【爬虫+多线程+MySQL】网抑云音乐评论爬取
提示:本文仅作学习交流使用,下面案例可供参考。
文章目录
- 前言
- 一、爬取所有华语男歌手姓名及ID
-
- 1.网页分析
- 2.代码实现
- 3.部分运行结果
- 附:url详解
- 二、爬取所有华语男歌手专辑ID
-
- 1.网页分析
- 2.代码实现
- 3.部分运行结果
- 三、爬取所有华语男歌手创作音乐名称及ID
-
- 1.网页分析
- 2.代码实现
- 3.部分运行结果
- 四、爬取华语男歌手创作音乐热门评论
-
- 1.网页分析
- 2.代码实现
- 3.部分运行结果
- 五、MySQL代码实现
- 总结
前言
之前在网上找到相关开源项目,发现由于网站结构变化或者其他原因,导致代码不能正常运行。在此基础上修改了部分代码,同时加上了必要的注释,当作自己爬虫练习。
本文主要内容为网抑云音乐爬虫,目标为爬取所有华语男歌手创作的音乐的热门评论。本文主要运用requests库发起请求,通过BeautifulSoup进行数据解析,将最后的爬取到的信息存入MySQL数据库中。本文实现需求需要配置好数据库,创建好对应数据库和数据表,之后按顺序完成前四个步骤,循序渐进,各步骤均有代码实现。
一、爬取所有华语男歌手姓名及ID
1.网页分析
- 首先进入歌手信息页面:https://music.163.com/discover/artist/cat
- 通过抓包工具,可以观察到并没有相应的数据接口,所以只能从其网页源代码入手。
- 通过分析页面可以得出,其URL的查询字符串共有两个参数:
id和initial。
id:用于区分歌手的类型
| id | type |
|---|---|
| 1001 | 华语男歌手 |
| 1002 | 华语女歌手 |
| 1003 | 华语组合/乐队 |
| 2001 | 欧美男歌手 |
| 2002 | 欧美女歌手 |
| 2003 | 欧美组合/乐队 |
| 4001 | 其他男歌手 |
| 4002 | 其他女歌手 |
| 4003 | 其他组合/乐队 |
| 6001 | 日本男歌手 |
| 6002 | 日本女歌手 |
| 6003 | 日本组合/乐队 |
| 7001 | 韩国男歌手 |
| 7002 | 韩国女歌手 |
| 7003 | 韩国组合/乐队 |
inital:用于区分歌手姓名拼音首字母
| inital | type |
|---|---|
| 65 | A |
| 66 | B |
| 67 | C |
| 68 | D |
| 69 | E |
| 70 | F |
| 71 | G |
| 72 | H |
| 73 | I |
| 74 | J |
| 75 | K |
| 76 | L |
| 77 | M |
| 78 | N |
| 79 | O |
| 80 | P |
| 81 | Q |
| 82 | R |
| 83 | S |
| 84 | T |
| 85 | U |
| 86 | V |
| 87 | W |
| 88 | X |
| 89 | Y |
| 90 | Z |
通过修改参数可以得到自己想要的数据,本文以所有华语男歌手为例,所以选取id=1001,inital=65~90。
2.代码实现
请求头设置与使用BeautifulSoup页面解析在代码中有具体实现,需要除华语男歌手数据之外的数据,可以通过修改上述参数实现。
# singers.py
"""爬取所有华语男歌手姓名及ID,存入数据库singers表中"""
import random
import requests
from bs4 import BeautifulSoup
# MySQL相关实现在下文
import sql
# UA池
UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
# 请求头
headers = {
'Cookie': '_ntes_nnid=0e6d3b71d7da032f61356a27d3fc194f,1601777819190; vinfo_n_f_l_n3=e94c9b8a4475073b.1.1.1601777819201.1601778713022.1601781972612; [email protected]|1618027035|0|mail163|00&99|lin&1618023823&mail163#lin&210200#10#0#0|&0|mail163&unireg|[email protected]; [email protected]:-1:1; _iuqxldmzr_=32; NMTID=00OsmCCeE-B_bVIJ0SImjak6JpZpdkAAAF4ue1aeQ; WM_TID=oPBxoZvaLp1BRQEAVVcu1cvCuON39iVM; _ntes_nuid=0e6d3b71d7da032f61356a27d3fc194f; JSESSIONID-WYYY=DoM%5Cw0ipCrmVHnDud0%2BtdxcvTz3UWcDd2JCvz9xO53tlx6S%5C%2Bg4bD8CKkA8K9jFQYY4I%5C76pBERvH%2Fvtm%5CjKy13MY7ZgEodaOQ0eq00GXkqcBcf%5CVoRI9kaWxx8FrllQEx6HoHe0%2FHcpGlsMo2gXHSAPoN4U3JGxbrbqawl8ZmoxV0n%2F%3A1629300525527; WNMCID=pmtxae.1629298725835.01.0; WEVNSM=1.0.0; WM_NI=6LFupq8QuWQn7oNm%2FiWFEGE0caGUGkRfLjbeInQOkhdQiQkqTGvLJqqWOovp61apSVt2UKJj9K6Qa7PM83k%2BZoWjvDQnf%2BCoOG3fGmEQGCQhrRnSP0gJYt71Z0yXemP4dUE%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb5b73ff896f9d7d03ab89e8eb6c85b979a8a84f167afbb9994d25c85bdaf85f92af0fea7c3b92af6948a96f37bfc8fbbb8d466f5b1828eae63959a8ba8c83ca1bf89b6c66192ba848be16f8bb29fb0ea64a88fa7b2ea7b9899baadc97bb3898190f57cf6efaf91d25eb8ee9bacc962fb95fab2e43d9493f8d4ea219ab1998bf55093b2aaccc2658d99fd87c667878f89a4d464b28ea2b4d33ca5969795b63b9af0b7b9e86794ecacb6c837e2a3',
'Referer': 'http://music.163.com/',
'User-Agent': random.choice(UApool),
}
def getSingers(id, initial):
# 歌手信息页面
url = 'http://music.163.com/discover/artist/cat'
# 参数
params = {
'id': id,
'initial': initial,
}
# 发起请求 获得响应
response = requests.get(url=url, headers=headers, params=params)
# 网页源代码
html = response.text
# BeautifulSoup网页解析
soup = BeautifulSoup(html, 'html.parser')
body = soup.body
# 定位目标标签
singers = body.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'})
for singer in singers:
# 歌手id
singerId = singer['href'].replace('/artist?id=', '').strip()
# 歌手姓名
singerName = singer['title'].replace('的音乐', '').strip()
try:
# 歌手信息存入数据库
sql.insertSinger(singerId, singerName)
print('歌手【ID:{}】信息存储完成'.format(singerId))
except Exception as e:
# 打印错误日志
print(e)
if __name__ == '__main__':
# 参数id
# 1001 华语男歌手 1002 华语女歌手 1003 华语组合/乐队
# 2001 欧美男歌手 2002 欧美女歌手 2003 欧美组合/乐队
# 4001 其他男歌手 4002 其他女歌手 4003 其他组合/乐队
# 6001 日本男歌手 6002 日本女歌手 6003 日本组合/乐队
# 7001 韩国男歌手 7002 韩国女歌手 7003 韩国组合/乐队
# 参数initial
# 姓氏拼音首字母A-Z 65-90
id = 1001
for initial in range(65, 91):
getSingers(id, initial)
3.部分运行结果
SQL语句:SELECT singerId,singerName FROM singers ORDER BY singerId;

附:url详解
URL是Uniform Resource Locator的简写,统一资源定位符。 一个URL由以下几部分组成:
scheme://host:port/path/?query-string=xxx#anchor
- scheme:代表的是访问的协议,一般为
http或者https以及ftp等。 - host:主机名,域名,比如www.baidu.com。
- port:端口号。当你访问一个网站的时候,浏览器默认使用
80端口。 - path:查找路径。比如:https://music.163.com/discover/artist/cat,后面的
discover/artist/cat。 - query-string:查询字符串,比如:www.baidu.com/s?wd=python,后面的
wd=python。 - anchor:锚点,前端用来做页面定位的。
在浏览器中请求一个URL,浏览器会对这个URL进行一个编码。除英文字母,数字和部分符号外,其他的全部使用百分号+十六进制码值进行编码。
二、爬取所有华语男歌手专辑ID
1.网页分析
- 选取歌手阿信,进入其个人主页:https://music.163.com/artist/album?id=1875&limit=200
- 通过分析页面可以得出,其URL的查询字符串共有两个参数:
id和limit。id:歌手ID。limit:不需要修改,实测该参数不提供也行。
2.代码实现
请求头设置与使用BeautifulSoup页面解析在代码中有具体实现,由于网页结构基本类似,代码结构同样类似。
# albums.py
"""根据singers.py爬取得到的歌手ID,获取该歌手所有的专辑ID,存入数据库albums表中"""
import requests
from bs4 import BeautifulSoup
import random
import time
# MySQL相关实现在下文
import sql
# UA池
UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
class Album(object):
# 请求头
headers = {
'Cookie': '_ntes_nnid=0e6d3b71d7da032f61356a27d3fc194f,1601777819190; vinfo_n_f_l_n3=e94c9b8a4475073b.1.1.1601777819201.1601778713022.1601781972612; [email protected]|1618027035|0|mail163|00&99|lin&1618023823&mail163#lin&210200#10#0#0|&0|mail163&unireg|[email protected]; [email protected]:-1:1; _iuqxldmzr_=32; NMTID=00OsmCCeE-B_bVIJ0SImjak6JpZpdkAAAF4ue1aeQ; WM_TID=oPBxoZvaLp1BRQEAVVcu1cvCuON39iVM; _ntes_nuid=0e6d3b71d7da032f61356a27d3fc194f; WNMCID=pmtxae.1629298725835.01.0; WEVNSM=1.0.0; WM_NI=6LFupq8QuWQn7oNm/iWFEGE0caGUGkRfLjbeInQOkhdQiQkqTGvLJqqWOovp61apSVt2UKJj9K6Qa7PM83k+ZoWjvDQnf+CoOG3fGmEQGCQhrRnSP0gJYt71Z0yXemP4dUE=; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb5b73ff896f9d7d03ab89e8eb6c85b979a8a84f167afbb9994d25c85bdaf85f92af0fea7c3b92af6948a96f37bfc8fbbb8d466f5b1828eae63959a8ba8c83ca1bf89b6c66192ba848be16f8bb29fb0ea64a88fa7b2ea7b9899baadc97bb3898190f57cf6efaf91d25eb8ee9bacc962fb95fab2e43d9493f8d4ea219ab1998bf55093b2aaccc2658d99fd87c667878f89a4d464b28ea2b4d33ca5969795b63b9af0b7b9e86794ecacb6c837e2a3; JSESSIONID-WYYY=zfdCBmRFxz8nPXIEXMb4TOQ9FKpu5bSPT0uc8mbMU3F7C5qM\KqlnmFWNSz1hsmbtU1OETAFvnW1X\ADCM3BxXCeP/dqEsIxmcB7tn7D8q2QANEKmx4ZGejePl6s4n2Q2ad4GnBt\gTafaK05YNjv3nzvPzvsfQBJpHJ\zuhJ4fbzclu:1629302265856',
'Referer': 'http://music.163.com/',
'User-Agent': random.choice(UApool),
}
def getAlbums(self, singerId):
# 歌手专辑链接
url = 'http://music.163.com/artist/album'
# 参数
params = {
'id': singerId,
'limit': 200,
}
# 发起请求 获得响应
response = requests.get(url=url, headers=self.headers, params=params)
# 网页源代码
html = response.text
# BeautifulSoup网页解析
soup = BeautifulSoup(html, 'html.parser')
body = soup.body
# 定位目标标签
albums = body.find_all('a', attrs={'class': 'tit s-fc0'})
for album in albums:
# 专辑ID
albumeId = album['href'].replace('/album?id=', '').strip()
# 专辑信息存入数据库
sql.insertAlbum(albumeId, singerId)
print('歌手【ID:{}】专辑存储完成'.format(singerId))
if __name__ == '__main__':
# 获取所有歌手的ID
singersID = sql.getAllSingerId()
# 实例化Album对象
album = Album()
for item in singersID:
try:
album.getAlbums(item['singerId'])
except Exception as e:
# 打印错误日志
print(str(item) + ': ' + str(e))
time.sleep(5)
3.部分运行结果
SQL语句:SELECT albumId,singerId FROM albums ORDER BY singerId;

三、爬取所有华语男歌手创作音乐名称及ID
1.网页分析
- 选取歌手阿信专辑《青空未来》,进入该专辑页面:https://music.163.com/album?id=131026477
- 通过分析页面可以得出,其URL的查询字符串只有一个参数:
id。id:专辑ID。
2.代码实现
请求头设置与使用BeautifulSoup页面解析在代码中有具体实现,由于网页结构基本类似,代码结构同样类似。
# music.py
"""根据albums.py爬取得到的专辑ID,获取该专辑所有的音乐名称及ID,存入数据库music表中"""
import requests
import random
from bs4 import BeautifulSoup
import time
# MySQL相关实现在下文
import sql
# UA池
UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
class Music(object):
# 请求头
headers = {
'Cookie': '_ntes_nnid=0e6d3b71d7da032f61356a27d3fc194f,1601777819190; vinfo_n_f_l_n3=e94c9b8a4475073b.1.1.1601777819201.1601778713022.1601781972612; [email protected]|1618027035|0|mail163|00&99|lin&1618023823&mail163#lin&210200#10#0#0|&0|mail163&unireg|[email protected]; [email protected]:-1:1; _iuqxldmzr_=32; NMTID=00OsmCCeE-B_bVIJ0SImjak6JpZpdkAAAF4ue1aeQ; WM_TID=oPBxoZvaLp1BRQEAVVcu1cvCuON39iVM; _ntes_nuid=0e6d3b71d7da032f61356a27d3fc194f; WNMCID=pmtxae.1629298725835.01.0; WEVNSM=1.0.0; WM_NI=6LFupq8QuWQn7oNm%2FiWFEGE0caGUGkRfLjbeInQOkhdQiQkqTGvLJqqWOovp61apSVt2UKJj9K6Qa7PM83k%2BZoWjvDQnf%2BCoOG3fGmEQGCQhrRnSP0gJYt71Z0yXemP4dUE%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb5b73ff896f9d7d03ab89e8eb6c85b979a8a84f167afbb9994d25c85bdaf85f92af0fea7c3b92af6948a96f37bfc8fbbb8d466f5b1828eae63959a8ba8c83ca1bf89b6c66192ba848be16f8bb29fb0ea64a88fa7b2ea7b9899baadc97bb3898190f57cf6efaf91d25eb8ee9bacc962fb95fab2e43d9493f8d4ea219ab1998bf55093b2aaccc2658d99fd87c667878f89a4d464b28ea2b4d33ca5969795b63b9af0b7b9e86794ecacb6c837e2a3; JSESSIONID-WYYY=E%5Cekmah%2B2zem%2FBGBSfAOQYp%2BPzsARHt7xnslWkrT3Vpke78RynVmOCZPGHbSdmBOOMXb%2Fnn%2BSO3249%5CSbAzMV%2BC1aQQYfbj1e3BwzB0Z%5ChGqsGIGS0nQUF0nK8bUAAySMWy%2B%5CYw9jX%2Ba8jfsQwfU53uuOeVqeIIEl6mEEQkPud45Npdz%3A1629347666845',
'Referer': 'http://music.163.com/',
'User-Agent': random.choice(UApool),
}
def getMusic(self, albumId):
# 专辑中歌曲信息的链接
url = 'http://music.163.com/album'
# 参数
params = {
'id': albumId
}
# 发起请求 获得响应
response = requests.get(url=url, headers=self.headers, params=params)
# 网页源代码
html = response.text
# BeautifulSoup网页解析
soup = BeautifulSoup(html, 'html.parser')
body = soup.body
# 定位目标标签
musics = body.find('ul', attrs={'class': 'f-hide'}).find_all('li')
for music in musics:
music = music.find('a')
# 歌曲ID
musicId = music['href'].replace('/song?id=', '').strip()
# 歌曲名称
musicName = music.getText()
# 歌曲信息存储到数据库
sql.insertMusic(musicId, musicName, albumId)
print('专辑【ID:{}】歌曲存储完成'.format(albumId))
if __name__ == '__main__':
# 获取所有专辑的ID
albums = sql.getAllAlbum()
# 实例化Music对象
music = Music()
for item in albums:
try:
music.getMusic(item['albumId'])
except Exception as e:
# 打印错误日志
print(str(item) + ': ' + str(e))
time.sleep(5)
3.部分运行结果
SQL语句:SELECT musicId,musicName,albumId FROM music ORDER BY albumId;

四、爬取华语男歌手创作音乐热门评论
1.网页分析
-
进入林俊杰创作的歌曲《江南》页面:https://music.163.com/song?id=26305527
-
通过抓包工具,可以观察到有相应的数据接口。
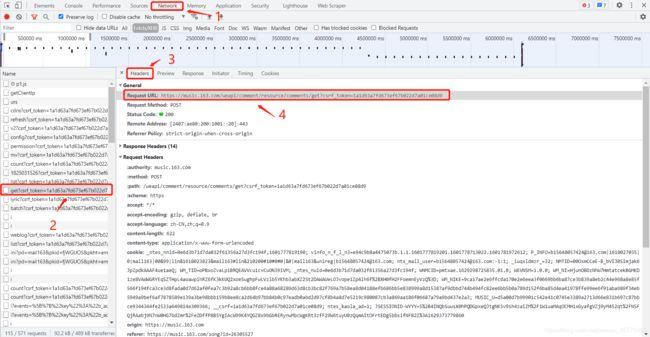
-
通过分析可以发现,下图这两个字段通过JS进行加密,会JS逆向的小伙伴可以尝试使用这个接口。

-
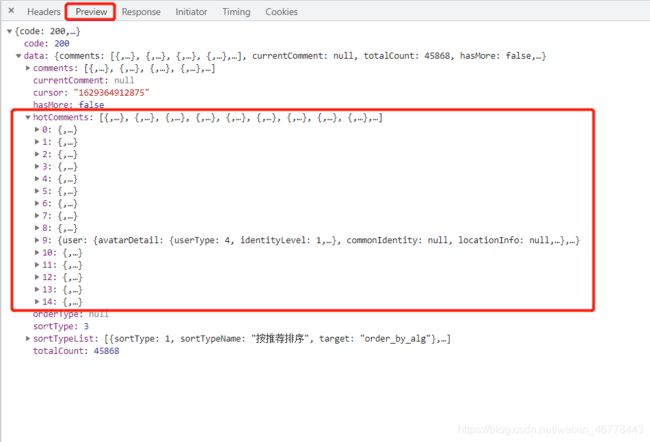
无法解决JS加密问题,但通过百度发现有其他数据接口可以获取评论信息:
http://music.163.com/api/v1/resource/comments/R_SO_4_ + musicId
- 用此接口查看林俊杰《江南》的评论,利用JSON在线视图查看器查看结果,提取出想要的数据。

2.代码实现
利用了多线程爬虫,将之前获得的数据分为两半分别交给两个线程进行处理。值得注意的是,有些歌曲可能没有评论,代码中有特殊处理。
# comment.py
# 注:需要将自己数据库密码填入。
"""根据music.py爬取得到的歌曲ID,获得所有的歌曲所对应的热门评论信息"""
import requests
import random
import sql
import time
import threading
import pymysql.cursors
# UA池
UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
class Comments(object):
# 请求头
headers = {
'User-Agent': random.choice(UApool),
'Cookie': '_ntes_nnid=245cf18b275ca93e963de3bc469594e3,1601644499267; _ntes_nuid=245cf18b275ca93e963de3bc469594e3; vinfo_n_f_l_n3=dca4621cd40ec194.1.2.1601644499276.1601777819250.1601781971956; NMTID=00OVux2wIv4gLrO_UqCpfJ_cvQ6bZIAAAF7Xi2gjg',
}
# 代理
proxies = {'https': 'http://127.0.0.1:10800'}
# 评论数据接口
api = 'http://music.163.com/api/v1/resource/comments/R_SO_4_'
def get_comments(self, musicId, flag):
# 请求头添加Referer
self.headers['Referer'] = 'https://music.163.com/song?id=' + str(musicId)
# 使用不同接口
if flag:
response = requests.post(self.api + str(musicId), headers=self.headers, proxies=self.proxies)
else:
response = requests.post(self.api + str(musicId), headers=self.headers)
# 返回json类型数据
return response.json()
if __name__ == '__main__':
# 实例化Comments对象
comment = Comments()
def getComments(musics, flag, connection0):
for item in musics:
musicId = item['musicId']
try:
# 获得Json格式的评论数据
commentJson = comment.get_comments(musicId, flag)
# 热门评论列表
hotComments = commentJson['hotComments']
# 数据解析
# 判断是否有评论
if len(hotComments) > 0:
for item in hotComments:
# 评论存入数据库
sql.insertComments(musicId, item['content'], connection0)
print('音乐【ID:{}】评论存储完成'.format(musicId))
except Exception as e:
# 打印错误日志
print(musicId)
print(e)
time.sleep(5)
musicBefore = sql.getBeforeMusic()
musicAfter = sql.getAfterMusic()
# pymysql链接不是线程安全的
connection1 = pymysql.connect(host='localhost',
port=3306,
user='root',
# 填自己的数据库密码
password='',
db='music',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
connection2 = pymysql.connect(host='localhost',
port=3306,
user='root',
# 填自己的数据库密码
password='',
db='music',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
t1 = threading.Thread(target=getComments, args=(musicBefore, True, connection1))
t2 = threading.Thread(target=getComments, args=(musicAfter, False, connection2))
t1.start()
t2.start()
3.部分运行结果
SQL语句:SELECT musicId, comment FROM comments ORDER BY musicId;

五、MySQL代码实现
- 创建名为music的数据库
SQL语句:CREATE DATABASE IF NOT EXISTS music;
- 创建名为singers的数据表
SQL语句:CREATE TABLE singers(singerId INT, singerName VARCHAR(50));
- 创建名为albums的数据表
SQL语句:CREATE TABLE music(musicId INT, musicName varchar(50), albumId INT);
- 创建名为music的数据表
SQL语句:CREATE TABLE music(musicId INT, musicName varchar(50), albumId INT);
- 创建名为comments的数据表
SQL语句:CREATE TABLE comments(musicId INT, comment TEXT);
# sql.py
# 注:需要将自己数据库密码填入。
import pymysql.cursors
# 连接数据库
connection = pymysql.connect(
# MySQL服务器地址
host='localhost',
# MySQL服务器端口号
port=3306,
# 用户名
user='root',
# 密码(填自己的)
password='',
# 数据库名称
db='music',
# 连接编码
charset='utf8mb4',
# cursor使用的种类
cursorclass=pymysql.cursors.DictCursor
)
# singers表结构
"""
CREATE TABLE singers(
singerId INT,
singerName VARCHAR(50)
);
"""
# 保存歌手
def insertSinger(singerId, singerName):
# 返回一个指针对象,用于访问和操作数据库中的数据
with connection.cursor() as cursor:
sql = "INSERT INTO `singers` (`singerId`, `singerName`) VALUES (%s, %s)"
# 执行一个数据库命令
cursor.execute(sql, (singerId, singerName))
# 事务提交
connection.commit()
# 获取所有歌手的ID
def getAllSingerId():
with connection.cursor() as cursor:
sql = "SELECT `singerId` FROM `singers` ORDER BY singerId"
cursor.execute(sql, ())
# 取出指针结果集中的所有行,返回的结果集[{},{},...]
return cursor.fetchall()
# albums表结构
"""
CREATE TABLE albums(
albumId INT,
singerId INT
);
"""
# 保存专辑
def insertAlbum(albumId, singerId):
with connection.cursor() as cursor:
sql = "INSERT INTO `albums` (`albumId`, `singerId`) VALUES (%s, %s)"
cursor.execute(sql, (albumId, singerId))
connection.commit()
# 获取所有专辑的ID
def getAllAlbum():
with connection.cursor() as cursor:
sql = "SELECT `albumId` FROM `albums` ORDER BY albumId"
cursor.execute(sql, ())
return cursor.fetchall()
# music表结构
"""
CREATE TABLE music(
musicId INT,
musicName varchar(50),
albumId INT
);
"""
# 保存音乐
def insertMusic(musicId, musicName, albumId):
with connection.cursor() as cursor:
sql = "INSERT INTO `music` (`musicId`, `musicName`, `albumId`) VALUES (%s, %s, %s)"
cursor.execute(sql, (musicId, musicName, albumId))
connection.commit()
# 获取前一半音乐的ID(多线程相关)
def getBeforeMusic():
with connection.cursor() as cursor:
sql = "SELECT `musicId` FROM `music` ORDER BY `musicId` LIMIT 0, 7000"
cursor.execute(sql, ())
return cursor.fetchall()
# 获取后一半音乐的ID(多线程相关)
def getAfterMusic():
with connection.cursor() as cursor:
sql = "SELECT `musicId` FROM `music` ORDER BY `musicId` LIMIT 7000, 13200"
cursor.execute(sql, ())
return cursor.fetchall()
# 获取所有音乐的ID
def get_all_music():
with connection.cursor() as cursor:
sql = "SELECT `musicId` FROM `music` ORDER BY `musicId`"
cursor.execute(sql, ())
return cursor.fetchall()
# comments表结构
"""
CREATE TABLE comments(
musicId INT,
comment TEXT
);
"""
# 保存评论
def insertComments(musicId, comment, connection0):
with connection0.cursor() as cursor:
sql = "INSERT INTO `comments` (`musicId`, `comment`) VALUES (%s, %s)"
cursor.execute(sql, (musicId, comment))
connection0.commit()
# 关闭数据库连接,并释放相关资源
def dis_connect():
connection.close()
总结
本文主要练习了使用requests库发起请求,包括设置请求头相关参数、使用代理、多线程爬虫等知识点;通过BeautifulSoup进行页面数据解析、从JSON类型数据中提取到相关数据;将最后的爬取到的信息存入MySQL数据库中,包括python连接数据库、SQL语句的使用、多线程爬虫与MySQL的结合等知识点。