三十一章:StructToken :Rethinking Semantic Segmentation with Structural Prior ——通过结构先验重新思考语义分割
0.摘要
在以前的基于深度学习的方法中,语义分割被视为静态或动态的像素级分类任务,即将每个像素表示分类到特定的类别。然而,这些方法只关注学习更好的像素表示或分类核,而忽视了物体的结构信息,而结构信息对于人类决策机制至关重要。本文提出了一种新的语义分割范式,称为结构感知提取。具体而言,它通过一组学习到的结构标记与图像特征之间的交互生成分割结果,旨在逐步从特征中提取每个类别的结构信息。大量实验证明,我们的StructToken在三个广泛使用的基准数据集上表现优于最先进的方法,包括ADE20K、Cityscapes和COCO-Stuff-10K。
关键词—语义分割,Transformer。
1.引言
随着自动驾驶技术、人机交互和增强现实的发展,语义分割越来越受到关注。在深度学习时代,语义分割主要被定义为像素级分类任务,即通过一个学习到的分类器(如1×1卷积)将每个像素分类到特定的类别。根据分类器的性质,以前的工作可以分为两个范式:静态像素级分类和动态像素级分类。如图1a所示,对于静态像素级分类范式,在训练过程之后分类器是固定的。遵循这种范式的方法主要关注如何通过上下文建模[7] [28] [45] [49] [53]或自动架构设计[11] [41] [47]来学习更好的每个像素表示。由于从数据集中学习到的静态分类器可以被视为每个类的综合表示,它可能与每个图像中每个对象的表示不一致,一些最近的工作[9] [10] [38]提出根据自身内容动态学习不同输入的分类器。如图1b所示,初始核通过图像特征进行更新,从而产生更适应当前输入的动态分类器。
在这两种范式中,整个解码器都致力于学习更好的特征(包括精确的语义和细节)和更强大的分类器,并且分割决策仅通过像素级分类在最终的分割头中进行。然而,从人类的角度来看,语义分割的决策过程呈现出不同的模式。特别是,基于对类别的结构信息(如纹理、形状和空间布局)的潜在知识,人类首先确定每个类别的粗略区域,然后逐渐细化,而不是一开始就密切关注所有图像信息,然后一次性进行分类。这激发我们探索一个更符合人类决策过程的范式是否比以前流行的像素级分类对于语义分割更好。
在本文中,我们设计了一种人类类似的语义分割范式,称为结构感知提取。为了模拟人类的知识,我们定义了一组可学习的结构标记,每个标记都被期望用来建模一个类别的隐含结构信息。如图1c所示,在给定图像特征的情况下,结构标记逐渐从图像特征中提取信息。定性可视化结果显示,在渐进提取过程中,结构信息变得越来越明确。因此,最终层次的精炼结构标记可以直接被视为分割结果。显然,我们的范式类似于人类使用结构知识进行粗略区分,然后逐渐进行细化的过程。
根据我们的结构感知提取范式,我们进一步设计了一个语义分割网络,名为Struct Token,来评估我们的范式的有效性。如上所述,提取旨在构建从图像特征的通道切片到结构标记的映射。我们以不考虑内容和考虑内容两种方式实例化了提取操作,从而得到了三种不同的实现方式,分别是点对点提取(PWE)、自身切片提取(SSE)和跨切片提取(CSE)。相应的三个变体分别被表示为StructToken CSE,StructToken-SSE和StructToken-PWE。具体而言,PWE和SSE分别对图像特征和结构标记的连接部分应用点对点卷积和通道自注意力。CSE在结构标记和图像特征之间执行通道间的交叉注意力,其中前者作为查询,后者作为键和值。由于点对点卷积核权重在训练后固定不变,PWE的提取与输入图像无关,即不考虑内容。而SSE和CSE中的注意机制根据通道切片之间的相似性确定映射权重,这与内容相关。此外,SSE和PWE包含了图像特征和结构标记的所有通道切片对之间的映射,而更高效的CSE仅涉及从图像特征到结构标记的单向通道切片映射。有趣的是,我们发现在更少的提取操作下,PWE相对于其他两种方法显示出了更多的优势(更多细节请参见图3)。此外,由于建模能力更强,SSE在更大的挑战下开始显示出其优势。
我们在不同的骨干网络上对我们的方法进行了三个具有挑战性的语义分割基准的评估。例如,使用ViT-L/16 [15]作为骨干网络,我们的Struct Token在ADE20K [55]上达到了54.18%的mIoU,在Cityscapes [12]上达到了82.07%的mIoU,在COCO-Stuff-10K [3]上达到了49.07%的mIoU,超过了现有的方法。我们的主要贡献包括:•我们提出了一种新的语义分割范式,称为结构感知提取范式,它遵循人类类似的机制,强调结构信息的关键作用。•我们在我们的结构感知提取范式下提出了一个名为StructToken的网络,并探索了提取过程的不同实现方式。•大量实验证实了我们方法的有效性,并展示了人类类似分割范式的前景。

图1.与三种语义分割范式的比较。在(a)中,分割结果是通过最终特征图与静态分类器的乘积获得的,其中分类器在训练后是固定的。相比之下,(b)根据图像内容进一步更新初始核以生成每个输入图像的动态分类器。在我们的(c)中,它学习了一组结构标记,并逐渐从特征图中提取信息来更新结构标记。最终的结构标记可以直接视为分割结果。C和K分别表示通道数和类别数。
2.相关工作
静态逐像素分类范式。自从全卷积网络(FCN)[34]被提出以来,逐像素分类一直主导着语义分割。它通过一个固定的分类器(如1×1卷积)将每个像素分类到一个特定的类别,这个分类器在训练过程中是不可改变的。在这个范式下的方法主要关注如何通过上下文建模和融合来学习每个像素的更好表示。早期的PSPNet [53]使用了金字塔池化模块来进行多尺度上下文融合。DeepLab系列 [5],[6]引入了扩张卷积来扩大感受野。DANet [17],DSANet [22],CCNet [23]和OCRNet [49]使用非局部模块来建模更精确的上下文信息。[42]提出了一个阶段感知的特征对齐模块,用于对邻近层级之间的特征进行对齐和融合。[39]提出了高斯动态卷积来自适应融合上下文信息。[24]通过级联条件随机场增强了定位目标边界的能力。[25]通过可变形卷积提取了非刚性几何特征。[2]通过对象级语义融合模块加强了与同一对象的连接,以更高效地整合上下文信息。此外,STLNet [56]开始考虑图像本身的结构信息,通过引入纹理增强模块和金字塔纹理特征提取模块来建模图像纹理的结构特性。然而,STLNet是通过对信息进行建模或统计上下文化来实现的,仍然属于逐像素分类的范式。最近的工作 [32],[36],[43],[46],[50],[54]开始使用Transformer架构来捕捉长程上下文信息。
动态逐像素分类范式。与静态范式相比,这种范式根据图像内容动态生成每个类别的分类器。具体而言,它通过注意力建立图像内容与分类器之间的连接,并通过多个块的串联使分类器更适合当前的样本图像。Segmenter [38]在解码阶段使用Transformer共同处理补丁和类别嵌入(令牌),并让类别令牌与特征图进行矩阵乘法,产生最终的得分图。MaskFormer [10]通过类别令牌和特征图之间的矩阵乘法,以及使用二进制匹配机制,统一了实例分割和语义分割的架构。Mask2Former [9]和K-Net [52]使用了学习到的语义令牌(等同于类别令牌)来替代1×1卷积核,并使用二进制匹配来统一语义、实例和全景分割任务。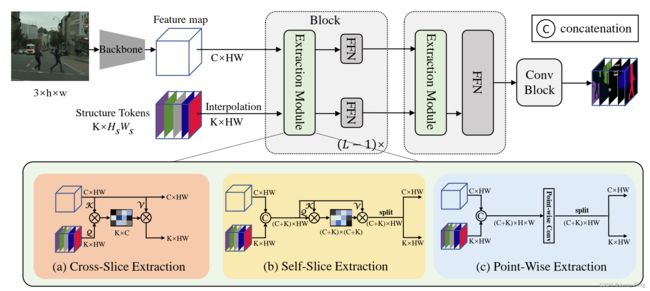
图2.我们的StructToken的总体框架。其中(a),(b)和(c)分别展示了提取模块的三种不同实现方式。这里h和w表示原始图像的高度和宽度,而H和W表示由主干网络输出的特征图的高度和宽度(例如,使用ViT [15]作为主干网络时,输出特征图的尺寸是原始图像的1/16)。HS和WS表示结构标记的高度和宽度。CSE和SSE中的Q,K和V分别表示映射函数Φ和Ψ输出的查询、键和值。更多细节请参见方法部分。
A.框架
我们的StructToken的整体框架如图2所示。给定一个输入图像I ∈ ℝ^3×h×w,我们首先使用单尺度的主干网络(例如ViT [15])生成特征图F ∈ ℝ^C×H×W。这里C是通道数,(h,w)和(H,W)分别表示输入图像和特征图的空间大小(高度和宽度)。然后,特征图F和结构标记S ∈ ℝ^K×Hs×Ws被送入解码器,这里K表示数据集中类别的总数。结构标记在训练过程中是可学习的,在推断过程中是固定的,每个结构标记包含了特定类别的隐含结构信息。需要注意的是,当(H,W) ≠ (Hs,Ws)时,结构标记会插值到与特征图F相同的空间大小。整个解码器由L个连续的块组成。每个块由一个提取模块和两个前馈网络(FFN)组成。提取模块旨在从特征图中提取结构信息到结构标记中,每个生成的结构标记可以被视为每个类别的掩码。两个FFN分别用于通过通道投影来优化F和S。对于最后一个块,只需要结构标记的FFN,因为特征图在后续处理中不会被使用。
最后,我们对最后一个块的输出结构标记应用简单的ConvBlock [21],其中包括两个3×3的卷积层和一个跳跃连接,以进一步优化分割结果。
B.扩展模块
由于结构标记是从整个数据集中学习得到的,其中的结构信息是抽象和隐含的,因此需要根据当前的输入图像进一步进行规范和细化。因此,提取模块被设计用于从特征图中提取结构信息到结构标记中。为了全面性,我们探索使用无关内容的卷积和与内容相关的注意力来实现提取操作,从而得到三种变体:点提取(PWE)、自切提取(SSE)和交叉切提取(CSE)。具体而言,PWE和SSE分别对图像特征和结构标记的串联应用1×1的卷积和通道自注意力。CSE在结构标记和图像特征之间执行通道级的交叉注意力,其中查询来自前者,而后者被视为键和值。由于PWE中的提取权重与输入图像无关,因此它是与内容无关的,而基于注意力的SSE和CSE是与内容相关的。此外,CSE可以被视为只有从图像特征到结构标记的通道切片的单向映射的简化版本的SSE。我们以下提供这三个变体的实现细节。
1)交叉切提取:考虑到交叉注意力是一种将信息从一个事物聚合到另一个事物的常用操作,与我们的交互模块的作用非常兼容。因此,我们利用交叉注意力从特征图中提取结构信息到结构标记中。这个过程被称为交叉切提取(CSE)。第i个块中CSE的前向传递可以表示为以下形式: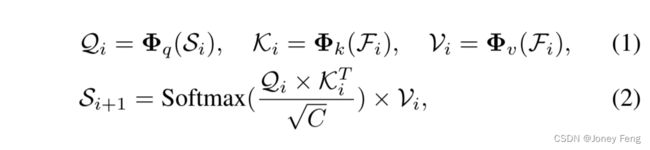
其中,Fi ∈ ℝC×H×W 是输入特征图,Si ∈ ℝK×H×W 是结构标记,可以看作是K个标记,每个标记都是一个具有高度H和宽度W的2维切片。交叉注意力中的查询由结构标记生成,特征图用于构建键和值。与[40]中的原始定义相同,投影层Φα2fq;k;vg在这里的作用是通过相同的模式重新映射Si和Fi中的每个标记。然而,对每个标记在HW维度上执行全连接层会导致与任意大小的输入图像以及多尺度推理过程的不兼容。为了解决这个问题,我们用局部连接层替换了三个全连接投影。具体而言,方程(1)中的Φα2fq;k;vg的公式如下所示: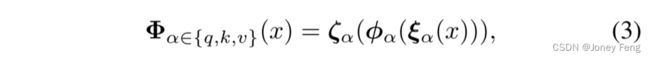
其中,φα表示一个3×3的深度卷积,它在本地映射每个标记。ζα和ξα是1×1的逐点卷积,使每个标记都能够预览其对应的标记。 2)自切提取:在这种变体中,我们使用自注意力来相互作用结构标记和特征图。具体而言,在第i个块的前向过程中,它首先沿着通道维度连接结构标记Si ∈ ℝK×H×W和特征图Fi ∈ ℝC×H×W,如下所示:
然后,在Gi上执行自注意力以在结构标记和特征图之间交换信息。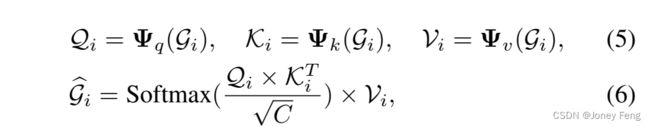
在这里,投影层Ψα2fq;k;vg与CSE中的Φα2fq;k;vg具有相同的实现方式。Qi、Ki和Vi的形状与(C + K)×HW相同。最后,通过沿着通道维度直接从更新后的Gbi中分割,得到更新的结构标记Si+1 ∈ ℝK×H×W和特征图Fi+1 ∈ ℝC×H×W。
可以发现,CSE中的交互是单向的(S→F),只有结构标记被更新,而我们的SSE实现了更全面的双向交互(S⇄F),其中结构标记和特征图都被更新。因此,SSE可以被看作是CSE的扩展。
3)点智能提取:如上所述,SSE中的注意力图(形状为R(C+K)×(C+K))表示用于每个拼接特征切片的聚合权重,进一步用于过滤无用信息。与使用点积生成聚合权重不同,我们的点智能提取(PWE)通过一个简单的逐点卷积层直接学习权重。具体而言,在第i个解码器块的前向过程中,我们也根据公式(4)首先将结构标记Si ∈ ℝK×H×W和特征图Fi ∈ ℝC×H×W进行拼接,得到Gi ∈ ℝ(C+K)×H×W。然后,通过点智能卷积Ω进行交互,其参数被视为聚合权重。
这里的投影层Υ的实现与公式(1)和公式(5)中的Ψ和Φ相同。Ω表示点智能卷积。
C.前馈网络(Feed-Forward Networks,FFN)
传统的前馈网络(Feed-Forward Networks,FFN)[40]由两个连续的全连接层组成,分别用于扩展和收缩通道维度。考虑到我们框架中的FFN起到了细化的作用,我们在原来的两个全连接层之间添加了一个轻量级的3×3组卷积[29],以涉及更多的局部上下文(在表III中进行了消融实验)。
3.实验
首先,我们介绍数据集和实现细节。然后,我们将我们的方法与最近在三个具有挑战性的语义分割基准上的最新技术进行比较。最后,我们进行全面的消融实验和可视化分析,以评估我们方法的有效性。
A.数据集
ADE20K [55]是一个具有挑战性的场景解析数据集,其中分别将20210和2000张图像用于训练和验证。它包含150个细粒度的物体类别和各种场景,具有1038个图像级标签。Cityscapes [12]精细地注释了城市车道景观图像中的19个物体类别。它包含5K个标注精细的图像,并分别划分为2975个训练图像和500个验证图像。这是一个高质量的数据集。COCO-Stuff-10K [3]是一个具有重要意义的场景解析基准,包含9000个训练图像和1000个测试图像。它包含171个类别。
B.实现细节
所有实验均在8个NVIDIA Tesla V100 GPU上(每张卡32 GB内存)使用PyTorch实现和mmsegmentation [35]代码库进行。我们使用ViT [15]作为骨干网络。在训练过程中,我们遵循常见的设置,使用数据增强技术,如随机水平翻转、随机调整大小、随机裁剪(ADE20K和COCO-Stuff-10K为512×512,Cityscapes为768×768,ADE20K使用ViT-L/16为640×640)等。至于优化,我们采用多项式学习率衰减策略;参考之前的工作[33],我们使用AdamW来优化模型,设置动量为0.9,权重衰减为0.01;初始学习率设为2e-5。对于所有数据集,批量大小均设置为16。总迭代次数分别为160k、80k和80k,用于ADE20K、Cityscapes和COCO-Stuff-10K。推理时,我们按照之前的工作[33],[54]对模型的多尺度(0.5、0.75、1.0、1.25、1.5、1.75)预测结果进行平均。使用插值操作进行多尺度推理。这里采用滑动窗口测试。所有实验中性能的衡量指标是常用的平均交并比(mean intersection of union,mIoU)。考虑到有效性和效率,我们在ADE20K的消融实验中采用ViT-T/16 [15]作为骨干网络。
表I:与ADE20K数据集上最先进方法的比较。"SS"和"MS"分别表示单尺度和多尺度推理。"y"表示从头在ImageNet-21K上训练的ViT模型,并在ImageNet-1K上进行微调[37]。"*"表示我们在与官方仓库相同的设置下进行的实现。
表II:与Cityscapes验证集上最先进方法的比较。
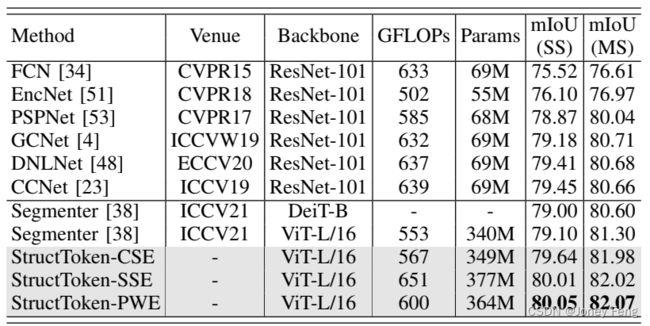
C.与当今主流方法的比较
- ADE20K结果:表I报告了在ADE20K验证集上与最先进方法的比较结果。从这些结果可以看出,我们的StructToken相对于Segmenter [38]在相同输入尺寸(640×640)下的mIoU分别高出1.02%、1.15%和1.04%(52.82、52.95和52.84对比51.80)。当采用多尺度测试时,我们的StructToken相对于Segmenter的mIoU分别高出0.4%、0.43%和0.58%(54.00、54.03和54.18对比53.60)。对于ViT-T/16,在相同输入尺寸(512×512)下,我们的最佳结果相对于DPT [36]高出0.86%的mIoU(42.99对比42.13)。对于ViT-S/16,我们的最佳结果相对于DPT高出1.44%的mIoU(48.89对比47.45)。对于ViT-B/16,我们的最佳结果相对于Segmenter高出1.82%的mIoU(51.82对比50.00)。此外,模型越大,StructToken的性能越好。
- Cityscapes结果:表II展示了在Cityscapes验证集上的比较结果。之前的最先进方法Segmenter使用ViT-L/16实现的mIoU为79.10%。我们的StructToken相对于Segmenter分别高出0.54%、0.91%和0.95%的mIoU(79.64、80.01和80.05对比79.10)。对于多尺度推理,我们的方法相对于Segmenter分别高出0.68%、0.72%和0.77%的mIoU(81.98、82.02、82.07对比81.30)。
- COCO-Stuff-10K结果:表IV对比了在COCO-Stuff-10K测试集上的分割结果。可以看出,我们的StructToken-SSE可以达到49.07%的mIoU,相对于MCIBI [26]高出4.18%的mIoU(49.07对比44.89)。
D.消融研究
在本节中,所有实验中的模型都采用ViT-T/16 [15]作为骨干网络,并在ADE20K训练集上进行160K次迭代训练。我们的基线模型是没有分组卷积的CSE模块和FFN模块。需要注意的是,我们没有使用全连接层来映射查询、键和值矩阵进行消融实验,因为它不支持多尺度推理。
- 每个组件的效果: 如表III所示,我们尝试在FFN模块中添加一个3×3的分组卷积层[29]和一个ConvBlock模块。此外,FFN与分组卷积层的FLOPs仅为0.002G,在表III中被忽略。这是一个轻量级的卷积层,在添加了FFN模块和ConvBlock模块后,模型的性能达到了39.12%的mIoU,相对于基线模型提高了+1.41%的mIoU(39.12对比37.71),在多尺度推理中提高了+1.33%的mIoU(40.23对比38.90)。
- 块数目的影响: 图3显示了在不同块数目下,StructToken-CSE、StructToken-SSE和StructToken-PWE之间的比较。可以看出,所有变体的性能随着块数目的增加呈现上升趋势。对于性能和计算复杂度以及参数数量之间的权衡,我们选择默认使用4个块数对于所有的变体,这也意味着我们在表I、II和IV中的StructToken的性能低于其上限。有趣的是,具有更灵活的内容相关注意力操作的SSE和CSE表现比内容无关的PWE更差,并且随着块数目的增加,它们之间的性能差距变小。这可能是因为不太灵活的卷积操作更容易学习,而注意力操作需要更多的块来展示其优势。
- CSE、SSE和PWE的比较: 我们从以下三个方面比较这三个变体:(a) 场景复杂度。从表I、II和IV可以看出,StructToken-PWE在小数据集和简单场景(例如具有19个类别的城市景观)下表现更好。对于中等复杂的场景(例如具有150个类别的ADE20K),SSE、CSE和PWE的性能相似,另外CSE相对于SSE节省了18%的GFLOPs。然而,当场景变得更复杂时(例如具有171个类别的COCO Stuff-10K),内容相关的注意力(即SSE和CSE)开始展现其优势,受益于动态建模。在这种情况下,复杂性更高的SSE表现更好。与SSE和CSE相比,PWE在较大的数据集上表现不佳,但在较小的数据集上表现良好。(b) 骨干网络的优势。如表V所示,当使用ViT-T/16 [15]作为骨干网络时,StructToken-PWE大幅超过CSE和SSE,分别比它们高出2.75%和1.06%的mIoU。随着骨干网络的增强,这种性能差距逐渐缩小(StructToken-PWE只比StructToken-SSE高出0.2%的mIoU),内容相关的SSE逐渐展示其优势。此外,内容相关的注意力更依赖于骨干网络提取的特征,特征越丰富,性能越好。(c) 解码器块的数量。图3的定量结果和图4的定性可视化表明,PWE在少量解码器块时具有更大的优势。随着块数目的增加,性能差距逐渐减小。
表III 在ADE20K数据集上对StructToken的每个组件进行剖析研究。“}”表示FFN的基本架构,即两个连续的线性层,而“}♠”表示在两个线性层之间添加一个3×3的分组卷积以增强局部性。所有的实验都使用VIT-T/16作为骨干网络。
表IV 在COCO-STUFF-10K数据集上与最先进的方法进行比较。
表V 在ADE20K数据集上比较VIT变体的性能。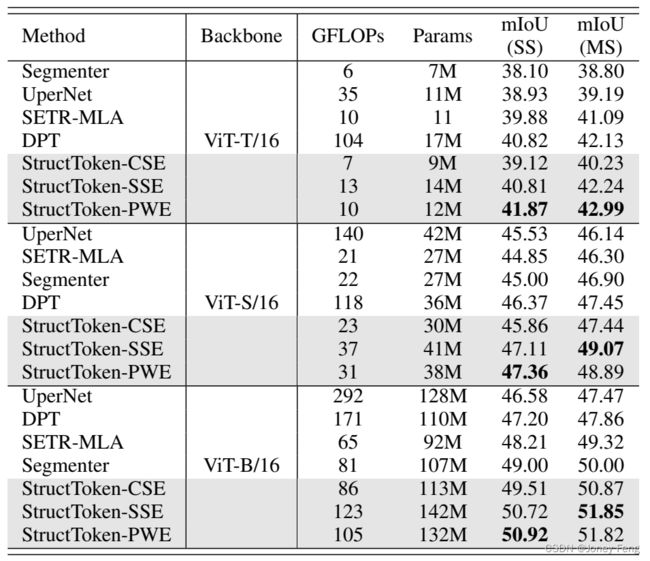

图3 在ADE20K数据集上比较不同块数的性能。这里使用ViT T/16作为骨干网络。
图4 我们三种变体按照结构感知提取范式进行可视化(第1∼3行),以及它们按照逐像素分类范式进行可视化(第4行)。我们选择了两个示例(第一列),分别包括“car”和“door”类别。对于每个示例的第1∼3行,第二列中的S表示从数据集中学习到的结构令牌,其中包含每个类别的隐含结构信息。第3∼6列中的Si表示第i个块的输出结构令牌。最后一列中的Y表示最终层的输出得分图。对于每个示例的第4行,第二列中的F表示骨干网络的输出特征,第3∼6列中的Fi表示第i个残差块的输出特征。“IoU”表示图像中特定类别(“car”或“door”)的交并比分数。
E.可视化分析
为了更好地理解我们提出的范式的机制,我们通过可视化结构令牌的演化过程来展示它的工作原理。图4展示了从ADE20K数据集中抽样的两个示例,分别包含“car”和“door”类别。我们在每个示例的前三行中比较了三种提取方法,其中第二列表示对应于特定类别(“car”或“door”)的学习到的结构令牌切片,第3∼6列表示它在第1∼4个块中的更新结果。从第二列可以看出,从数据集中学习到的结构令牌相对抽象。它没有呈现明显的物体模式,这也是可以理解的,因为每个类别中的对象多样性很大。第3∼6列显示随着渐进的提取操作,结构令牌中的结构信息越来越明显。此外,StructToken-PWE在第一个块之后(第3列)就呈现出了粗略的物体轮廓,而其他两个对应的方法中这种现象更加模糊,这意味着PWE可以更快地从图像特征中提取信息。相比之下,内容相关的SSE的提取过程似乎最慢。
为了更好地理解我们的范式与逐像素分类范式之间的差异,我们进一步进行了视觉比较。为了更好地比较,我们实例化了一个遵循逐像素分类范式的模型作为对比,这更符合我们的范式。具体而言,我们首先对骨干网络输出特征应用1×1卷积,将通道数投影到类别数,然后使用四个残差块[20]来转换特征图,随后再经过一个1×1卷积生成最终的分割结果。因此,每个残差块的特征图输出具有与结构令牌类似的含义,即每个切片包含特定类别的结构信息。但它们的区别在于,逐像素分类范式中的结构信息仅来自当前输入图像,而结构令牌中的结构信息是从数据集中学习到的先验知识。在图4中,每个示例的第4行显示了来自每个残差块输出的特定类别的特征切片的可视化结果。我们可以看到,即使逐像素分类范式在最终的mIoU和分割头的输出特征上与我们的范式相似,但每个块之后的特征图与结构令牌相比呈现完全不同的模式。从第1∼3行,我们可以看到结构令牌中“car”和“door”类别的清晰结构。相比之下,在第4行中,直到1×1卷积将特征图转换为逐像素分类得分图之前,我们只能看到模糊的结构甚至没有结构的语义类别。这种更明确的结构信息为我们的范式在保留结构信息方面的优势提供了有力的证据。
4.总结
在本文中,我们提出了一种与逐像素分类不同的新范式,称为结构感知提取。经典的逐像素分类方法仅关注学习更好的像素表示或分类核,而忽视了对象的结构信息,而结构信息对于人类的决策机制至关重要。相反,结构感知提取具有很好的提取结构特征的能力。具体而言,它通过一组学习到的结构令牌与图像特征之间的交互生成分割结果,旨在逐步从特征中提取每个类别的结构信息。我们希望这项工作能为语义分割和其他任务带来一些基础性的启示。