字节跳动青训营笔试题解
文章目录
-
- 前言
- 一、单选题
- 二、多选题
- 三、编程题
-
- T1.旋转数组最大值
-
- 题目
- 思路
- 代码
- T2.社交圈
-
- 题目
- 思路
- 代码
- 四、简答题
-
- 题目
- 思路
前言
第五届字节跳动青训营-后端专场笔试题解,简单做了一下,选择题和简答题不知道是否正确,编程题是通过了的,有问题欢迎评论,我会及时改正的~
一、单选题

选A
QUIC(Quick UDP Internet Connection)是谷歌制定的一种基于UDP的低时延的互联网传输层协议。
选D
MTU这个概念是指数据帧中有效载荷的最大长度,不包括帧首部的长度。所以
T C P 报文的有效载荷 = 1500 B − 20 B ( I P 数据报首部 ) − 20 B ( T C P 报文首部 ) = 1460 B TCP报文的有效载荷 \\ = 1500B-20B (IP数据报首部)-20B( TCP报文首部) \\ = 1460B TCP报文的有效载荷=1500B−20B(IP数据报首部)−20B(TCP报文首部)=1460B
选D
利用 netstat 指令可让你得知整个 Linux 系统的网络情况。

== 选B==
https加密是在传输层。这层的功能包括是否选择差错恢复协议还是无差错恢复协议,及在同一主机上对不同应用的数据流的输入进行复用,还包括对收到的顺序不对的数据包的重新排序功能

== 选D==
-
IaaS(Infrastructure as a service – 基础设施即服务):用户可以在云服务提供商提供的基础设施上部署和运行任何软件,包括操作系统和应用软件。用户没有权限管理和访问底层的基础设施,如服务器、交换机、硬盘等,但是有权管理操作系统、存储内容,可以安装管理应用程序,甚至是有权管理网络组件。简单的说用户使用IaaS,有权管理操作系统之上的一切功能。我们常见的IaaS服务有虚拟机、虚拟网络、以及存储。 -
PaaS(Platform as a service – 平台即服务):PaaS给用户提供的能力是使用由云服务提供商支持的编程语言、库、服务以及开发工具来创建、开发应用程序并部署在相关的基础设施上。用户无需管理底层的基础设施,包括网络、服务器,操作系统或者存储。他们只能控制部署在基础设施中操作系统上的应用程序,配置应用程序所托管的环境的可配置参数。常见的PaaS服务有数据库服务、web应用以及容器服务。成熟的PaaS服务会简化开发人员,提供完备的PC端和移动端软件开发套件(SDK),拥有丰富的开发环境(Inteli、Eclipse、VS等),完全可托管的数据库服务,可配置式的应用程序构建,支持多语言的开发,面向应用市场。 -
SaaS(Software as a Service – 软件即服务):SaaS给用户提供的能力是使用在云基础架构上运行的云服务提供商的应用程序。可以通过轻量的客户端接口(诸如web浏览器(例如,基于web的电子邮件))或程序接口从各种客户端设备访问应用程序。 用户无需管理或控制底层云基础架构,包括网络,服务器,操作系统,存储甚至单独的应用程序功能,可能的例外是有限的用户特定应用程序配置设置。类似的服务有:各类的网盘(Dropbox、百度网盘等),JIRA,GitLab等服务。而这些应用的提供者不仅仅是云服务提供商,还有众多的第三方提供商(ISV: independent software provider)。
选B
虚存的实际容量由CPU的地址长和外存的容量决定,当CPU的地址长度能表示的大小远远大于外存容量时,虚存的实际容量为内存和外存容量之和;当外存容量远大于CPU字长能表示的大小时,虚存的实际容量由CPU字长决定。一般情况下,CPU的地址长度能表示的大小都大于外存容量。
虚存容量不是无限的,最大容量受内存和外存可利用的总容量限制,虚存实际容量受计算机总线地址结构限制。
选D
详情参见:https://blog.51cto.com/u_15162069/2901383

选D
详情参考:https://studygolang.com/articles/34110



选C
TIME_WAIT状态是TCP在四次挥手终止连接时,主动关闭连接的一方(客户端或者服务端)在收到对端发送的FIN之后,进入的一种状态。
二、多选题

选C、D
Redis提供了两种方式:RDB方式和AOF方式。
1、RDB方式
RDB方式的持久化是通过快照(snapshotting)完成的,当符合一定条件时,Redis会自动将内存中所有的数据生成一份副本并存储在硬盘中,这个过程被称为“快照”。“快照”,就类似于拍照,摁下快门那一刻,所定格的照片,就称为“快照”。
2、AOF方式
通过RDB方式实现持久化,一旦Redis异常退出,就会丢失最后一次快照之后更改的所有数据。为了降低因进程中止导致的数据丢失风险,可以使用AOF方式实现数据持久化。
AOF持久化是以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,文件中可以看到详细的操作记录。

选A、B

选A、B、C、D
netfilter五个hook点分别是:
NF_INET_PRE_ROUTINGNF_INET_LOCAL_INNF_INET_FORWARDNF_INET_LOCAL_OUTNF_INET_POST_ROUTING
选B、D
三、编程题
T1.旋转数组最大值
题目

思路
看到样例有点懵,就直接找的最大值,然后就过了……(有点无语)
代码
#includeT2.社交圈
题目
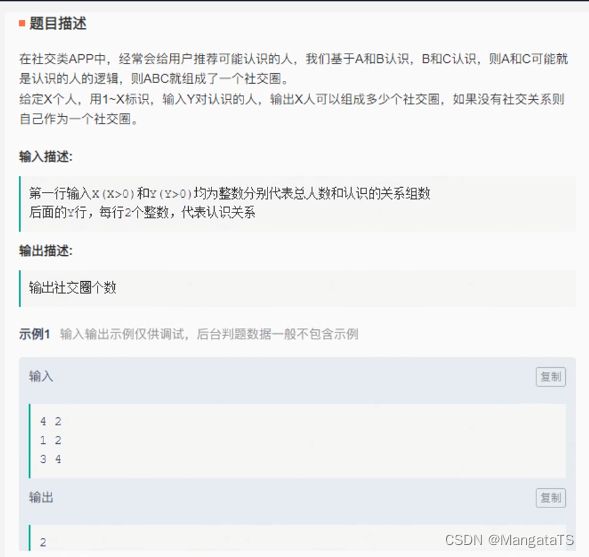
思路
我们用并查集来维护这个社交圈,一开始社交圈的个数就是X个,那么我们不断的读入两个人的关系,如果不在一个社交圈,那么我们就将其放入同一个社交圈,并且将社交圈的数量减一,如果在同一个社交圈那就不用减一,最后输出一下,我们统计的社交圈的数量即可。
代码
#include四、简答题
题目
思路
笔者的见解比较浅薄(其实是不知道),于是就猜测了一下
- 文本复制粘贴
- 复制阶段,操作系统为我们创建一个缓存区, 并将我们复制的内容放入这个缓存区,然后给这个缓存区创建一一个定时器, 到一定程度后就自动销毁
- 粘贴阶段,操作系统从缓存区中复制一份,并且将内容输出到我们粘贴的地方
- 文件复制粘贴
- 复制阶段,操作系统会将该文件的路径记录在缓存区中
- 粘贴阶段,操作系统将缓存区的文件路径做一个软连接,放在当前目录,并不会真正的移动文件
下面是引用一下其他大佬的见解吧:
下面内容摘自:
-
https://www.zhihu.com/question/22554008
-
https://www.zhihu.com/question/66284095
操作系统中会有一块地方,称作剪贴板(clipboard),专门用来处理复制粘贴。
不同系统的细节可能会不同,但大致上是这样的:
- 复制文本时,会把所复制的文本克隆一份到剪贴板里面。粘贴文本时,再将剪贴板里的文本克隆到所粘贴应用程序之中;
- 复制文本时会保留其样式(比如在 Office 软件中复制,也会存储字体、字号等等信息,复制到剪贴板的实质上是一种「标记语言」)。但粘贴时若应用程序(比如记事本)不支持这些样式,则会去掉样式;
- 复制图片、混合富文本时,也是同样先克隆到剪贴板里。
- 复制文件时,系统只会把文件的路径复制到剪贴板,等到粘贴时再分情况处理:
- 同一分区下,粘贴(或剪切)文件,都不会真正在存储设备里直接克隆、挪动,而是更改此文件的路径(
path)属性。当然这与不同文件系统的具体实现有关; - (这也就是为什么,「复制 → 删除复制源文件 → 粘贴」这个操作会在大部分系统中失效了)
- 不同分区下,粘贴(或剪切)文件,会重新开辟空间,然后克隆文件;
- 涉及到与其他设备(即插即用设备等)之间的复制粘贴则更加复杂,实现各有不同。
- 同一分区下,粘贴(或剪切)文件,都不会真正在存储设备里直接克隆、挪动,而是更改此文件的路径(
- 还要考虑的情况,就是涉及虚拟机、远程主机的复制粘贴机制。虚拟机软件、远程主机软件都会有一个「介于两系统之间的」剪贴板,「连接起」这两个系统的各自剪贴板,并做一些编码格式转换的工作。
- 关于虚拟机复制粘贴,更具体的细节可以看这里:Is it possible to copy paste between Mac OS and its virtual machine? 各软件实现有异。