么是Ribbon
Spring Cloud Ribbon是一个基于http和tcp的客户端负载均衡工具,是基于netflix ribbon实现的,通过Spring Cloud封装, 可以让我们将面向服务的resttemplate请求自动转换成客户端负载均衡的服务调用。
所以Ribbon是SpringCloud提供一套客户端负载均衡组件,提供一系列的完善的配置,如超时,重试等,它有助于控制HTTP和TCP的客户端的行为。通过Load Balancer获取到服务提供的所有机器实例, Ribbon会自动基于某种规则(默认是轮询机制)去调用这些服务。Ribbon也可以实现我们自己的负载均衡算法。

标题Ribbon的负载均衡策略
基于Ribbon方式的负载均衡,Netflix默认提供了七种负载均衡策略,分别是:
1、RoundRobinRule(轮询策略)
轮询策略是Ribbon的默认策略,是按照顺序,依次对所有的服务实例进行访问。比如一共有 3 个服务,第一次调用服务 1,第二次调用服务 2,第三次调用服务3。
2、WeightedResponseTimeRule(权重策略)
权重策略是根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。它的实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大。
3、RetryRule(重试策略)
重试策略指的是按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null。
4、RandomRule(随机策略)
随机策略比较简单就是指从服务提供者的列表中随机选择一个服务实例。
5、BestAvailableRule(最小连接数策略)
最小连接数策略,也叫最小并发数策略,它是指遍历服务提供者列表,选取连接数最小的⼀个服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取。
6、ZoneAvoidanceRule(区域敏感策略)
区域敏感策略是根据服务所在区域的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似。
7、AvailabilityFilteringRule(可用敏感性策略)
可用敏感性策略是先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例。
在ribbon中可以通过下述命令指定负载均衡策略,比如设置RoundRobinRule:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
设置其他策略修改具体的策略名即可。
除此之外还可以自定义负载均衡策略。自定义负载均衡策略,则需要继承com.netflix.loadbalancer.AbstractLoadBalancerRule抽象类。

实战
项目导入spring-cloud-starter-consul-discovery依赖后,包含了ribbon依赖,所以不需要额外导入ribbon依赖。项目是在之前项目的基础上, 可以参考:SpringCloud系列:服务注册中心组件—consul文中的项目。
使用resttemplate+ribbon组件去实现负载均衡,主要有三种方法:
1、使用DiscoveryClient对象
DiscoveryClient是一种服务发现客户端对象,可以用来获取服务注册中心的信息:
@Autowired
private DiscoveryClient discoveryClient;
//创建一个RestTemplate对象
RestTemplate restTemplate = new RestTemplate();
List<ServiceInstance> serviceInstances = discoveryClient.getInstances("orders");
serviceInstances.forEach(serviceInstance -> {
logger.info("服务主机:{};服务地址:{};服务端口:{}",serviceInstance.getHost(),serviceInstance.getUri(),serviceInstance.getPort());
});
String result = restTemplate.getForObject(serviceInstances.get(0).getUri()+"/order/order",String.class);
通过DiscoveryClient的getInstances方法根据服务id去服务注册中心获取对应的服务列表到本地中,但是可以发现这里其实并没有负载均衡,还是需要自己去实现负载均衡,并且服务的访问路径还是需要进行拼接。
2、LoadBalancerClient对象
LoadBalancerClient对象是一种负载均衡客户端对象,也是根据服务id去服务注册中心获取对应的服务列表,并且根据默认的负载均衡策略选择服务列表中的一台机器并返回,所以这里返回的是一个服务,而DiscoveryClient返回的是服务列表:
ServiceInstance serviceInstance = loadBalancerClient.choose("orders");
logger.info("服务主机:{};服务地址:{};服务端口:{}",serviceInstance.getHost(),serviceInstance.getUri(),serviceInstance.getPort());
String result = restTemplate.getForObject(serviceInstance.getUri()+"/order/order",String.class);
可以发现使用LoadBalancerClient时需要每次先根据服务id获取一个负载均衡的机器之后再通过resttemplate调用服务,也较为复杂和繁琐。
3、使用@LoadBalanced注解
@LoadBalanced注解是来自cloud包下的一个注解,这个注解就是让某一个东西拥有负载均衡的能力,该注解主要用在方法上。
比如这里就是让这个RestTemplate在请求时拥有客户端负载均衡的能力。可以这样写在一个配置类中:
@Configuration
public class MyConfig {
@Bean
@LoadBalanced //使其具有负载均衡属性
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
然后在需要进行负载均衡的地方,使用服务名+请求路径即可:
String result = restTemplate.getForObject("http://orders/order/order",String.class);
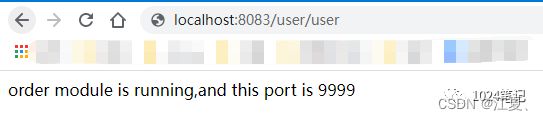
这是如果启动项目,输入:
http://localhost:8083/user/user
并不断刷新,进行请求,则会按照默认的轮询的负载均衡策略依次请求8084和9999端口的请求:

通过上述的代码可以发现,Ribbon是客户端的负载均衡,它实现负载均衡是根据调用服务的服务id去服务注册中心获取对应服务id的服务列表,并将服务列表拉取到本地进行缓存,然后在本地根据负载均衡机制在现有的列表中选择可以可用节点提供服务。
Ribbon是一种客户端的负载均衡,在使用Ribbon的负载均衡中,大致可以分为以下几步:
1、首先拦截请求,并且通过请求中的url地址,截取服务名称 ;
2、通过LoadBalancerClient获取ILoadBalancer;
3、根据服务id在Eureka、consul等服务注册中心中获取服务列表;
4、通过IRule负载均衡策略选择具体服务;
5、ILoadBalancer通过IPing及定时更新机制来维护服务列表;
6、重构该url,并且最终调用HttpURLConnection发起请求。
总结
以上就是springcloud中使用resttemplate+ribbon实现负载均衡的内容。Ribbon是客户端的负载均衡,它实现负载均衡是根据调用服务的服务id去服务注册中心获取对应服务id的服务列表,并将服务列表拉取到本地进行缓存,然后在本地根据负载均衡机制在现有的列表中选择可以可用节点提供服务。
有任何问题或者不正确的地方,欢迎指出,交流讨论!
文章项目源码在:https://github.com/JiangXia-1024/SpringCloudProject。