IM 架构设计03 读扩散 && 写扩散
https://blog.csdn.net/z50L2O08e2u4afToR9A/article/details/86746814
https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651961230&idx=1&sn=b2ab831a72f54950498d43ac01e26453&chksm=bd2d02528a5a8b444050c242729f764d6435185feb015f81631d75b018b9760b1a90a467e817&scene=21#wechat_redirect
系统通知,究竟是推送还是拉取?
任何脱离业务场景的架构设计都是耍流氓。
广义系统通知,有1对1的通知,以及一对多的通知,有相对实时的业务通知,以及能够容忍一定延时的系统通知。结合具体的场景来看下,这样的一些系统通知,究竟是推还是拉?
一、系统对1的通知
典型业务,计数类通知:
-
有10个美女添加了你为好友
-
有8个好友私信了你
很多业务经常有这类计数通知,通知结果只针对你,这类通知是推送,还是拉取的呢?常见的有这样一些实践:
如果业务需求对计数需求需要实时展现,例如微博的加好友计数,假如希望实现不刷新网页,计数就实时变化:
-
登录微博时,会有一个计数的拉取,对网页端的计数进行初始化
int getCountByType(int countType)
-
在浏览微博的过程中,一旦有人加你为好友,服务端对网页端进行实时推送,告之增加了1个(或者N个)好友
int addCountByType(int countType, int diff)
这里的思路是,一开始得到初始值,后续推送增量值,由网页端计算最终计数并呈现最终结果。需要注意,针对不同业务,计数变化的差值可增可减。
上述方案的坏处是,一旦有消息丢失,网页端的计数会一直不一致,直至再次登录重新初始化计数。这个计算计数可以优化为在服务器直接计算并通知网页端最终的结果,网页端只负责呈现即可,这样网页端的逻辑会变轻。
如果业务对此类通知的展现不需要这么实时,完全可以通过拉取:
-
只有在链接跳转,或者刷新网页时,才重新拉取最新的通知,例如上述计数
int getCountByType(int countType)
这样系统的实现会最简单。需要注意,通知拉取要异步,不要影响主页面的快速返回。
系统对1的推送,例如针对1个用户的业务计数推送,计数的变化频率其实非常低,使用cache来存储这些计数能够极大提升系统性能。
更多计数系统架构实践可详见《计数系统架构实践一次搞定》。
二、系统对多的通知
系统对多的通知消息,会比系统对1的通知消息复杂一些,以两个场景为例:
-
QQ登录弹窗新闻
-
QQ右下角弹窗广告
IM登录弹窗新闻
这个通知的需求是:
-
同一天,用户登录弹出的新闻是相同的(很多业务符合这样的场景),不同天新闻则不一样(但所有用户都一样)
-
每天第一次登录弹出新闻,当天的后续登录不出新闻
不妨设有一个表存放弹窗新闻:
t_msg(msg_id, date, msg_content)
有一个表来存放用户信息:
t_user(user_id, user_info, …)
有一个表来存放用户收到的新闻弹窗:
t_user_msg(user_id, msg_id, date)
这里的实现明显不能采用推送的方式:
-
将t_user_msg里对于所有user_id推送插入一个msg_id,表示未读
-
在user每天第一次登录的时候,将当天的msg_id拉取出来,并删除,表示已读
-
在user每天非第一次登录的时候,就拉取不到msg_id于是不会再次弹窗
这个笨拙的方式,会导致t_user_msg里有大量的脏数据,毕竟大部分用户并不会登录。
如果改为拉取的方式会好很多:
-
在user每天第一次登陆时,将当天的msg_id拉取出来,并插入t_user_msg,表示已读
-
在user每天非第一次登陆时,则会插入t_user_msg失败,则说明已读,不再进行二次弹窗展现
这个方式虽然有所优化,但t_user_msg的数据量依然很大。
还有一种巧妙的方式,去除t_user_msg表,改为在t_user表加一列,表示用户最近拉取的弹窗时间:
t_user(user_id, user_info, last_msg_date, …)
这样业务流程会升级为:
-
在user每天第一次登录时,将当天的msg_id拉取出来,并将last_msg_date修改为今天
-
在user每天非第一次登录时,发现last_msg_date为今天,则说明今天已读
这种方式不再存储消息与用户的笛卡尔关系,数据量会大大减少,是不是有点意思?
IM右下角弹窗广告
这个通知的需求是:
-
每天会对一批在线用户推送相同的弹窗TIPS广告,例如球鞋广告,手机广告等
画外音:如果1个推送一块钱,5KW用户推送收入就有5KW收入哟,一天推个几次,实现1个亿的小目标居然如此简单。
最直观的感受,这是一个for循环批量推送的过程。如果是推送,必须要考虑的问题是,推送限速控制,避免短时间内对系统造成冲击,引发雪崩。
能不能用拉取呢?
完全可以,这是一个对实时性要求不太高的场景,用户早1分钟晚1分钟收到这个广告影响不大,其实可以借助IM原本已有的keepalive请求,在请求返回时,告之“有消息拉取”,然后采用拉取的方式拉取广告消息。
这个方案的好处是,由于5KW在线用户的keepalive请求是均匀的,所以可以很均匀的将广告拉取的请求同样均匀的分散到一段时间内,避免5KW集中推送对系统造成冲击。
三、总结
广义系统通知,究竟是推送还是拉取呢?不同业务,不同需求,实现方式不同。
系统对1的通知:
-
实时性要求高,可以推送
-
实时性要求低,可以拉取
系统对N的通知:
-
登录弹窗新闻,拉取更佳,可以用一个last_msg_date来避免大量数据的存储
-
批量弹窗广告,常见的方法是推送,需要注意限速,也可以拉取,以实现请求的均匀分散
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
状态同步,究竟是推还是拉?
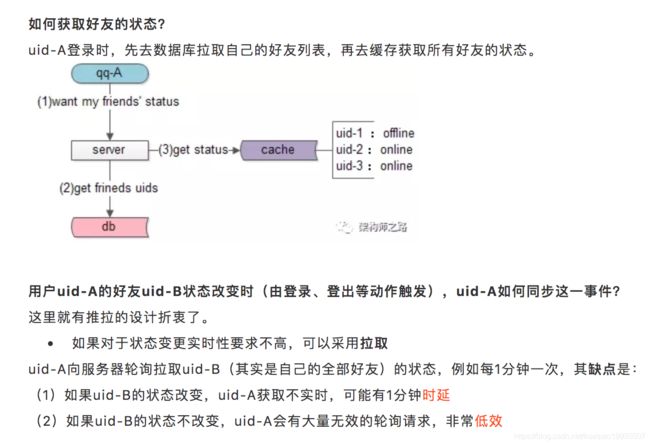
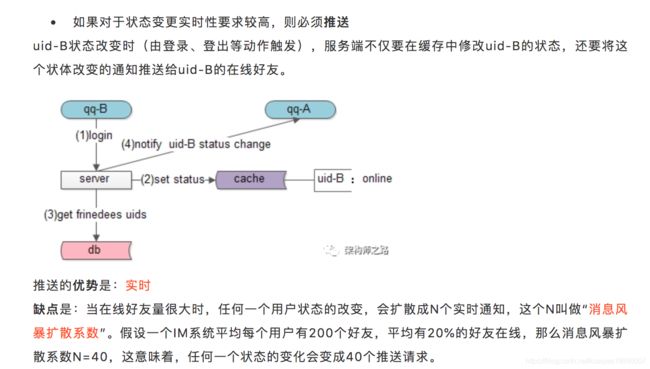
什么是服务端状态?
服务端状态,主要分为在线online和离线offline,不同的状态,对于不同的业务处理流程可能不同。例如对于消息的处理:
-
服务端状态在线,直接投递给用户
-
服务端状态离线,直接存储离线消息,等用户下一次登录拉取

什么是客户端状态?
不同的产品,会有不同的客户端状态,例如隐身、离线、忙碌、勿扰等,这些状态大多是产品功能需求。有的产品,例如微信,在设计之初,就摒弃了用户端状态这个概念。
后文为了方便描述,不妨设待讨论的是QQ这种拥有客户端状态的产品,并假设客户端状态也只有在线和离线两种状态,后文统一称为“用户状态”。


+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
网页端收消息,究竟是推还是拉?
消息的接收方,也就是用户A,如果是在网页端登录,因为HTTP协议是“请求-响应”式的,服务端与网页之间没有消息通道,对于这类“收消息”的需求,是如何处理的呢?
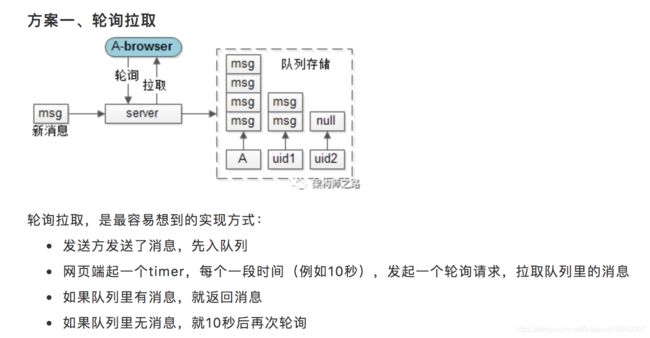
缺点也很明显:
-
实时性差:最坏的情况下,1条消息进入队列后,10s之后才会收到
-
效率低下:发消息是一个低频动作,如果10次轮询才收到1条消息,请求有效性只有10%,浪费了大量服务器资源
更要命的是,在这种方案下,实时性与效率是一对不可调和的矛盾:如果将轮询周期设为1/10,将时延缩短到1秒,意味着100次轮询才会收到1条消息,请求有效性则降为了1%。
方案二、建立长连接
如果要兼顾实时性和效率,长连接是最佳之选,PC端聊天软件基本都是使用长连接。网页端常见的实现长连接的方式有两种:
-
WebSocket
-
FlashSocket
这两种方案的细节不再展开,ta们均有一定的局限性。
更为通用的方式,是“长轮询”。
长轮询,是通过拼装HTTP短连接来达到长连接的效果,即保证了消息100%实时,又最大化的系统效率。

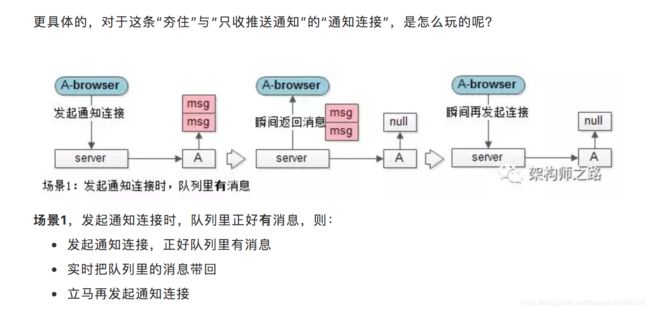

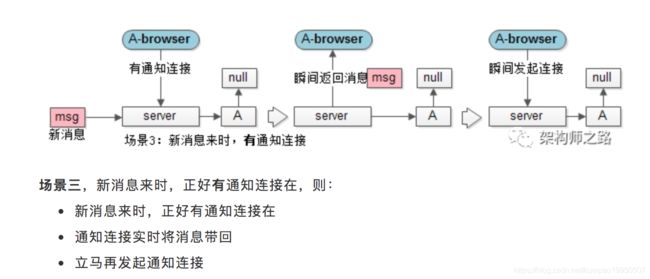

总结
网页端收消息,究竟是推还是拉?
-
最容易想到的是拉,但实时性和效率是一对无法调和的矛盾
-
最佳的方式是推,但WebSocket和FlashSocket各有局限性
-
最通用的方式是长轮询,通过HTTP短连接拼装长连接,具体是通过“夯住”“只收推送通知”的“通知连接”来实现的,能够做到消息的实时性到达
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
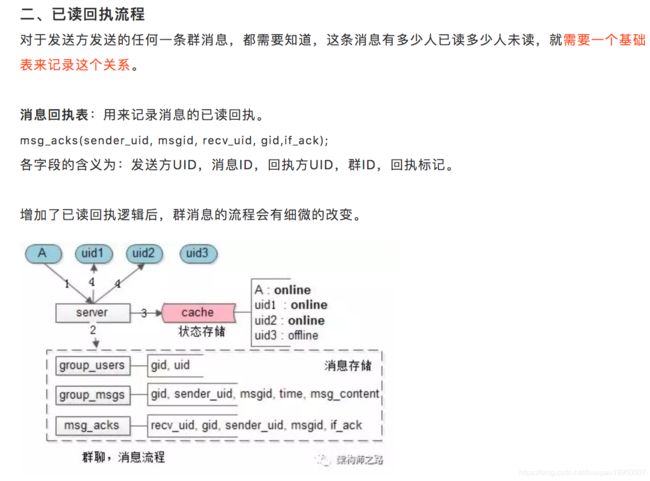
群消息已读回执(这个diao),究竟是推还是拉?
一、群消息投递流程,以及可达性保证
大家一起跟着楼主的节奏,一步一步来看群消息怎么设计。
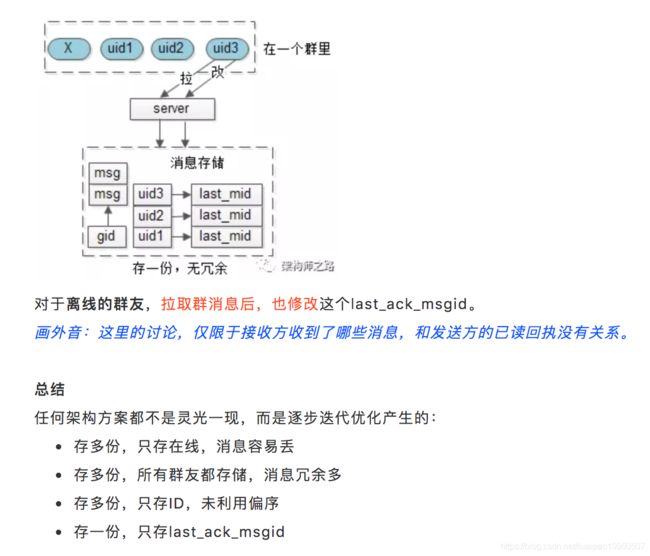
核心问题1:群消息,只存一份?还是,每个成员存一份?
答:存一份,为每个成员设置一个群消息队列,会有大量数据冗余,并不合适。
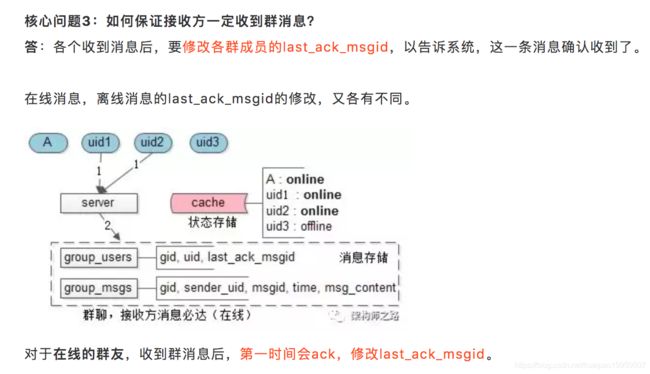
核心问题2:如果群消息只存一份,怎么知道每个成员读了哪些消息?
答:可以利用群消息的偏序关系,记录每个成员的last_ack_msgid(last_ack_time),这条消息之前的消息已读,这条消息之后的消息未读。该方案意味着,对于群内的每一个用户,只需要记录一个值即可。
解答上述两个核心问题后,很容易得到群消息的核心数据结构。
群消息表:记录群消息。
group_msgs(msgid, gid, sender_uid, time, content);
各字段的含义为:消息ID,群ID,发送方UID,发送时间,发送内容。
群成员表:记录群里的成员,以及每个成员收到的最后一条群消息。
group_users(gid, uid, last_ack_msgid);
各字段的含义为:群ID,群成员UID,群成员最后收到的一条群消息ID。

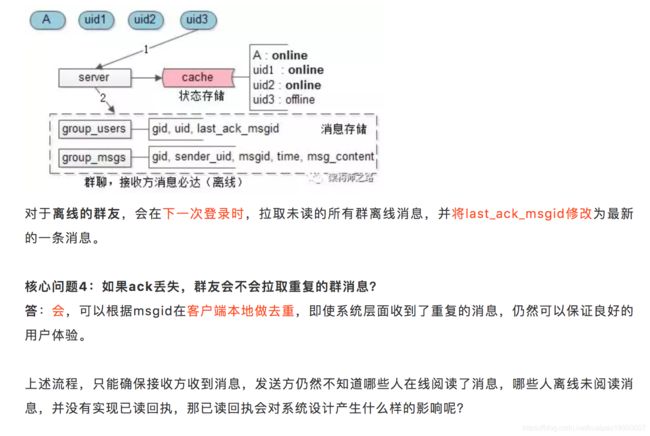
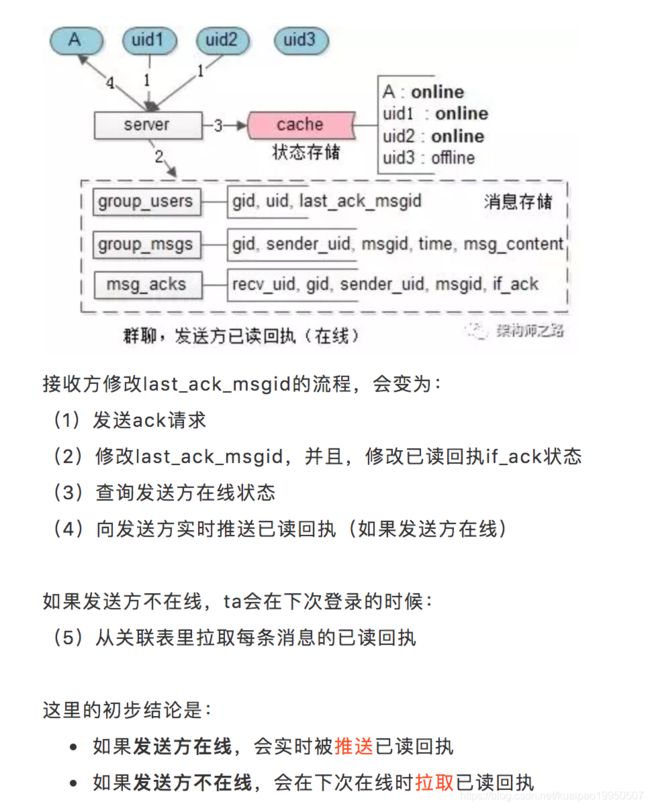
步骤二,server收到消息后,除了要:
-
将群消息落地
-
查询群里有哪些群成员,以便实施推送
之外,还需要:
-
插入每条消息的初始回执状态

群消息的推送,能否改为接收方轮询拉取?
答:不能,消息接收,实时性是核心指标。
对于last_ack_msgid的修改,真的需要每个群消息都进行ack么?
答:其实不需要,可以批量ack,累计收到N条群消息(例如10条),再向服务器发送一次last_ack_msgid的修改请求,同时修改这个请求之前所有请求的已读回执,这样就能将40个发送给服务端的ack请求量,降为原来的1/10。
会带来什么副作用?
答:last_ack_msgid的作用是,记录接收方最近新取的一条群消息,如果不实时更新,可能导致,异常退出时,有一些群消息没来得及更新last_ack_msgid,使得下次登陆时,拉取到重复的群消息。但这不是问题,客户端可以根据msgid去重,用户体验不会受影响。
发送方在线时,对于已读回执的发送,真的需要实时推送么?
答:其实不需要,发送方每发一条消息,会收到40个已读回执,采用轮询拉取(例如1分钟一次,一个小时也就60个请求),可以大大降低请求量。
画外音:或者直接放到应用层keepalive请求里,做到0额外请求增加。
会带来什么副作用?
答:已读回执更新不实时,最坏的情况下,1分钟才更新回执。当然,可以根据性能与产品体验来折衷配置这个轮询时间。
如何降低数据量?
答:回执数据不是核心数据
-
已读的消息,可以进行物理删除,而不是标记删除
-
超过N长时间的回执,归档或者删除掉
四、总结
对于群消息已读回执,一般来说:
-
如果发送方在线,会实时被推送已读回执
-
如果发送方不在线,会在下次在线时拉取已读回执
如果要对进行优化,可以:
-
接收方累计收到N条群消息再批量ack
-
发送方轮询拉取已读回执
-
物理删除已读回执数据,定时删除或归档非核心历史数据
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
群消息,究竟存1份还是多份?
今天就聊一聊,群消息,为啥只需要存一份。
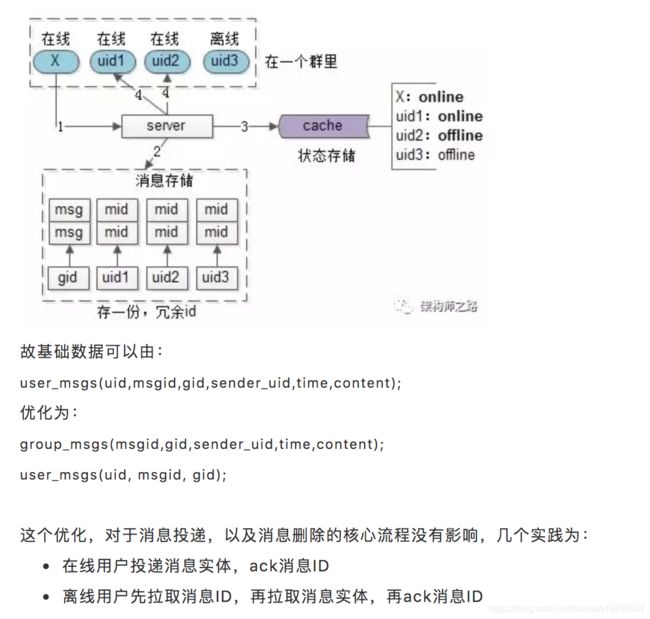
群信息,用户信息,群成员关系都是基础数据:
group_info(gid, group_info);
user_info(uid, user_info);
group_members(gid, uid);
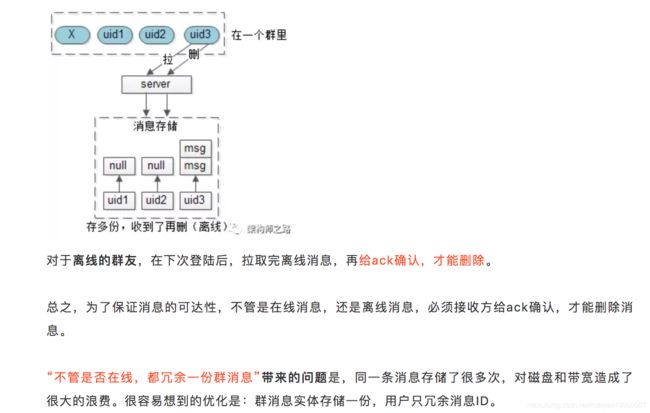
假设一个群(gid)里有4个成员,其中三个在线(A, uid1, uid2),一个不在线(uid3)。
A发送了一条消息,很容易想到,对于不同的群友消息存多份,每个群友一个队列来存储。但由于在线的用户会实时的收到消息,所以暂定只为离线的用户存储。
用户收到的群消息,也是基础数据:
user_msgs(uid,msgid,gid,sender_uid,time,content);





feed流拉取,读扩散,究竟是啥?


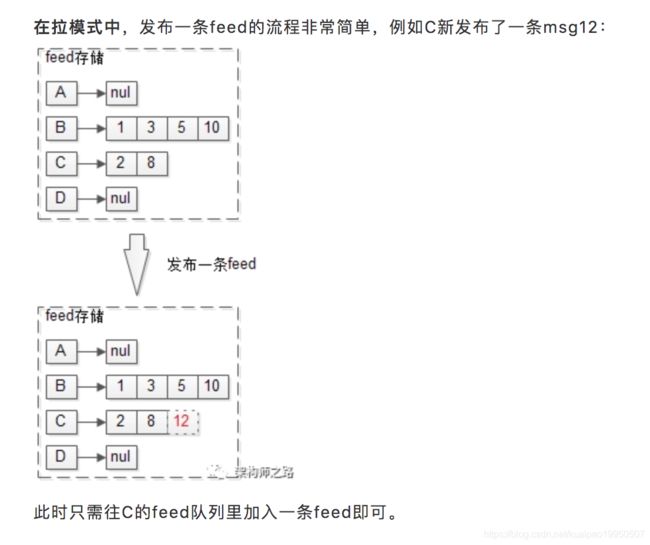

朋友圈微博feed流,推拉实践
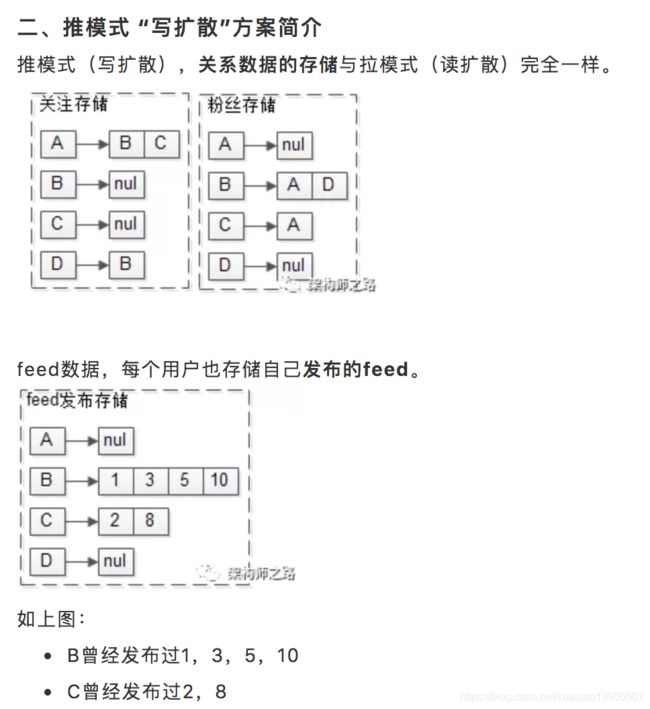

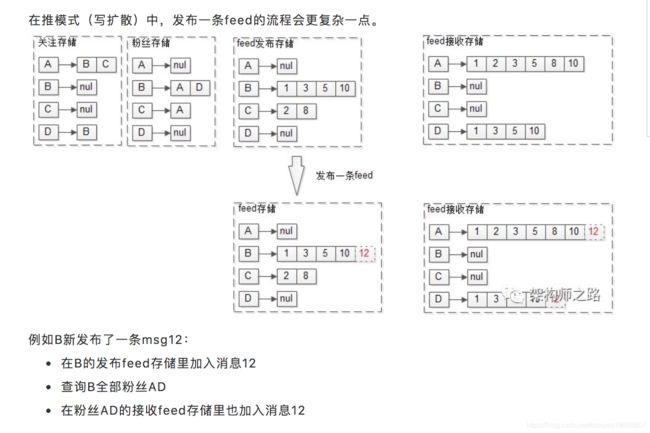
之所以该方案称为推模式(写扩散),就是因为,用户发布feed的时候:
-
直接将feed推到了粉丝的接收列表里,故称为“推模式”
-
不止写发布feed存储,而且要写多个粉丝的接收feed存储,故称为“写扩散”
例如D新增关注C:
-
在D的关注存储里添加C
-
在C的粉丝存储里添加D
-
在D的接收feed存储里加入C发布的feed
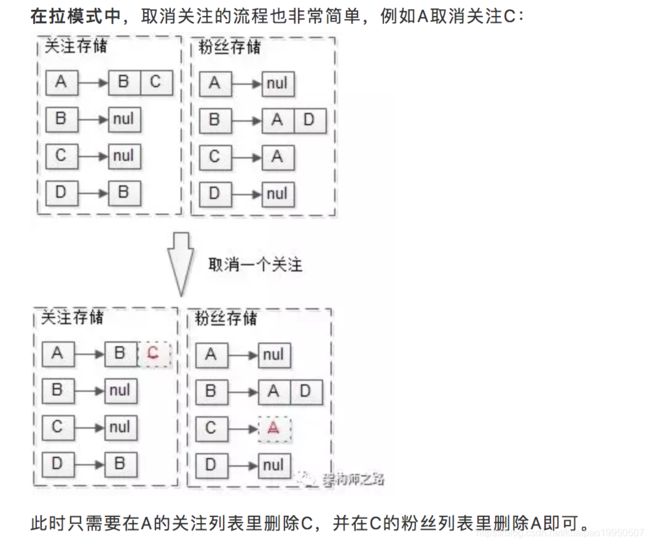
例如A取消关注C:
-
在A的关注存储里删除C
-
在C的粉丝存储里删除A
-
在A的接收feed存储里删除C发布的feed

三、小结
feed流业务的推拉模式小结:
-
拉模式,读扩散,feed存一份,存储小,用户集中访问数据,性能差
-
推模式,写扩散,feed存多份,用冗余存储换锁冲突,性能高