GraphQL 入门实操,详细的代码开发
一、GraphQL简介
GraphQL的官方文档:https://graphql.cn (http://graphql.js.cool/)。官方有这一句话来描述的:
GraphQL是一种用于API的查询语言。graphql对你的API中的数据提供了一套易于理解的完整描述,使得客户端能够准确的获得他需要的数据,而且没有任何冗余,也让API更容易的随着时间推移而演进。
简单来说,就是客户端想要什么信息, 就传入什么字段, 服务端也就会返回什么字段, 具体字段处理是服务器所提供, 而 graphql 并不会关心怎么服务器怎么处理。
二、GrapQL与Restful差异
GraphQL可以理解为是一个基于新的API标准,或者说基于对Restful的封装的一种API查询语言。
首先说下Restful, 它是基于REST架构风格的服务端为其它客户端提供交互的一个统一接口。它包含GET,DELETE,PUT和POST 四种典型的请求方式,并遵循这些方法的语义。Restful的核心思想就是资源,每个资源都能用一个URL来表示。
例如,在同一个业务中服务端需要对接Android、IOS、WEB等客户端。但是他们需要的数据就相差几个字段。比如:User,WEB端需要 name 和 age,Android需要name和hight,IOS需要age和sex。按照Restful我们可以写3个接口分别调用或者就一个接口,然后返回值冗余全部返回,客户端自己去选择自己的字段。
如果使用GraphQL,客户端可以根据自己需要哪些字段,就传给后端那些字段,然后就会返回对应字段,不会多也不会少返回一个字段。比如web端想请求用户的个人信息,主要包含name、age。客户端只需要传name和age 就可以,接口自动返回这2个。GraphQL有一个统一的入口,它只有一个接口,但是这个接口非常聪明,能按需返回你想要的数据。它会根据访问者的需要来返回数据,不会缺少,也不会像聚合接口这样,返回一堆你不太需要的数据。举例说明:
| 传统的rest api: /user/{id} return { id, name, age } 是一成不变的, graphql: findUser(id: xx) return { id, name } (注: 传输参数id, 指定返回字段 id, name, 当然也可以写{ name, age },完全取决于前端需求 ) |
三、代码开发
1.环境配置
Jdk1.8
graphql的依赖:
graphql-spring-boot-starter 5.0.2
graphql-java-tools 5.2.4
graphql GUI依赖(图形化工具):
graphiql-spring-boot-starter 7.1.0
2.新建demo
2.1 引入相关依赖
在新建的项目中,pom文件引入相关的jar。
2.2 编写业务代码
新建相关的entity、dao、service等
2.3 新建resolvers
GraphQL是通过实现GraphQLQueryResolver(空接口),在里面定义自己的方法处理数据,类似controller中的代码。我们在demo中新建QueryResolver(查询类) 和 MutationResolver(修改类)
2.4 graphql服务定义和scheme定义
一般情况下,我们都会在resources下面新建graphql文件夹,然后再里面定义root.graphqls 和schema.graphql两个文件。
resources/graphql/root.graphqls : 一般会在root.graphqls文件中放Query或者Mutation的接口定义:
# 定义查询的方法
type Query {
findAuthorById(id: Long!):Author
}
resources/graphql/schema.graphql:文件中定义type等数据对象
type Author {
id: Int!
firstName: String
lastName: String
}
2.5 配置文件application.yml文件
在配置文件需要配置GraphQL和GraphiQL Tool相关的配置
graphql:
servlet:
mapping: /graphql # 请求映射地址
enabled: true # 开启graphql
corsEnabled: true # 是否允许跨域
2.6测试
启动项目,访问http://localhost:8081/graphiql,看到如下界面
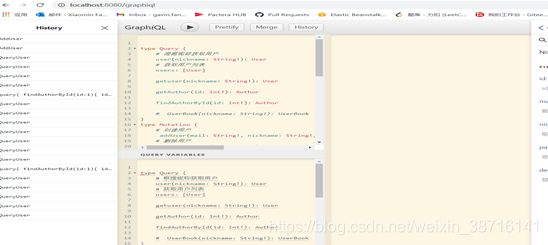
在左边的界面中输入如下的语法:
query{
findAuthorById(id:1){
id,
lastName,
}
}
然后点击执行Execute Query按钮,可以在右边看到返回的数据 :

3.多文件开发
上面的demo 只有一个root.graphqls。但是我们的项目是团队配合开发。且涉及到的表会有多个,如果在一个文件开发,不利于代码的开发和维护。因此,需要在/resources/graphql创建业务相关的文件。比如我们的author.graphqls/ book.graphqls等。
此处需要重点说明:
①文件里面必须使用extend继承Root Query,如果不使用extend的话,多个文件的话就不能都生效了。另外对于类型的声明也移到了一起统一管理。
②在root.graphqls文件中添加空的Query。否则服务启动报错(SchemaClassScannerError: Type definition for root query type 'Query' not found!)
代码如下:
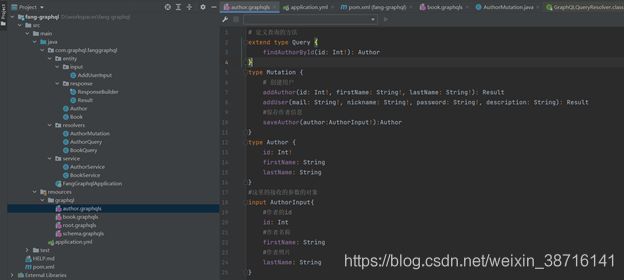
4.常见的查询语句
4.1 简单的查询
query{
findAuthorById(id: 1) {
id
lastName
}
}
或者
query QueryAuth($id: Int!){
findAuthorById(id: $id) {
id
lastName # 需要返回的字段
}
}
{"id": 2} # 在variables需要写的,入参
上面的QueryAuth是别名,可要可不要
4.2 联合查询
有时候需要查询多个接口。
query{
findAuthorById(id:1){
id,
lastName
},
findBookById(id:1){
id,
title,
isbn
},
findAuthorById(id:1){
id,
firstName
}
}
或者
返回值含有其他对象的:
query{
findBookAuthorById(id: 1) {
id
title
isbn
author{
id
firstName
}
}
}
4.3 简单的新增
与配置文件的参数对应起来。
mutation addAuthor{
addAuthor(id:1, firstName: "testuser11", lastName: "111") {
respCode
msg
}
}
4.4 新增使用对象接收
首先需要定义接收对象的类型。
mutation{
saveAuthor(author:{lastName:"小纤"}){
id,
lastName,
firstName
}
}
或者
# mutation 变更关键字
# AddUserByInput 别名
# mutation后$userinput,声明userinput变量,类型为AddUserInput
# 变量的类型AddUserInput,已经在graphqls文件中定义,input开头那个
# addUserByInput 接口名
# addUserByInput后input 入参类型
# addUserByInput后$userinput 入参变量引用
mutation saveAuthor ($userinput: AuthorInput) {
saveAuthor (input: $userinput) {
id
nickname
mail
}
}
在Variables中写入变量userinput具体的值,格式为JSON格式
{
"userinput": {
"mail": "[email protected]",
"nickname": "testuser2",
"password": "123456"
}
}
4.5使用curl进行查询
curl -i -X POST -d '{"query": "query {findAuthorById(id:1) {id,lastName}}"}' http://127.0.0.1:8081/graphql && echo
5.开发中的注意事项
1、单业务下,root.graphqls 里面主要是方法,schema.graphqls 主要是定义一些实体、返回值等。当然也可以把实体等直接放入root,不需要 schema文件。
2、如果是多文件操作(author.graphqls, book.graphqls),author.graphqls必须extend query,否则多文件不生效。root里面必须添加空的Query。否则服务启动报错找不到。
3、如果是多文件操作(author.graphqls, book.graphqls),.graphqls里面的方法名、类型等不能重复,否则启动报错,例如findById(),所有文件只能出现一次。
4、.graphqls文件里面的方法必须与resolvers里面的方法一致,如果resolvers没有.graphqls定义的方法,启动报错。
5、配置文件需要配置graphQL相关的配置项,否则找不到文件。
6、.graphqls文件 里面的 ‘!’(感叹号) 表示必填,不能为null。
7、GraphQL指定要返回的字段,可以使用逗号分隔,也可以使用空格或者换行符号。
8、同一个文件的extend type可以多个
四、总结
综上所述,GraphQL有着他的优点,但同时也存在一些缺点。
优点:
- 没有数据冗余和请求冗余 :按需返回
- 相对灵活而且参数是强类型的,不能修改
- 接口校验:对参数校验 !
- 接口变动,不需要维护文档
缺点:
- 迁移成本:老项目引入,需要修改很多的代码
- 牺牲性能:需要写很多的 resolver对应每个业务
- 缺乏动态类型:对于部分业务,比如业务建模那种非固定数据有限制
- 简单问题复杂化: REST API的情况下,我们不需要解析Response的内容,只需要看HTTP status code和message,就能知道请求是否成功,大概问题是什么,处理错误的程序也十分容易编写。GraphQL需要专门检查response的内容才知道是否有error。resolvers需要大量的样例代码。
- 有各种各样的Types, Queries, Mutators, High-order components需要写。相比之下,反倒是REST API更好编写和维护。
| RPC |
RESTFUL |
GraphQL |
|
| 优点 |
速度快 |
接入简单 |
查询方便,按需查询 |
| 缺点 |
耦合度高 |
接口管理问题 |
会增加架构复杂度 |
通过以上分析,GraphQL确实有他的好处,降低了沟通成本, 避免每次了定义api字段的多少问题,完全由前端自己选择,并且graphql 提供了GUI 可以很方便的测试。
个人认为对于简单业务的系统可以使用GraphQL来进行开发。对于微服务这种项目,GraphQL还是没有太大优势。除了返回值可以灵活以外, swagger 也可以将所有的API自动生成文档且可以进行测试,不需要额外的维护API文档。第二GraphQL需要去开发很多对应的resolvers以及.graphqls文件,对前端来说工作量确实是减少了,但是对于后端,新增了不少工作量,因为业务的处理代码都一样。
附上git地址:https://gitee.com/fangm886/fang-graphql.git