BW4HANA转换与DTP
其实我觉得这还真的是一个比较有意思的话题。
在知道了ADSO的各种类型之后,每个类型都有啥区别。其实用的多的也就标准ADSO和Staging ADSO。这个Staging还有compress和不compress的区别。也就是有两张表或一张表的区别。
那么既然在LSA里面,staging是底层,就是说可以直接fields的ADSO然后1对1往上抽。
但是呢,在实际应用中,如果你需要这个staging层。最好是搞个带compress的,虽然不从它弄报表。但是你只有有两张表了,才能说在inbound表改数据。不然一张表是改不出来的。而且compress了能少点空间。
有些公司LSA是搞了staging这一层的,有些公司没有这一层,直接上标准ADSO。上标准的呢,就是如果有数据错误的话,就不太好删,都激活了,删太难了只能搞个selective deletion。如果有个中间层staging来兜底。然后再恢复上层ADSO的数据,还是有些方便的。当然没有也没啥问题。
这中间会有个我的疑问,就是上层标准ADSO的change log表数据如果被删除了。那么此时如果有的R的记录,X和后象的记录,怎么弄呢?我有这个疑问,其实是我没理解清楚。change log的数据是怎么来的?其实是inbound表和active表对比来的。
如果你inbound里面没有这条,那么激活的时候,对比了active的数据,会在changelog里面生成一个R。同时删除active的数据。
如果inbound里面改了。那么还是对比和active的数据,然后去更新到changelog表。和changelog表有没有数据没关系。active这个动作,是先到active表,然后到changelog表的。
之后从changelog再到其他target的话,所有的更改也是会被捕获的。 没有问题。
回到转换和DTP上面来。从LSA的角度来讲。
我们最下层是DataSource。
数据源会有两种:如果是老的ERP,那就还是标准数据源。如果是S4那么就会有新的CDSview作为数据源。这个CDS view是你在S4那边新建了。然后在BW这边再建一个CDS数据源。就是基于你的SQL view来建一个提取。具体看这里:CDS
当然不论哪种数据源都是最底层。
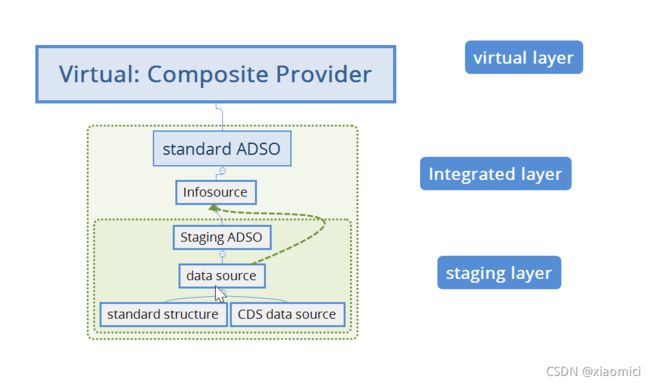
那么用infosource主要是为了如果你有很多个datasource数据源。而只在integrated层做一次transformation里面的rule。这样就很方便。那么实际上这样的转换是到infosource,而DTP是在ADSO里面的。

也就是说转换是两层,一层是从数据源到infosource,有N个数据源的转换,一般是1对1没逻辑,第二层是从infosource到ADSO,只有一个。而DTP只在ADSO里面建N个。
那如果我在datasource和infosource里面插一个staging ADSO,那么数据源一多,这也相当麻烦啊。所以忽略也行。几十个数据源要搞几十个DTP,还得double。那真是没办法搞。
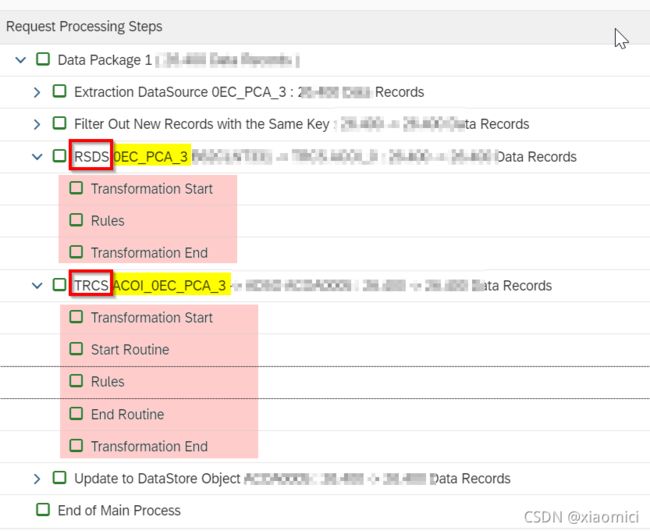
在DTP里面可以看到,实际上是一个DTP走了两步的转换。如下图,第一步RSDS走了数据源,是直接转换,没啥rule。
第二步是TRCS是指的infosource,有了start routine和end routine。最后结束更新到了ADSO里面。
前情介绍完毕:
文章目录
-
-
- 1.转换
-
- 1.1 转换中的HANA运行
- 1.2 HANA运行时间的ABAP 结束例程
- 1.3 转换规则
-
- 1.3.1 allow currency and unit conversion
- 1.3.2 check units for consistency
- 1.3.3 allow error handling for HANA routines
- 1.3.4 create inverse routine for abap routines
- 1.3.5 initialization of fields containing NULL values for SAP HANA Routines
- ***1.3.6 ABAP runtime & HANA runtime
- 1.3.7 rule group
- 2.DTP
- 2.1 DTP的delta机制设置
-
1.转换
那么实际操作过程中,转换和DTP里都会有很多个小的属性。如果你不知道怎么去设置。还是挺麻烦的。

简单的来看一般页,转换有两种方式,旧的是ABAP运行。新的是HANA运行(也就是AMDP语法,SQL)那么如果你的旧转换有一些field routine,或者start/end routine啥的使用ABAP语法写的(也就是用类和方法写的)那么就转换不成HANA运行(到数据库底层)。
这个ABAP运行,上面有两个复选框,默认勾上的那个是反转代码,意思是你有虚拟的infoprovider可以勾这个。如果嫌麻烦不用管。
那么Rules里面呢,也就是转换的规则。转换的规则有很多:

除了特殊的时间和ODP的recordmode转换,还有一个lookup。这个是啥意思呢?这个就像是Excel的VLOOKUP。
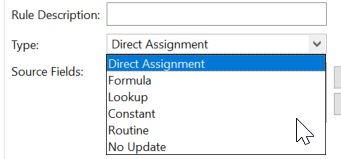
lookup的对象可以是ADSO,也可以是主数据characteristic。这个其实就是外连接表来获取数据。
情景如下:
- 主数据。
target要求的字段是source字段的属性。那么这个属性就直接从我源里有的字段的属性里面去找就行了。我这个源里的主数据字段就是关键的关联字。 - ADSO。
需要的target字段在ADSO里。
ADSO的主键和source的字段相同(需要关联ADSO的所有主键),那么我可以连接这些字段去获取我target的存在于ADSO中的字段值。
1.1 转换中的HANA运行
前提条件,你的user要有权限。
你在HANA database里面要写script,那么你得有 privilege:
- Privilege Execute on the object GET_PROCEDURE_OBJECTS of the schema SYS
- Privilege Execute on the TRUNCATE_PROCEDURE_OBJECTS of the SYS schema
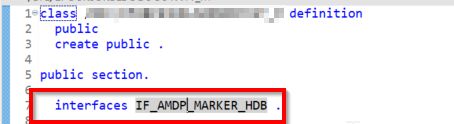
代码这里要有两个申明:
第一个是在这个类下面,有个接口:IF_AMDP_MARKER_HDB.
第二个是在方法那里:BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY
这两个都齐活了,才能是HANA运行,只有第一个不行。这个第二个就是说用的SQL语法了。跟ABAP语法不一样的了。

这个语法就是outab = select * from : intab;
这个里面就是三个重要的intab , outtab, errortab. 跟原来ABAP里面的result field(字段例程)result package一个意思了。
这个errortab一般你不选下面这个勾是不出来的:

那勾了的话,代码里就得声明,懒得管就给个空值。如果你勾了但是不声明,那你激活不了这个代码。

或者最后改成FROM “PUBLIC”.“DUMMY”
1.2 HANA运行时间的ABAP 结束例程
现在区分ABAP运行和HANA运行就是说它里面的代码语法是ABAP语法还是HANA语法。
HANA运行时间会把所有的SQL处理下放到HANA数据库层面去处理,这样就会很快。那么ABAP运行实际是在ABAP应用服务器上去处理,没那么快的。
但是呢,HANA运行处理完逻辑后,还是要返回到ABAP的应用服务器上来的。它说,现在我数据库层面处理完了,你应用层面还有什么要处理的?你去处理吧。
那么这里就有一个例外了,就是在HANA运行里,可以允许有ABAP语法的结束例程。只有这个结束例程可以哦。
这个是啥个意思呢?就是说如果你选了HANA运行时,那你还是可以写个ABAP语法的结束例程的。但是如果你同时有开始例程和字段例程,那么这两个得是HANA的SQL语法。等它俩都在HANA数据库处理完了,最后HANA把处理结果给回ABAP应用服务器的时候,还可以再来处理一个ABAP的结束例程。
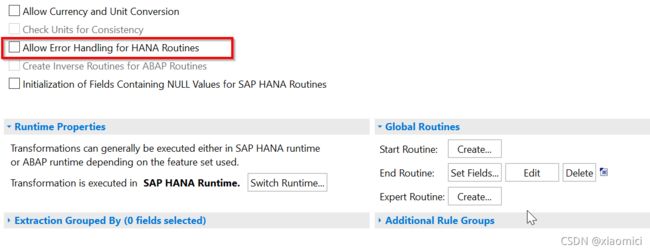
这种情况的前提条件是: 下面这个HANA 例程的错误处理就别勾了。要不然搞不起来的。
因为这个是HANA的逻辑了,你勾了这个,就带了一个HANA的errortab,这个就跟ABAP没办法兼容了。
还有就是你这个target得是ADSO或者infoobject,得是persist层存数据的。不能是ODS view这种。
如果你勾了,那这个结束例程的ABAP就灰了。
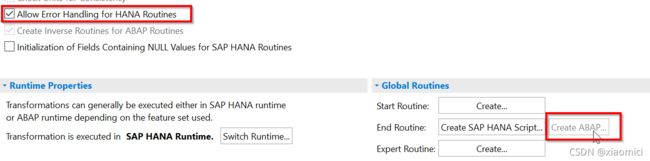
这个时候呢,在HANA下的ABAP例程,就不会有那个第二个声明了:
只有个这样的结束了。就是说它是不会转换成一个procedure的。
![]()
![]()
就是这个样的了:注释掉用Ctrl+7
METHOD GLOBAL_END.
FIELD-SYMBOLS:
<RESULT_FIELDS> TYPE _ty_s_TG_1.
DATA: MONITOR_REC TYPE rstmonitor.
loop at result_package assigning <result_fields>.
<result_fields>-* = *.
endloop.
在这里有一点稍微要注意的是,如果你的两层转换,就是中间有一个是infosource的,一个是HANA一个是ABAP,好像会报错还是啥的。所以一般都是给弄成一致的。
我想可能是因为就只有一个DTP,它实际上走了两步转换的话,第一个是从数据源到infosource,第二步是从infosource到ADSO,如果转换运行一个是HANA,一个是ABAP,大概DTP不支持这么搞。
1.3 转换规则

1.3.1 allow currency and unit conversion
这是啥意思呢?就是说允许你的货币和单位转换。一般呢,我们可以在field routine里面做转换的。写代码。
但是你也可以这样搞转换。
前提条件是,你的这个计量值得是在target里面1. 是infoobject,2. 是key。
一般好像不这么搞,我没见过把计量值当成key的。我具体也没操作过。
1.3.2 check units for consistency
这个就是检查单位的一致性。去T006表主数据检查,如果你这个record的单位不在人家主数据表里,就数据一致性就不行。就不会给你加这条数据的,会报错的。一般也不选。
1.3.3 allow error handling for HANA routines
这个是在HANA routine里面的,给你个error_tab,要写代码进行处理。
1.3.4 create inverse routine for abap routines
这个也是有个单独的地方,在inverse下面你要写routine的。但是这个如果是空的也没事。具体这个反转代码,我还真没用过。HANA routine 里面没这个。
我查了下解释,是说这个用于virtual provider。为了性能提升,来建这个反转routine。就是把这个在导航步骤(应该说是在query里面的查询步骤)里的查询条件直接转换成提取器的查询条件。在report-report接口,你得用这个。。。我尽力了。。。
1.3.5 initialization of fields containing NULL values for SAP HANA Routines
这个也是在HANA routine里面的。就是源如果来了NULL值,到HANA这里就不接受。如果到了target还是NULL,HANA就说不行,我不允许。
那么你点了这个选项,他会把NULL给转换掉,如果char类型,那就是blank,如果numeric类型,那就0. 那就如果你搞了HANA routine,不嫌累的,那就点上这个吧。
***1.3.6 ABAP runtime & HANA runtime

就是说HANA routine有更好的处理大量数据的能力,它快。搞到内存里去计算了。
但是对于ODP 源系统,还是用ABAP runtime吧。因为它这个提取就是用的ABAP,你用个HANA的转换是徒劳,HANA的得是一开始给它弄到persist层去,让它去数据库处理才好。
对于ABAP runtime和HANA runtime有一个区别点,就是ABAP runtime会自动给你处理一些数据类型转换,char类型的数据如果有数字会自动给你转成integer类型。但是在HANA里面,就会有个runtime error了。所以你得在formula或者HANA 的script里面去给他转换类型。
第二个不同点就是,round。ABAP会自动四舍五入,HANA不会。
如果你的DEC有三位小数,那么2/3 在ABAP里面是0.667,在HANA里面就是0.666
你得自己搞公式去给他限定。
TO_DECIMAL(ROUND(TO_DOUBLE(AMOUNT)/TO_DOUBLE(/BIC/SZDEC02);3;“);17;3)
虽然说HANA runtime通过创建一个数据库存储结构,一个列视图来搞到数据库去计算快了很多。但是它不能完全来替代ABAP runtime。有些function module啊,一些ABAP对象啊,还得用ABAP runtime来搞,你要去替换那些ABAP代码,太复杂了啊。
所以这个HANA runtime到底怎么用,什么情景下用,还是得靠功力来看。从我的理解来看呢,最好LSA的底层不要用HANA runtime 了。都是ODP数据源啥的,没必要。往上层A-P层,那大家都是ADSO了,都实在的存数了,那就就用用吧。
对于那种用了HANA runtime的,SAP推荐你在转换里面用一些lookup,就是说你用read master data或者read from datastore object,能不用code写就不用code写。这对性能提升很有帮助。
对于在HANA runtime的end routine里面写ABAP代码,这个有个前提条件,是你的target是persist的对象,得是ADSO啥的。不能是ODS view。
1.3.7 rule group

就是一组准换规则。一个转换可以包含很多rule group。
![]()
一般情况下我们有标准规则组和技术规则组。你如果要一条source多条target,就建一个rule group。像hierarchy里面的rule group一样。
还有一个extraction grouped by,这个是在转换里面把record按照你给的字段来分组。这个是和以前DTP的sementic key一样。
主要用来:1. 分组 2.error stack处理。
这两处都有。都有的时候,系统来处理是个combine.

2.DTP
如果要debug你这个转换里面的例程。
先打个断点,小蓝点。

然后在DTP里面,如果想先测试,不传数据,那就先模拟:

如果要针对特定的一些record,选export mode来做过滤:

下一篇:debug.
在DTP里面也有一些选项。那都是什么意思呢?

- 提取模式:全量或增量。增量中,右侧有请求的不同场景的执行方式。
Perform delta initialization without data: 目标已经有了这个数据了。那么已经有了的request ID就不会被再次抽取。
Only get delta once: 原本增量数据源只能被target抽取一次。我不太懂这个啥用。 - 处理模式:就是抽取,转换和传输的步骤。转换中的运行时间HANA runtime和ABAP runtime会影响到这个处理模式。下面就是一些技术状态。
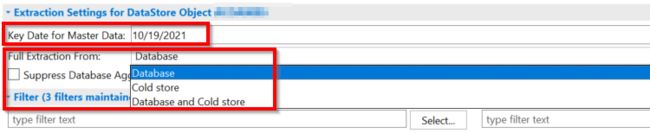
Key date呢是如果你主数据比如层级是时间相关的,那么提取的时候只提有效时间的数据。这个DTP的例子是从ADSO来的。
如果直接从数据源就会简单点没这些。
抽取可以从热、冷两个地方数据库来。取决于你ADSO的温度划分,你如果要archive的数据,那么就所有的都要。
还有个suppress database aggregation,这个默认给你勾上,啥意思呢?就是如果你勾了,那么key figure会先聚集,然后执行你的那些转换逻辑。如果你不勾,那就是先每个record执行你的转换逻辑,然后激活的时候会再给你聚集。

还可以加过滤值,或者分组。分组的语义最后可以用于错误堆栈分析。
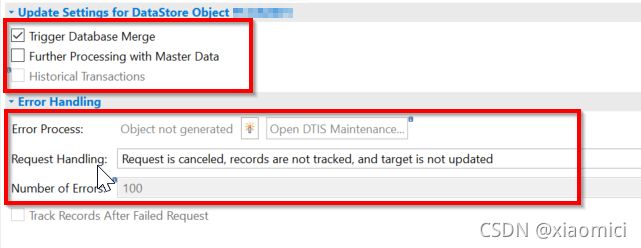
在更新的时候,如果触发数据库合并就是说的HANA列存储的Main storage和delta storage的合并。如果不勾,在处理链中也能弄。
更多主数据的处理呢,也就是参照完整性。不勾。让那些SID表没有的也能更新进去。
错误处理:你这个是HANA或者ABAP的可以有error 处理。如果是HANA runtime有个ABAP endroutine的,那错误处理不起来。
请求的处理有三个选项:

要想处理错误数据,选第二个。
下面还有个追踪失败请求。HANA runtime不是默认启动的。ABAP runtime时,在处理链失败后重新执行,再次失败会跟你讲你上次record失败了。
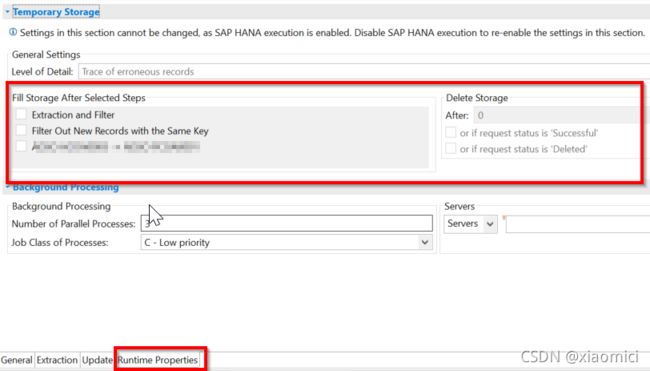
最后运行属性。第一个是临时存储。
是说DTP执行的每一步,都会存一个临时表,这样你可以好debug,而且对于错误的record也可以在这里进行查询。对于错到一半的,从错的地方还可以再次执行。
启动临时存储,可以在properties里面看到program flow。具体有DTP每一个执行步骤。
那么当你去处理错误请求的时候,就是在error handling下面选填入错误堆栈。然后你要再生成一个error DTP。
这个error DTP会把你错误堆栈里面的记录(修复好了以后)更新到目标。
在哪里修复?在那个右边的DTIS里面。就像inbound表一样。
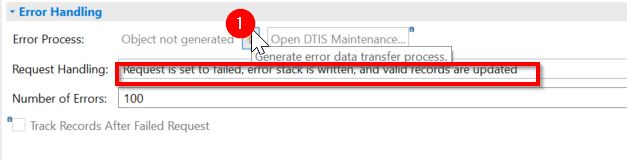
等修好了,把前一个DTP的状态改成OK。然后再执行一下这个新DTP。就可以了。
2.1 DTP的delta机制设置
这个算是插播。
在Extraction Mode里面:
Delta的第一次是初始化抽取所有历史数据,第一次以后就是抽取上次没被这个DTP抽过的。

Full就是全部抽。只能是说数据是覆盖型的。那可以full。而且也可以是如果你的delta是分语义层的。那么错的那条有filter的语义可以用这个full来修复。
*only get delta once:只抽一次。下次就不抽了。那万一下次这条还有更改呢?如果这个数据说出错了,我想在target里面删掉,然后再重新抽一次呢?
这种情况就是源如果有数据被删掉,它不会有R,也不会有D。它没办法告诉目标。那我目标就只能自己来删了。一般情况不用。我觉得这个可能是用来替代巨量数据无法用Full的情况。
*parallel processing: 并行处理。提取和处理多个包。默认使用。但是如果说数据的一致性与记录的顺序特别相关,那就不太好用了。那就一个串行吧。
*perform delta initialization without data: 就上次你抽过了。这次那就不用抽数了,就告诉它,我抽过了,别重复给了。很少用。
然而根据实际应用来看呢,勾上这个的话,好像只是对已经抽取过的delta数据有了限制,如果有新的数据,还是会抽过来的。也就是跟它的前提Delta不冲突。我感觉,这个只对第一次初始化有限制。对之后的数据影响呢也就是只抽新的:



数据源给的条目数,最后就是它抽取的条目数。
Delta增量机制是保证了从上次抽取之后到这次抽取之间的所有数据都会被抽取。当数据源的增量数据被Delta DTP给抽取了之后,那增量数据在queue里面默认24小时后(成功被提取)就会被删除(这个保留时间可以在ODQMON里面去做更改)。
如果是BW那边的DTP请求出错,那么就要删除last request(把请求设置成error)。然后再执行一遍Delta DTP去拉queue里面的数据。毕竟源那边是不会再给你一遍增量数据的。
所以说有时候你在infoprovider里面删除请求的时候,要想清楚,你删了这个数据,那么delta请求没办法再从delta queue取数据过来了。你得把这个infoprovider的所有DTP的 delta 请求删除掉,然后再弄一个新的delta初始化来搞数据了。
如果你这个Delta DTP实际上已经不跑了。那么你在delta queue那边可以就把这个subscriber删掉了。