滴普FastData系列-自动化数据集成服务DCT可编程调度容器设计
作者:陈峰
针对传统数据传输面临的问题和挑战:数据源多样性、数据传输不一致问题、不能有效满足数据实时性需求,并且传统的ETL缺乏智能调度和监控功能;工业企业的数据治理急需一套高效、实时的数据同步工具,滴普在服务客户进行数据治理的过程中,打磨了一套先进的数据同步产品DCT,也是滴普FastData产品组合中的重要模块。
DCT在立项时曾确立了any2any的最终目标。Any2any意味着dct需要兼容各种数据源的读取与写入。据粗略统计,目前常用的数据源超过30种,按照排列组合计算,dct需要支持900种传输组合(按照30种计算)。图表 1两种any2any的架构设计,需要实现any2any有两种架构方式:不使用统一数据标准和使用统一数据标准。
两种架构方式各有优缺点,左图的架构优点在于简单,可以针对特殊数据源进行优化。但缺点也很明显,需要实现的组合太多,假设有N种数据源,那么最多可能需要实现N*N种组合,每个组合都是一套程序,最终就会出现工程量庞大的问题。
右图架构的主要思想是制定一个中间语言的数据标准(IL),然后任意数据源只需要实现一个读取程序和一个写入程序,读取程序将数据源转换为IL,写入程序将IL转换回该数据源支持的格式。这种架构的优势在于工程量小,假设有N种数据源,那么最多只需要实现2*N个程序即可满足需求。但缺点也很明显:设计一种数据源无关的IL成为了该架构方案的巨大挑战。

图表 1两种any2any的架构设计
除上述优缺点之外,以上两种结构再扩展性上也存在很大的不同,对于右侧的架构来说,其扩展非常灵活,非常适合再读取和写入的过程中增加转换动作,可以灵活适配ETL和ELT架构[ ETL架构指转换在写入目标库之前完成,ELT指转换在写入目标库之后完成。两种模式各有优缺点,大数据批处理时代由于存储成本降低,使用ELT模式比较多。但ELT模式的缺陷导致其不适用于实时计算的场景中,而ETL非常适用于实时计算的场景。]。而左侧的架构由于数据源组合实现已经经过了编译,再在其中增加转换过程几乎是不可能的,因此只适合ELT模式。
考虑到研发成本和扩展性,DCT最终适用于右侧架构。右侧架构关键在于数据标准的设计,在实现上则表现为组件化。本文将会重点介绍DCT 3.0的组件化机制——PSC(Programmable Scheduled Container,可编程调度容器),将为读者揭示PSC内部的具体结构,以及PSC是如何将多个组件整合成独立程序并完成迁移任务的。
本文主体部分分为3个大模块:概述、静态结构、动态结构和性能优化。概述章节说明了PSC的定义;静态结构章节展示了PSC组织不同组件的方式;动态结构章节揭示了PSC在运行过程中多个组件是如何进行交互的;性能优化章节描述了PSC在设计过程中可能遇到的性能问题以及PSC的解决思路。
第一章 概述
PSC(Programmable Scheduled Container,可编程调度容器),从广义上可以理解为组合了多个组件,为了完成某个具体任务的可执行可编程的程序集合。狭义上指的是经过PSC编译器根据任务配置编译而成的psc文件。

图表 2任务示例
图表 2任务示例描述了一个DCT常见的任务实例,这个任务常见于数仓分析场景中,定期将业务数据库的数据导入到数据仓库中以供分析,在数据入仓前做一些数据清洗和密码脱敏的动作。图中的两个虚线框表示这两个过程可有可无。如果去掉中间两个虚线框的过程,那么就是一个最简单的EL任务。
在上述例子中,DCT在实现时会将4个圆角矩形全部当成组件,存放于组件库。用户可以按需从组件库中组合任意组件,形成上述的任务。
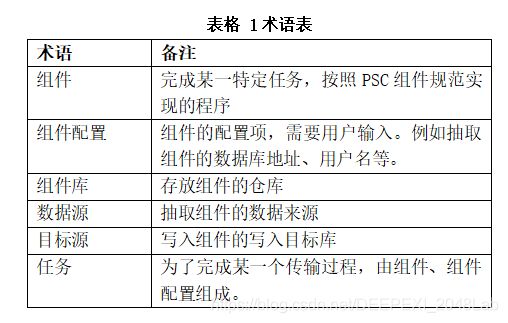
列出了上述过程中出现的一些术语。简而言之,DCT通过组件和任务,实现any2any的目标。组件由程序员按照PSC规范编写,并上传到组件库中,业务人员可以从组件库中按照目标,组织一个传输任务。PSC编译器会根据用户创建的任务,自动从组件库中编译出一个PSC,已完成任务。
总结来说,PSC本质上可以看成一个实现传输任务的程序。为了使得用户易于使用,PSC在设计时需要满足如下特性:
完备性:PSC应该是任务完备的,也就是说可以完全满足某一个特定任务。
可调度:PSC应该可以被调度器调度。
原子性:PSC应该是可独立运行的,不能依赖于调度器或其他组件。
完备性显而易见,如果不具备完备性那么PSC和组件就没有本质的差别了。可调度指的是PSC应该能够被调度器调度,从而和工作流、资源调度器配合,实现更复杂的场景。原子性指的是PSC应该能够独立执行,而不需要依赖调度器执行。这个特性在测试、poc、简单项目时能减少部署成本。
有了上述的设计原则,PSC的设计就有了方向,最终实现了目前的第一版设计。
第二章 静态结构
PSC在经过编译器会编译成一个独立的文件,该文件会将组件、脚本、依赖包、配置等信息打包到一起,之后可以将这个PSC文件拷贝到任意一台linux服务器上执行。本章节介绍PSC的静态组成部分。
2.1 物理结构

图表 3 PSC物理结构示意图
图表 3 PSC物理结构示意图展示了PSC的物理结构。Libs目录存放所有的依赖包,可以在运行时通过参数覆盖,以减小psc文件的大小。Conf目录存放各个组件的配置。Vfs是虚拟文件系统的工作目录,其详情会在动态结构章节讲述。Apps存放所有组件。Hook存放钩子脚本,系统会在PSC的运行生命周期的各个阶段自动执行各个脚本。根目录中main.sh是psc的启动脚本,该脚本由PSC编译器自动生成,不建议用户执行修改。Config,properties存放PSC的配置信息。
2.2 内存结构
如图表 4PSC 内存结构所示,PSC在设计时设计了3块内存区域,供组件使用。

图表 4PSC 内存结构
系统变量区由PSC系统管理,存放一些常量信息。并转发操作系统变量的获取请求。部分系统变量如所示。

组件可以通过PSC提供的SDK获取到由PSC执行器在运行时设置的各种系统变量,该区域的数据无法被组件修改。
私有内存区为各个组件所独有,该区域在组件之间互相隔离,组件之间无法互相访问。组件可以将运行状态保存到该区域中,PSC执行器会将该数据写入磁盘,当程序下次启动时,组件可以根据该区域的信息恢复运行状态。断点续传和故障转移就可以依靠该区域的特性解决。
公共内存区是所有组件共享的,任何组件都可以对该区域进行读写,组件可以将需要传递给下游组件的信息写入该区域。另外,该区域也提供锁机制,避免产生冲突。
总得来说,系统变量区保存任务等基本信息,私有内存区将数据在时间上传递,公共内存去将数据在空间上传递。借助PSC的内存机制,可以实现复杂业务。
第三章动态结构
前一章节介绍了PSC的静态结构,静态结构是PSC的基础,暂时了PSC的组成,本节将具体展示PSC在执行过程中各个环节。
3.1 生命周期
图表 1展示了PSC的生命周期示意图。由于真实的生命周期过于复杂,不利于讲解PSC设计理念,因此本文使用的是重新绘制的示意图。
如图所示,PSC在启动时会优先调用用户定义的预启动脚本,并读取任务配置信息,检查依赖,初始化组件,最后启动组件。整个过程简单明了,但也存在很多需要考虑的细节,本节将对这些细节进行描述。
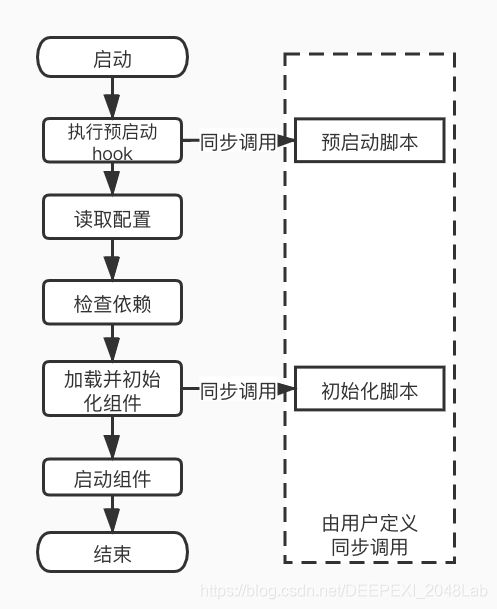
图表 5 PSC生命周期示意图
3.1.1依赖检查
PSC会使用大量的组件,考虑到组件的复用性和便携性,PSC有两种编译模式,完整编译和配置编译。完整编译模式会将所有的组件统一的编译为同一个文件。这种编译模式生成的PSC可以分发到任意的机器上执行,适合简单的任务场景。配置编译模式只会将配置编译,可以看成是一个配置文件。这种编译方式生成的PSC文件体积小,适合集群调度环境。
对于配置编译模式生成的PSC程序,PSC执行器会在读取配置文件后,检查依赖的组件是否存在。可以通过运行时设置—libs=xxx参数进行配置。或在执行的服务器上设置PSC_LIBS环境变量。
3.1.2用户定义脚本
PSC在运行阶段,还提供了两处用户自定义脚本的方式,分别在读取配置之前和加载组件后执行前,分别成为预启动脚本和初始化脚本。这两个脚本都由用户编写,可以借助这两个过程实现一些特殊的目的。
用户定义脚本是可选的,如果用户未定义,则会跳过该过程。并且,执行用户定义脚本是同步调用,因此用户编写脚本时建议不要使用死循环,否则PSC执行器不会继续执行后续过程。
需要注意的是,PSC执行器不会检查用户脚本的内容,用户脚本能够带来很多便利,但同时也会存在一些安全风险。
3.1.3 组件执行过程
在执行初始化脚本之后,PSC执行器已经完成了全部的准备工作,准备开始执行各个组件。PSC会依据配置中的DAG任务图按照组件执行规则有序执行组件。组件的执行规则如下:
多线程并发执行DAG图中所有入度为0的节点。
节点通过分发器将数据传输到下游节点。
节点可以在内部使用多线程加速。或使用死循环等手段实现永续运行(实时同步)。
所有由PSC执行器创建的线程退出后即为执行结束。
通过以上规则,可以构建出非常复杂的业务场景,图表 6展示了部分使用场景。上述规则可以兼容多reader+多transformer+多writer的复杂场景。
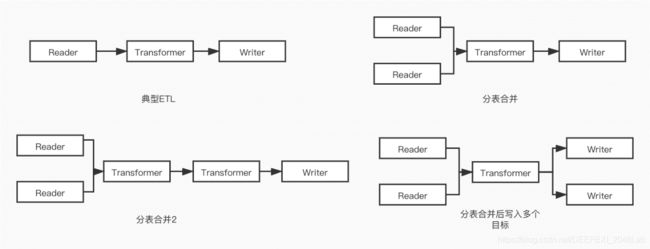
图表 6 业务场景示例
持久化
PSC提供持久化存储,方便任务保存信息。该功能可以为断点续传、任务迁移、HA提供支持。组件可以通过持久化机制保存程序状态,PSC会自动将其持久化到硬盘。PSC重启时,PSC执行器会自动恢复。PSC持久化提供虚拟内存和虚拟文件系统两种方式。
PSC的持久化的目标不仅仅时将数据持久化到磁盘中,更重要的是提供跨机器转移的能力。
PSC程序的一个常见场景是集群环境中,程序需要迁移到另一台机器上执行,此时如何恢复之前机器的状态,就成为了一项挑战。PSC的持久化机制正是为了应对这种挑战而设计的。通过PSC的持久化机制可以保证PSC在任意一台机器上重启都能恢复到之前的状态。
3.2.1 虚拟内存
PSC虚拟内存见2.2节内存结构。
3.2.2虚拟文件系统
PSC提供虚拟文件系统,组件可以通过该机制直接在PSC内部创建文件。对于Java编写的组件,可以通过SDK直接获得JDK的File对象。从而兼容各种IO库。程序员在编写组件时,也可以不使用PSC的虚拟文件系统,直接在宿主机上创建文件,但通过虚拟文件系统机制管理的文件,会成为PSC的程序状态,从而由持久化机制维护,保证其在跨机器执行时也能恢复为之前的状态。
快照
PSC提供快照功能,通过命令可以保存一个正在运行的PSC的快照。该快照可以迁移到任意机器上从保存的状态开始执行。快照功能是PSC实现断点续传、跨机器执行的基本。
分发器
3.1.3节描述了几种常见的应用场景,显而易见PSC需要兼容非常复杂的业务,在实际实现过程中,PSC使用分发器模型实现组件解耦。图表 7展示了3.1.3节中一个通过分发器解耦的示例。不难看出,组件之间的关系由分发器维护,各个组件只需要和分发器进行通信,大大降低了组件之间的耦合。
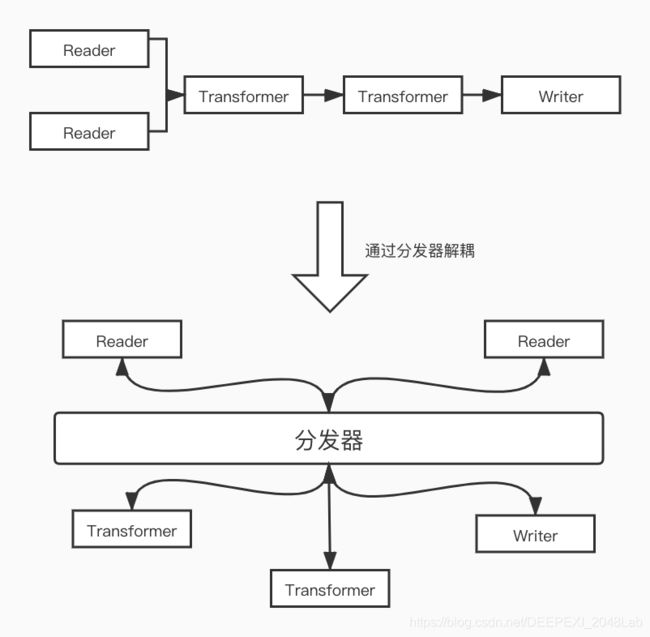
图表 7 通过分发器解耦
分发器的设计时PSC的一个很大的改进,在DCT2.0结构并没有分发器的设计,而是使用的Channel的设计。channel设计是DCT3.0之前的主要设计,有着其独特的优势——简单、易于维护。但同时也存在着很大的不足,主要体现在无法应对复杂的业务场景。因此,3.0架构中改变了channel的设计。采用了分发器的设计以支持复杂的业务场景。
第四章总结
PSC是DCT3.0整体架构中承担着组织者和执行者的双重角色,是承上启下的关键。组织者指的是PSC将各个组件组织起来完成一个用户任务。执行者指的是PSC持久化成为了集群HA、任务迁移、故障转移等的基础能力。承上指的是将用户的业务通过PSC变成可执行的程序,启下指的是提供给任务调度器,用于集群资源调度。
PSC的设计成为了许多优秀商业特性实现的基础。生命周期模型为复杂业务设计提供了支持。分发器为组件多样化共存提供了便利、持久化机制为断点续传、故障恢复提供了基础。
与此同时,复杂的PSC设计显而易见会成为性能提升的一个瓶颈,而性能在集群稳定运行后会成为新的矛盾点,因此在PSC的实现层面,对性能的设计就开始成为新的关键。PSC在性能设计上广泛使用了分页技术、IPC技术、零拷贝技术等,为PSC的高性能运行提供保障。详细的高性能设计会在《DCT3.0 PSC高性能设计》中进行详细描述。
了解更多DCT产品详情请登录:https://www.deepexi.com/product-new/9