深度学习笔记(二)——激活函数原理与实现
深度学习笔记(二)——激活函数原理与实现
闲聊
昨天详细推了下交叉熵,感觉还可以,今天继续加油。

ReLU
原理
定义:ReLU是修正线性单元(rectified linear unit),在0和x之间取最大值。
出现原因:由于sigmoid和tanh容易出现梯度消失,为了训练深层神经网络,需要一个激活函数神经网络,它看起来和行为都像一个线性函数,但实际上是一个非线性函数,允许学习数据中的复杂关系 。该函数还必须提供更灵敏的激活和输入,避免饱和。而ReLU是非饱和激活函数,不容易发生梯度消失。
def ReLU(input):
if input>0:
return input
else:
return 0
ReLU 的函数表达式:
当 x <= 0 时,ReLU = 0
当 x > 0 时,ReLU = x

ReLU 的导数表达式:
当 x<= 0 时,导数为 0
当 x > 0 时,导数为 1

优点
计算简单
因为ReLU只需要一个max()函数便可以完成运算,而tanh和sigmoid需要指数运算,所以ReLU计算成本很低。
代表性稀疏
ReLU在负输入时可以输出真零值,允许神经网络中的隐藏层包含一个或多个真零值,这就是所谓的稀疏表示。在表示学习,因为它可以加速学习和简化模型。有效缓解过拟合的问题,因为 ReLU 有可能使部分神经节点的输出变为 0,从而导致神经节点死亡,降低了神经网络的复杂度。
线性行为
在输入大于零时,ReLU看起来像一个线性函数,当网络行为是近线性时,更容易优化,不会发生梯度消失或梯度爆炸,当 x 大于 0 时,ReLU 的梯度恒为 1,不会随着网路深度的加深而使得梯度在累乘的时候变得越来越小或者越来越大,从而不会发生梯度消失或梯度爆炸,也因此可以更适合训练深度网络。现在深度学习中,默认的激活函数是ReLU。
缺点
不适合RNN类网络
对 MLPs,CNNs 使用 ReLU,但不是 RNNs。ReLU 可以用于大多数类型的神经网络,它通常作为多层感知机神经网络和卷积神经网络的激活函数 。传统上,LSTMs 使用 tanh 激活函数来激活cell状态,使用 Sigmoid激活函数作为node输出。而ReLU通常不适合RNN类型网络的使用。
代码
import torch
import torch.nn as nn
relu = nn.ReLU(inplace=True)
Sigmoid
原理
Sigmoid 是常用的非线性的激活函数,可以将全体实数映射到(0, 1)区间上,其采用非线性方法将数据进行归一化处理;sigmoid函数通常用在回归预测和二分类(即按照是否大于0.5进行分类)模型的输出层中。
函数公式:

def Sigmoid(x):
return 1. / (1 + np.exp(-x))
曲线图:
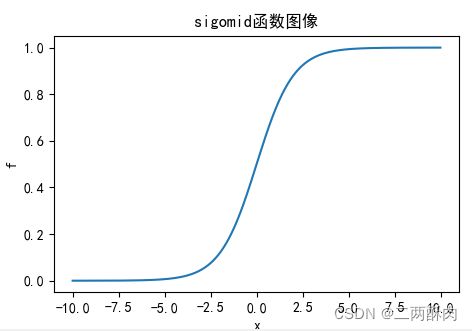
导数:
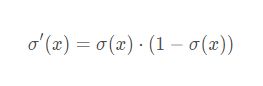
导数图像:

优点
求导容易
梯度平滑,求导容易
优化稳定
Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层
缺点
计算量大
在正向传播和反向传播中都包含幂运算和除法,所以存在着较大计算资源。
梯度消失
梯度消失:输入值较大或较小(图像两侧)时,sigmoid导数则接近于零,因此在反向传播时,这个局部梯度会与整个代价函数关于该单元输出的梯度相乘,结果也会接近为 0 ,无法实现更新参数的目的;
关于这点可以从其导数图像中看出,如果我们初始化神经网络的权值为 [0,1] [0,1][0,1] 之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍,如果神经网络隐层特别多,那么梯度在穿过多层后将变得非常小接近于0,即出现梯度消失现象;
代码
import torch
import torch.nn as nn
sigmoid=nn.Sigmoid()
Softmax
原理
Sigmoid函数只能处理两个类别,这不适用于多分类的问题,所以Softmax可以有效解决这个问题。Softmax函数很多情况都运用在神经网路中的最后一层网络中,使得每一个类别的概率值在(0, 1)之间。Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)。构建分类器,解决只有唯一正确答案的问题时,用Softmax函数处理各个原始输出值。Softmax函数的分母综合了原始输出值的所有因素,这意味着,Softmax函数得到的不同概率之间相互关联。即得到的所有概率和为1,示例看代码部分

def softmax(x):
return np.exp(x) / sum(np.exp(x))
优点
适用范围较广
相较于sigmoid,softmax可以处理多分类问题,因此可以适用于更多领域。
拉开值之间差距
由于Softmax函数先拉大了输入向量元素之间的差异(通过指数函数),然后才归一化为一个概率分布,在应用到分类问题时,它使得各个类别的概率差异比较显著,最大值产生的概率更接近1,这样输出分布的形式更接近真实分布。由于其拉开了差距,这样便于提高loss,能够获得更多的学习效果。
代码
举例:
假如一个鸡鸭鹅的三分类数据集,假如一个batch有三个输入,通过之前的网络,得到结果是([10,8,6],[7,9,5],[5,4,10])。
实际的标签值为[0,1,2],即是鸡鸭鹅。
表示含义是:网络推测鸡的概率为[86.68%],鸭[11.73%],鹅[1.59%],后面两行同理。
import torch
import torch.nn as nn
import math
import time
# 假设结果
input_1=torch.Tensor([0,1,2])
# 预测结果
input_2 = torch.Tensor([
[10,8,6],
[7,9,5],
[5,4,10]
])
#规定不同方向的softmax
softmax = nn.Softmax(dim=1)
#对不同维度的张量试验
output = softmax(input_2)
print(output)
#------------#
#tensor([[0.8668, 0.1173, 0.0159],
# [0.1173, 0.8668, 0.0159],
# [0.0067, 0.0025, 0.9909]])
#------------#
Tanh
原理
公式:

def tanh(x):
return np.sinh(x)/np.cosh(x)
函数图像

一阶求导后函数形式:

求导函数图像:
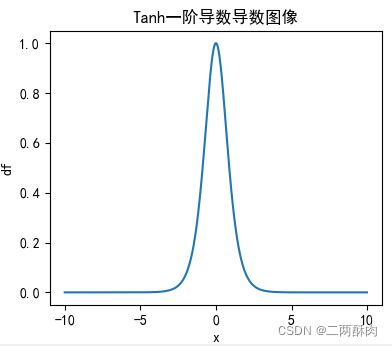
优点
收敛快
比Sigmoid函数收敛速度更快
梯度消失问题较轻
tanh(x) 的梯度消失问题比 sigmoid 要轻。因为可以看出,sigmoid在接近0时每层会缩小0.25倍,而tanh可以接近1,所以在深层网络中,梯度消失问题得到了减轻。
输出以0为中心
相比Sigmoid函数,输出是以 0 为中心 zero-centered
缺点
计算消耗量大
可以看出其进行了几次指数运算,消耗了比较大的计算成本。
梯度消失仍然存在
从导数图像可以看出,其导数图像和sigmoid有很大的相似性,还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
代码
import torch
import torch.nn as nn
relu = nn.tanh()
LeakyReLU
原理
Leaky ReLU 是为解决“ ReLU 死亡”问题的尝试。主要是为了避免死亡ReLU:x小于0时候,导数是一个小的数值,而不是0。

通常a为0.01。
def ReLU(input):
if input>0:
return input
else:
return 0.01*input
优点
计算成本低
计算快速:不包含指数运算。
能得到负值输出
相较于ReLU可以得到负值输出
拥有ReLU其他优点
缺点
a是超参数,需要人工设定
两部分都是线性
代码
import torch
import torch.nn as nn
LR=nn.LeakyReLU(inplace=True)
ReLU6
原理
主要是为了在移动端float16的低精度的时候,也能有很好的数值分辨率,如果对ReLu的输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。

特点
基本和ReLU相同,只是输出值上限有了限制。
def ReLU(input):
if input>0:
return min(6,input)
else:
return 0
代码
"""pytorch 神经网络"""
import torch.nn as nn
Re=nn.ReLU6(inplace=True)
ELU
原理
LU 的提出也解决了ReLU 的问题。与ReLU相比,ELU有负值,这会使激活的平均值接近零。均值激活接近于零可以使学习更快,因为它们使梯度更接近自然梯度。
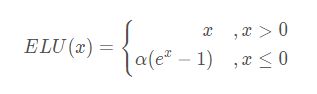
函数图像:

优点
解决了Dead ReLU
没有Dead ReLU问题,输出的平均值接近0,以0为中心。
加速学习
ELU 通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向零加速学习。
减少变异和信息
ELU函数在较小的输入下会饱和至负值,从而减少前向传播的变异和信息。
缺点
计算量变大
ELU函数的计算强度更高。与Leaky ReLU类似,尽管理论上比ReLU要好,但目前在实践中没有充分的证据表明ELU总是比ReLU好。
代码
import torch
import torch.nn as nn
LR=nn.ELU()
# ELU函数在numpy上的实现
import numpy as np
import matplotlib.pyplot as plt
def elu(x, a):
y = x.copy()
for i in range(y.shape[0]):
if y[i] < 0:
y[i] = a * (np.exp(y[i]) - 1)
return y
if __name__ == '__main__':
x = np.linspace(-50, 50)
a = 0.5
y = elu(x, a)
print(y)
plt.plot(x, y)
plt.title('elu')
plt.axhline(ls='--',color = 'r')
plt.axvline(ls='--',color = 'r')
# plt.xticks([-60,60]),plt.yticks([-10,50])
plt.show()
SELU
原理
SELU 源于论文 Self-Normalizing Neural Networks,作者为 Sepp Hochreiter,ELU 同样来自于他们组。
SELU 其实就是 ELU 乘 lambda,关键在于这个 lambda 是大于 1 的,论文中给出了 lambda 和 alpha 的值:
- lambda = 1.0507
- alpha = 1.67326

函数图像:

优点
自归一化
SELU 激活能够对神经网络进行自归一化(self-normalizing);
不出现梯度消失或爆炸
不可能出现梯度消失或爆炸问题,论文附录的定理 2 和 3 提供了证明。
缺点
应用较少
应用较少,需要更多验证;
需要初始化
lecun_normal 和 Alpha Dropout:需要 lecun_normal 进行权重初始化;如果 dropout,则必须用 Alpha Dropout 的特殊版本。
代码
import torch
import torch.nn as nn
SELU=nn.SELU()
Parametric ReLU (PRELU)
原理
形式上与 Leak_ReLU 在形式上类似,不同之处在于:PReLU 的参数 alpha 是可学习的,需要根据梯度更新。

- alpha=0:退化为 ReLU
- alpha 固定不更新,退化为 Leak_ReLU

优点
与 ReLU 相同。
缺点
在不同问题中,表现不一。
代码
import torch
import torch.nn as nn
PReLU= nn.PReLU()
Gaussian Error Linear Unit(GELU)
原理
高斯误差线性单元激活函数在最近的 Transformer 模型(谷歌的 BERT 和 OpenAI 的 GPT-2)中得到了应用。GELU 的论文来自 2016 年,但直到最近才引起关注。


优点
效果好
似乎是 NLP 领域的当前最佳;尤其在 Transformer 模型中表现最好;
避免梯度消失
能避免梯度消失问题。
缺点
这个2016 年提出的新颖激活函数还缺少实际应用的检验。
代码
import torch
import torch.nn as nn
gelu_f== nn.GELU()
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from matplotlib import pyplot as plt
class GELU(nn.Module):
def __init__(self):
super(GELU, self).__init__()
def forward(self, x):
return 0.5*x*(1+F.tanh(np.sqrt(2/np.pi)*(x+0.044715*torch.pow(x,3))))
def gelu(x):
return 0.5*x*(1+np.tanh(np.sqrt(2/np.pi)*(x+0.044715*np.power(x,3))))
x = np.linspace(-4,4,10000)
y = gelu(x)
plt.plot(x, y)
plt.show()
Swish
原理
Swish激活函数诞生于Google Brain 2017的论文 Searching for Activation functions中,其定义为:


β是个常数或可训练的参数.
Swish 在深层模型上的效果优于 ReLU。例如,仅仅使用 Swish 单元替换 ReLU 就能把 Mobile NASNetA 在 ImageNet 上的 top-1 分类准确率提高 0.9%,Inception-ResNet-v 的分类准确率提高 0.6%。
特点
Swish 具备无上界有下界、平滑、非单调的特性。
代码
import torch
import torch.nn as nn
class Swish(nn.Module):
def __init__(self):
super(Swish, self).__init__()
def forward(self, x):
x = x * F.sigmoid(x)
return x
Swi=Swish()
函数求导作图代码
对
import sympy as sy #用于求导积分等数学计算
import matplotlib.pyplot as plt #绘图
import numpy as np
x = sy.symbols('x') #定义符号变量x
#sigmoid函数
f = 1. / (1 + sy.exp(-x))
df = sy.diff(f,x) #求一阶导数
#ddf = sy.diff(df,x)
ddf = sy.diff(f,x,2) #求二阶导数,参数2为求导阶数
#建立空列表用来保存数据
x_value = [] #保存自变量x的取值
f_value = [] #保存函数值f的取值
df_value = [] #保存一阶导数df的取值
for i in np.arange(-10,10,0.01):
x_value.append(i)#对x进行取值
f_value.append(f.subs('x',i))#将i值代入表达式
df_value.append(df.subs('x',i))#将i值代入求导表达式
#正常显示中文需要一下两行代码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.title('sigomid函数图像')
plt.xlabel('x')
plt.ylabel('f')
plt.plot(x_value,f_value)
plt.show()
plt.title('sigmoid一阶导数导数图像')
plt.xlabel('x')
plt.ylabel('df')
plt.plot(x_value,df_value)
plt.show()