Attention is all you need (一)
论文地址:https://arxiv.org/abs/1706.03762
1、本篇论文提出的模型是 Transformer。
2、适用的任务是 sequence modeling(例语言模型) 和 sequence transduction(例机器翻译)。
3、目前主流的方法是用基于RNN的或CNN的encoder-decoder结构,在encoder和decoder中间用attention机制做连接。
4、Transformer 解决的问题是,减少计算时间复杂度,加快训练速度,提升模型效果。
5、Transformer 解决的方法是,用attention替代encoder和decoder中的RNN结构,Transformer中只有attention。
本篇读
0 Abastract
7 Conclusion
浅看一下
3 Model Architecture
6 Results
0 Abastract
目前机器翻译的主流模型用的是基于RNN或CNN的encoder-decoder模型,encoder和decoder中间用attention进行连接会取得更好的效果。
本篇论文提出的Transformer,仅仅有 attention mechanisms的网络结构,不依赖与RNN 和 CNN的网络结构。
实验效果:效果更好,更加并行化,训练时间少。
7 Conclusion
1、本篇论文首次提出一个完全基于attention的sequence transduction模型,称为Transformer。用multi-headed self-attention替代encoder-decoder结构中常见的RNN。
2、在翻译的任务上,Transformer的训练速度明显快于基于RNN和CNN的结构。
3、未来展望:计划将Transformer应用在其他任务上;将Transformer扩展到输入输出为图像、音频、视频的任务上(这盛世如你所愿!)
4、代码地址:https://github.com/tensorflow/tensor2tensor
(用pytorch的推荐:GitHub - jadore801120/attention-is-all-you-need-pytorch: A PyTorch implementation of the Transformer model in "Attention is All You Need".)
3 Model Architecture
1、模型结构图
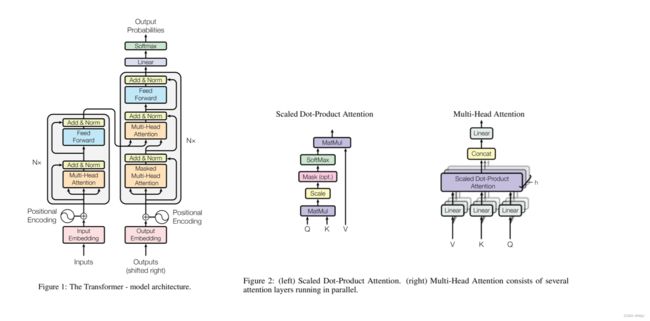
2、attention、RNN、CNN 的时间复杂度对比

6 Results
三个实验数据:翻译、调参、英语成份句法分析
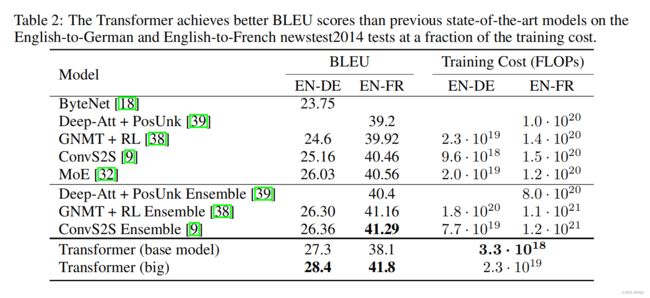
1、Machine Translation
在EN-DE,EN-FR的翻译任务上,对比下列模型的BLEU指标和训练成本。
2、Model Variations
为评估Transformer的不同组成部分的重要性,改变attention相关的几个参数:muti-heads中N的个数,self-attention中key 和 value的维度。

3、English constituency Parsing
为评估Transformer是否可以用于其他任务,用英语成份句法分析做了实验对比。
