MKDCNet分割模型搭建
原论文:https://arxiv.org/abs/2206.06264v1
源码:https://github.com/nikhilroxtomar/MKDCNet
直接步入正题~~~
一、基础模块
class Conv2D(nn.Module):
def __init__(self, in_c, out_c, kernel_size=3, padding=1, dilation=1, bias=False, act=True):
super().__init__()
self.act = act
self.conv = nn.Sequential(
nn.Conv2d(
in_c, out_c,
kernel_size=kernel_size,
padding=padding,
dilation=dilation,
bias=bias
),
nn.BatchNorm2d(out_c)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.act == True:
x = self.relu(x)
return x
class residual_block(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.network = nn.Sequential(
Conv2D(in_c, out_c),
Conv2D(out_c, out_c, kernel_size=1, padding=0, act=False)
)
self.shortcut = Conv2D(in_c, out_c, kernel_size=1, padding=0, act=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x_init):
x = self.network(x_init)
s = self.shortcut(x_init)
x = self.relu(x+s)
return x
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16): #in_planes=96
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): #2,96,128,128
# 2,96,128,128 -> 2,96,1,1 -> 2,6,1,1 -> 2,96,1,1
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
# 2,96,128,128 -> 2,96,1,1 -> 2,6,1,1 -> 2,96,1,1
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out #2,96,1,1
return self.sigmoid(out)二、ChannelAttention和SpatialAttention
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16): #in_planes=96
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): #2,96,128,128
# 2,96,128,128 -> 2,96,1,1 -> 2,6,1,1 -> 2,96,1,1
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
# 2,96,128,128 -> 2,96,1,1 -> 2,6,1,1 -> 2,96,1,1
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out #2,96,1,1
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): #2,96,128,128
avg_out = torch.mean(x, dim=1, keepdim=True) #2,1,128,128
max_out, _ = torch.max(x, dim=1, keepdim=True) #2,1,128,128
x = torch.cat([avg_out, max_out], dim=1) #2,2,128,128
x = self.conv1(x) #2,1,128,128
return self.sigmoid(x)三、encoder模块
class encoder(nn.Module):
def __init__(self, ch):
super().__init__()
""" ResNet50 """
backbone = resnet50()
self.layer0 = nn.Sequential(backbone.conv1, backbone.bn1, backbone.relu)
self.layer1 = nn.Sequential(backbone.maxpool, backbone.layer1)
self.layer2 = backbone.layer2
self.layer3 = backbone.layer3
""" Reduce feature channels """
self.c1 = Conv2D(64, ch)
self.c2 = Conv2D(256, ch)
self.c3 = Conv2D(512, ch)
self.c4 = Conv2D(1024, ch)
def forward(self, x):
""" Backbone: ResNet50 """
x0 = x
x1 = self.layer0(x0) ## [-1, 64, h/2, w/2] 2,64,128,128
x2 = self.layer1(x1) ## [-1, 256, h/4, w/4] 2,256,64,64
x3 = self.layer2(x2) ## [-1, 512, h/8, w/8] 2,512,32,32
x4 = self.layer3(x3) ## [-1, 1024, h/16, w/16] 2,1024,16,16
c1 = self.c1(x1) #2,96,128,128
c2 = self.c2(x2) #2,96,64,64
c3 = self.c3(x3) #2,96,32,32
c4 = self.c4(x4) #2,96,16,16
return c1, c2, c3, c4四、MKDC模块
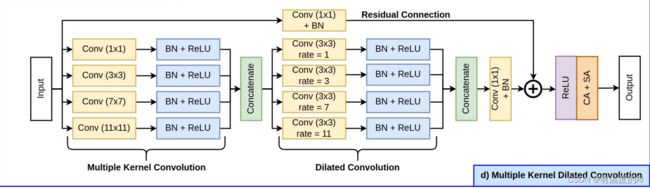
class multikernel_dilated_conv(nn.Module):
def __init__(self, in_c, out_c): #in_c=96, out_c=96
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.c1 = Conv2D(in_c, out_c, kernel_size=1, padding=0)
self.c2 = Conv2D(in_c, out_c, kernel_size=3, padding=1)
self.c3 = Conv2D(in_c, out_c, kernel_size=7, padding=3)
self.c4 = Conv2D(in_c, out_c, kernel_size=11, padding=5)
self.s1 = Conv2D(out_c*4, out_c, kernel_size=1, padding=0)
self.d1 = Conv2D(out_c, out_c, kernel_size=3, padding=1, dilation=1)
self.d2 = Conv2D(out_c, out_c, kernel_size=3, padding=3, dilation=3)
self.d3 = Conv2D(out_c, out_c, kernel_size=3, padding=7, dilation=7)
self.d4 = Conv2D(out_c, out_c, kernel_size=3, padding=11, dilation=11)
self.s2 = Conv2D(out_c*4, out_c, kernel_size=1, padding=0, act=False)
self.s3 = Conv2D(in_c, out_c, kernel_size=1, padding=0, act=False)
self.ca = ChannelAttention(out_c)
self.sa = SpatialAttention()
def forward(self, x): #假设x.shape [2,96,128,128]
x0 = x
x1 = self.c1(x) #2,96,128,128
x2 = self.c2(x) #2,96,128,128
x3 = self.c3(x) #2,96,128,128
x4 = self.c4(x) #2,96,128,128
x = torch.cat([x1, x2, x3, x4], axis=1) #2,96*4,128,128
x = self.s1(x) #2,96,128,128
x1 = self.d1(x) #2,96,128,128
x2 = self.d2(x) #2,96,128,128
x3 = self.d3(x) #2,96,128,128
x4 = self.d4(x) #2,96,128,128
x = torch.cat([x1, x2, x3, x4], axis=1) #2,96*4,128,128
x = self.s2(x) #2,96,128,128
s = self.s3(x0) #2,96,128,128
x = self.relu(x+s) #2,96,128,128
# 2,96,1,1 -> 2,96,128,128
x = x * self.ca(x)
# 2,1,128,128 -> 2,96,128,128
x = x * self.sa(x)
return x #2,96,128,128五、MFF模块
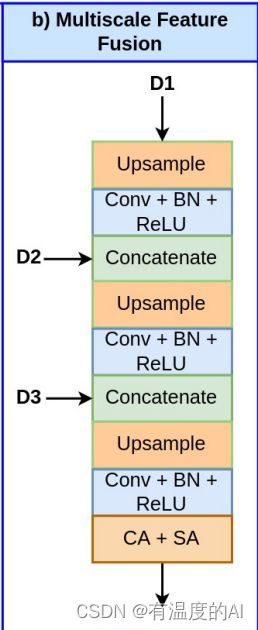
class multiscale_feature_fusion(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.up_2 = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.c1 = Conv2D(in_c, out_c)
self.c2 = Conv2D(out_c+in_c, out_c)
self.c3 = Conv2D(in_c, out_c)
self.c4 = Conv2D(out_c+in_c, out_c)
self.ca = ChannelAttention(out_c)
self.sa = SpatialAttention()
def forward(self, f1, f2, f3): #f1:2,96,32,32, f2:2,96,64,64, f3:2,96,128,128
x1 = self.up_2(f1) #2,96,64,64
x1 = self.c1(x1) #2,96,64,64
x1 = torch.cat([x1, f2], axis=1) #2,192,64,64
x1 = self.up_2(x1) #2,192,128,128
x1 = self.c2(x1) #2,96,128,128
x1 = torch.cat([x1, f3], axis=1) #2,192,128,128
x1 = self.up_2(x1) #2,192,256,256
x1 = self.c4(x1) #2,96,256,256
x1 = x1 * self.ca(x1) #2,96,256,256
x1 = x1 * self.sa(x1) #2,96,256,256
return x1六、decoder模块
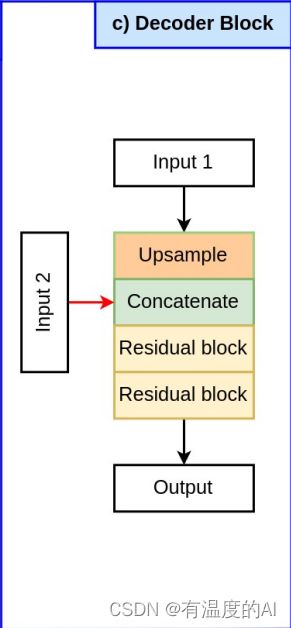
class decoder_block(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.r1 = residual_block(in_c[0]+in_c[1], out_c)
self.r2 = residual_block(out_c, out_c)
def forward(self, x, s): #假设 x:2,96,16,16 s:2,96,32,32
x = self.up(x) #2,96,32,32
x = torch.cat([x, s], axis=1) #2,192,32,32
x = self.r1(x) #2,96,32,32
x = self.r2(x) #2,96,32,32
return x七、整体网络结构
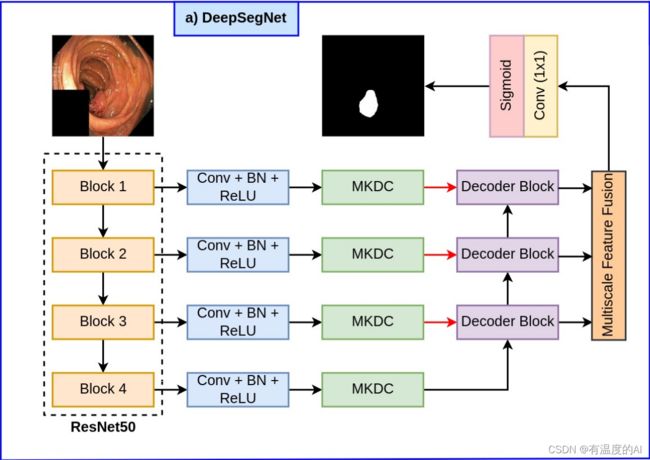
class DeepSegNet(nn.Module):
def __init__(self):
super().__init__()
""" Encoder """
self.encoder = encoder(96)
""" MultiKernel Conv + Dilation """
self.c1 = multikernel_dilated_conv(96, 96)
self.c2 = multikernel_dilated_conv(96, 96)
self.c3 = multikernel_dilated_conv(96, 96)
self.c4 = multikernel_dilated_conv(96, 96)
""" Decoder """
self.d1 = decoder_block([96, 96], 96)
self.d2 = decoder_block([96, 96], 96)
self.d3 = decoder_block([96, 96], 96)
""" Multiscale Feature Fusion """
self.msf = multiscale_feature_fusion(96, 96)
""" Output """
self.y = nn.Conv2d(96, 1, kernel_size=1, padding=0)
def forward(self, image): #image:2, 3, 256, 256
s0 = image
s1, s2, s3, s4 = self.encoder(image)
x1 = self.c1(s1)
x2 = self.c2(s2)
x3 = self.c3(s3)
x4 = self.c4(s4)
d1 = self.d1(x4, x3)
d2 = self.d2(d1, x2)
d3 = self.d3(d2, x1)
x = self.msf(d1, d2, d3)
y = self.y(x)
return y