【论文笔记】K-plet Recurrent Neural Networks for Sequential Recommendation

原文:K-plet Recurrent Neural Networks for Sequential Recommendation
(本文只是略读,所以笔记只记录了主要的思想,更多的细节还需看原文)
背景
-
一般推荐
忽略时间因素,将用户的历史行为表示为一个集合,利用矩阵分解技术获取用户兴趣。
-
序列推荐
主要考虑用户的评分和购买行为
-
马尔科夫链:序列转化为转移图,融合矩阵分解,难以对长期依赖性建模
-
基于循环神经网络的方法: 只对整体结构建模
-
因为循环神经网络(RNN)在序列数据 (文本,语音)的学习中表现很好,故尝试将其用于推荐系统。
RNN只对考虑序列的全局结构,但在推荐系统中,一个好的模型需要对序列的全局结构和局部关系都进行考虑。
所以将近邻序列合并到循环神经网络中,得到新的模型K-plet Recurrent Neural Network,简称 KrNN
序列推荐下的RNN
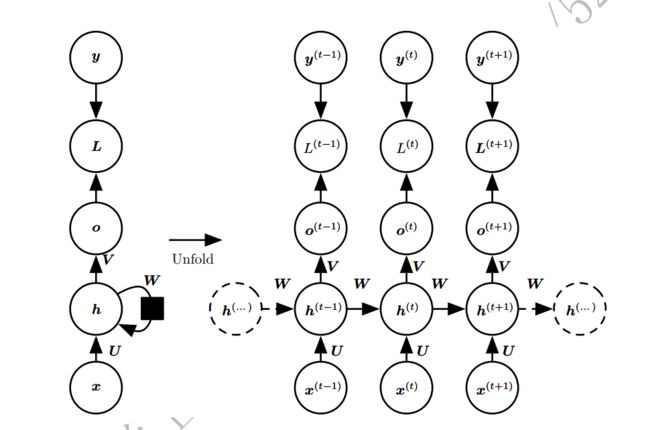
x:输入层
o:输出层
h:隐藏层
U、V、W:权重参数
对于某一个时刻 t t t, h t = f ( U x t + W h t − 1 ) h_t=f(Ux_t+Wh_{t-1}) ht=f(Uxt+Wht−1)
f ( ) f() f()为隐藏层中的激活函数, o t = g ( V h t ) o_t = g(Vh_t) ot=g(Vht)
g ( ) g() g()为输出层中的激活函数,常见的有sigmod、tanh或 relu
从t=1开始不断循环,将全部的过去序列 ( x ( t ) , x ( t − 1 ) , x ( t − 2 ) , … , x ( 2 ) , x ( 1 ) ) (x^{(t)}, x^{(t-1)}, x^{(t-2)},…,x^{(2)},x^{(1)}) (x(t),x(t−1),x(t−2),…,x(2),x(1)) 作为输入来生成当前状态。
几个RNN变体:
Vanilla RNN 最初被用来预测用户希望在博客中播放的下一首歌,之后RNN的变体被用来序列推荐
基于GRU的RNN 用于基于会话的推荐,有两种类型的排名损失函数:BPR 和 TOP1。
DREAM 利用池来总结一次的嵌入的项目,然后输入Vanilla RNN来解决得到下一次推荐。
CRNN 为每个用户u学习一个RNN 参数 F θ u F_{\theta^u} Fθu,在所有用户之间共享 W i W_i Wi和 W p W_p Wp,因此,容易因参数化过度而过拟合。
但是归根结底,RNN及其变体只擅长捕获序列数据中的整体结构
KrNN的主要思路
所以主要解决两个问题:
- 如何通过相似度确定KrNN中的近邻序列
- 如何在序列预测任务中对查询序列和它的邻居之间的交互进行建模
根据序列相似度决定已给定的查询序列的最相近的 k 个近邻序列,将查询序列传入一个RNN,其k个近邻序列传入剩余k个RNN中,k+1个 RNN中共享参数,最终在损失层或输出层对 RNN 建模,这样就建立了KrNN。
在序列预测任务中,假设 若序列的下一个项目是相同的,则两个序列是相似的(传统上一般认为两个相似的输入应该拥有相似的标签)
KrNN-L
基本假设:下一个项目相同的两个用户的上下文序列共享相似的潜在表示。 在此假设下,增加 L s r L_{sr} Lsr来保持项目相似度的局部一致性。
在损失函数中对查询序列与其近邻之间的相似度进行建模,并将这种相似度作为原始损失函数(如交叉熵损失)的正则化,通过优化损失来学习参数。即在损失层引入一种特殊的图正则化,为RNN添加局部信息
KrNN-P
KrNN-P尝试让近邻序列在查询序列的预测功能中起作用
在k-NN的基础上,我们提出一种查询序列及其近邻的网络输出加权和的分类方法:
F ( S ≤ t q , N ≤ t q ) = f θ ( S ≤ t q ) + ∑ S [ max ( 0 , t i − l ) , t i i ∈ N ≤ t q γ q , i f θ ( S [ max ( 0 , t i − l ) , t i ] i ) F\left(S_{\leq t}^{q}, N_{\leq t}^{q}\right)=f_{\theta}(S_{\leq t}^{q})+\sum_{S_{\left[\max \left(0, t_{i}-l\right), t_{i}\right.}^{i} \in N_{\leq t}^{q}} \gamma_{q, i} f_{\theta}\left(S_{\left[\max \left(0, t_{i}-l\right), t_{i}\right]}^{i})\right. F(S≤tq,N≤tq)=fθ(S≤tq)+S[max(0,ti−l),tii∈N≤tq∑γq,ifθ(S[max(0,ti−l),ti]i)
$\gamma_{q, i} $是序列的相似度
实验结果
实验设置
数据集
- Movielens 1M
- Amazonnmovies
基线
- POP UKNN BPRMF
- MC FPMC
- RNN MrRNN
参数调整
作者在10倍验证集上选择最佳参数设置。
(1)BPRMF和FPMC:两者的潜在维度均设置为32,学习率分别为0.05和0.2,两者的采样偏差均为200,σ分别为1和0.01。
(2)UKNN:邻域大小为80。
(3)RNN,MrRNN,KrNN-P和KrNN-L:一层具有50个隐藏单元的LSTM层,学习率设置为0.1,
统一使用adagrad进行优化。 样本大小为7,权衡参数为0.5。
评估指标
- 短期预测:sps (短期预测的目的是预测下一次购买或评级的项目)
- 长期预测:precision、recall、ndcg 和 F1-score。
- 概括:user_average (使用至少收到一个正确建议的用户比例)
实验结果
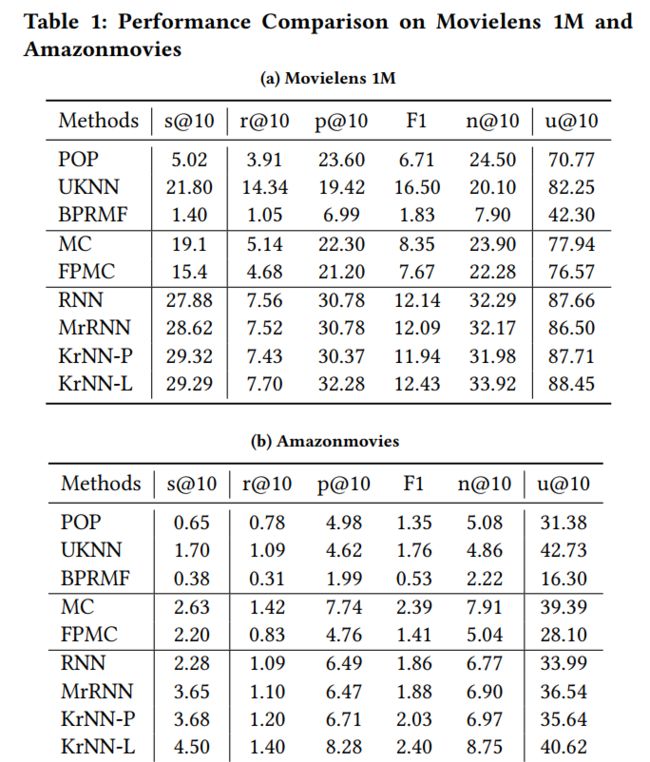
通过表1,可以发现KrNN-P特别是KrNN-L有很大的提升效果
样本量的影响
作者基于一个Nvidia K40m GPU, 在MovieLens 1M上比较了它们之间每个 epoch的训练时间(秒)。
原始RNN的时间为613.58s。 通过表2,我们可以看到样本数量对KrNN效率的影响很大。 但是k不必很大。 作者证明,k = 1足以在两个数据集中获得更好的性能。
