实测结果公开:用户见证 StarRocks 存算分离优异性能!
StarRocks 在 3.0 版本正式引入了存算分离架构,从 shared-nothing 走向 shared-data,实现了架构上的重大升级。这一升级受到许多用户的高度期待,因为它不仅是企业降本增效的关键,也是 StarRocks 迈向云原生的必经之路。因此,在 StarRocks 3.0 版本发布初期,StarRocks 号召了社区用户响应存算分离的测试活动,以便用户通过实际测试来反映最真实的使用体验和性能。
在用户测试报告中,StarRocks 存算分离在数据导入性能、查询性能都与存算一体达到了一致;在冷数据查询的场景的性能也只有 50% 左右的性能下降。此外,在查询性能扩展能力上,我们通过测试报告可以看到随着计算节点的增加,查询性能会接近线性增长。
以下是此次征文活动的摘录内容,完整的用户测试报告请查看:https://forum.mirrorship.cn/t/topic/7110
数据导入
❗️通过多种方式模拟真实的写入场景,包括历史数据的批量写入以及实时数据的持续写入。经测试 StarRocks 存算分离的写入吞吐与存算一体基本相当。
数据小黑@浪潮:总的来说,在我们的实际测试中,由于我们使用了自建的 MinIO,存算一体和存算分离在导入性能上基本保持一致。
导入方式:stream load (total bytes 7711779006);
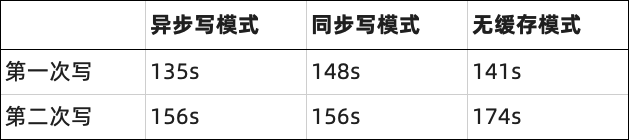
张了了@聚水潭:资源稳定的情况下,存算分离开启本地缓存和存算一体写入基本持平。异步写入参数对于写入性能有较大影响,关闭后对于写入性能有大约 7 倍左右的提升。
导入方式:stream load
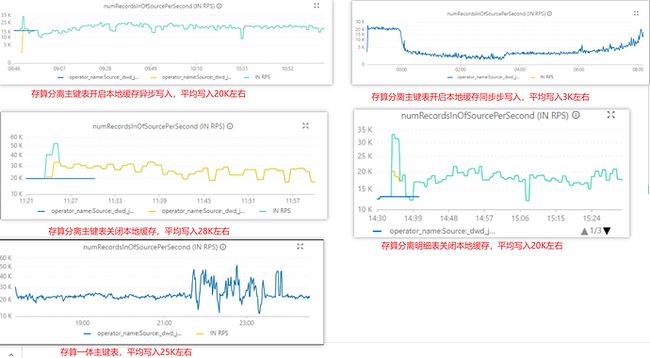
杨荣:单表同步任务使用 Flink 实时持续写入,单 BE 最高吞吐 120MB/s 左右。部分列更新场景写入峰值可达 11.8 w records/s,平时可以到 5w records/s 以上,满足业务对导数性能的需求。在近 50 个写入并发下,存算分离集群运行整体平稳。
导入方式:Flink 实时写入

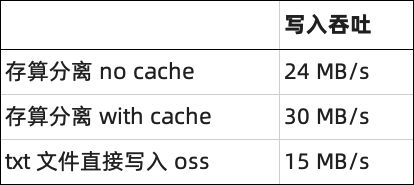
rink@天道金科:使用 StarRocks 存算分离表相较于原有的 txt 数据存储到 OSS 的数据同步方式,写入吞吐有一倍左右的性能提升。
导入方式:DataX
Richard@芒果TV:导入性能符合预期
导入方式:stream load /routine load /SQL insertRoutine load 导入峰值12万 QPS,数据 json 格式,单条大小 300B 左右。Stream load 导入峰值15万 QPS,数据 json 格式,单条大小 100B 左右。
SQL insert 使用 Hive catalog,将 Hive ORC 表数据 insert 到 OLAP 表,按照 Hive 天分区导入,4000 万数据导入耗时 90S 左右。
查询性能
❗️StarRocks 存算分离的版本通过 cache 机制达到了与存算一体版本相同的查询性能。
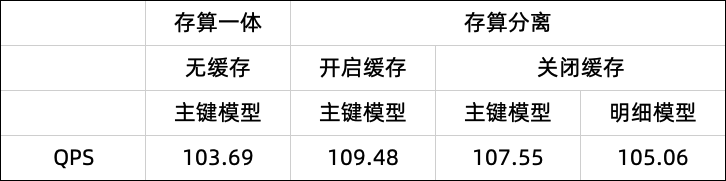
张了了@聚水潭:对于单 SQL 查询来看,开启本地缓存后有明显优化,查询性能基本和存算一体表持平,根据回放测试表现来看,基本都可以符合在 100 左右的 QPS。
测试方法:50s 发送 5000 个查询
rink@天道金科:对比 Spark,Trino 的查询框架,StarRocks 存算分离在 cache 命中的情况下有数十倍的性能优势。未命中 cache 的情况下也有数倍的性能提升。
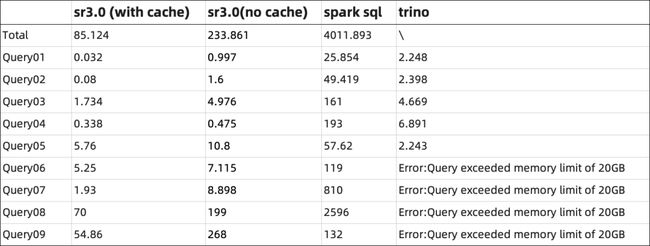
杨荣: local 表与 cloud native 表的查询性能基本持平,q1 在 10 并发以上的场景下 cloud native 表都比 local 表查询性能要好。
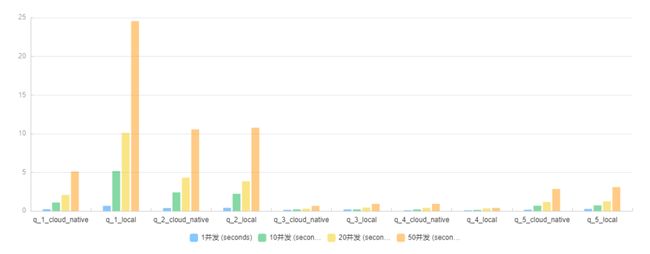
任伟:简单查询场景下,存算分离的查询并发响应时间优于存算一体。复杂查询的场景下两者基本持平。
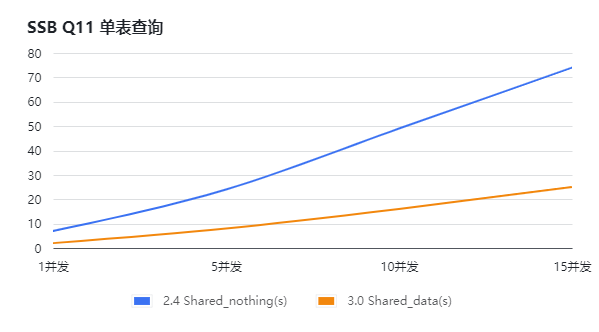

Richard@芒果TV:存算分离内表查询性能相比于 Presto 有 5 倍以上的性能提升,部分查询性能可以提升数十倍。

冷数据查询性能
❗️存算分离的优势之一是,存储可以独立于计算资源单独扩容。但是首次查询或者是大批量的历史数据查询时 cache 容量有限,需要对远端存储的冷数据进行分析。通过测试验证表明,存算分离的冷数据查询性能对比热数据(cache 命中)只有 50% 左右的性能下降。
任伟:冷热数据(本地是否有磁盘 cache)SSB 全部 SQL 有2.5倍左右的性能差距,TPC-H 全部 SQL 有1.5倍左右的性能差距。
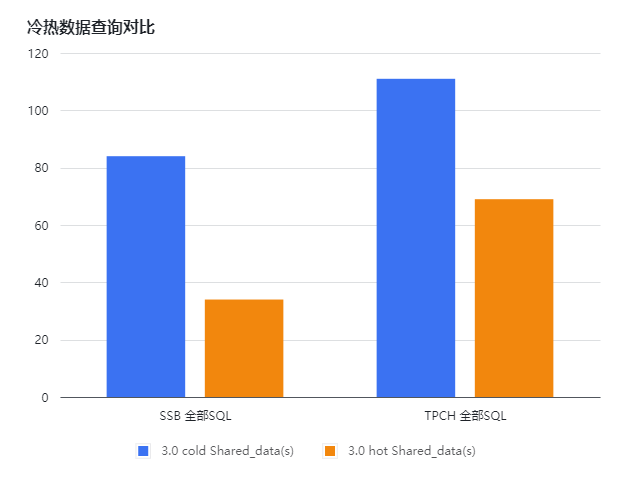
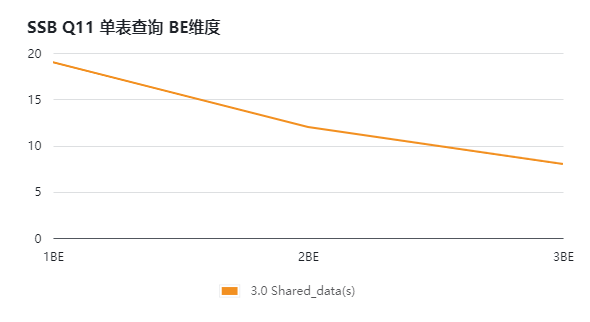
查询性能扩展能力
❗️通过水平扩容的方式验证存算分离版本的查询性能提升。通过测试可以看到随着计算节点的增加,查询的响应时间会接近线性下降。
任伟:可以看到不论是单表的简单查询还是多表的复杂查询,随着 BE 节点的增加查询性能均有明显的提升。

未来规划
未来,StarRocks 将继续坚定不移地优化存算分离架构,并会在以下方面持续发力:
-
Cache 能力的持续优化:StarRocks 将使用自研的 Cache 来优化性能和效率
-
Multi-warehouse:一份数据,多处计算。通过 multi-warehouse 技术实现真资源隔离,进一步提升业务系统稳定性
-
实时场景优化:我们在3.1版本将开启对主键模型表的存算分离能力支持,并且将继续优化存算分离场景下的实时能力
-
继续优化存算分离架构下的弹性能力:配合 multi-warehouse,在 multi-warehouse 内引入智能化的自动弹性能力,在业务峰谷期实现资源的自动伸缩,降本增效,省人也省事
-
继续深化推进存算分离:在 BE 存算分离基础上进一步实现 FE 的存算分离
想要再深入了解更多关于 StarRocks 存算分离架构吗?欢迎利用以下资源:
兼顾降本与增效,我们对存算分离的设计与思考
深入探索 StarRocks 存算分离架构
存算分离用户小组:
StarRocks Feature Group 正式成立,欢迎入群对特定 feature 进行深入交流!
下方添加小助手,回复关键字“存算分离”即可加入 StarRocks 存算分离用户小组,开启你的降本增效之旅!
https://842372.ma3you.cn/articles/Oz4kpdl/