语言模型用作知识嵌入
每天给你送来NLP技术干货!
来自:知识工场
知识嵌入(Knowledge Embedding)将知识图谱中的关系和实体嵌入向量空间进行表示。现有工作主要分为两类:传统的基于结构的方法(如TransE)在向量空间建模KG的结构信息,此类方法无法良好地表示真实知识图谱中大量结构信息匮乏的长尾实体;新兴的基于文本的方法(如Kepler)引入额外的文本信息和语言模型, 但该方向的现有工作相较于基于结构的方法存在以下不足,包括效率较低、表现不佳、限制性文本依赖等问题。
知识工场实验室提出了一个将语言模型用作知识嵌入的方法 LMKE,以期在提升长尾实体表示的同时解决现存基于文本方法的以上问题。LMKE 首次提出将基于文本的知识嵌入学习建模在对比学习框架下,显著提升了模型在训练和下游应用中的效率。实验结果表明,LMKE在多个知识嵌入评价基准上取得了超越现有方法的表现,尤其是针对长尾实体。研究成果《Language Models as Knowledge Embeddings》已被IJCAI 2022录用。
论文链接 https://www.ijcai.org/proceedings/2022/0318.pdf

一、背 景
知识图谱(Knowledge Graphs)以三元组的形式储存了大量的知识。其中,三元组(h,r,t)表示,头实体h与尾实体t间存在关系 r,如(法国,包含,卢浮宫)。
知识嵌入(Knowledge Embeddings, KEs)将知识图谱上的实体和关系嵌入到向量空间中进行表示,以便在向量空间中推理,用于三元组分类、链接预测等任务。比如说,TransE 将实体“法国”、“卢浮宫”和关系“包含”分别表示为向量“法国”、“卢浮宫”、“包含”,而如果“法国”+“包含”≈“卢浮宫”,则认为该三元组为真。近年来,知识嵌入也越来越多地被用于与预训练语言模型相结合,以赋予语言模型更多的知识。
现有的知识嵌入方法可以被大致分为两类:传统的基于结构的方法(Structure-based Methods)和近期兴起的基于文本的方法(Description-based Methods)。
基于结构的方法在向量空间中表达知识图谱的结构信息,包括 TransE、RotatE 等。这类方法可以建模多种特殊的关系模式,如对称模式、逆模式、组合模式等。比如,已知“A 的父亲是 B”,“B 的父亲是 C”,且“父亲的父亲是爷爷”,则这类方法可以推理出“A 的爷爷是 C”,如下图所示。

图1 知识图谱中的组合模式
然而,这类方法单纯依赖知识图谱的结构信息,因此自然难以良好地表示结构信息匮乏的长尾实体。在真实世界的知识图谱中,实体的度数分布服从power-law定律,形成一条长长的尾巴,意味着大量实体缺乏充足的结构信息。比如,下方左图展示了知识图谱数据集WN18RR中的实体度数分布,其中14.1%的实体度数为1,60.7%的实体度数不超过3,这意味着这些实体在知识图谱上连边极少。下方右图的结果则表明,以RotatE为代表的典型基于结构的方法在长尾实体上表现不佳。
 图2 WN18RR上的节点度数分布及基于结构的方法在该数据集上的表现
图2 WN18RR上的节点度数分布及基于结构的方法在该数据集上的表现
基于文本的方法引入了文本信息和语言模型进行知识的嵌入与推理,如 DKRL、KEPLER 等。许多知识图谱提供了实体和关系的文本描述,而这些丰富的文本信息可以良好地用于实体和关系的表示,并弥补结构信息的不足。同时,近期关于语言模型的相关研究表明:
①语言模型在预训练时不仅掌握了语言知识,还学会了大量事实知识[1]
②语言模型可以同基于结构的知识嵌入方法一样,掌握对称模式、逆模式、隐含模式等部分关系模式[2]。
因此,我们认为语言模型非常适合作为知识嵌入使用。
此前已有工作尝试将语言模型用于知识嵌入的三元组分类、链接预测任务上。然而,现存的基于文本的方法存在以下缺陷:
① 效率较低。语言模型规模庞大,因此现有工作在训练及下游任务中或是时间复杂度过高,或进行了大量的 trade-off。一方面,它们在训练时限制负采样率。比如基于文本的 KEPLER 中正样本和负样本的数量是 1:1 的,而基于结构的 TransE 中一个正样本会搭配上千个负样本。另一方面,现有方法的模型结构在链接预测等下游任务上复杂度也过高。
② 表现不佳。尽管引入了更多的信息与更大的模型,现存的基于文本的方法在许多数据集和指标上并未超越基于结构的方法,其中效率问题带来的负采样率不足等 trade-off 一定程度上造成了负面影响。
③ 限制性文本依赖。现存方法只适用于有文本描述的实体,而往往舍弃掉大量没有文本信息(但有结构信息)的实体。现存方法对数据的严苛要求限制了他们在下游任务中的使用。
[1] Petroni, Fabio, et al. "Language Models as Knowledge Bases?" Proceedings of EMNLP-IJCNLP 2019.
[2] Kassner, Nora, Benno Krojer, and Hinrich Schütze. "Are Pretrained Language Models Symbolic Reasoners over Knowledge?." Proceedings of CoNLL 2020.
二、方 法
在本文中,我们提出了一个更好地将语言模型用作知识嵌入的方法LMKE(Language Models as Knowledge Embeddings),同时利用结构信息和文本信息,在提升长尾实体表示的同时解决基于文本方法的上述问题。在 LMKE 中,实体和关系被视作额外的词(token),并从相关实体、关系和文本描述中学习表示。本文进一步提出将基于文本的知识嵌入学习建模在对比学习框架下,使得一个三元组里的实体表示可以作为同 batch 中其他三元组的负样本,从而避免了编码负样本带来的额外开销。LMKE 也是一种将知识图谱与语言模型结合的具体方式。
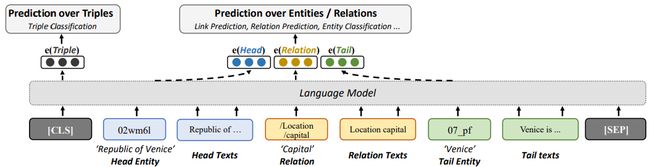
图3 LMKE的模型结构(用于三元组分类)
LMKE 用语言模型作为知识嵌入,即用语言模型获得实体和关系的嵌入向量表示,从而对三元组或实体进行预测。在 LMKE 中,实体和关系的嵌入向量与文本中的词被表示在同一个向量空间中。如图3所示,给定一个特定的三元组u=(h,r,t),LMKE 利用相应的文本描述信息 ,将它们拼为一个序列 。将该序列 作为语言模型的输入,h,r,t 的相应输出向量 h,r,t,即是相应的实体和关系的嵌入向量。一个实体(或关系)的嵌入向量同时依赖于其自身、其自身的文本描述、其相关实体和关系、以及相关实体和关系的文本描述,对文本信息进行了最大程度的利用。因此,长尾实体可以利用文本信息而被良好表示,而缺乏文本信息的实体则可以利用相关实体和关系(结构信息)以及它们的文本描述被良好表示。语言模型中的CLS token(或 BOS token)对应的向量聚合了整个序列的信息,因此我们将其视作代表整个三元组 u 的向量 u。与KG-BERT相似,LMKE 将向量 u 输入一个线性层,来计算三元组为真的概率 p(u): 知识嵌入的主要应用是预测缺失的链接(链接预测)和对可能的三元组进行分类(三元组分类)。其中,三元组分类基于上述 p(u) 即可进行。链接预测则需要预测出不完整三元组(?,r,t)或(h,r,?)的缺失实体。具体来说,模型需要将候选实体(一般为所有实体)填入不完整三元组,并将相应的三元组进行打分,从而对候选实体按照得分进行排序。然而,对于上述 LMKE 模型,以及大部分现有的基于文本的方法,这一流程的计算时间复杂度都过高,如表1所示。

表1 部分基于文本的方法在训练和链接预测上的时间复杂度
为了将语言模型高效地用于链接预测任务,一个简单的方法是不完整地编码三元组,而仅编码部分三元组。实体遮盖模型(MEM-KGC)可以视为 LMKE 的 masked变体,将待预测的缺失实体和其文本描述 mask,并将相应的向量表示 q 输入一个线性层来预测缺失实体。因为仅需要编码一个不完整的三元组,MEM-KGC显著降低了时间复杂度。然而,MEM-KGC 忽视了待预测实体的文本信息,降低了文本信息的利用率。
我们提出了一个对比学习框架来更充分地利用文本信息。在我们的对比学习框架中,给定的实体关系对被视作查询q,而目标实体被视作键 k,我们通过匹配q和k进行对比学习。在这一框架的视角下,MEM-KGC 中的向量q即为查询的向量表示,而MEM-KGC的线性层权重 的每一行则是每一个实体作为键的向量表示。因此,将q输入到线性层即为查询q匹配键。差别在于,MEM-KGC的键是用可学习的向量表示,而非像查询一样是文本信息的语言模型编码。我们提出的对比学习框架也使得语言模型能够被高效地用于链接预测。
C-LMKE是对比学习框架下的LMKE变体,将MEM-KGC中的可学习实体权重改进为目标实体的文本描述编码,如图4所示。C-LMKE进行批次内的对比匹配,从而避免了编码负样本带来的额外开销。具体来说,对于 batch 中的第i个三元组,它的给定实体关系对q和目标实体k构成一个正样本,而同batch内其他三元组的目标实体k’与q构成负样本。由表1可见,C-LMKE在训练和链接预测时的时间复杂度均显著优于现有基于文本的方法。

图4 C-LMKE的模型结构(用于链接预测)
不同于一般的对比学习方法,C-LMKE采用一个双层MLP而非余弦相似度来计算 q 和 k 的匹配度。假设查询 q=(法国,包含)同时与 =(卢浮宫)和 =(巴黎)匹配,则基于相似度的得分会迫使 和 的表示相似,这在知识嵌入的场合是不被期望的。同时,我们还发现,引入度数信息 和 (相应实体在训练集中的三元组个数)对于链接预测任务相当有帮助。
基于得分 p(q, k),我们使用二元交叉熵作为损失函数进行训练,并参考RotatE 中提出的自对抗负采样来提高难负样本的损失权重。
三、实验结果

表2 FB15k-237及WN18RR上的链接预测结果
我们在链接预测和三元组分类两个任务上对我们的方法进行了实验,以BERT-tiny和BERT-base作为基本模型。在链接预测上,我们的模型显著超越了现有模型。使用BERT-BASE的C-LMKE在WN18RR上取得了 80.6% 的 Hits@10,而此前最好的结果仅为70.4%。即使我们使用 BERT-tiny 作为语言模型,我们的方法取得的表现也优于或相当于使用更大模型的现有方法。同时,使用BERT-tiny的C-LMKE在FB15k-237上取得了57.1%的Hits@10,是首个超越基于结构方法的基于文本方法。
一个有趣的现象是,基于文本的方法在WN18RR上显著超越基于结构的方法,但在FB15k-237上却不然。我们认为背后的原因是数据集的差异。WN18RR来源于字典知识图谱WordNet,其中的实体是词而文本描述是词的定义,而从词的定义中可以很容易推出词之间的关系。相对地,FB15k-237来源于真实知识图谱Freebase,其中的文本仅部分地描述了一个实体最广为人知的知识,比如(爱因斯坦,是,和平主义者)这一知识就不被它们的文本描述所涵盖。因此,过度依赖于文本而非结构信息可能导致模型表现不佳。这也解释了在该数据集上使用BERT-tiny替换 BERT-base后表现没有下降。

表3 FB13和UMLS上的三元组分类结
LMKE 在三元组分类任务上也取得了最优的表现。其中,LMKE和KG-BERT的差距代表了引入实体和关系作为特殊词的有效性。

图5 不同模型对于FB15k-237中包含不同度数实体的三元组的平均表现
为了展示我们的方法在长尾实体表示上的有效性,我们将实体按度数的对数进行分组,统计包含不同度数实体的三元组,并研究包含不同度数实体的三元组上的表现。实验结果表明,基于文本的方法在低度数组 0,1,2(即包含度数低于 4 的实体的三元组)上的表现显著优于基于结构的方法,而C-LMKE又显著优于其他的基于文本的方法。同时,在加入了度数信息后,C-LMKE在中高度数组上的表现有了显著提升。
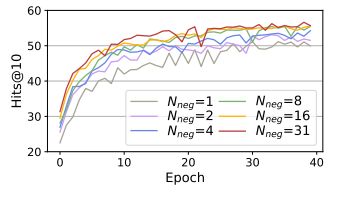
图6 不同负采样率下C-LMKE在FB15k-237上的表现
我们进一步研究了负采样率对基于文本的知识嵌入学习的影响。我们将batch size 设为32,因此 1 个正样本最多配有31个负样本,而我们进一步限制可见负样本数为{1, 2, 4, 8, 16}。实验结果表明,更大的负采样率能显著提升模型的表现,证明了负采样率对基于文本的方法的重要性。然而,现有基于文本方法受限于负样本编码代价,一般仅使用1个或5个负样本。
总结起来,我们的贡献主要有以下三点:
① 我们注意到基于结构的知识嵌入在表示长尾实体上的不足,并首次提出利用文本信息和语言模型来提升长尾实体的表示。
② 我们提出了一个基于文本的新模型LMKE,解决了现有基于文本方法的三个不足之处。同时,我们也首次提出将基于文本的知识嵌入学习建模为对比学习问题。
③ 我们在多个知识嵌入数据集上进行了广泛实验,实验结果表明LMKE 在三元组分类和链接预测任务上取得了state-of-the-art 的表现,显著超越现有知识嵌入方法,使得基于文本的方法首次在数据集FB15K-237 上超越基于结构的方法。
笔者认为,LMKE提出的对比学习框架将是基于文本的知识嵌入的发展方向。在这一方向上,我们仍可参考对比学习领域的优秀方法来取得进一步提升。同时,信息检索、实体链接在本质上也是链接预测任务,近年来也越来越多地采用了对比学习,我们也可以从这些领域的工作中吸取经验。
最后,我们注意到被 ACL 2022 接收的同期工作SimKGC同样提出了基于文本的知识嵌入的对比学习框架,在 WN18RR 上取得了与我们相当的表现,并研究了负采样对于基于文本方法的重要性。这进一步说明了对比学习框架在基于文本的知识嵌入的发展上的必然性。SimKGC相较于LMKE,使用了更庞大的算力(32 倍的 batch size)、余弦相似度度量、InfoNCE损失以及基于图的Reranking策略,产出了值得我们借鉴的结果,不过他们在事实知识图谱FB15k-237上的表现仍未超越基于结构的方法。LMKE相较于SimKGC,则还关注了长尾实体表示、三元组分类任务以及度信息的重要性。
![]()
论文&文稿作者

责任编辑:郭放 图文编辑:王文
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~