前端JS如何实现对复杂文本进行句子分割,将每句话拆分出来?
文章目录
-
- 切割句子背景简介
- 前端如何使用NLP?
- 技术实现
切割句子背景简介
开发中遇到一种场景,在做文本翻译这块需求时,需要对输入的原文进行一句一句话的拆分出来,传给后台,获取每句话的翻译结果,便于实现页面的翻译结果句句对照功能。
页面需要做的句句对照功能效果如下:

有尝试过正则匹配切割句子,但是不能满足复杂文本场景。
例如:
const text = "This is the first sentence. 这是第二句话50.05%。 这是the third sentence. 这是第四句话。 Here's the fifth sentence.";
// 匹配中英文句子的正则表达式
const regex = /([^\。.?!?!]+[.?!。?!])/g;
const sentences = text.match(regex);
console.log(sentences);
// ['This is the first sentence.', ' 这是第二句话50.', '05%。', ' 这是the third sentence.', ' 这是第四句话。', " Here's the fifth sentence."]
上面正则切割句子处理,虽然也能满足大部分场景,但仍存在不少场景无法满足,如上述会将文本中的百分比的小数点当作句子结尾给切割,还有其它场景下的标点符号、特殊符号等都会被错误处理,所以需要结合语言的上下文语境进行切割处理,这就需要借助自然语言处理(NLP)啦!
前端如何使用NLP?
对于写 Python 的人来说处理起来比较简单,因为 Python 有很多 NLP 第三方库可以引入,但是对于前端来说就没那么简单了,原因在于 NLP 依赖包的匮乏以及网上关于前端 NLP 处理的技术文章很难找到,毕竟这个工作应该需要后台来做而不是放在前端来处理,还有就是很多 NLP 处理不支持浏览器环境下运行,这也能理解,毕竟自然语言处理主要还是靠 Python 来写的。
在花费大量时间搜寻后,发现有 "sentence-splitter" 这么一个 NLP 库,但是相关使用文档也没能找到,所以还得是自己去实践,实践是检验真理的唯一标准!
技术实现
- 安装 NLP 相关库
npm install sentence-splitter
- 导入并使用
const sentenceSplitter = require('sentence-splitter'); // 借助自然语言处理库对句子切割
console.log(sentenceSplitter)
const text = "Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instructionfollowing dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available."
const sentences = sentenceSplitter.split(text); // 这一步已经切割完成了,下面操作是自己对拿到的数据自定义处理想要的格式。
console.log(sentences)
// 将 split 出来的单独空格字符拼接在一句话末尾处理。
const sentenceList = sentences.map(item => item.raw).reduce((prev, next) => {
!next.trim() ? prev[prev.length - 1] += next : prev.push(next)
return prev
}, [])
注意:在经过 console.log(sentenceSplitter) 打印出导入的 NLP 库的对象具体是什么数据后,才发现有 split 这个分割句子 API。打印出的 sentenceSplitter 结果如下:
{
"SentenceSplitterSyntax": {
"WhiteSpace": "WhiteSpace",
"Punctuation": "Punctuation",
"Sentence": "Sentence",
"Str": "Str",
"PairMark": "PairMark"
},
"DefaultSentenceSplitterOptions": {
"separatorCharacters": [
".",
".",
"。",
"?",
"!",
"?",
"!"
]
},
split: ƒ split(text, options),
splitAST: ƒ splitAST(paragraphNode, options),
__esModule: true,
get DefaultSentenceSplitterOptions: ƒ ()
}
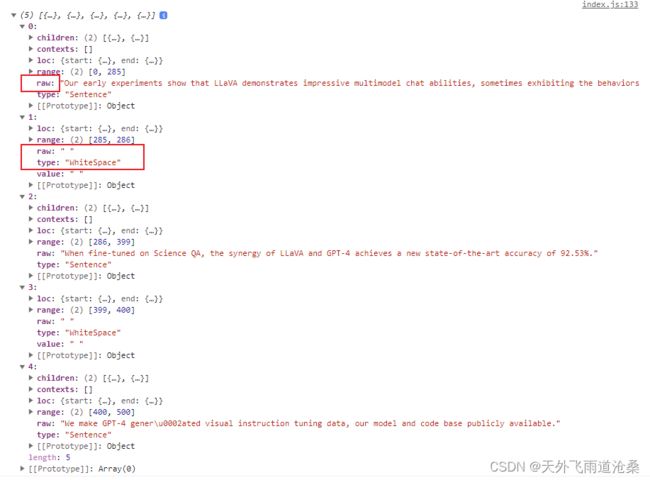
上面代码中: console.log(sentences) 打印出来sentenceSplitter.split(text)处理后的数据格式如下:
我们只需要取其中的 raw 就行,raw 就是切割出来的一句话内容,但英文不包括符号后面的空格,它会被单独按照一句话给切割出来,type 对应类型就是 WhiteSpace,我上面做了拼接在前一句句尾处理。
小结:亲测各种语言都能很好的按照语境进行切句!很棒的一个前端 NLP 处理库,建议收藏!以后直接用它简单多了!!