不止是数据,RedPajama的模型也出来了,RedPajama 7B, 一个开源的高效LLM模型
资源/参考链接:
官网:TOGETHER
博客: https://www.together.xyz/blog/redpajama-models-v1
GitHub:Together
介绍
RedPajama和它背后的公司Together其实都挺有意思的。Together,由苹果前高管Vipul Ved Prakash,斯坦福大模型研究中心主任Percy Liang,苏黎世联邦理工大学助理教授张策等人联合创办。

RedPajama是“一个创建领先的开源模型的项目,从复制超过1.2万亿个Token的LLaMA训练数据集开始”。这是Together,Ontocord.ai,ETH DS3Lab,斯坦福CRFM,Hazy Research和MILA Québec AI Institute之间的合作。(前两天发布的MPT-7B也用到了RedPajama数据集,详见:北方的郎:MPT-7B:开源,商业可用,性能堪比LLaMA-7B的LLM新成员)

然后Together又在RePajama数据的基础上,开发RedPajama模型。在训练的过程中不断更新进展, 搞得像连续剧似的。
第一集(4月17日):我们搞的数据集很棒的
RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens — TOGETHER
第二集(4月24日):我们开始训练模型啦,这是进展
https://www.together.xyz/blog/redpajama-training-progress
第三季(5月5日):我们发布模型啦,棒棒的,而且7B的还在继续优化训练
https://www.together.xyz/blog/redpajama-models-v1
模型介绍:
作者说明:以下内容大部分翻译自Together发布RedPajama模型的文章(有调整),这里面的“我们”指的是Together公司。
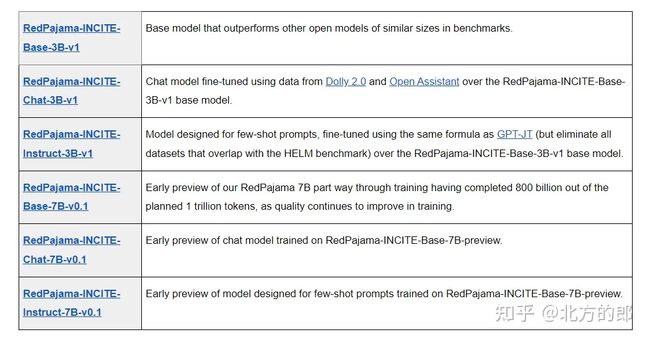
RedPajama 项目旨在创建一套领先的开源模型,并严格了解产生良好性能的成分。几周前,我们发布了基于LLaMA论文的RedPajama基础数据集,这激发了开源社区的热情。5 TB的数据集已被下载数百次,用于训练MPT,OpenLLaMA,OpenAlpaca等模型。今天,我们很高兴发布RedPajama-INCITE模型,包括 instruct-tuned 和 chat 版本。
今天的版本包括我们在RedPajama基础数据集上训练的第一个模型:一个3亿和一个7B参数基础模型,旨在尽可能接近地复制LLaMA配方。此外,我们还发布了完全开源的指令调整和聊天模型。我们的主要收获:
- 3B型号是同类产品中最强大的,小尺寸使其非常快速且易于使用(它甚至可以在2070年前发布的RTX 5上运行)。
- 这些模型的指令调整版本在 HELM 基准测试中实现了强大的性能。正如预期的那样,在HELM上,7B模型的性能比基本LLaMA模型高出3个百分点。我们建议将这些模型用于具有少量样本、实体提取、分类或汇总任务的下游应用程序。
- 7B模型(已完成80%的训练)已经优于Pythia 7B模型,这表明了更大数据集的重要性以及RedPajama基础数据集的价值。
- 根据我们的观察,我们看到了创建更好版本的RedPajama数据集的明确途径,我们将在未来几周内发布该数据集,这将超越LLaMA 7B的质量。我们计划使用这个新数据集构建更大规模的模型。
- 我们预计LLaMA 7B和我们的复制之间存在差异,我们将在下面进行研究。
最大的收获是证明了开源社区可以快速构建高性能LLM。这项工作建立在我们1.2万亿Token的RedPajama数据集,EleutherAI的Pythia训练代码,斯坦福大学的FlashAttention和Together,斯坦福CRFM的HELM基准以及MILA,EleutherAI和LAION的慷慨支持之上,用于INCITE计划内Summit超级计算机上的计算时间。 被授予"Scalable Foundation Models for Transferable Generalist AI”。我们相信,这种更大规模的开放式合作将成为未来最好的人工智能系统的幕后推手。
“RedPajama 3B 模型是同类产品中最强大的模型,为各种硬件带来了高性能的大型语言模型。“
今天的版本包括以下模型,所有模型都在宽松的Apache 2.0许可证下发布,允许在研究和商业应用中使用。
在短短几周内,开源社区对 RedPajama 的支持、建议和反馈令人难以置信。根据我们的学习,我们也已经开始了RedPajama基础数据集的下一个版本,其大小几乎是原始v1数据集的两倍。感谢您的支持、反馈和建议!

3B 模型已稳定在 800 亿个Token,7B 模型随着完成对 1 万亿个Token的训练而不断改进
在 RedPajama 模型训练期间,我们分享了定期更新,3B 和 7B 模型现在已经在 800 亿个Token上进行了训练。我们很高兴地看到 3B 模型已经稳定在 800 亿个Token,而 7B 模型随着完成训练到 1 万亿个Token而继续改进。
3B RedPajama Models
RedPajama-INCITE-Base-3B-v1 基于 RedPajama v1 数据集进行训练,其架构与流行的 Pythia 模型套件相同。我们选择从 Pythia 架构开始,以了解相对于当前领先的开源数据集 Pile,使用更大的 RedPajama 数据集进行训练的价值。Summit 上的培训利用了 EleutherAI 开发的 DeeperSpeed 代码库。
我们很高兴地看到,与类似大小的开放模型相比,包括备受推崇的 GPT-Neo 和 Pythia-2.8B(分别使用 420B 和 300B Token训练,使用 Pile),在 800B Token下,RedPajama-Base-INCITE-3B 具有更好的few-shot性能(以 HELM 衡量,作为 16 个核心场景的平均分数)和更好的zero-shot性能(在 Eleuther 的 LM 评估工具中测量)。在 HELM 上,它的性能比这些模型高出 3-5 分。在 lm-evaluation-harness 的任务子集上,性能比这些开放模型高出 2-7 分。
此外,我们很高兴发布此3B模型的指令调整版本RedPajama-INCITE-Instruct-3B-v1,该版本按照Together的GPT-JT配方进行训练,并删除HELM基准测试中的任何数据,以确保HELM没有污染。该模型在few-shot任务中表现出出色的性能,甚至在更小的模型中接近LLaMA 7B的质量,如下面的结果所示:
在 HELM 核心场景中的few-shot结果
| Models | Type | HELM (Average score over 16 core scenarios) |
|---|---|---|
| GPT-Neo | Base model | 0.357 |
| Pythia-2.8B | Base model | 0.377 |
| RedPajama-INCITE-Base-3B-v1 | Base model | 0.406 |
| RedPajama-INCITE-Instruct-3B-v1 | Instruction-tuned | 0.453 |
| Llama-7B | Base model | 0.465 |
基本模型在zero-shot任务上也表现良好,使用EleutherAI的语言模型评估工具进行测量:
(Zero Shot)在lm-evaluation-harness的子集上的结果,遵循LLM工作表选择的任务和指标。
| Lambada_openai (acc) |
Hellaswag (acc_norm) |
Winogrande (acc) |
Piqa(acc) | average | |
|---|---|---|---|---|---|
| GPT-Neo | 0.6223 | 0.5579 | 0.5769 | 0.7219 | 0.6197 |
| Pythia-2.8B | 0.6466 | 0.5933 | 0.6006 | 0.7399 | 0.6451 |
| Pythia-2.8B-dedup | 0.6524 | 0.5941 | 0.5848 | 0.7404 | 0.6429 |
| RedPajama-INCITE-Base-3B-v1 | 0.6541 | 0.6317 | 0.6322 | 0.7470 | 0.6662 |
lm-evaluation-harness子集的结果,从用于评估Pythia和GPT-J的任务中选择。

RedPajama 3B 结果在 lm 评估线束的子集上
RedPajama-INCITE-Chat-3B-v1是一个开源聊天模型,由RedPajama-INCITE-Base-3B-v1构建,并由Open Assistant对OASST1数据集和DataBricks的Dolly v2.0数据集进行微调。我们平均混合数据集,并微调 3 个epochs。
评估聊天模型是一项具有挑战性的任务,我们正在根据人类和社区的反馈进行更多的定量评估,并很高兴很快分享这些结果!不过,这里有一些比较不同聊天模型行为的示例。我们看到,在许多例子中,RedPajama-INCITE-Chat-3B-v1与他们的论文中报告的Open Assistant(their paper)具有相似的质量。
RedPajama 7B 预览
7B模型仍在训练(800B Token),我们看到训练损失仍在持续减少。因此,我们将继续将其训练为 1T Token。尽管如此,这个checkpoint非常有用,并且很有趣,可以帮助社区更好地了解我们的培训过程。因此,我们发布了三个中间checkpoint作为最终模型的“预览”。
- RedPajama-INCITE-Base-7B-v0.1 是一个经过 800B token训练的基本模型
- RedPajama-INCITE-Chat-7B-v0.1 是通过 Dolly 2.0 和 Open Assistant 训练的聊天对应物
- RedPajama-INCITE-Instruct-7B-v0.1 是针对few-shot应用程序调整的指令。我们遵循 GPT-JT 的配方,但删除了所有与 HELM 基准重叠的数据集。
这些检查点中的每一个都是在 Apache 2.0 许可证下发布的。即使在800B代币上,我们也已经看到了很有前景的结果。在HELM上,基本模型的性能优于GPT-J和Pythia-6.9B等开放模型0.5-2.2分,而在EleutherAI的lm-evaluation-harness上,它的性能平均比这些模型高出1-3分。
我们还看到,与LLaMA 7B相比,仍然存在质量差距 - 目前HELM为4.3分。对于few-shot应用程序(如HELM中的应用程序),指令调整模型(RedPajama-INCITE-Instruct-7B-v0.1)比基本模型显着改进。我们希望在我们进行更多迭代训练后,可以缩小其中的一些差距。
(few-shot)HELM 核心方案的结果
| Model | Type | HELM (Average score over 16 core scenarios) |
|---|---|---|
| GPT-J | Base model | 0.417 |
| Pythia-6.9B | Base model | 0.400 |
| Llama-7B | Base model | 0.465 |
| RedPajama-INCITE-Base-7B-v0.1 | Base model | 0.422 |
| RedPajama-INCITE-Instruct-7B-v0.1 | Instruction-tuned | 0.499 |
基本模型在zero-shot任务上也表现良好,使用EleutherAI的语言模型评估工具进行测量:
(Zero Shot)在lm-evaluation-harness的子集上的结果,遵循LLM工作表选择的任务和指标。We didn’t run coqa because of an error as in this issue. Llama numbers marked with * are taken directly from LLM Worksheet because we run into the following issue.
| Lambada_openai (acc) |
Hellaswag (acc_norm) |
Winogrande (acc) |
Piqa (acc) | average | |
|---|---|---|---|---|---|
| GPT-J | 0.6699 | 0.6663 | 0.6503 | 0.7565 | 0.6857 |
| Pythia-6.9B | 0.6712 | 0.6389 | 0.6069 | 0.7519 | 0.6672 |
| Pythia-6.9B-dedup | 0.6893 | 0.6588 | 0.6266 | 0.7578 | 0.6831 |
| Llama-7B | 0.7360* | 0.7620* | 0.7040 | 0.7810 | 0.7457 |
| RedPajama-INCITE-Base-7B-v0.1 | 0.7061 | 0.6951 | 0.6519 | 0.7611 | 0.7035 |
LLM评估线束子集的结果,从用于评估Pythia和GPT-J的任务中选择。
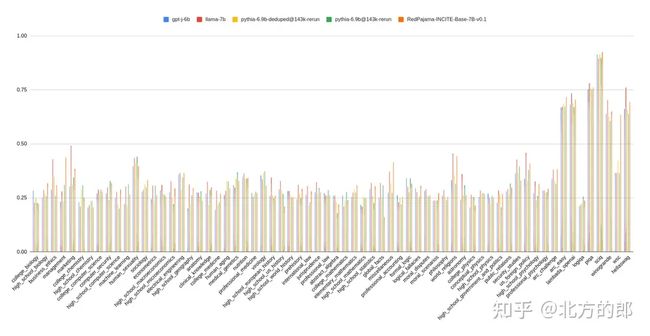
LLM评估工具子集的结果
前进:RedPajama v2 with 2T Token
我们从社区学到了很多东西,并正在努力通过采用系统的方法构建具有 2 万亿个Token的 RedPajama v2:
- 我们测量了不同模型在Pile不同切片上的验证损失(对于每个切片,我们选择了前5K通道)。我们看到 RedPajama 在 Pile 的许多切片上都落后了,尤其是那些没有直接包含在 RedPajama 数据集中的切片。受此启发,我们计划将 Pile 数据集混合到 RedPajama 中,并形成一个具有更多Token的更多样化的数据集。
- 我们需要更多的Token!我们的另一个直接任务是混合来自堆栈的数据并丰富RedPajama的Github切片,其中仅包含59亿个Token。
通过所有这些改进,我们正在为2T token RedPajama v2数据集而努力。下周我们将开始进行一系列运行,以了解正确的数据组合,并开始在 RedPajama v2 上训练新模型。
| Llama-7B | GPT-J | RedPajama-Base-INCITE-6.9B-v0.1 | |
|---|---|---|---|
| ArXiv | 1.727 | 1.511 | 1.990 |
| BookCorpus2 | 1.904 | 2.226 | 2.213 |
| Books3 | 1.664 | 1.979 | 1.909 |
| DM Mathematics | 1.411 | 1.158 | 1.910 |
| Enron Emails | 2.494 | 1.844 | 2.962 |
| EuroParl | 1.964 | 1.216 | 2.066 |
| FreeLaw | 1.425 | 1.121 | 1.889 |
| Github | 1.126 | 0.756 | 1.273 |
| Gutenberg (PG-19) | 1.837 | 1.718 | 2.079 |
| HackerNews | 2.423 | 2.311 | 2.821 |
| NIH ExPorter | 1.864 | 2.135 | 2.413 |
| OpenSubtitles | 2.184 | 2.136 | 2.510 |
| OpenWebText2 | 2.027 | 2.264 | 2.321 |
| PhilPapers | 1.947 | 2.225 | 2.280 |
| Pile-CC | 2.095 | 2.441 | 2.430 |
| PubMed Abstracts | 1.694 | 1.937 | 2.220 |
| PubMed Central | 1.697 | 1.494 | 2.122 |
| StackExchange | 1.776 | 1.588 | 2.078 |
| USPTO Backgrounds | 1.740 | 1.841 | 2.142 |
| Ubuntu IRC | 2.094 | 1.704 | 2.518 |
| Wikipedia (en) | 1.597 | 1.629 | 1.758 |
| YoutubeSubtitles | 1.943 | 1.955 | 2.226 |
RedPajama到现在的进展介绍完了,让我们期待他们的后续成果吧。
感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^