python第三方库概览
目录
第三方库的获取和安装
脚本程序转变为可执行程序的第三方库PyInstaller
jieba库(必选)、wordcloud库(可选)
知识导图:

1.Python第三方库的获取和安装
Python第三方库依照安装方式灵活性和难易程度有三个方法:pip工具安装、自定义安装和文件安装。
1.1 pip工具安装:
最常用且最高效的Python第三方库安装方式是采用pip工具安装。pip是Python官方提供并维护的在线第三方库安装工具。pip install <拟安装库名>,以pygame库安安装为例子:
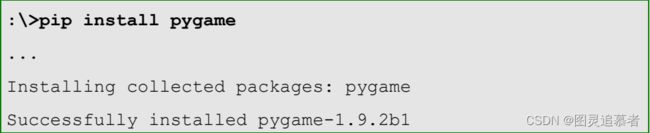
pip是Python第三方库最主要的安装方式,可以安装超过90%以上的第三方库。然而,还有一些第三方库无法暂时用pip安装,此时,需要其他的安装方法。pip工具与操作系统也有关系,在Mac OS X和Linux等操作系统中,pip工具几乎可以安装任何Python第三方库,在Windows操作系统中,有一些第三方库仍然需要用其他方式尝试安装。
1.2 自定义安装:
自定义安装指按照第三方库提供的步骤和方式安装。第三方库都有主页用于维护库的代码和文档。以科学计算用的numpy为例,开发者维护的官方主页是:http://www.numpy.org/,浏览该网页找到下载链接,进而根据指示步骤安装。
1.3 文件安装:
为了解决有些库文件直接使用pip安装失败的问题,美国加州大学尔湾分校提供了一个页面,帮助Python用户获得Windows可直接安装的第三方库文件,链接地址如下:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
界面如下:

库界面如下,以numpy为例:

这里以scipy为例说明,首先在上述页面中找到scipy库对应的内容。选择其中的.whl文件下载,这里选择适用于Python 3.5版本解释器和32位系统的对应文件:scipy- 0 . 1 7 . 1 - cp3 5 - cp3 5m-win3 2 .whl,下载该文件到D:\pycodes目录。 然后,采用pip命令安装该文件:

总结:
对于上述三种安装方式,一般优先选择采用pip工具安装,如果安装失败,则选择自定义安装或
者文件安装。另外,如果需要在没有网络条件下安装Python第三方库,请直接采用文件安装方
式。其中,.whl文件可以通过pip download指令在有网络条件的情况下获得。
1.4 pip工具的使用:
在dos窗体中执行pip -h或者pip命令将列出pip常用的子命令和一些常用说明:
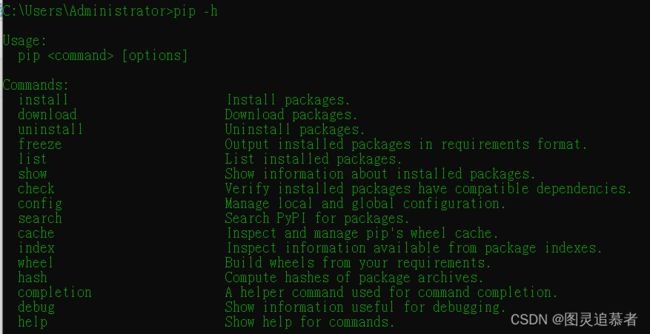
 pip支持安装(install)、下载(download)、卸载(uninstall)、列表(list)、查看(list)、查找(search)等一系列安装和维护子命令。
pip支持安装(install)、下载(download)、卸载(uninstall)、列表(list)、查看(list)、查找(search)等一系列安装和维护子命令。
pip的show子命令列出某个已经安装库的详细信息,格式如下:pip show <拟查询库名>
pip的download子命令可以下载第三方库的安装包,但并不安装,格式如下:pip download
pip的search子命令可以联网搜索库名或摘要中关键字,格式如下:pip search <拟查询关键字>
2.脚本程序转变为可执行程序的第三方库PyInstaller
PyInstaller是一个十分有用的Python第三方库,它能够在Windows、Linux、Mac OS X等操作系统下将Python源文件打包,变成直接可运行的可执行文件。通过对源文件打包,Python程序可以在没有安装Python的环境中运行,也可以作为一个独立文件方便传递和管理。
PyInstaller库的安装如下:pip install PyInstaller
使用PyInstaller库对Python源文件打包十分简单,使用方法如下:PyInstaller
执行完毕后,源文件所在目录将生成dist和build两个文件夹。最终的打包程序在dist内部与源文
件同名的目录中。
可以通过-F参数对Python源文件生成一个独立的可执行文件,如下:

执行后在dist目录中出现了SnowView.exe文件,没有任何依赖库,执行它即可显示雪景效果。
PyInstaller有一些常用参数:

3.jieba库
3.1 jieba库概述:
jieba(“结巴”)是Python中一个重要的第三方中文分词函数库。安装如下:pip install jieba ,由于中文文本中的单词不是通过空格或者标点符号分割,中文及类似语言存在一个重要的“分词”问题。
jieba库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动
态规划方法找到最大概率的词组。除了分词,jieba还提供增加自定义中文单词的功能。
jieba库支持三种分词模式:精确模式,将句子最精确地切开,适合文本分析;全模式,把句子中
所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式
基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。对中文分词来说,
jieba库只需要一行代码即可。

3.2 jieba库与中文分词:
jieba.lcut(s)是最常用的中文分词函数,用于精准模式,即将字符串分割成等量的中文词组,返回
结果是列表类型。

jieba.lcut(s, cut_all = True)用于全模式,即将字符串的所有分词可能均列出来,返回结果是列表
类型,冗余性最大。

jieba.lcut_for_search(s)返回搜索引擎模式,该模式首先执行精确模式,然后再对其中长词进一
步切分获得最终结果。

搜索引擎模式更倾向于寻找短词语,这种方式具有一定冗余度,但冗余度相比全模式较少。 如果希望对文本准确分词,不产生冗余,只能选择jieba.lcut(s)函数,即精确模式。如果希望对文本分词更准确,不漏掉任何可能的分词结果,请选用全模式。如果没想好怎么用,可以使用搜索引擎模式。
jieba.add_word()函数,顾名思义,用来向jieba词库增加新的单词。

4.wordcloud库
4.1 wordcloud库概述:
词云以词语为基本单元,根据其在文本中出现的频率设计不同大小以形成视觉上不同效果,形成
“关键词云层”或“关键词渲染”,从而使读者只要“一瞥”即可领略文本的主旨。wordcloud库是专门用于根据文本生成词云的Python第三方库,十分常用且有趣。装wordcloud库在Windows的cmd命令行使用如下命令:pip install wordcloud
wordcloud库的使用十分简单,以一个字符串为例。其中,产生词云只需要一行语句,在第三行,
并可以将词云保存为图片。

4.2 wordcloud库与可视化词云:
在生成词云时,wordcloud默认会以空格或标点为分隔符对目标文本进行分词处理。对于中文文
本,分词处理需要由用户来完成。一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数。

wordcloud库的核心是WordColoud类,所有的功能都封装在WordCloud类中。使用时需要实
例化一个WordColoud类的对象,并调用其generate(text)方法将text文本转化为词云。WordCloud对象创建的常用参数:

WordCloud类的常用方法:

下面以Alice梦游仙境为例,展示参数、方法的使用。

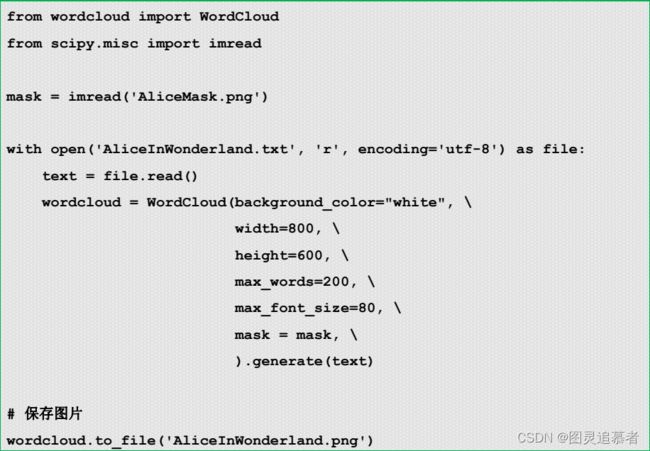
其中,from scipy.misc import imread一行用于将AliceMask.png读取为nd-array类型,用于后面传递给mask参数使用。(这个库函数隶属于scipy库,pip在安装wordcloud库时会自动安装依库。)