Django框架之DRF框架
文章目录
- 一、前言
-
- 1、Web应用模式
- 2、RESTful API规范
- 二、简介
- 三、安装与配置
- 四、序列化器
-
- 1、创建序列化器
- 2、序列化操作
-
- 1)序列化过程
- 2)反序列化过程
- 3、校验规则
-
- 1)单表字段校验
- 2)关联字段校验
- 4、优化serializer.save()
- 5、to_internal_value
- 6、to_representation
- 五、模型序列化器类
-
- 1、定义模型序列化器类
- 2、修改部分字段方法
- 3、模型器类重写creat/update
- 六、视图层views
-
- 1、APIView渲染器
- 2、解析器
- 3、渲染器
- 4、GenericAPIView
-
- 1)queryset和serializer_class
- 2)get_object
- 3)过滤
- 4)排序
- 4)分页
- 4)总结
- 5、Mixin拓展类
-
- 1)ListModelMixin
- 2)CreateModelMixin
- 3)RetrieveModelMixin
- 4)UpdateModelMixin
- 5)DestroyModelMixin
- 6、类视图
- 7、视图集
-
- 1)前言
- 2)ViewSet
- 3)GenericViewSet
- 4)ModelViewSet和ReadOnlyModelViewSet类
- 5)重写父类方法
- 6)类视图原则
- 7)自定义action
- 7)routers自动生成路由条目
- 七、API接口文档
-
- 1、coreapi
- 2、drf_yasg
- 3、接口文档注解
- 八、日志器
- 九、认证器
-
- 1、session认证
- 2、token认证
- 十、跨域问题
一、前言
在讲DRF框架之前先简单了解一下下面内容:
1、Web应用模式
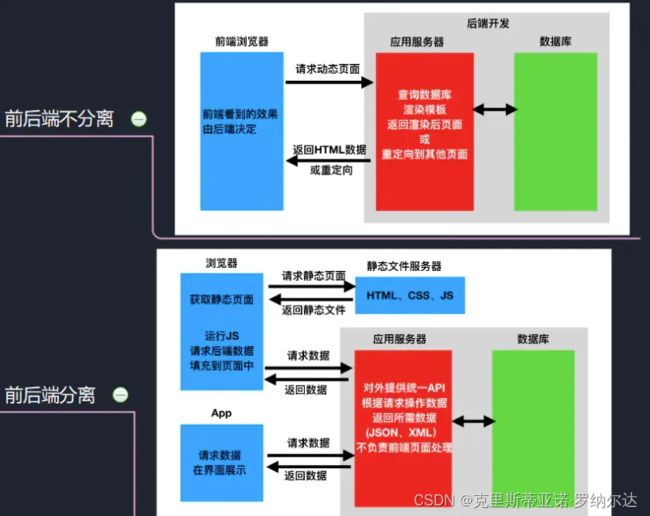
在WEB开发应用中,有2种应用模式:前后端不分离、前后端分离;
2、RESTful API规范
RESTful API通常根据 GET/POST/PUT/DELETE 来区分操作资源的动作,是一种风格,而不是一种约束和规约
统一接口:
GET(SELECT):从服务器查询,可以在服务器通过请求的参数区分查询的方式。
POST(CREATE):在服务器新建一个资源,调用insert操作。
PUT(UPDATE):在服务器更新资源,调用update操作。
PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。(目前jdk7未实现,tomcat7也不行)。
DELETE(DELETE):从服务器删除资源,调用delete语句。
状态码和返回数据:
主要分为五大类:
1xx:相关信息
2xx:操作成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误
如果当前url是 http://localhost:8080/User
那么用户只要请求这样同一个URL就可以实现不同的增删改查操作,例如
http://localhost:8080/User?_method=get&id=1001 这样就可以通过get请求获取到数据库 user 表里面 id=1001 的用户信息
http://localhost:8080/User?_method=post&id=1001&name=zhangsan 这样可以向数据库 user 表里面插入一条记录
http://localhost:8080/User?_method=put&id=1001&name=lisi 这样可以将 user表里面 id=1001 的用户名改为lisi
http://localhost:8080/User?_method=delete&id=1001 这样用于将数据库 user 表里面的id=1001 的信息删除
这样定义的规范我们就可以称之为restful风格的API接口,我们可以通过同一个url来实现各种操作。
二、简介
DRF框架全称是:Django REST framework,它建立在Django基础之上的WEB应用开发框架,基于前后端分离的开发模式,可以快速的开发REST API接口应用;
在REST framework中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST framework还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework提供了一个API 的Web可视化界面来方便查看测试接口。
特点:
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;[jwt]
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
使用DRF框架的优势:
在使用Django写接口代码时,会有很多痛点:
a.代码冗余非常严重,不够简洁
b.数据校验极为麻烦(往往需要嵌套多级if条件语句),校验逻辑的复用性较差
c.代码没有统一的规范,代码维护性较差
d.获取项目列表数据时,有很多功能缺失
- 没有提供分页功能
- 没有提供过滤功能
- 也没有提供排序功能
e.整个项目的痛点
- 没有提供认证授权功能
- 没有提供限流功能
- 传递参数形式单一,只支持json格式的参数,不支持x-www-form-urlencoded
- 5个接口无法放在同一个类视图中
然而,django restframwork框架解决以上问题
官方文档:https://www.django-rest-framework.org/
三、安装与配置
安装:
pip install djangorestframework
添加rest_framework应用:
在settings.py的INSTALLED_APPS中添加’rest_framework’。
INSTALLED_APPS = [
...
'rest_framework',
]
四、序列化器
DRF框架中实现序列化、反列化、数据操作;
序列化与反列化的定义:
序列化:如果前端是GET请求,则构造查询集,将结果返回,这个过程为序列化;
反序列化:如果前端是POST请求,要对数据库进行改动,则需要拿到前端发来的数据,进行校验,校验通过将数据写入数据库,这个过程称为反序列化;
1、创建序列化器
在子应用中创建serializers.py文件,文件名推荐命名为serializers.py;
class ProjectSerializer(serializers.Serializer):
# id = serializers.IntegerField(label='项目id', help_text='项目id', max_value=1000, min_value=1)
# name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5, write_only=True)
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5)
# leader = serializers.CharField(label='项目负责人', help_text='项目负责人', allow_null=True)
leader = serializers.CharField(label='项目负责人', help_text='项目负责人', default='阿名')
is_execute = serializers.BooleanField()
# update_time = serializers.DateTimeField()
注意点:
1.必须得继承Serializer类或者Serializer子类
2.定义的序列化器类中,字段名要与模型类中的字段名保持一致;
3.定义的序列化器类的字段(类属性)为Field子类
4.默认定义哪些字段,那么哪些字段就会返回前端,同时也必须的输入(前端需要传递)
5.常用的序列化器字段类型
IntegerField -> int
CharField -> str
BooleanField -> bool
DateTimeField -> datetime
6.可以在序列化器字段中指定不同的选项
label和help_text,与模型类中的verbose_name和help_text参数一样
IntegerField,可以使用max_value指定最大值,min_value指定最小值
CharField,可以使用max_length指定最大长度,min_length指定最小长度,error_messages用来自定义错误信息
7.定义的序列化器字段中,required默认为True,说明默认定义的字段必须得输入和输出
8.如果在序列化器字段中,设置required=False,那么前端用户可以不传递该字段(校验时会忽略改该字段,所以不会报错)
9.如果未定义模型类中的某个字段,那么该字段不会输入,也不会输出
10.前端必须的输入(反序列化输入)name(必须得校验),但是不会需要输出(序列化器输出)?
如果某个参数指定了write_only=True,那么该字段仅仅只输入(反序列化输入,做数据校验),不会输出(序列化器输出),
默认write_only为False
11.前端可以不用传递,但是后端需要输出?
如果某个参数指定了read_only=True,那么该字段仅仅只输出(序列化器输出),不会输入(反序列化输入,做数据校验),
默认read_only为False
12.在序列化器类中定义的字段,默认allow_null=False,该字段不允许传递null空值,如果指定allow_null=True,那么该字段允许传递null;
13.在序列化器类中定义CharField字段,默认allow_blank=False,该字段不允许传递空字符串,如果指定allow_blank=True,那么该字段允许传递空字符串
14.在序列化器类中定义的字段,可以使用default参数来指定默认值,如果指定了default参数,那么前端用户可以不用传递,会将default指定的值作为入参
2、序列化操作
1)序列化过程
get请求(数据查询):数据库操作(读取所有项目数据) -> 序列化输出操作(将模型对象转化为Python中的基本类型),可以使用序列化器进行序列化输出操作:
- 创建序列化器对象
- 可以将模型对象或者查询集对象、普通对象、嵌套普通对象的列表,以instance关键字来传递参数(instance关键字可以做序列化输出,而若使用data关键字,则必须要校验,否则报错data keyword argument you must call .is_valid()
- 如果传递的是查询集对象、嵌套普通对象的列表(多条数据),必须得设置many=True
- 如果传递的是模型对象、普通对象,不需要设置many=True
- 可以使用序列化器对象的.data属性,获取序列化器之后的数据(字典、嵌套字典的列表)
def get(self, request):
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True)
return JsonResponse(serializer.data, safe=False)
2)反序列化过程
post请求(数据插入):数据校验(规范传入的参数) —> 反序列化输入操作(将json格式的数据转化为复杂的类型) -> 数据库操作(创建项目数据)-> 序列化输出操作(将模型对象转化为Python中的基本类型):
- 定义序列化器类,使用data关键字参数传递字典参数
- 可以使用序列化器对象调用.is_valid()方法,才会开始对前端输入的参数进行校验
- 如果校验通过.is_valid()方法返回True,否则返回False
- 如果调用.is_valid()方法,添加raise_exeception=True,校验不通过会抛出异常,否则不会抛出异常
- 只有在调用.is_valid()方法之后,才可以使用序列化器对象调用.errors属性,来获取错误提示信息(字典类型)
- 只有在调用.is_valid()方法之后,才可以使用序列化器对象调用.validated_data属性,来获取校验通过之后的数据,与使用json.load转化之后的数据有区别
# views.py
class ProjectsView(View):
def post(self, request):
try:
python_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer11 = ProjectSerilizer(data=python_data)
# 校验数据
if not serializer11.is_valid():
return JsonResponse(serializer11.errors, status=400)
# project_obj = Projects.objects.create(**serializer11.validated_data)
serializer11.save()
return JsonResponse(serializer11.data, status=201)
注意:
return JsonResponse(serializer11.data, status=201)serializer11.data这种写法是在两个前提下,否则会报错:
- 如果没有调用save方法,使用创建序列化器对象.data属性时,必须得调用is_valid()方法通过之后,来获取序列化输出的数据;(会把validated_data数据作为输入源,参照序列化器字段的定义来进行输入)
- 如果调用了save方法,使用创建序列化器对象.data属性,来获取序列化输出的数据;(会把create方法返回的模型对象数据作为输入源,参照序列化器字段的定义来进行输出)
3、校验规则
反序列化过程会对数据进行校验
1)单表字段校验
校验顺序:对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法 -> 调用多字段联合校验方法validate方法
from rest_framework import serializers
from rest_framework.validators import UniqueValidator
from interfaces.models import Interfaces
from .models import Projects
# 类外函数
def is_contains_keyword(value):
if '项目' not in value:
raise serializers.ValidationError('项目名称中必须得包含“项目”关键字')
class ProjectSerilizer(serializers.Serializer):
# 1、对字段类型进行校验
# 2、依次验证validators列表中的校验规则,validators=[UniqueValidator(queryset=Projects.objects.all())]
# 3、从右到左依次验证其他规则 max_length=20, min_length=5...等
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,
error_messages={
'min_length': '项目名称不能少于5位',
'max_length': '项目名称不能超过20位'
}, validators=[UniqueValidator(queryset=Projects.objects.all(), message='项目名称不能重复'),
is_contains_keyword])
leader = serializers.CharField(label='项目负责人', help_text='项目负责人', default='阿名')
is_execute = serializers.BooleanField()
# 调用单字段校验方法
# 单字段校验
def validate_name(self, attr: str):
if not attr.endswith('项目'):
raise serializers.ValidationError('项目名称必须得以“项目”结尾')
return attr
# 调用多字段校验方法
# 多字段联合校验
def validate(self, attrs: dict):
if len(attrs.get('leader')) <= 4 or not attrs.get('is_execute'):
raise serializers.ValidationError('项目负责人名称长度不能少于4位或者is_execute参数为False')
return attrs
以上代码为例的校验顺序为:
- 字段类型校验:CharField/IntegerFieldBooleanField等Field子类的字段校验;
- validators关键字校验,先校验UniqueValidator唯一性,再通过类外自定义的函数is_contains_keyword校验名字中是否包含项目名称
1)可以在序列化器字段上使用validators指定自定义的校验规则
2)validators必须得为序列类型(列表),在列表中可以添加多个校验规则
3)DRF框架自带UniqueValidator校验器,必须得使用queryset指定查询集对象,用于对该字段进行校验
4)UniqueValidator校验器,可以使用message指定自定义报错信息
5)类外自定义校验函数is_contains_keyword,可以在类外自定义校验函数- 第一个参数为待校验的值
- 如果校验不通过,必须得抛出serializers.ValidationError(‘报错信息’)异常,同时可以指定具体的报错信息
- 需要将校验函数名放置到validators列表中
- 从右到左依次验证其他规则,先min_length,再max_length,其中error_messages中为自定义的错误提示信息,error_messages具体用法:
1)可以任意序列化器字段上使用error_messages来自定义错误提示信息;
2)使用校验选项名(校验方法名)作为key,把具体的错误提示信息作为value;
3)DateTimeField可以使用format参数指定格式化字符串,update_time =serializers.DateTimeField(label=‘更新时间’,format=‘%Y年%m月%d日 %H:%M:%S’) - 然后单字段校验validate_name,单字段校验使用如下:
1)可以在序列化器类中对单个字段进行校验;
2)单字段的校验方法名称,必须把validate_作为前缀,加上待校验的字段名,如:validate_待校验的字段名;
3)如果校验不通过,必须得返回serializers.ValidationError(‘具体报错信息’)异常;
4)如果校验通过,往往需要将校验之后的值,返回;
5)如果该字段在定义时添加的校验规则不通过,那么是不会调用单字段的校验方法; - 多字段联合校验方法validate方法
1)可以在序列化器类中对多个字段进行联合校验;
2)使用固定的validate方法,会接收上面校验通过之后的字典数据;
3)当所有字段定义时添加的校验规则都通过,且每个字段的单字段校验方法通过的情况下,才会调用validate;
2)关联字段校验
PrimaryKeyRelatedField字段:
# interfaces_set = serializers.PrimaryKeyRelatedField(label='项目所属接口id', help_text='项目所属接口id', many=True, read_only=True)
interfaces_set = serializers.PrimaryKeyRelatedField(label='项目所属接口id', help_text='项目所属接口id',many=True, queryset=Interfaces.objects.all(), write_only=True)
- 可以定义PrimaryKeyRelatedField来获取关联表的外键值
- 如果通过父表获取从表数据,默认需要使用从表模型类名小写_set作为序列化器类中的关联字段名称(interfaces_set)
- 如果在定义模型类的外键字段时,指定了realated_name参数,那么会把realated_name参数名作为序列化器类中的关联字段名称
- PrimaryKeyRelatedField字段,要么指定read_only=True,要么指定queryset参数,否则会报错
- 如果指定了read_only=True,那么该字段仅序列化输出
- 如果指定了queryset参数(关联表的查询集对象),用于对参数进行校验
- 如果关联字段有多个值,那么必须添加many=True,一般父表获取从表数据时,关联字段需要指定
StringRelatedField字段:
interfaces_set = serializers.StringRelatedField(many=True)
- 使用StringRelatedField字段,将关联字段模型类中的__str__方法的返回值作为该字段的值
- StringRelatedField字段默认添加了read_only=True,该字段仅序列化输出
SlugRelatedField字段:
interfaces_set = serializers.SlugRelatedField(slug_field='name', many=True, queryset=Interfaces.objects.all())
- 使用SlugRelatedField字段,将关联模型类中的某个字段,作为该字段的值
- 如果指定了read_only=True,那么该字段仅序列化输出
- 如果该字段需要进行反序列化输入,那么必须得指定queryset参数,同时关联字段必须有唯一约束
4、优化serializer.save()
创建数据create
# views.py
serializer11 = ProjectSerilizer(data=python_data)
serializer11.save()
# 调用save方法时会自动调用serializers.py中的create方法
#---分隔线----
# serializers.py
class ProjectSerializer(serializers.Serializer):
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,
error_messages={"min_length": "最短不能少于5位"},
validators=[UniqueValidator(queryset=Projects.objects.all(), message="项目名称不能重复"),
is_contains_keyword])
leader = serializers.CharField(label='项目负责人', help_text='项目负责人')
is_execute = serializers.BooleanField(write_only=True)
def create(self, validated_data):
myname = validated_data.pop('myname')
myage = validated_data.pop('myage')
validated_data.pop('sms_code')
project_obj = Projects.objects.create(**validated_data)
return project_obj
- 如果在创建序列化器对象时,仅传递data参数,使用序列化器对象调用save方法时,会自动调用序列化器类中的create方法
- create方法用于对数据进行创建操作
- 序列化器类中的create方法,validated_data参数为校验通过之后的数据(一般字典类型)
- 在调用save方法时,可以传递任意的关键字参数,并且会自动合并到validated_data字典中
- create方法一般需要将创建成功之后模型对象返回
更新数据update
def put(self, request, pk):
try:
project_obj = Projects.objects.get(id=pk)
python_data = json.loads(request.body)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer = ProjectSerilizer(instance=project_obj, data=python_data)
if not serializer.is_valid():
return JsonResponse(serializer.errors, status=400)
serializer.save()
return JsonResponse(serializer.data, status=201)
def update(self, instance, validated_data: dict):
# for key, value in validated_data.items():
# setattr(instance, key, value)
instance.name = validated_data.get('name') or instance.name
instance.leader = validated_data.get('leader') or instance.leader
instance.is_execute = validated_data.get('is_execute') or instance.is_execute
instance.desc = validated_data.get('desc') or instance.desc
instance.save()
return instance
- 如果在创建序列化器对象时,同时instance和data参数,使用序列化器对象调用save方法时,会自动调用序列化器类中的update方法
- update方法用于对数据进行更新操作
- 序列化器类中的update方法,instance参数为待更新的模型对象,validated_data参数为校验通过之后的数据(一般字典类型)
- 在调用save方法时,可以传递任意的关键字参数,并且会自动合并到validated_data字典中
- update方法一般需要将更新成功之后模型对象返回
5、to_internal_value
允许改变我们反序列化的输出,处理反序列化的输入数据
class ProjectSerilizer(serializers.Serializer):
def to_internal_value(self, data):
# 1、to_internal_value方法,是所有字段开始进行校验时入口方法(最先调用的方法)
# 2、会依次对序列化器类的各个序列化器字段进行校验:
# 对字段类型进行校验 -> 依次验证validators列表中的校验规则 -> 从右到左依次验证其他规则 -> 调用单字段校验方法
# to_internal_value调用结束 -> 调用多字段联合校验方法validate方法
tmp = super().to_internal_value(data)
# 对各个单字段校验结束之后的数据进行修改
return tmp
6、to_representation
允许我们改变序列化的输出;
class ProjectSerilizer(serializers.Serializer):
def to_representation(self, instance):
# 1、to_representation方法,是所有字段开始进行序列化输出时的入口方法(最先调用的方法)
tmp =super().to_representation(instance)
return tmp
五、模型序列化器类
模型类序列化器ModelSerilizer,跟表模型有对应关系
1、定义模型序列化器类
class ProjectModelSerializer(serializers.ModelSerializer):
"""
定义模型序列化器类
1、继承serializers.ModelSerializer类或者其子类
2、需要在Meta内部类中指定model、fields、exclude类属性参数
3、model指定模型类(需要生成序列化器的模型类)
4、fields指定模型类中哪些字段需要自动生成序列化器字段
5、会给id主键、指定了auto_now_add或者auto_now参数的DateTimeField字段,添加read_only=True,仅仅只进行序列化输出
6、有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验
class Meta:
model = Projects
# fields指定模型类中哪些字段需要自动生成序列化器字段
# a.如果指定为"__all__",那么模型类中所有的字段都需要自动转化为序列化器字段
# b.可以传递需要转化为序列化器字段的模型字段名元组
# c.fields元组中必须指定进行序列化或者反序列化操作的所有字段名称,指定了'__all__'和exclude除外
fields = "__all__"
# fields = ('id', 'name', 'leader')
# c.exclude指定模型类中哪些字段不需要转化为序列化器字段,其他的字段都需要转化
# exclude = ('create_time', 'update_time')
tips:主动查看生成的字段方法:然后到terminal下执行 python manage.py shell,然后执行from projects.serializers import ProjectsModelSerializer,然后执行ProjectsModelSerializer();
2、修改部分字段方法
方式一:
- 重新定义模型类中同名的字段
- 自定义字段的优先级会更高(会覆盖自动生成的序列化器字段);
# 重新定义模型类中同名的字段
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,error_messages={'min_length': '项目名称不能少于5位','max_length': '项目名称不能超过20位'}, validators=[UniqueValidator(queryset=Projects.objects.all(),message='项目名称不能重复'), is_contains_keyword])
interfaces_set = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
# 新定义的字段,只做序列化输出,输入时不会校验;
token = serializers.CharField(read_only=True)
方式二:
- 如果自动生成的序列化器字段,只有少量不满足要求,可以在Meta中extra_kwargs字典进行微调
- 将需要调整的字段作为key,把具体需要修改的内容字典作为value
# 重新定义模型类中同名的字段
name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=5,error_messages={'min_length': '项目名称不能少于5位','max_length': '项目名称不能超过20位'}, validators=[UniqueValidator(queryset=Projects.objects.all(),message='项目名称不能重复'), is_contains_keyword])
interfaces_set = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
# 新定义的字段,只做序列化输出,输入时不会校验;
token = serializers.CharField(read_only=True)
extra_kwargs = {
'leader': {
'label': '负责人',
'max_length': 15,
'min_length': 2,
# 'read_only': True
# 'validators': []},
'name': {'min_length': 5}}
# 可以将需要批量需要设置read_only=True参数的字段名添加到Meta中read_only_fields元组
read_only_fields = ('leader', 'is_execute', 'id')
3、模型器类重写creat/update
def create(self, validated_data):
"""
a.继承ModelSerializer之后,ModelSerializer中实现了create和update方法
b.一般无需再次定义create和update方法
c.如果父类提供的create和update方法不满足需要时,可以重写create和update方法,最后再调用父类的create和update方法
:param validated_data:
:return:
"""
validated_data.pop('myname')
validated_data.pop('myage')
instance = super().create(validated_data)
instance.token = "xxxxxxx"
return instance
六、视图层views
1、APIView渲染器
class ProjectsView(APIView):
"""
继承APIView父类(Django中View的子类)
a.具备View的所有特性
b.提供了认证、授权、限流功能
"""
def get(self, request):
queryset = Projects.objects.all()
serializer = ProjectSerilizer(instance=queryset, many=True)
# 在DRF中Response为HTTPResponse的子类
# a.data参数为序列化之后的数据(一般为字典或嵌套字典的列表)
# b.会自动根据渲染器来将数据转化为请求头中Accept需要的格式进行返回
# c.status指定响应状态码
# d.content_type指定响应头中的Content-Type,一般无需指定,会根据渲染器来自动设置
return Response(serializer.data, status=status.HTTP_200_OK, content_type='ap')
def post(self, request):
# a.一旦继承APIView之后,request是DRF中Request对象
# b.Request是在HttpRequest基础上做了拓展
# c.兼容HttpRequest的所有功能
# d.前端传递的查询字符串参数:GET、query_params
# e.前端传递application/json、application/x-www-form-urlencoded、multipart/form-data参数
# 可以根据请求头中Content-Type,使用统一的data属性获取
# try:
# python_data = json.loads(request.body)
# except Exception as e:
# return JsonResponse({'msg': '参数有误'}, status=400)
# python_data = request.data
serializer = ProjectModelSerializer(data=request.data)
# if not serializer.is_valid():
# # return JsonResponse(serializer11.errors, status=400)
# return Response(serializer.errors, status=400)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
2、解析器
parsers=self.get_parsers()就是解析模块源码的入口
解析器和渲染器类的修改
# DRF中的解析器(类)
# 1、可以根据请求头中的Content-Type来自动解析参数,使用统一的data属性来获取即可
# 2、默认JSONParser、FormParser、MultiPartParser三个解析器类
# JSONParser:media_type = 'application/json'
# FormParser:media_type = 'application/x-www-form-urlencoded'
# MultiPartParser: media_type = 'multipart/form-data'
# 3、可以在全局配置文件(settings.py)中修改DRF全局参数,把REST_FRAMEWORK作为名称
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser',
# 'rest_framework.parsers.FormParser',
# 'rest_framework.parsers.MultiPartParser'
],
# 4、局部配置
# 默认全局配置是因为我们写的视图继承自APIView,APIView中配置了类属性parser_classes,所以我们自己编写的视图函数中,也设置个类属性,并且导入JSONParser解析器
from rest_framework.parsers import JSONParser
class TestView(APIView):
# 局部解析类配置,只加JSONParser配置后,就只能application/json提交数据,其他方式会报错
parser_classes = [JSONParser]
def post(self, request, *args, **kwargs):
print(request.data)
return Response("drf post ok")
3、渲染器
# DRF中的渲染器(类)
# 1、可以根据请求头中的Accept参数来自动渲染前端需要的数据格式
# 2、默认的渲染器为JSONRenderer、BrowsableAPIRenderer
# 3、如果前端请求头未指定Accept参数或者指定为application/json,那么会自动返回json格式的数据
# 4、如果前端请求头指定Accept参数为text/html,那么默认会返回可浏览的api页面(api进行管理)
# 5、可以在DEFAULT_RENDERER_CLASSES中指定需要使用的渲染器
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
# 'rest_framework.renderers.BrowsableAPIRenderer',
],
}
4、GenericAPIView
继承自APIVIew,增加了对于列表视图和详情视图可能用到的通用支持方法。通常使用时,可搭配一个或多个Mixin扩展类。
注意:查询结果集是会被缓存的,相当于,当我们执行模型类.objects.all()后,数据会放到缓存中
1)queryset和serializer_class
GenericAPIView提供了两个类属性,queryset(指定查询集)和serializer_class(指定序列化器类)
- queryset指定当前类视图的实例方法需要使用的查询集对象
- serializer_class指定当前类视图的实例方法需要使用的序列化器类
然后通过self.get_queryset()和self.get_serializer方法分别去获取
# 需继承GenericAPIView
#class ProjectViews(APIView):
class ProjectViews(GenericAPIView):
queryset = Projects.objects.all()
serializer_class = serializers.ProjectModelSerializer
def get(self, request: Request):
...
# 一般不用self.queryset获取,而使用self.get_queryset获取类属性queryset
queryset = self.get_queryset()
# 同上,使用self.get_serializer获取类属性serializer_class
self.get_serializer(instance=queryset)
2)get_object
get_object可以获取模型对象,无需传递外键值,会自动获取url中传入的pk值(若自定义名字,则需指定lookup_field=‘ww’,那么url中的变量也要是ww,如‘projects/int:ww’)
project_obj = self.get_object()
源码如下:
def get_object(self):
"""
Returns the object the view is displaying.
You may want to override this if you need to provide non-standard
queryset lookups. Eg if objects are referenced using multiple
keyword arguments in the url conf.
"""
queryset = self.filter_queryset(self.get_queryset())
# Perform the lookup filtering.
########此处lookup_url_kwarg为url传过来的pk
lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
assert lookup_url_kwarg in self.kwargs, (
'Expected view %s to be called with a URL keyword argument '
'named "%s". Fix your URL conf, or set the `.lookup_field` '
'attribute on the view correctly.' %
(self.__class__.__name__, lookup_url_kwarg)
)
filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]}
obj = get_object_or_404(queryset, **filter_kwargs)
# May raise a permission denied
self.check_object_permissions(self.request, obj)
return obj
3)过滤
a、指定过滤器
第一种方式:全局指定
在django的settings设置以下过滤引擎类,在全局DEFAULT_FILTER_BACKENDS指定使用的过滤引擎类(SearchFilter为搜索引擎类)
REST_FRAMEWORK = { 'DEFAULT_FILTER_BACKENDS': [
'rest_framework.filters.SearchFilter',
'rest_framework.filters.OrderingFilter']}
第二种方式:在视图中指定
from rest_framework.filters import SearchFilter
class ProjectViews(GenericAPIView):
...
filter_backends = [SearchFilter]
- views中的模型类里面,类属性中罗列出搜索的字段
- search_fields = [‘^name’, ‘=leader’, ‘id’]
- 在字段前面添加前缀指定过滤方法。
- 默认的过滤方法为icontain(忽略大小写的包含查询)
- 字段前加’^'为 ‘istartswith’(以…开头)
- 字段前加’='为 ‘iexact’(忽略大小写的相等)
- 字段前加’$'为 ‘iregex’(忽略大小写的正则)
在方法中使用self.filter_queryset(self.get_queryset())获取过滤后的查询集,此时,前端传query string参数?search=xxx就可以使用过滤功能了
class ProjectViews(GenericAPIView):
queryset = Projects.objects.all()
serializer_class = serializers.ProjectModelSerializer
search_fields = ['^name', '=leader']
def get(self, request: Request):
# filter_queryset需要传递查询集对象作为参数
queryset = self.filter_queryset(self.get_queryset())
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
b、修改参数
注意:http://127.0.0.1:8000/projects/?search=dj,必须用search,如果制定别的关键字需在settings中指定SEARCH_PARAM=‘s’
现在我们修改query string参数的默认key“search”
REST_FRAMEWORK = {
...
'SEARCH_PARAM': 's',
}
此时,前端需要传query string参数?s=xxx才能使用过滤功能ordering_fields = [‘id’, ‘-name’, ‘leader’]
4)排序
a、指定过滤器
第一种方式:全局指定
REST_FRAMEWORK = {
...
'DEFAULT_FILTER_BACKENDS': ['rest_framework.filters.OrderingFilter'],
}
第二种方式:在视图中指定
from rest_framework.filters import OrderingFilter
class ProjectViews(GenericAPIView):
...
queryset = Projects.objects.all()
serializer_class = serializers.ProjectModelSerializer
filter_backends = [OrderingFilter]
# 指定需要过滤的字段
ordering_fields = ['id', 'name', 'leader']
# 指定默认排序字段
ordering = ['name']
...
前端传query string参数:http://127.0.0.1:8000/projects/?ordering=-name,id,就可以使用过滤功能了(默认生序,若降序在字段前加-号,如果指定多个排序字段,使用英文逗号进行分割)。
b、修改参数
修改query string参数的默认key“ordering”
REST_FRAMEWORK = {
...
'ORDERING_PARAM': 'o',
}
此时,前端需要传query string参数?o=xxx才能使用过滤功能。
4)分页
a、直接引用PageNumberPagination
引用DRF框架自带的类rest_framework.pagination.PageNumberPagination
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
}
b、自定义PageNumberPagination类
自定义PageNumberPagination类,然后在settings.py的配置中修改
# settings.py
REST_FRAMEWORK = {
# 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
'DEFAULT_PAGINATION_CLASS': 'utils.pagination.PageNumberPagination',
}
# utils/pagination.py
from rest_framework.pagination import PageNumberPagination as _PageNumberPagination
# 导入DRF中的PageNumberPagination类时重命名为_PageNumberPagination
class PageNumberPagination(_PageNumberPagination):
# 指定默认每一页显示3条数据
page_size = 3
# 前端用于指定页码的查询字符串参数名称
page_query_param = 'pp'
# 前端用于指定页码的查询字符串参数描述
page_query_description = '获取的页码'
# 前端用于指定每一页显示的数据条数,查询字符串参数名称
page_size_query_param = 'ss'
page_size_query_description = '每一页数据条数'
# 当接口uri中传入的size大于当前设置的max_page_size,则按max_page_size中的数据返回数据个数
max_page_size = 50
invalid_page_message = '无效页码'
# 重写父类的方法给返回的数据增加页号字段
def get_paginated_response(self, data):
# 调用父类的实现
response = super().get_paginated_response(data)
# 增加页号字段
response.data['current_num'] = self.page.number
response.data['max_num'] = self.page.paginator.num_pages
# 返回新增后的字典
return response
c、应用
views.py,修改视图类添加分页功能
class ProjectViews(GenericAPIView):
queryset = Projects.objects.all()
serializer_class = serializers.ProjectModelSerializer
filter_backends = [SearchFilter, OrderingFilter]
search_fields = ['^name', '=leader']
def get(self, request: Request):
queryset = self.filter_queryset(self.get_queryset())
# 使用paginate_queryset方法,进行分页操作;需要接收查询集参数;如果返回的数据为空,说明不进行分页操作,否则需要进行分页操作
page = self.paginate_queryset(queryset)
if page is not None:
# 调用get_serializer,将page作为参数传给instance
serializer = self.get_serializer(instance=page, many=True)
# 分页必须调用get_paginated_response方法返回
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
4)总结
GenericAPIView主要的属性:
- queryset: 指定查询集,如:queryset = Projects.objects.all()
- serializer_class: 指定序列化器类,如:serializer_class = serializers.ProjectModelSerializer
GenericAPIView主要的方法
- get_queryset(): 获取类属性中指定的查询集。
- get_serializer(): 获取类属性中指定的序列化器类。
- get_serializer_class(): 返回序列化器类,调用get_serializer()时会调用这个方法,默认返回serializer_class。
- filter_queryset(): 使用过滤器对数据进行过滤,需要接收查询集参数。
- paginate_queryset(): 对传入的数据进行分页操作,需要接收查询集参数。
- get_paginated_response(): 为给定的输出数据返回一个分页样式的’ Response '对象,一般传参为serializer.data。
- get_object():根据pk获取单个数据。
class ProjectsView(GenericAPIView):
"""
继承GenericAPIView父类(GenericAPIView子类)
a.具备View的所有特性
b.具备了APIView中的认证、授权、限流功能
c.还支持对于获取列表数据接口的功能:搜索、排序、分页
"""
# 一旦继承GenericAPIView之后,往往需要指定queryset、serializer_class类属性
# queryset指定当前类视图的实例方法需要使用的查询集对象
queryset = Projects.objects.all()
# serializer_class指定当前类视图的实例方法需要使用的序列化器类
serializer_class = ProjectSerilizer
# 可以在类视图中指定分页引擎类,优先级高于全局
pagination_class = PageNumberPagination
# filter_backends在继承了GenericAPIView的类视图中指定使用的过滤引擎类(搜索、排序)
# 优先级高于全局
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
# 2、在继承了GenericAPIView的类视图中,search_fields类属性指定模型类中需要进行搜索过滤的字段名
# 3、使用icontains查询类型作为过滤类型
# 4、可以在字段名称前添加相应符号,指定查询类型
# '^': 'istartswith',
# '=': 'iexact',
# '$': 'iregex',
search_fields = ['^name', '=leader', 'id']
# ordering_fields类属性指定模型类中允许前端进行排序的字段名称
# 前端默认可以使用ordering作为排序功能查询字符串参数名称,默认改字段的升序
# 如果在字段名称前添加“-”,代表改字段降序
# 如果指定多个排序字段,使用英文逗号进行分割
ordering_fields = ['id', 'name', 'leader']
def get(self, request: Request):
# name_param = request.query_params.get('name')
# if name_param:
# queryset = Projects.objects.filter(name__exact=name_param)
# else:
# queryset = Projects.objects.all()
# queryset = Projects.objects.all()
# 1、在实例方法中,往往使用get_queryset()方法获取查询集对象
# 2、一般不会直接调用queryset类属性,原因:为了提供让用户重写get_queryset()
# 3、如果未重写get_queryset()方法,那么必须得指定queryset类属性
# 4、调用self.get_queryset()方法时,类属性必须要有queryset类属性
# queryset = self.queryset
# queryset = self.get_queryset()
# filter_queryset对查询对象进行过滤操作
queryset = self.filter_queryset(self.get_queryset())
# serializer = ProjectSerilizer(instance=queryset, many=True)
# 调用paginate_queryset方法对查询集对象进行分页
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(instance=page, many=True)
return self.get_paginated_response(serializer.data)
# 1、在实例方法中,往往使用get_serializer()方法获取序列化器类
# 2、一般不会直接调用serializer_class类属性,原因:为了让用户重写get_serializer_class()
# 3、如果未重写get_serializer_class()方法,那么必须得指定serializer_class类属性
# 4、调用self.get_serializer()方法时,类属性必须要有serializer_class类属性
# serializer = self.serializer_class(instance=queryset, many=True)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
def post(self, request):
# serializer = ProjectModelSerializer(data=request.data)
# serializer = self.serializer_class(data=request.data)
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
5、Mixin拓展类
Mixin拓展类,拓展类只提供了action方法(mixins库下的各个类);
action方法:
list --> 获取列表数据(ListModelMixin类的list方法)
retrieve --> 获取详情数据(RetrieveModelMixin类的retrieve方法)
create --> 创建数据(CreateModelMixin类的create方法)
update --> 更新数据(完整)(UpdateModelMIxin类的update方法)
partial_update --> 更新数据(部分)(UpdateModelMIxin类的update方法)
destroy --> 删除数据(DestroyModelMixin类的destroy方法)
1)ListModelMixin
列表视图扩展类,提供list(request, *args, **kwargs)方法快速实现列表视图,返回200状态码。
该Mixin的list方法会对数据进行过滤和分页。
源码如下:
# 源码:
class ListModelMixin(object):
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
实际使用:
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import ListModelMixin
from book.models import BookInfo
from book.serializers import BookInfoModelSerializer
class BookListGenericMixinView(ListModelMixin,GenericAPIView):
# 设置查询结果集属性
queryset = BookInfo.objects.all()
# 设置序列化器属性
serializer_class = BookInfoModelSerializer
def get(self,request):
#调用Mixin抽取好的list方法
return self.list(request)
# ------------分割线-------------------------------------------
# 上述BookListGenericMixinView引用的父类可以合并使用ListAPIView替换
from rest_framework.generics import ListAPIView
class BookListGenericMixinView(ListAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoModelSerializer
# ------------分割线-------------------------------------------
# 我们来看下ListAPIView的源码,就知道为啥可以替换了
# ListAPIView源码如下:
class ListAPIView(mixins.ListModelMixin,
GenericAPIView):
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
2)CreateModelMixin
创建视图扩展类,提供create(request, *args, **kwargs)方法快速实现创建资源的视图,成功返回201状态码。
如果序列化器对前端发送的数据验证失败,返回400错误。
源码:
# 源码
class CreateModelMixin(object):
"""
Create a model instance.
"""
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
serializer.save()
def get_success_headers(self, data):
try:
return {'Location': str(data[api_settings.URL_FIELD_NAME])}
except (TypeError, KeyError):
return {}
具体使用:
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import CreateModelMixin
from book.models import BookInfo
from book.serializers import BookInfoModelSerializer
class BookListGenericMixinView(CreateModelMixin,GenericAPIView):
# 设置查询结果集属性
queryset = BookInfo.objects.all()
# 设置序列化器属性
serializer_class = BookInfoModelSerializer
def post(self,request):
# 调用Mixin抽取好create的方法
return self.create(request)
3)RetrieveModelMixin
详情视图扩展类,提供retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。
如果存在,返回200, 否则返回404。
源码:
class RetrieveModelMixin(object):
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
具体使用:
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin
from book.models import BookInfo
from book.serializers import BookInfoModelSerializer
class BookDetailGenericMixinView(RetrieveModelMixin, GenericAPIView):
# 设置查询结果集属性
queryset = BookInfo.objects.all()
# 设置序列化器属性
serializer_class = BookInfoModelSerializer
def get(self, request,pk):
# 调用Mixin抽取好的retrieve方法
return self.retrieve(request)
4)UpdateModelMixin
更新视图扩展类,提供update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。
同时也提供partial_update(request, *args, **kwargs)方法,可以实现局部更新。
成功返回200,序列化器校验数据失败时,返回400错误。
源码:
class UpdateModelMixin(object):
"""
Update a model instance.
"""
def update(self, request, *args, **kwargs):
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return Response(serializer.data)
def perform_update(self, serializer):
serializer.save()
def partial_update(self, request, *args, **kwargs):
kwargs['partial'] = True
return self.update(request, *args, **kwargs)
具体使用:
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import UpdateModelMixin
from book.models import BookInfo
from book.serializers import BookInfoModelSerializer
class BookDetailGenericMixinView(UpdateModelMixin, GenericAPIView):
# 设置查询结果集属性
queryset = BookInfo.objects.all()
# 设置序列化器属性
serializer_class = BookInfoModelSerializer
def put(self, request,pk):
# 调用Mixin抽取好update的方法
return self.update(request)
5)DestroyModelMixin
删除视图扩展类,提供destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。
成功返回204,不存在返回404。
源码:
class DestroyModelMixin(object):
"""
Destroy a model instance.
"""
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
self.perform_destroy(instance)
return Response(status=status.HTTP_204_NO_CONTENT)
def perform_destroy(self, instance):
instance.delete()
具体使用:
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import DestroyModelMixin
from book.models import BookInfo
from book.serializers import BookInfoModelSerializer
class BookDetailGenericMixinView(DestroyModelMixin, GenericAPIView):
# 设置查询结果集属性
queryset = BookInfo.objects.all()
# 设置序列化器属性
serializer_class = BookInfoModelSerializer
def delete(self,request,pk):
调用Mixin抽取好destory的方法
return self.destroy(request)
6、类视图
类视图将Mixin拓展类和GenericAPIView结合,比如generics.ListAPIView直接继承Mixin拓展类((只提供了action方法))和GenericAPIView类,而generics.ListAPIView中将方法与action连接起来,如下:
class ListAPIView(mixins.ListModelMixin,
GenericAPIView):
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
类视图识别action方法对应情况如下(generics库下的各个类):
get --> list (ListAPIView类下的get方法)
get --> retrieve (RetrivevAPIView类下的get方法)
post --> create (CreateAPIView下的post方法)
put --> update (UpdateAPIView类下的put方法)
patch --> partial_update (UpdateAPIView类下的patch方法)
delete --> destroy (DestroyAPIView类下的delete方法)
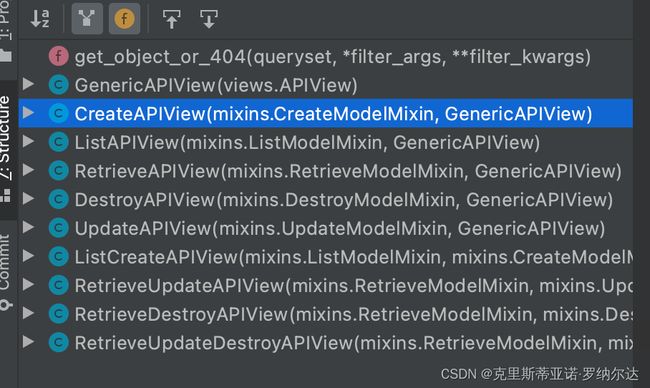
除此之外还有ListCreateAPIView、RetrivevUpdateAPIView、RetrivevDestroyAPIView、RetrivevUpdateDestroyAPIView方法,具体可以查看源码
ListAPIView ====〉mixins.ListModelMixin, GenericAPIView
CreateAPIView ==== 〉mixins.CreateModelMixin, GenericAPIView
RetrieveAPIView==== 〉mixins.RetrieveModelMixin, GenericAPIView
DestroyAPIView ====〉mixins.DestroyModelMixin, GenericAPIView
UpdateAPIView ====〉mixins.UpdateModelMixin, GenericAPIView
ListCreateAPIView ==== 〉mixins.ListModelMixin,mixins.CreateModelMixin, GenericAPIView
RetrieveUpdateAPIView ====〉mixins.RetrieveModelMixin, mixins.UpdateModelMixin, GenericAPIView
RetrieveDestroyAPIView ====〉mixins.RetrieveModelMixin, mixins.DestroyModelMixin, GenericAPIView
RetrieveUpdateDestroyAPIView ====〉mixins.RetrieveModelMixin, mixins.UpdateModelMixin, mixins.DestroyModelMixin, GenericAPIView
# class ProjectsDetailView(
# mixins.RetrieveModelMixin,
# mixins.UpdateModelMixin,
# mixins.DestroyModelMixin,
# GenericAPIView):
# 为了进一步优化代码,需要使用具体的通用视图XXXAPIView
class ProjectsDetailView(generics.RetrieveUpdateDestroyAPIView):
queryset = Projects.objects.all()
serializer_class = ProjectSerilizer
genaric.py源码
class CreateAPIView(mixins.CreateModelMixin,
GenericAPIView):
"""
Concrete view for creating a model instance.
"""
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class ListAPIView(mixins.ListModelMixin,
GenericAPIView):
"""
Concrete view for listing a queryset.
"""
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
class RetrieveAPIView(mixins.RetrieveModelMixin,
GenericAPIView):
"""
Concrete view for retrieving a model instance.
"""
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
class DestroyAPIView(mixins.DestroyModelMixin,
GenericAPIView):
"""
Concrete view for deleting a model instance.
"""
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
class UpdateAPIView(mixins.UpdateModelMixin,
GenericAPIView):
"""
Concrete view for updating a model instance.
"""
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def patch(self, request, *args, **kwargs):
return self.partial_update(request, *args, **kwargs)
class ListCreateAPIView(mixins.ListModelMixin,
mixins.CreateModelMixin,
GenericAPIView):
"""
Concrete view for listing a queryset or creating a model instance.
"""
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class RetrieveUpdateAPIView(mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
GenericAPIView):
"""
Concrete view for retrieving, updating a model instance.
"""
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def patch(self, request, *args, **kwargs):
return self.partial_update(request, *args, **kwargs)
class RetrieveDestroyAPIView(mixins.RetrieveModelMixin,
mixins.DestroyModelMixin,
GenericAPIView):
"""
Concrete view for retrieving or deleting a model instance.
"""
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
class RetrieveUpdateDestroyAPIView(mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
GenericAPIView):
"""
Concrete view for retrieving, updating or deleting a model instance.
"""
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def patch(self, request, *args, **kwargs):
return self.partial_update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
7、视图集
1)前言
视图集有4个类(ViewSet/GenericViewSet/ReadOnlyModelViewSet/ModelViewSet)具体参考源码。
GenericViewSet源码如下:
class GenericViewSet(ViewSetMixin, generics.GenericAPIView):
"""
The GenericViewSet class does not provide any actions by default,
but does include the base set of generic view behavior, such as
the `get_object` and `get_queryset` methods.
"""
pass
class ViewSetMixin:
"""
This is the magic.
Overrides `.as_view()` so that it takes an `actions` keyword that performs
the binding of HTTP methods to actions on the Resource.
For example, to create a concrete view binding the 'GET' and 'POST' methods
to the 'list' and 'create' actions...
view = MyViewSet.as_view({'get': 'list', 'post': 'create'})
"""
@classonlymethod
def as_view(cls, actions=None, **initkwargs):
"""
Because of the way class based views create a closure around the
instantiated view, we need to totally reimplement `.as_view`,
and slightly modify the view function that is created and returned.
"""
# The name and description initkwargs may be explicitly overridden for
# certain route configurations. eg, names of extra actions.
cls.name = None
cls.description = None
# The suffix initkwarg is reserved for displaying the viewset type.
# This initkwarg should have no effect if the name is provided.
# eg. 'List' or 'Instance'.
cls.suffix = None
# The detail initkwarg is reserved for introspecting the viewset type.
cls.detail = None
# Setting a basename allows a view to reverse its action urls. This
# value is provided by the router through the initkwargs.
cls.basename = None
# actions must not be empty
if not actions:
raise TypeError("The `actions` argument must be provided when "
"calling `.as_view()` on a ViewSet. For example "
"`.as_view({'get': 'list'})`")
# sanitize keyword arguments
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r" % (
cls.__name__, key))
# name and suffix are mutually exclusive
if 'name' in initkwargs and 'suffix' in initkwargs:
raise TypeError("%s() received both `name` and `suffix`, which are "
"mutually exclusive arguments." % (cls.__name__))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if 'get' in actions and 'head' not in actions:
actions['head'] = actions['get']
# We also store the mapping of request methods to actions,
# so that we can later set the action attribute.
# eg. `self.action = 'list'` on an incoming GET request.
self.action_map = actions
# Bind methods to actions
# This is the bit that's different to a standard view
for method, action in actions.items():
handler = getattr(self, action)
setattr(self, method, handler)
self.request = request
self.args = args
self.kwargs = kwargs
# And continue as usual
return self.dispatch(request, *args, **kwargs)
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
# We need to set these on the view function, so that breadcrumb
# generation can pick out these bits of information from a
# resolved URL.
view.cls = cls
view.initkwargs = initkwargs
view.actions = actions
return csrf_exempt(view)
def initialize_request(self, request, *args, **kwargs):
"""
Set the `.action` attribute on the view, depending on the request method.
"""
request = super().initialize_request(request, *args, **kwargs)
method = request.method.lower()
if method == 'options':
# This is a special case as we always provide handling for the
# options method in the base `View` class.
# Unlike the other explicitly defined actions, 'metadata' is implicit.
self.action = 'metadata'
else:
self.action = self.action_map.get(method)
return request
def reverse_action(self, url_name, *args, **kwargs):
"""
Reverse the action for the given `url_name`.
"""
url_name = '%s-%s' % (self.basename, url_name)
namespace = None
if self.request and self.request.resolver_match:
namespace = self.request.resolver_match.namespace
if namespace:
url_name = namespace + ':' + url_name
kwargs.setdefault('request', self.request)
return reverse(url_name, *args, **kwargs)
@classmethod
def get_extra_actions(cls):
"""
Get the methods that are marked as an extra ViewSet `@action`.
"""
return [_check_attr_name(method, name)
for name, method
in getmembers(cls, _is_extra_action)]
def get_extra_action_url_map(self):
"""
Build a map of {names: urls} for the extra actions.
This method will noop if `detail` was not provided as a view initkwarg.
"""
action_urls = OrderedDict()
# exit early if `detail` has not been provided
if self.detail is None:
return action_urls
# filter for the relevant extra actions
actions = [
action for action in self.get_extra_actions()
if action.detail == self.detail
]
for action in actions:
try:
url_name = '%s-%s' % (self.basename, action.url_name)
url = reverse(url_name, self.args, self.kwargs, request=self.request)
view = self.__class__(**action.kwargs)
action_urls[view.get_view_name()] = url
except NoReverseMatch:
pass # URL requires additional arguments, ignore
return action_urls
a.可以继承视图集父类ViewSet
b.在定义url路由条目时,支持给as_view传递字典参数(请求方法名与具体调用的action方法名的一一对应关系)(如{‘get’:‘list’})
c.ViewSet继承了ViewSetMixin, views.APIView
d.具备APIView的所有功能,提供了身份认证、权限校验、流量管理等
e.继承ViewSetMixin,所有具备持给as_view传递字典参数(请求方法名与具体调用的action方法名的一一对应关系)
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 如 list() 、create() 等:
- list() 提供一组数据
- retrieve() 提供单个数据
- create() 创建数据
- update() 保存数据
- destory() 删除数据
视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上。如:
from rest_framework.response import Response
from demo.models import ClassInfo
from demo.serializers import ClassInfoSerializer
from rest_framework import viewsets, status
class ClassViewSet(viewsets.ViewSet):
# 获取所有班级数据
def list(self, request):
Classes = ClassInfo.objects.all()
serializer = ClassInfoSerializer(Classes, many=True)
return Response(serializer.data)
def retrieve(self, request, pk=None):
try:
Class = ClassInfo.objects.get(id=pk)
except ClassInfo.DoesNotExist:
return Response(status=status.HTTP_404_NOT_FOUND)
serializer = ClassInfoSerializer(Class)
return Response(serializer.data)
from django.urls import path
from demo import views
urlpatterns = [
······
path('classes/', views.ClassViewSet.as_view({'get': 'list'})),
path('classes//' , views.ClassViewSet.as_view({'get': 'retrieve'})),
]
2)ViewSet
继承自APIView与ViewSetMixin,作用也与APIView基本类似,提供了身份认证、权限校验、流量管理等。
ViewSet主要通过继承ViewSetMixin来实现在调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作。
在ViewSet中,没有提供任何动作action方法,需要我们自己实现action方法
3)GenericViewSet
使用ViewSet通常并不方便,因为list、retrieve、create、update、destory等方法都需要自己编写,而这些方法与前面讲过的Mixin扩展类提供的方法同名,所以我们可以通过继承Mixin扩展类来复用这些方法而无需自己编写。但是Mixin扩展类依赖与GenericAPIView,所以还需要继承GenericAPIView;
GenericViewSet就帮助我们完成了这样的继承工作,继承自GenericAPIView与ViewSetMixin,在实现了调用as_view()时传入字典(如{‘get’:‘list’})的映射处理工作的同时,还提供了GenericAPIView提供的基础方法,可以直接搭配Mixin扩展类使用
举例:
from rest_framework import mixins
from rest_framework.viewsets import GenericViewSet
from rest_framework.decorators import action
class ClassInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
queryset = ClassInfo.objects.all()
serializer_class = ClassInfoSerializer
urlpatterns = [
······
path('classes_set/', views.ClassInfoViewSet.as_view({'get': 'list'})),
path('classes_set//' , views.ClassInfoViewSet.as_view({'get': 'retrieve'})),
]
4)ModelViewSet和ReadOnlyModelViewSet类
# a.ModelViewSet是一个最完整的视图集类
# b.提供了获取列表数据接口、获取详情数据接口、创建数据接口、更新数据接口、删除数据的接口
# c.如果需要多某个模型进行增删改查操作,才会选择ModelViewSet
# d.如果仅仅只对某个模型进行数据读取操作(取列表数据接口、获取详情数据接口),一般会选择ReadOnlyModelViewSet
class ProjectViewSet(viewsets.ModelViewSet):
queryset = Projects.objects.all()
serializer_class = ProjectModelSerializer
filter_backends = [filters.SearchFilter, filters.OrderingFilter]
search_fields = ['=name', '=leader', '=id']
ordering_fields = ['id', 'name', 'leader']
@action(methods=['GET'], detail=False)
def names(self, request, *args, **kwargs):
return super().list(request, *args, **kwargs)
@action(detail=True)
def interfaces(self, request, *args, **kwargs):
project = self.get_object()
interfaces_qs = project.interfaces_set.all()
interfaces_data = [{'id': interface.id, 'name': interface.name} for interface in interfaces_qs]
return Response(interfaces_data, status=200)
源码:
# 源码
class ReadOnlyModelViewSet(mixins.RetrieveModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `list()` and `retrieve()` actions.
"""
pass
class ModelViewSet(mixins.CreateModelMixin,
mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `create()`, `retrieve()`, `update()`,
`partial_update()`, `destroy()` and `list()` actions.
"""
pass
5)重写父类方法
class ProjectViewSet(viewsets.ModelViewSet):
def get_serializer_class(self):
"""
a.可以重写父类的get_serializer_class方法,用于为不同的action提供不一样的序列化器类
b.在视图集对象中可以使用action属性获取当前访问的action方法名称
:return:
"""
if self.action == 'names':
return ProjectsNamesModelSerailizer
else:
# return self.serializer_class
return super().get_serializer_class()
def retrieve(self, request, *args, **kwargs):
response = super().retrieve(request, *args, **kwargs)
response.data.pop('id')
response.data.pop('create_time')
return response
# def filter_queryset(self, queryset):
# if self.action == "names":
# return self.queryset
# else:
# return super().filter_queryset(queryset)
def paginate_queryset(self, queryset):
if self.action == "names":
return
else:
return super().paginate_queryset(queryset)
def get_queryset(self):
if self.action == "names":
return self.queryset.filter(name__icontains='2')
else:
return super().get_queryset()
6)类视图原则
如何定义类视图?类视图的设计原则?
- a.类视图尽量要简单
- b.根据需求选择相应的父类视图
- c.如果DRF中的类视图有提供相应的逻辑,那么就直接使用父类提供的
- d.如果DRF中的类视图,绝大多数逻辑都能满足需求,可以重写父类实现
- e.如果DRF中的类视图完全不满足要求,那么就直接自定义即可
7)自定义action
在视图集中,除了上述默认的方法动作外,还可以添加自定义动作。
添加自定义动作需要使用rest_framework.decorators.action装饰器。
以action装饰器装饰的方法名会作为action动作名,与list、retrieve等同。
action装饰器可以接收两个参数:
methods: 该action支持的请求方式,列表传递,加上后可以自动获取路由,不写就默认为get
detail: 表示是action中要处理的是否是视图资源的对象(即是否通过url路径获取主键)
(1)True 表示使用通过URL获取的主键对应的数据对象
(2)False 表示不使用URL获取主键
@action(methods=['GET'], detail=False)
def names(self, request, *args, **kwargs):
return super().list(request, *args, **kwargs)
@action(detail=True)
def interfaces(self, request, *args, **kwargs):
project = self.get_object()
interfaces_qs = project.interfaces_set.all()
interfaces_data = [{'id': interface.id, 'name': interface.name} for interface in interfaces_qs]
return Response(interfaces_data, status=200)
7)routers自动生成路由条目
使用routers自动生成路由条目:
- 1、可以使用路由器对象,为视图集类自动生成路由条目
- 2、路由器对象默认只为通用action(create、list、retrieve、update、destroy)生成路由条目,自定义的action不会生成路由条目
- 3、创建SimpleRouter路由对象
- 4、使用路由器对象调用register方法进行注册,register里面的参数是register(路由前缀,视图集,basename),访问时的路径则变为: (前缀)/路由前缀/函数名
- 5、prefix指定路由前缀
- 6、viewset指定视图集类,不可调用as_view
- 7、加载路由条目:
- 方式一:路由器对象.urls属性可获取生成的路由条目 include(router.urls)
- 方式二:urlpatterns += router.urls,# router.urls为列表
注意:如果是视图集类中自己定义的action,需要在自定义的action加上装饰器@action
# -*- coding: utf-8 -*-
from django.urls import path, include
from rest_framework import routers
from . import views
router = routers.SimpleRouter()
# DefaultRouter与SimpleRouter功能类似,仅有的区别为:DefaultRouter会自动生成一个根路由(显示获取数据的入口)
# router = routers.DefaultRouter()
router.register(r'projects', views.ProjectViewSet)
urlpatterns = [
# 7、加载路由条目
# 方式一:
# 路由器对象.urls属性可获取生成的路由条目
path('', include(router.urls)),
]
# 方式二:
# router.urls为列表
# urlpatterns += router.urls
七、API接口文档
1、coreapi
注意配置1:在配置文件settings.py中重新指定schema_class的配置
REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
# 新版drf schema_class默认用的是rest_framework.schemas.openapi.AutoSchema
}
注意配置2:在setting文件的INSTALLED_APPS加入rest_framework,具体如下:
INSTALLED_APPS = [
‘rest_framework’,]
然后urls中制定访问路由
from rest_framework.documentation import include_docs_urls
urlpatterns = [
path('docs/', include_docs_urls(title='test接口文档', description='哈哈哈哈哈哈,这是哥的第一个接口文档'))
]
2、drf_yasg
INSTALLED_APPS = [‘drf_yasg’,]
from drf_yasg.views import get_schema_view
from drf_yasg import openapi
# 固定写法
schema_view = get_schema_view(
openapi.Info(
title="Lemon API接口文档平台", # 必传
default_version='v1', # 必传
description="这是一个美轮美奂的接口文档",
terms_of_service="http://api.keyou.site",
contact=openapi.Contact(email="[email protected]"),
license=openapi.License(name="BSD License"),
),
public=True,
)
urlpatterns = [
re_path(r'^swagger(?P\.json|\.yaml)$' , schema_view.without_ui(cache_timeout=0), name='schema-json'),
path('swagger/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
]
3、接口文档注解
可以通过在类视图下注解描述,即可在接口文档中显示
class ProjectViewSet(viewsets.ModelViewSet):
"""
list:
获取项目列表数据
retrieve:
获取项目详情数据
update:
更新项目信息
names:
获取项目名称
"""
八、日志器
需要在settings.py中定义logging和loggers,
然后log = logging.getLogger(‘wl’)获取logger
# 指定允许使用哪些地址访问当前系统
ALLOWED_HOSTS = ['*']
LOGGING = {
# 指定日志版本
'version': 1,
# 指定是否禁用其他日志,False为不禁用
'disable_existing_loggers': False,
# 定义日志输出格式
'formatters': {
# 简单格式
'simple': {
'format': '%(asctime)s - [%(levelname)s] - [msg]%(message)s'
},
# 复杂格式
'verbose': {
'format': '%(asctime)s - [%(levelname)s] - %(name)s - [msg]%(message)s - [%(filename)s:%(lineno)d ]'
},
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
# 指定日志输出渠道(日志输出的地方)
'handlers': {
# 指定在console控制台(终端)的日志配置行李箱
'console': {
# 指定日志记录等级
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
# 指定在日志文件的配置信息
'file': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(BASE_DIR, "logs/mytest.log"), # 日志文件的位置
'maxBytes': 100 * 1024 * 1024,
'backupCount': 10,
'formatter': 'verbose',
'encoding': 'utf-8'
},
},
# 定义日志器
'loggers': {
# 指定日志器的名称
'dev07': { # 定义了一个名为mytest的日志器
'handlers': ['console', 'file'],
'propagate': True,
'level': 'DEBUG', # 日志器接收的最低日志级别
},
}
}
实际使用:
# log使用
log = logging.getLogger('wl')
log.info("qqqqq")
九、认证器
1、session认证
settings.py中的rest_framework内指定DEFAULT_AUTHENTICATION_CLASSES和DEFAULT_PERMISSION_CLASSES
# 指定使用的认证类
# a.在全局指定默认的认证类(指定认证方式)
'DEFAULT_AUTHENTICATION_CLASSES': [
# b.Session会话认证
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication'
],
# 指定使用的权限类
# a.在全局指定默认的权限类(当认证通过之后,可以获取何种权限)
'DEFAULT_PERMISSION_CLASSES': [
# AllowAny不管是否有认证成功,都能获取所有权限
# IsAdminUser管理员(管理员需要登录)具备所有权限
# IsAuthenticated只要登录,就具备所有权限
# IsAuthenticatedOrReadOnly,如果登录了就具备所有权限,不登录只具备读取数据的权限
'rest_framework.permissions.IsAuthenticatedOrReadOnly',
],
# 在全局路由表中添加rest_framework.urls子路由
# a.rest_framework.urls提供了登录和登出功能(返回的是一个HTML页面,并不是接口)
path('api/', include('rest_framework.urls'))
2、token认证
安装
pip install djangorestframework-jwt
settings.py中增加配置 DEFAULT_AUTHENTICATION_CLASSES和JWT_AUTH
REST_FRAMEWORK = {
# 指定使用的认证类
# a.在全局指定默认的认证类(指定认证方式)
'DEFAULT_AUTHENTICATION_CLASSES': [
# 1)指定使用JWT TOKEN认证类
# 2)在全局路由表中添加obtain_jwt_token路由(可以使用用户名和密码进行认证)
# 3)认证通过之后,在响应体中会返回token值
# 4)将token值设置请求头参数,key为Authorization,value为JWT token值
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
# b.Session会话认证
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication'
],
}
JWT_AUTH={
# 修改JWT TOKEN认证请求头中Authorization value值的前缀,默认为JWT
# 'JWT_AUTH_HEADER_PREFIX': 'bearer',
# 指定TOKEN过期时间,默认为5分钟,可以使用JWT_EXPIRATION_DELTA指定
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
# 修改处理payload的函数
'JWT_RESPONSE_PAYLOAD_HANDLER':
'utils.handle_jwt_response.jwt_response_payload_handler',
}
注意DEFAULT_AUTHENTICATION_CLASSES加在settings.py中默认全局生效,
但是实际使用时建议放在app的views.py中如下
class ProjectViewSet(viewsets.ModelViewSet):
...
# 在继承了APIView的类视图中,可以使用permission_classes类属性指定权限类,值为列表,可添加多个权限类
permission_classes = [permissions.IsAuthenticated]
...
# urls.py配置
from rest_framework_jwt.views import obtain_jwt_token
urlpatterns = [
path('user/login/', obtain_jwt_token),
]
十、跨域问题
安装corsheaders
pip install django-cors-headers
使用
INSTALLED_APPS = [ #注册应用
'corsheaders', #增加这个
]
MIDDLEWARE = [ #中间件
'corsheaders.middleware.CorsMiddleware', #增加这个,放最前面
'django.middleware.security.SecurityMiddleware',
]
CORS_ORIGIN_ALLOW_ALL = True
CORS_ORIGIN_WHITELIST = () #白名单ip,可以不填
# CORS_ORIGIN_WHITELIST指定能够访问后端接口的ip或域名列表
# CORS_ORIGIN_WHITELIST = [
# "http://127.0.0.1:8080",
# "http://localhost:8080",
# "http://192.168.1.63:8080",
# "http://127.0.0.1:9000",
# "http://localhost:9000",
# ]
CORS_ALLOW_CREDENTIALS = True # 允许携带cookie
# 前端需要携带cookies访问后端时,需要设置
# withCredentials=True
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
CORS_ALLOW_HEADERS = (
'accept',
'accept-encoding',
'authorization',
'content-type',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
)