LVS 工作原理图文讲解新
LVS原理概述
负载均衡就是,在多个提供相同服务主机的前段,增加一个分发器,根据用户请求,然后根据某种方式或者策略,将用户请求分发到提供服务的主机上。同时负载均衡应用还应该提供对后其后端服务健康检查的功能。
如何转发取决于调度算法,有2种算法一个是RR一个是WRR。用户看到的是负载均衡的地址,一般还会对负载均衡做高可用,这样才能保证业务的持续性。
负载均衡有2大类:
- 硬件:F5的BIG IP;Citrx的Netcaler
- 软件:
- 四层负载均衡(LVS):TCP/IP层,类似一个路由设备,根据用户请求的套接字(三层IP)和四层的端口协议类型,将请求分发至后端主机。LVS的发明者是中国人。
- 七层负载均衡(Nginx和Haproxy):Nginx主要是对HTTP、SMTP、POP3和IMAP协议做负载均衡,是一个7层代理,只负责解析有限的7层协议;Haproxy主要是对HTTP做负载均衡,另外还可以对常见的TCP/IP层应用做负载均衡,比如MYSQL,还有SMTP。
四层和七层的有什么区别?
一般七层的负载均衡叫做代理或者叫反向代理。四层和七层的主要区别在于四层只解析到TCP/IP层,它不在解析更高层,说白了就是不再继续拆包,所以四层的比七层的性能更好,但是缺点是没有高级特性,网康设备就是工作在七层的,所以它可以有很多高级功能,比如查看用户访问了那些网站,其实就是对HTTP请求做的解析。对负载均衡设备来说,工作在七层的可以根据用户请求的URL来做负载均衡。而且七层负载均衡一般都是针对特定一种或者几种(不会是所有,也就是针对某一个方面)做解析,同时它还支持对解析出来的东西做一些修改然后在向后端分配。不过相对来讲七层的性能比四层的略低(在相同硬件配置和相同请求量的前提下),不过在生产环境中七层的更能贴近实际需求,所以在选择使用哪种负载均衡的时候要根据业务特性和需求来进行判断。
LVS可以解析三层和四层请求,只要是TCP/IP协议都可以解析,假设一个WEB服务器集群,使用默认80端口,其中一台主机是172.16.100.1,如果负载均衡器收到一起请求,那么它就会把请求转发到该主机上,这个过程有点类似于NAT,但是还不同,因为它可以向后转发到多台主机上。
DNAT的工作过程:
用户请求IP:PORT地址A(这个地址是路由器的地址),路由器收到这个地址后会查看自己的过滤表,如果找到匹配的配置项,就会修改数据包的目标地址为后端主机的真实地址,然后把数据包放到转发队列,然后进行转发。如果发现没有匹配项,则认为这个请求是请求给路由器自己的,因为请求带有端口号,路由器会检查自己是否开启了对应端口的进程,如果有就说明是访问该进程的,如果没有就会给请求发起方报错。
LVS其实也是借鉴了DNAT的工作方式,LVS工作在Linux的内核空间上。但是不同的是LVS收到请求会直接修改请求的数据包中的目标地,然后进行转发。
在Iptables中,ipbables只是用来写规则的,真正执行的是netfilter;在LVS中也是类似的结构,ipvsadmin是管理工具(工作在用户空间的工具),ipvs是执行的且工作在内核中。Ipvs是工作在input链上(Input链是Iptables所用的到的Linux内核框架的一部分),一旦用户请求到了input链,就会被IPVS捕获,然后IPVS就会去检查数据包,如果它发现请求是一个集群服务就会修改数据包,然后转发。如果IPVS发现这个请求不是对集群服务的请求,就会把这个请求转发到用户空间(Linux系统的用户空间)。这一点和iptables有点不太一样,所以iptables和LVS不能同时在一台Linux主机上使用。所以LVS中的IPVS必须工作在内核中。所以基于IP和端口的转发就是四层转发。
一个负载均衡调度器可以为多个集群服务提供服务,功能上可以,但是出于性能考虑一般不会这么做,所以一个负载均衡调度器只会为一个集群服务提供服务。
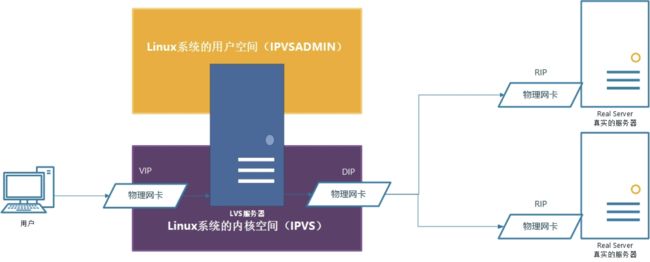
LVS的服务器有2个网卡,对外接收请求的网卡的IP叫做VIP,也就是虚拟IP,其实也是真实的IP地址,至少这样称呼,相对于内部真正的应用服务器而言;对内的网卡的IP叫做DIP,也就是转发IP;而真实的应用服务器网卡的IP叫做RIP。用户电脑的IP叫做CIP。
LVS的三种类型
LVS-NAT模式

对于这种类型,负载均衡调度器需要有2个网络接口,一个面对互联网,一个面对内网,也就是上面的图形。属于串联模式。相当于在LVS后面组成一个私有网络。
实现原理就是把用户的请求的地址修改为后端真是服务器的IP地址来然后进行转发。工作机制和DNAT一样。
源地址是CIP,目标地址是VIP,然后修改数据包,挑选一个后端服务器,然后就把数据包转发到该后端服务器,这时候数据包的源IP是CIP,目标IP则是某一台主机的RIP。
当主机返回信息的时候,转发器会在做一次转发,修改数据包。
在这种模式下对于用户请求的进出都要经过转发器,所以转发器的压力相对较大。在这种模式下后端应用最多10个,但一般都会少于10个。
基本法则:
- 转发器、应用服务器都要在同一子网中(转发器的DIP和应用服务器组成一个私有网络)
- 应用服务器的网关要指向DIP
- RIP通常都是私有地址,而且仅可以和DIP通讯
- 转发器可以实现端口映射,例如80转换到8080
- 应用服务器可以是任何操作系统
- 单一转发器可能成为整个集群的瓶颈尤其是在大规模场景下
一般企业不使用NAT模型,哪怕应用服务器比较少。
缺陷:转发器和应用服务器必须在同一子网中
LVS-DR 直接路由模式
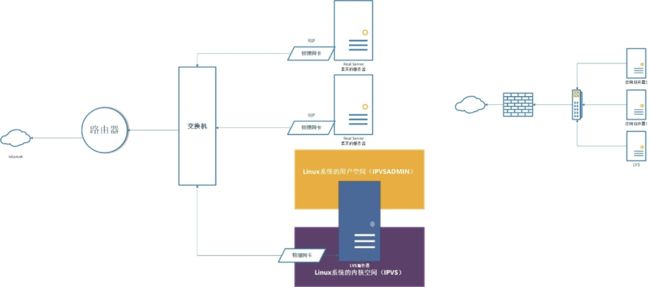
LVS服务器和应用服务器都是单网卡,LVS和应用服务器并联在交换机上。
在这个模型上就是请求进来被发送到LVS上,LVS的内核空间的IPVS截取,然后分析,如果是访问集群服务,就转发到被LVS选中的应用服务器上,应用服务器处理完成后,直接返回数据给客户端,而不再经过LVS,这样就减少了LVS的工作负担,同时应用服务器也不用和LVS组成一个私有网络。
这里就有一个问题,我们知道转发器在会把数据包中的目标IP更换为RIP进行转发,那么应用服务器处理完成后返回结果,返回数据包的源IP会是RIP,目标IP则是CIP,这时就不对了,因为请求进来的时候目标IP是LVS上的VIP。所以为了解决这个问题,LVS和所有应用服务器上都配置了VIP。
那么这里就又有一个问题,如果都配置相同的VIP,那么就会冲突,而且路由器也不知道该发给谁,所以这里就用到了网卡别名。在LVS上它其实配置了VIP和DIP,虽然只有一个网卡,VIP配置在网卡上,DIP配置在网卡别名上。在应用服务器上,RIP是不同的这个是肯定的,VIP是一样的,这个VIP也是配置在网卡别名上而且是隐藏的,它不用来接收任何请求,接收数据还是RIP来完成,这个VIP只有在应用服务器响应请求的时候把它作为源地址时使用,当然实际使用的网卡开始那个配置了RIP的网卡,在通讯层面上VIP不起作用,它只是作为数据包的源地址使用。
不过需要注意的是,在DR模式中,转发器会修改请求的数据包的地址,但是修改不是把VIP替换成RIP,而是修改了地址(源MAC和目标MAC)。因为从路由器进来以后,会把报文封装成帧,会加入源MAC和目标MAC,路由器的内网口会把源MAC地址写成自己的内网口MAC,目标写成LVS物理网卡的MAC地址,然后LVS收到以后会修改帧里面的目标MAC地址(原来为LVS网卡的MAC地址)为被挑选的应用服务器的MAC地址,修改源MAC地址(原来路由器内网口的MAC地址)为自己网卡的MAC地址,而不是修改目标IP地址。
当应用服务器收到数据包以后,拆掉MAC地址,看到的数据包的源IP是CIP也就是客户端的IP,而目标IP就是VIP,而且应用服务器上通过网卡别名已经设置了VIP,所以它会认为这就是个自己的。处理完请求后需要返回数据,因为客户端是请求的VIP,所以应用服务器就用VIP来封装数据包,这样就直接响应出去了,而不需要再经过LVS。
这样的话就LVS的性能就会有很大提高,因为请求数据包都很小,响应报文都比较大。
说明:无论是否是DR模式,来自网络层的IP报文都最终都会被封装成帧。所以路由器接收到IP数据包之后会先到到数据链路层后经过LLC子层和MAC子层进行协议头封装,最终形成以太网MAC帧,送达到主机。
基本法则:
- 集群节点和转发器必须在同一物理网络内,因为它使用MAC地址转发
- RIP的地址可以使用公网IP
- 转发器仅处理入栈请求,响应报文由应用服务器之间发往客户端
- 集群节点不能使用DIP作为网关
- 这种模式下转发器不支持端口映射
- 大多数操作系统都可以是应用服务器,因为应用服务器需要隐藏VIP
- DR模式性能强,可以处理比NAT模式更多的主机
缺陷:所有应用服务器都暴露在公网,就算它用私有地址,但是也要保障它可以和互联网直接通讯,否则它响应的报文无法到达客户端。
LVS-TUN 隧道模式
DR模式下集群节点要在同一物理网络内,那有一种场景如果要实现异地容灾,两个机房在不同城市甚至是不同国家,那怎么办?这就用到隧道模式。
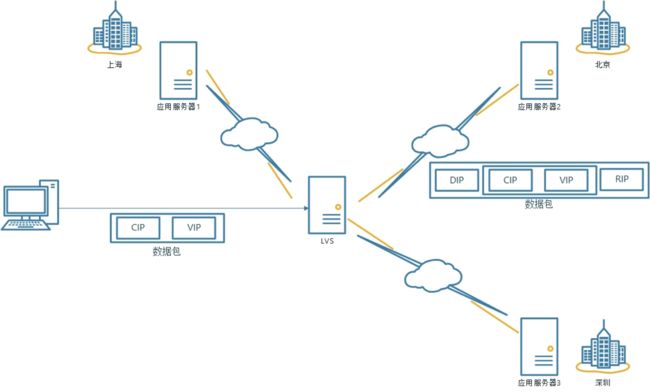
在隧道模式下LVS即不替换VIP也不修改MAC地址,而是通过在数据报文外层再套一层报文来封装。
因为客户端请求发过来的时候源IP是CIP,目标IP是VIP,所以LVS要转发到其他地区的应用服务器上这只能在三层协议上进行也就是IP报文,如果你替换了VIP,那么应用服务器响应客户端的时候就有问题,所以就会在原有的IP报文上在套一层来封装,把LVS的DIP作为源IP,而应用服务器的RIP作为目标IP,然后进行转发。当应用服务器收到数据包以后,拆开第一层,然后发现里面的数据包有CIP和VIP,应用服务器上也有VIP(跟DR模式一样使用网卡别名然后隐藏),就会认为是发给自己的,然后做出处理最后响应请求,同时封装响应请求的时候目标是CIP,源IP则使用VIP地址。
在这种模式下LVS和应用服务器要支持隧道机制。
基本法则:
- 集群节点可以跨越互联网部署
- 应用服务器的RIP必须是公网地址(可路由的)
- 转发器仅处理入栈请求
- 响应报文直接发送给客户端不经过LVS,也就是说应用服务器的网关指向公网网关
- 支持隧道功能的操作系统才可以成为应用服务器
- 不支持端口映射
LVS-FULLNAT 模式
Linux内核发展到2.6.32以后才引入的一种类型,这个类型必须要打补丁才能使用。不过现在大多使用CentOS 7所以无需补丁。
这个模型是采用NAT基础但是解决了应用服务器和调度器可以在不同子网中。因为是NAT模型所以应用服务器就不会暴露在互联网上,同时也实现了应用服务器可以跨网段部署。

所谓FULLNAT就是把数据包的源地址和目标地址都做修改,入栈的时候把CIP +VIP的数据包修改为DIP+RIP的数据包,这样就可以发送到应用服务器上,当应用服务器响应请求的时候,同样适用DIP+RIP的数据包,这样就保障肯定会发到LVS主机上,然后调度器再次修改数据包的源地址和目标地址,改成CIP+VIP然后发送给客户端。
LVS的调度算法
调度算法就是从LVS的后端应用服务器中挑选一个进行转发。调度算法有10种,那么10种又分成2大类,静态方法和动态方法。
静态方法:
只根据算法本身进行调度和分配请求,这种方法中RR和WRR有缺陷就是用户会话无法保持,比如在电商网站上,用户第一次的请求被转发到了A服务器,用户第二次的操作请求被转发到了B服务器,所以这就造成了用户第一次会话请求数据丢失。所以要想解决就只能使用Session复制或者建立单独的服务器。
- RR,也就是轮询一个挨一个的逐个转发,这种方法不考虑服务器本身的硬件性能。
- WRR,加权轮询,也就是给每个服务器设置权重,权重高的多分配。
- SH:源地址哈希,这个方法主要是增加了实现Session绑定功能,只要来源于同一个IP的就定向到相同的应用服务器。但是它反均衡,就是会把同一IP地址出口的所有请求都转发到同一服务器,比如一般公司出口IP是一个,几几百人都用这一个公网IP上网。因为LVS是工作在四层的,所以它也只能根据IP来识别会话。无法像F5那样七层设备根据COOKIE来识别,COOKIE对于每一个计算机来说都是唯一,即使大家都用同一公网IP上网。
- DH:目标地址哈希,这个应用场景不多,它主要的作用就是保证在LVS前面有多台防火墙的时候,用户请求从哪个防火墙进来最后响应也从哪个防火墙出去。
动态方法:
根据算法和应用服务器的负载情况综合分析来觉得转发到哪个应用服务器。
- LC(Least Connection):最少链接数方法。也就是哪个服务器的连接数少就给哪个的,但是在TCP中,连接有2种状态,一个是正在传送数据的叫做活动连接、另外一个是没有传输数据但是连接没有断叫做非活动连接,这两种连接所需要的资源是不同的,显然活动连接需要服务器的资源多,而非活动连接仅需要维持一个与服务器的会话就行。所以这种方法是考虑应用服务器的负载(活动连接数*256+非活动连接),这个计算结果数小的胜出,如果结果都一样就轮询。不过这种方法是不考虑权重的,其基本方法还是轮询,只是增加了一个计算负载的前置条件。
- WLC(Weighted LC):加权最少连接算法,这个算法跟LC大体一样只是考虑了权重而不简单的轮询,(活动连接数*256+非活动连接)/权重,数最小的胜出,如果都一样还是轮询。
- SED(Shorting expect delay):最少期望延迟,它是一种改进型的WLC,为了避免连接少的时候正好挑选了最差性能的服务器,(活动连接数+1)*256/权重。
- NQ(Nerver Queue):永不排队,第一次根据权重轮询一遍,之后根据SED算法来分配。
- LBLC(Locality-based least connection):基于本地的最少连接,相当于DH+LC算法,主要用于后端的应用服务器是缓存服务器的时候,来提高缓存命中率,不过很少用这种算法。
- LBLCR(Rerplicated and Locality-based least connection):带复制的基于本地最少连接,主要用于后端的应用服务器是缓存服务器的时候。来提高缓存命中率,不过很少用这种算法。
补充知识:
Session会话保存的方法有三种:
- Session绑定:将同一请求者的连接始终保持连接在同一服务器上,这种方式没有容错能力,如果用户请求的会话在A服务器上,那么A服务器一旦故障,那么用户请求会话的数据就丢失了。另外还有一个缺陷是反均衡,也就是一旦绑定该用户的会话请求都会到这个服务器上,无论这个服务器是否繁忙,在大规模环境中,这种方法也不适用。
- Session复制:在所有应用服务器上建立Session集群,基于单播、多播或者广播的方式实现Session传递,让每个应用服务器都拥有一份相同的完整会话数据,在大规模集群环境中,这种方式不适用。
- 建立单独的Session服务器,所有应用服务器都共享该会话服务器,而且该服务器也要实现高可用,否则会有单点故障。
LVS的缺陷是:它不会考虑应用服务器的健康状况,如果应用服务器故障它也会选择。