微服务架构基础
微服务架构基础
- 1.摘要
- 2.书本导读
- 3.认识微服务架构
-
- 3.1架构的演进
-
- 3.1.1单体应用
- 3.1.2水平扩展
- 3.1.3SOA架构
- 3.2微服务架构概述
- 3.3微服务架构的组件和技术选型
- 4.Spring Cloud
-
- 4.1概述
- 4.2搭建Spring Cloud根模块
- 4.3服务治理
- 4.4负载均衡
- 4.5服务容错保护
- 4.6API网关
- 4.7分布式配置管理
- 4.8声明式服务调用:Spring Cloud Feign
- 4.9消息中心:Spring Cloud Bus
- 4.10消息驱动的微服务:Spring Cloud Stream
- 4.11分布式服务跟踪:Spring Cloud Sleuth
1.摘要
本篇博客参考了《微服务架构基础》和《Spring Cloud 微服务实战》,对微服务架构和Spring Cloud基础进行总结,以便加深理解和记忆。
2.书本导读
- 《微服务架构基础》
《微服务架构基础》是由“黑马程序员”于2018年出版的微服务架构教材,主要包括springboot、springcloud和docker等内容。此书更注重于基本概念和实践,由于其简单性和内容不多,可以帮助初学者快速入门并上手微服务架构项目。
阅读该书需要一定的Spring基础,预计7-14天可以读完。对于关于微服务等相关知识还需要阅读更详细、更新的文档或教程。

- 《Spring Cloud 微服务实战》
对Spring Cloud 的思想、工作流程、使用进行了较为全面的讲解,前几章还对源码进行了一定程度的分析。书本内容较多,没有读完。所用版本较久,和最新版本不太兼容。

3.认识微服务架构
3.1架构的演进
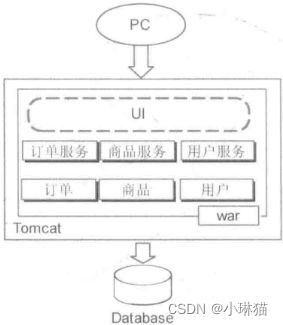
3.1.1单体应用
1)一个归档包对应整个应用系统,应用的格式依赖于相应的语言和框架。
2)优点:易于开发、调试和部署,在用户量不多时,此架构可以完全满足需求。
3)缺点:用户数量增多时,一台机器已经满足不了负载。
3.1.2水平扩展
1)增加服务器的数量,并将归档包运行于不同的服务器上,并通过负载均衡器(如Apache、Nginx)实现单体应用的水平扩展
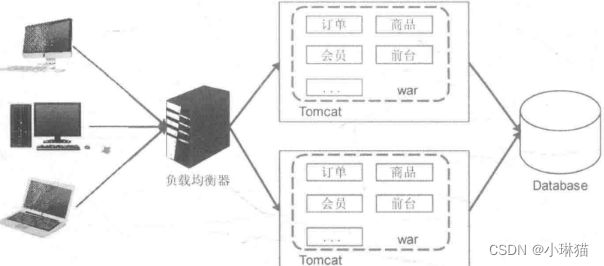
2)早期,单体应用的水平扩展可以满足需求,但随着时间推移会产生如下许多问题:
| 问题 | 解释 |
|---|---|
| 应用复杂度增加,更新、维护困难 | 应用逐渐变得庞大而复杂,难以进行二次开发和维护 |
| 易造成系统资源的浪费 | 水平扩展会将应用的所有模型复制到各个机器,但是不同模块的访问量是不同的,将低频模块以与高频模块同等对待会浪费系统资源 |
| 影响开发效率 | 单体应用太过庞大导致启动时间过长,在开发和调试过程中浪费时间 |
| 应用可靠性低 | 所有模块运行在同一进程中,任何模块出错导致系统崩溃,会影响到整个应用 |
| 不利于技术更新 | 单体架构整个系统都使用特定的某些技术,后期的维护和扩展都依赖于这些技术。一旦想要更改某种技术,整个应用则需要重新开发,成本太大 |
水平扩展弥补了单体应用负载不足的问题,但没有解决其根本问题。这些原因的根本在于:一个归档包包含了整个系统的全部服务。
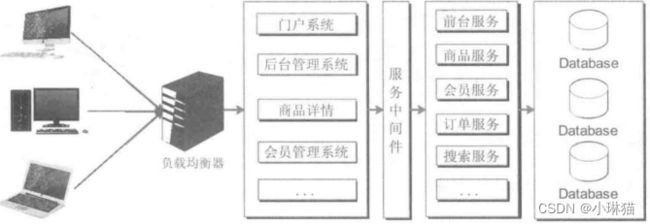
3.1.3SOA架构
1)SOA(Service-Oriented Architecture)面向服务的架构
①服务部分:将应用中相近的功能聚合在一起,以服务的形式提供出去(SOA可以看作一批服务的组合)
②服务消费者部分:将原来的单体架构按功能细分为不同的子系统,由各个子系统依赖的中间件(企业服务总线Enterprise Service Bus,ESB)调用所需的服务
2)优点
| 优点 |
|---|
| 将项目拆分成多个子项目,不同团队负责不同子项目,提高开发效率 |
| 把模块拆分,使用接口通信,降低模块间的耦合度 |
| 为企业的现有资源带来了更好的重用 |
| 能够在最新和现有的应用之上创建应用 |
| 能够使客户或服务消费者免予服务实现的改变所带来的影响 |
| 能够升级单个服务或服务消费者而无需重写整个应用,也无需保留已经不再适用于新需求的现有系统 |
3)问题
尽管SOA解决了单体架构,系统的全部模块集中的问题,但多数情况下,SOA中相互独立的服务仍然会运行在一个容器中。和单体架构类似,随着业务功能的增多,SOA的服务会变得越来越复杂。本质上来看,单体架构的问题并没有因为SOA变得更好。
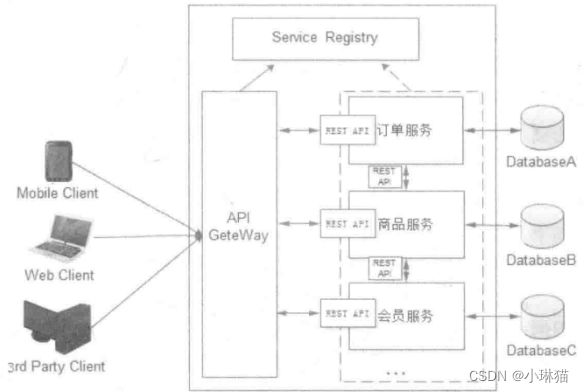
3.2微服务架构概述
针对单体架构和SOA的问题,许多公司通过采用微处理结构模式解决了系统架构的问题,思路是将应用分解为小的、互相连接的微服务,微服务架构思想随之产生。
1)微服务架构的概念
①微服务:指提供独立服务的实体(也可强调服务的大小,关注的是独立服务的规模)
②微服务架构:微服务架构是一种架构风格和架构思想,它将传统的单体应用按照业务功能拆分为更细粒度的服务,所拆分的每一个服务都是一个独立/职责单一的应用,这些应用对外提供公共API,各个服务构成分布式的网络结构(从系统全局考虑)
围绕着微服务思想构建的软件体系结构(包括开发、测试、部署等)就可称为“微服务架构”
2)构建微服务架构的目的:有效拆分应用,实现敏捷开发和部署
3)优点
| 优点 | 解释 |
|---|---|
| 复杂度可控 | 避免了单体应用扩展时复杂度无休止的积累,每个微服务专注于单一功能,并通过良好的接口描述服务边界。由于体积小、复杂度低,每个微服务可由一个小规模开发团队完全掌握,开发效率高,可维护性高 |
| 可独立部署 | 每个微服务是独立的应用,可独立部署。当某个微服务发生变更时,无需编译、部署整个系统。由微服务组成的应用相当于具备一系列可并行的发布流程,使得发布更加高效,同时降低了对生产环境造成的风险,最终缩短应用交付周期 |
| 技术选型灵活 | 各个微服务可根据自身的需求和行业发展现状,选择最适合的技术。由于每个微服务相对简单,当需要对技术进行升级时,所面临的风险较低,甚至完全重构一个微服务也是可行的 |
| 易于容错 | 单体架构中的某一模块发生故障时,故障可能在进程内扩散导致整个应用不可用。微服务架构下的故障会被单独隔离在单个服务中,若设计良好,其余服务也可以通过重试、平稳退化等机制实现应用层面的容错 |
| 易于扩展 | 每个独立的微服务实体也可以水平扩展,相比于单体应用一次复制一个应用的水平扩展,微服务架构可以根据不同微服务实体的特点灵活地进行水平扩展,避免资源的浪费 |
| 功能单一 | 每个微服务都有自己的业务逻辑和适配器,职责单一,开发人员可以完全专注于一个特定功能的开发,开发难度降低,开发效率提高 |
4)不足
| 不足 | 解释 |
|---|---|
| 引入了分布式系统的复杂性 | a.开发工具是面向传统单体应用设计的,不为开发分布式应用提供全面的支持 b.必须实现服务间的通信 c.实现用例横跨多个服务时,需要处理分布式事务管理的困难 d.实现跨多个服务的用例时,需要团队间仔细的配合 e.测试更加困难 f.部署的复杂性 |
| 增加内存开销 | 每个服务都运行在自己的JVM中,有多少个服务实例,就有多少个实例运行时的内存开销 |
5)微服务架构的要求
①根据业务模块划分服务种类
②每个服务可独立部署且相互隔离
③通过轻量级API调用服务
④服务需保证良好的高可用性
6)如何拆分服务
①通过业务功能分解并定义与业务功能相应的服务
②将域驱动设计分解为多个子域
③按照动词/用例分解,并定义负责特定操作的服务,如一个负责完成订单的航运服务
④通过定义一个给定类型的实体的所有负责的操作作为一个服务,如一个负责管理用户账户的服务
7)微服务架构和SOA架构的区别
| 微服务架构 | SOA |
|---|---|
| 一个系统拆分成多个服务,粒度细 | 服务由多个子系统组成,粒度粗 |
| 团队级,自底向上开展实施 | 企业级,自顶向下开展实施 |
| 无集中总线式,松散的服务架构 | 企业服务总线,集中式的服务架构 |
| 集成方式简单(HTTP/REST/JSON) | 集成方式复杂(ESB/WS/SOAP) |
| 服务能独立部署 | 服务相互依赖,无法独立部署 |
3.3微服务架构的组件和技术选型
1)微服务架构的组件
| 组件 | 功能 |
|---|---|
| 服务注册中心 | 注册系统中所有服务的地方 |
| 服务客户端 | 进行服务注册,暴露出自己的服务;进行服务发现,调用其他服务 |
| 负载均衡 | 服务提供方一般以多实例的形式提供服务,负载均衡能让服务调用方连接到合适的服务节点 |
| 服务容错 | 通过熔断器(断路器)等一系列的服务保护机制,保证服务调用者在调用异常服务时能快速地返回结果,避免大量的等待同步 |
| 服务网关 | API网关,是服务调用的唯一入口,可以在该组件中实现用户鉴权、动态路由、灰度发布、负载限流等功能 |
| 分布式配置中心 | 将本地化的配置信息注册到配置中心以实现归档包在开发、测试、生产环境的无差异性,方便归档包的迁移 |
| 其他微服务架构组件 | 健康检测、日志处理… |
2)微服务架构的技术选型
| 组件 | 技术选型 |
|---|---|
| 微服务实例的开发 | Spring Boot、WildFly Swarm、KumuluzEE |
| 服务的注册与发现 | Spring Cloud Eureka、Apache Zookeeper、Consul、Etcd、Dubbo |
| 负载均衡 | Spring Cloud Ribbon、Dubbo |
| 服务容错 | Hystrix(Spring Cloud Hystrix) |
| API网关 | Spring Cloud Zuul、Spring Reactor、Netty、NodeJS |
| 分布式配置中心 | Spring Cloud Config |
| 部署 | Docker |
| 持续集成&自动化部署 | Jenkins |
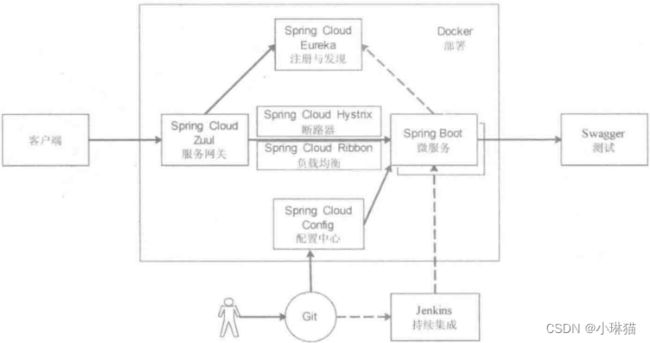
4.Spring Cloud
有关本篇博客介绍的Spring Cloud的项目代码,可在我的开源项目中获取。
4.1概述
1)简介
Spring Cloud是在Spring Boot的基础上构建的,用于简化分布式系统构建的工具集。该工具集为微服务架构中涉及的配置管理、服务发现、智能路由、熔断器和控制总线等操作提供了一种简单的开发方式。
2)组成
①Spring Cloud Netflix:集成了各种OSS组件,包括Eureka、Ribbon、Hystrix、Zuul、Feign和Archaius等
②Spring Cloud Config:配置管理工具,支持使用Git存储配置内容,能够实现应用配置的外部化存储,支持客户端配置信息刷新、加密和解密等配置内容
③Spring Cloud Starters:Spring Cloud的基础组件,是基于Spring Boot风格项目的基础依赖模块
除此之外,其子项目还包括:Spring Cloud Bus、Spring Cloud Consul和Spring Cloud CLI等
3)特点
①集成了许多开源框架,生态好
②使用方便,不需要过多的配置,上手容易
③功能齐全,覆盖了微服务架构的方方面面
④依赖引入方便,都是通过Maven或Gradle引入
⑤适用各种环境,包括PC服务器、云环境和各种容器(如Docker)
4)版本
不同于3段数字区分版本号,Spring Cloud是根据英文字母的顺序,按照伦敦的“地名+版本号”,如Angel SR6,SR是Service Relaeases的缩写。
4.2搭建Spring Cloud根模块
创建Maven项目,删除根模块的src目录,并在根模块的pom.xml中加入依赖,这里需要注意的是spring-boot-starter-parent的版本要与spring-cloud-dependencies相对应。
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.5.6.RELEASEversion>
<relativePath/>
parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>Dalston.SR3version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
4.3服务治理
在微服务架构中,服务治理是最核心和最基础的模块,该模块主要用于各个微服务实例的自动化注册与发现。在Spring Cloud的子项目中,Spring Cloud Netflix提供了Eureka来实现服务发现
1)Eureka简介
Eureka是Netflix开发的一个服务发现框架,基于REST服务,主要用在AWS的中间层服务,以达到负载均衡和中间层服务故障转移的目的。Spring Cloud将其集成在自己的子项目Spring Cloud Netflix中,以实现服务发现功能。
2)服务治理机制
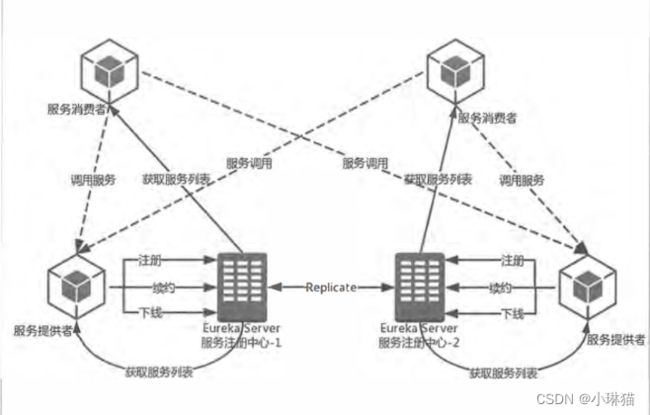
- 两个服务注册中心相互注册形成注册中心集群
- 同一服务提供者的两个实例分别注册到两个注册中心上
- 两个服务消费者分别指向一个注册中心上
①服务注册者:
- 服务注册
服务注册者启动 (注意指明注册中心url并开启eureka.client.register-with-eureka=ture)→ 发送REST请求将自己注册到注册中心 → 注册中心接收到请求,将服务注册者的元数据存储在一个双层Map中(第一层key是服务名,第二层key是服务实例名)
- 服务同步
尽管服务提供者仅注册到注册中心集群中的某一实例上,但注册中心集群中的注册中心实例会转发请求到其他注册中心,从而实现服务同步。
- 服务续约
注册完成之后,服务注册者会每隔一段时间向注册中心发送一个心跳进行服务续约,若在服务失效时间外,注册中心仍没收到服务注册者的心跳,则会将其剔除。
②服务消费者
- 获取服务
服务消费者启动(保证eureka.client.fetch-registry=ture开启) → 向注册中心发起REST请求获取服务 → 注册中心将一份只读的服务清单返回给服务客户端,该缓存的服务清单默认每30s更新一次
- 服务调用
由于服务调用方本地拥有服务清单的缓存,就可以通过服务的实例名/ip调用服务。
对于访问实例的选择,一个Region中有多个Zone,每个服务客户端需要被注册到一个Zone中,因而每个服务客户端对应到一个Region和Zone,服务调用时,会优先调用同一个Zone的服务提供方
-
服务下线
服务在正常关闭时 → 会向注册中心发起一个REST请求 → 注册中心会将该服务的状态设置为DOWN下线,并将该事件传播出去
③服务注册中心
- 失效剔除
注册中心启动 → 启动定时任务 → 每个服务失效时间内若未收到服务提供方的心跳则将其剔除
- 自我保护
注册中心在运行期间会统计心跳失败的比例在15分钟内是否例低于85%,若低于,则会将当前的服务注册信息保护起来,让这些实例不会过期(本地条件下很容易满足)
3)高可用注册中心
高可用对应着节点发生故障时仍不会导致整个系统的瘫痪。在微服务架构基础中使用的注册中心为单注册中心,若该注册中心无法工作,则会导致服务注册和发现的功能都不能工作,从而导致系统不可用。为了避免这一问题,就要构建高可用的注册中心,具体的做法是:添加注册中心的个数(这时每个注册中心节点可称为分片replicas),这样以来,即便一个注册中心无法工作,其余注册中心仍能运行。
更具体的是,将注册中心也作为服务注册进其他注册中心,这样就可以形成一组相互注册的服务注册中心(注册中心集群),以实现服务清单的相互同步,达到高可用的效果。
Eureka以集群模式部署,当集群中分片出现故障时,那么Eureka就转入自我保护模式,允许分片在故障期间继续提供服务的发现和注册,当故障分片恢复时,集群中其他分片会把他们的状态再次同步回来。以在AWS上的实践为例,Netflix推荐每个可用的区域运行在一个Eureka服务端,通过它来形成集群。不同可用区域的服务注册中心通过异步模式相互复制各自的状态,这意味着在任意给定的时间点每个实例关于所有服务的状态是有细微差别的。
# 创建双节点的服务注册中心,令他们的服务地址相互指向
# eureka server 1
spring:
application:
name: eureka-server
server:
port:
1111
eureka:
instance: server1
# 2.若通过地址的方式注册入其他注册中心,则需要开启该选项,默认为关闭
prefer-ip-address: true
client:
serviceUrl:
# 1.通过实例名的方式注册
defaultZone: http://server2:1112/eureka/
# 2.通过地址的方式注册
defaultZone: http://localhost:1112/eureka/
# eureka server 2
spring:
application:
name: eureka-server # 注意两个注册中心节点的应用名称相同
server:
port:
1112
eureka:
instance: server2
# 2.若通过地址的方式注册入其他注册中心,则需要开启该选项,默认为关闭
prefer-ip-address: true
client:
serviceUrl:
# 1.通过实例名的方式注册
defaultZone: http://server1:1111/eureka/
# 2.通过地址的方式注册
defaultZone: http://localhost:1111/eureka/
# 使用上述服务名称注册的方式需要在Windows的C:\Windows\System32\drivers\etc\hosts中增加服务名与ip的映射
127.0.0.1 server1
127.0.0.1 server2
在将注册中心的不同实例相互注册后,在服务客户端还需指定多个注册中心
eureka:
client:
serviceUrl:
defaultZone: http://server1:1111/eureka,http://server2:1112/eureka
4)配置详解
①服务注册中心配置
Eureka服务端更多地类似于一个现成产品,大多情况下无需进行配置,其配置参数均以eureka.server为前缀,具体可以查看org.springframework.cloud.netflix.eureka.server.EurekaServerConfigBean配置类查看
②服务客户端配置
spring:
application:
name: eureka-client-article
eureka:
# 服务注册类配置:服务注册的相关信息
# 具体涉及的配置类为:org.springframework.cloud.netflix.eureka.EurekaClientConfigBean
client:
# 指定注册中心
serviceUrl:
# 单个注册中心,通过ip地址
#defaultZone: http://{ip}:{port}/eureka/
# 多个注册中心,通过ip地址,用逗号隔开
defaultZone:
- http://localhost:8001/eureka/
- http://localhost:8002/eureka/
# 单个注册中心,通过注册中心实例名
# defaultZone: http://{serverName}:{port}/eureka/
# 多个注册中心,通过注册中心实例名,用逗号隔开
# defaultZone: http://{serverName}:{port}/eureka/,http://{serverName}:{port}/eureka/
# 带账号密码的安全校验
# http://{username}:{password}@{ip}:{port}/eureka
# 自定义region
region: JiLin
# 自定义zone
availability-zones: 1
# 是否要将自身的实例信息 注册到Eureka服务端
registerWithEureka: true
# 是否从Eureka服务端获取注册信息
fetchRegistry: true
# 健康检测:尽管eureka通过心跳来判断某个服务是否运转,但默认情况下,它只是检测该服务的进程是否运行,由于各种原因,可能会出现进程运行,
# 但服务无法提供服务的情况.这时需要把Eureka客户端的健康检测交给actuator通过/health端口判断服务是否正常提供服务,以实现更加全面的健康状态维护
health-check:
enabled: true
# 是否启用eureka客户端
enable: true
# 从注册中心获取服务清单的时间间隔(以下时间间隔单位均为秒)
registryFetchIntervalSeconds: 30
# 更新实例信息的变化到Eureka服务端的时间间隔
instanceInfoReplicationIntervalSeconds: 30
# 初始化实例信息到Eureka服务端的时间间隔
initialInstanceInfoReplicationIntervalSeconds: 40
# 轮询Eureka服务端地址更改的间隔时间
# 当我们与Spring Cloud Config配合,动态刷新Eureka的serv1ceURL地址时需要关注该参数
eurekaServiceUrlPollIntervalSeconds: 300
# 读取Eureka Server信息的超时时间
eurekaServerReadTimeoutSeconds: 8
# 连接 Eureka Server的超时时间
eurekaServerConnectTimeoutSeconds: 5
# 从Eureka客户端到所有Eureka服务端的连接总数
eurekaServerTotalConnections: 200
# 从Eureka客户端到每个Eureka服务端主机的连接总数
eurekaServerTotalConnectionsPerHost: 50
# Eureka服务端连接的空闲关闭时间
eurekaConnectionIdleTimeoutSeconds: 30
# 心跳连接池的初始化线程数
heartbeatExecutorThreadPoolSize: 2
# 心跳超时重试延迟时间的最大乘数值
heartbeatExecutorExponentialBackOffBound: 10
# 缓存刷新线程池的初始化线程数
cacheRefreshExecutorThreadPoolSize: 2
# 缓存刷新重试延迟时间的最大乘数值
cacheRefreshExecutorExponentialBackOffBound: 10
# 使用DNS来获取Eureka服务端的serviceUri
useDnsForFetchingServiceUrls: false
# 是否偏好使用处于相同Zone的Eureka服务端
preferSameZoneEureka: true
# 获取实例时是否过滤, 仅保留UP状态的实例
filterOnlyUpInstances: true
# 服务实例类配置
# 具体涉及的配置类为:org.springframework.cloud.netflix.eureka.EurekaInstanceConfigBean
# 实例配置时大多数配置是对服务实例元数据的配置,实例配置类涉会被包装成元数据配置类:com.netflix.appinfo.InstanceInfo
instance:
# 服务名,默认取spring.applcation.name的配置值,如果没有则为unknown
# appname:
# 主机名, 不配置的时候将根据操作系统的主机名来获取
# hostname:
# 实例名配置,它是每个服务中一个实例的唯一标识.
# 在NetflixEureka的原生实现中,实例名采用主机名作为默认值,这样的设置使得在同一主机上无法启动多个相同的服务实例
# 所以,Spring Cloud Eureka针对同一主机中启动多实例的情况,对实例名的默认命名做了更为合理的扩展,采用如下默认规则:
# ${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance—id}:{server.port}
# 仅通过server.port设置同一服务不同实例的端口号不同,会导致这些实例的实例名相同,因而仍需instanceId解决
instanceId: ${spring.application.name}:${random.int}
# 是否优先使用IP地址作为主机名的标识,设置为true则可使用ip注册到服务端
preferIpAddress: false
# Eureka客户端向服务端发送心跳的时间间隔
leaseRenewalIntervalInSeconds: 30
# 服务失效时间
leaseExpirationDurationInSeconds: 90
# 端点配置:默认情况下statusPageUrl、healthCheckUrl对应actuator中的/info和/health端口
# 若actuator模块增加了一个前缀,则需要校对端点配置,如:management.context-path=/hello
# statusPageUrlPath: ${management.context-path}/info
# healthCheckUrlPath: ${management.context-path}/health
# 有时也会出于安全等动机修改原始端点,如:endpoints.info.path=/appInfo、endpoints.health.path=/checkHealth
# statusPageUrlPath: /${endpoints.info.path}
# healthCheckUrlPath: /${endpoints.health.path}
# Eureka的服务注册中心默认会以HTTP的方式来访问和暴露这些端点,这时端点配置采用相对路径的方式
# 因此当客户端应用以HTTPS的方式来 暴露服务和监控端点时,相对路径的配置方式就无法满足需求了,因此需要配置绝对路径
# statusPageUrl: https://${eureka.instance.hostname}/info # 状态页的 URL
# healthCheckUrl: https://${eureka.instance.hostname}/health # 健康检查的 URL
# homePageUrl: https://${eureka.instance.hostname}/ # 应用主页的 URL
# 以下配置不太需要修改
# 自定义元数据
# metadata:
# {selfKey}: {selfValue}
# 非安全的通信端口号
nonSecurePort: 80
# 安全的通信端口号
securePort: 443
# 是否启用非安全的通信端口号
nonSecurePortEnabled: true
# 是否启用安全的通信端口号
# securePortEnabled:
5)示例
- 搭建服务注册中心(服务发现服务端)
①在Spring Cloud根模块下,创建子模块,并引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eureka-serverartifactId>
dependency>
dependencies>
②编写配置文件
server:
# 所有服务实例都要向此端口号注册
port: 8761
eureka:
instance:
# 实例名
hostname: localhost
client:
# 注册中心,不需要向自己进行注册和发现服务,故下面两个配置为false
register-with-eureka: false
fetch-registry: false
# 注册中心的地址
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
③编写启动类
@SpringBootApplication
@EnableEurekaServer // 声明这是一Eureka服务注册中心
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
④测试
浏览器输入:http://localhost:8761/ 进入服务注册中心的管理页面
- 搭建服务客户端
①搭建order服务模块,在根模块下新建子模块,引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eurekaartifactId>
dependency>
dependencies>
②编写配置文件
server:
port: 7900
eureka:
instance:
# 是否显示主机IP,显示后当服务节点连接到注册中心鼠标放置其上会显示IP:端口号(默认为机器名:服务名:端口号)
prefer-ip-address: true
client:
service-url:
# 指定服务中心地址
defaultZone: http://localhost:8761/eureka/
spring:
application:
# 指定应用名称
name: microservice-eureka-order
③编写启动类
@SpringBootApplication
@EnableEurekaClient // 加入Eureka客户端注解,以此来注册服务
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
④编写接口,模拟业务
@RestController
@RequestMapping("/order")
public class OrderController {
/**
* @description: 通过订单ID查询订单
* @param orderId
* @return
*/
@GetMapping("getOrderById/{orderId}")
public OrderEntity queryOrderByUserId(@PathVariable Long orderId){
// pretend to get order by orderId
return new OrderEntity(1L,new BigDecimal("0.99"));
}
}
- 服务之间的调用
①搭建用户服务模块,用用户服务模块来调用订单服务模块中的接口
在根目录下创建user模块,user模块和order模块的依赖和配置信息相同(只需更换端口名和服务名)
②在user服务模块的启动类注入RestTemplate(也可通过其他方法注入)
@EnableEurekaClient
@SpringBootApplication
public class Application {
/**
* @description: RestTemplate是Spring提供的用于访问Rest服务的客户端实例,提供了多种便携的远程http调用方法
* @return
*/
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
③编写user调用order服务的接口
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private RestTemplate restTemplate;
/**
* @description: 通过用户ID查询其下的订单
* @param userId
* @return
*/
@GetMapping("queryOrderByUserId/{userId}")
public OrderEntity queryOrderByUserId(@PathVariable Long userId){
// pretend to get orders' ID by userId
long orderId = 1L;
String orderServiceAddress = "http://localhost:7900/order/getOrderById/" + orderId;
return restTemplate.getForObject(orderServiceAddress,OrderEntity.class);
// restTemplate.exchange方法用于返回某一类型的集合,restTemplate.exchange(URL,HttpMethod.GET,null(传入参数),new ParameterizedTypeReference>(){});
}
}
4.4负载均衡
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,基于Netflix Ribbon实现,经过了Spring Cloud的封装,可以将面向服务的REST模板请求自动转为客户端负载均衡的服务调用。它只是一个工具类框架,不像其他组件一样需要独立部署,但几乎存在于每一个微服务组件中,因为服务间的调用、API网关的请求转发都是基于Ribbon实现的。
1)负载均衡
服务端负载均衡(硬件负载均衡、软件负载均衡);客户端负载均衡:其区别在于服务清单的存储位置及由谁进行转发选择
原理:负载均衡组件(客户端/服务端)通过心跳维持服务清单,接收到请求时(客户端发起请求被负载均衡器拦截),通过负载均衡算法(线性轮询、按权重负载、按流量负载等)选出一个服务进行转发
2)Spring Cloud Ribbon使用
①将服务实例与注册中心[集群]关联
②服务消费者通过被@LoadBalanced注解修饰过的RestT。emplate来调用服务提供方接口
3)RestTemplate
RestTemplate对象是Spring封装的Rest请求模板
RestTemplate restTemplate = new RestTemplate();
/** GET请求 **/
/* getForEntity */
/*
ResponseEntity是Spring对HTTP请求响应的封装,主要包括:
HTTP返回状态的枚举对象HttpStatus;
请求头对象HttpHeaders;
泛型返回对象body
*/
ResponseEntity<T> responseEntity = restTemplate.getForEntity(String url,Class responseType, Object...params);
ResponseEntity<T> responseEntity = restTemplate.getForEntity(String url,Class responseType, Map params);
ResponseEntity<T> responseEntity = restTemplate.getForEntity(URI url,Class responseType);
// e.g.1.占位符拼接,或直接拼接
ResponseEntity<User> responseEntity = restTemplate.getForEntity("http://USER-SERVICE/user?name={1}",User.class,"LinCat");
// e.g.2.字典参数拼接
Map<String,String> params = new HashMap<>();
params.put("name","LinCat");
ResponseEntity<User> responseEntity = restTemplate.getForEntity("http://USER-SERVICE/user?name={name}",User.class,params);
// e.g.3 构造URI(统一资源标识符)
UriComponents uriComponents = UriComponensBuilder.fromUriString("http://USER-SERVICE/user?name={name}")
.build()
.expand("LinCat")
.encode();
Uri uri = UriComponent.toUri();
ResponseEntity<User> responseEntity = restTemplate.getForEntity(uri,User.class).getBody();
/* getForObject:可理解为对getForEntity的进一步封装,通过HttpMessageConverterExtractor对HTTP请求响应体body内容进行对象转换,实现直接返回包装好的对象 */
Class result = restTemplate.getForObject(String url,Class responseType, Object...params);
Class result = restTemplate.getForObject(String url,Class responseType, Map params);
Class result = restTemplate.getForObject(URI url,Class responseType);
// e.g.3
User user = restTemplate.getForObject(uri,User.class);
/** POST请求 **/
/* postForEntity:request会被当做完整的body处理 */
ResponseEntity<T> responseEntity = restTemplate.postForEntity(String url,Object request,Class responseType,Object...params);
ResponseEntity<T> responseEntity = restTemplate.postForEntity(String url,Object request,Class responseType,Map params);
ResponseEntity<T> responseEntity = restTemplate.postForEntity(URI url,Object request,Class responseType);
/* postForObject */
Class result = postForObject(String url,Object request,Class responseType,Object...params);
Class result = postForObject(String url,Object request,Class responseType,Map params);
Class result = postForObject(URI uri,Object request,Class responseType);
/* postForLocation:以post提交资源并返回资源的URI */
URI uri = restTemplate.postForLocation(String url,Object request,Object...params);
URI uri = restTemplate.postForLocation(String url,Object request,Map params);
URI uri = restTemplate.postForLocation(URI uri,Object request);
/* PUT请求:无返回值 */
restTemplate.put(String url,Object request,Object...params);
restTemplate.put(String url,Object request,Map params);
restTemplate.put(URI uri,Object request);
/* DELETE请求:无返回值 */
restTemplate.delete(String url,Object... params);
restTemplate.delete(String url,Map params);
restTemplate.delete(URI uri);
4)使用示例
①在实例化RestTemplate方法上添加@LoadBalanced注解
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
②使用服务名称调用服务,而非ip:port
// String orderServiceAddress = "http://localhost:7900/order/getOrderById/" + orderId; ip:port
orderServiceAddress = "http://microservice-eureka-order/order/getOrderById/" + orderId; // service name
return restTemplate.getForObject(orderServiceAddress,OrderEntity.class);
③创建服务监听类,测试负载均衡的效果
在order模块下创建一个用于监听服务实例端口的工具类
// 实现ApplicationListener接口,该接口的泛型指明了要监听事件的事件类型
@Component
public class ServiceInfoUtil implements ApplicationListener<EmbeddedServletContainerInitializedEvent> {
// EmbeddedServletContainerInitializedEvent主要用于获取运行服务的端口号
private static EmbeddedServletContainerInitializedEvent event;
@Override
public void onApplicationEvent(EmbeddedServletContainerInitializedEvent event) {
ServiceInfoUtil.event = event;
}
/**
* @description: 获取端口号
* @return
*/
public static int getPort(){
int port = event.getEmbeddedServletContainer().getPort();
return port;
}
}
在业务代码中输出端口号
System.out.println(ServiceInfoUtil.getPort());
④测试
启动order模块,然后修改端口号,再启动添加一个进程(IDEA增加一个Application),多次调用进行测试。
5)配置详解
①自动化配置
未引入Eureka时Ribbon的自动化配置
- IClientConfig:Ribbon的客户端配置:com.netflix.client.config.DefaultClientConfigImpl
- IRule:Ribbon的负载均衡策略:com.netflix.loadbalancer.zoneAvoidanceRule,该策略能在多区域环境下选出最佳区域的实例进行访问
- IPing:Ribbon的实例检查策略:com.netflix.loadbalancer.NoOpPing,不检查均返回true
- ServerList:服务清单的维护机制:com.netflix.loadbalancer.ConfigurationBasedServerList
- ServerListFilter:服务清单的过滤机制:org.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilter,优先过滤出与调用方处于同区域的服务实例
- ILoadBalancer:负载均衡器:com.netflix.loadbalancer.zoneAwareLoadBalancer,具有区域感知能力
引入Eureka后的自动化配置
引入Eureka后,服务清单的维护机制改变,服务清单交给注册中心维护
# 将不同机房的实例配置成不同的区域值,作为跨区域的容错机制实现
eureka.instance.metadataMap.zone=shanghai
# 禁用eureka对服务清单的管理
ribbon.eureka.enabled=false
②修改默认的配置
- Brixton版本:创建对应的实现实例以覆盖自动化的默认配置
@Configuration
public class MyRibbonConfiguration{
// 用PingUrl代替默认的NoOpPing
@Bean
public IPing ribbonPing(IClientConfig config){
return new PingUrl();
}
}
- Camden版本:对自定义配置的简化
# 配置Ribbon的实例检查策略
{server_name}.ribbon.NFLoadBalancerPingClassName=com.netf让x.loadbalancer.PingUrl
# 配置LoadBalancer接口的实现
{server_name}.ribbon.NFLoadBalancerClassName
# 配置IRule接口的实现
{server_name}.ribbon.NFLoadBalancerRuleClassName
# 配置ServerList接口的实现
{server_name}.ribbon.N工WSServerListClassName
# 配置ServerListFilter接口的实现
{server_name}.ribbon.NIWSServerLis七丘lterClassName
③参数配置
CommonClientConfigKey类
# 全局参数配置:ribbon.=
# e.g.创建连接的超时时间
ribbon.ConnectTimeOut=250
# 指定服务(客户端)的配置.ribbon.=
# e.g.没有服务治理框架的帮助,需要为该客户端指定具体的实例清单
hello-service.ribbon.listOfServers=localhost:8001,localhost:8002,localhost:8003
④重试机制
Spring Cloud Eureka的服务治理机制强调CAP中的AP,即可用性与可靠性;而Zookeeper更强调于CP,即一致性和可靠性,Eureka牺牲了一定的一致性,即极端情况下,它宁愿接受故障实例,也不要丢掉健康实例。因而在调用故障服务时,应该引入一定的容错机制。
Brixton需要我们自己扩展重试机制,Camden SR2开始,Spring Cloud整合了Spring Retry来增强RestTemplate的重试能力
# 开启重试机制
spring.cloud.loadbalancer.retry.enabled=true
# 断路器的超时时间需要大于Ribbon的超时时间, 不然不会触发重试
hystrix.command.default.execution.isolation.thread.timeoutinMilliseconds=10000
# 请求连接的超时时间
{service_name}.ribbon.ConnectTimeout=250
# 请求处理的超时时间
{service_name}.ribbon.ReadTimeout=1000
# 对所有操作请求都进行重试
{service_name}.ribbon.OkToRetryOnAllOperations=true
# 切换实例的重试次数
{service_name}.ribbon.MaxAutoRetriesNextServer=2
# 对当前实例的重试次数
{service_name}.ribbon.MaxAutoRetries=1
根据如上配置, 当访问到故障请求的时候, 它会再尝试访问一次当前实例(次数由 MaxAutoRetries配置), 如果不行, 就换 一个实例进行访问, 如果还是不行, 再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置), 如果依然不行, 返回失败信息。
4.5服务容错保护
1)服务故障的级联传递
微服务架构中,通常存在多个服务层调用的情况,若基础服务故障可能会发生级联传递,导致整个服务链上的服务不可用。
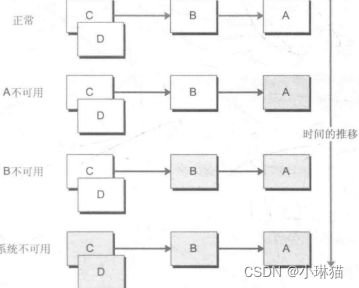
2)Spring Cloud Hystrix介绍
Spring Cloud Hystrix实现了断路器、 线程隔离等一系列服务保护功能。 它也是基于Netflix的开源框架Hystrix实现的, 该框架的目标在于通过控制那些访问远程系统、 服务和第三方库的节点, 从而对延迟和故障提供更强大的容错能力。Hystrix具备服务降级、 服务熔断、 线程和信号隔离、 请求缓存、 请求合并以及服务监控等强大功能。
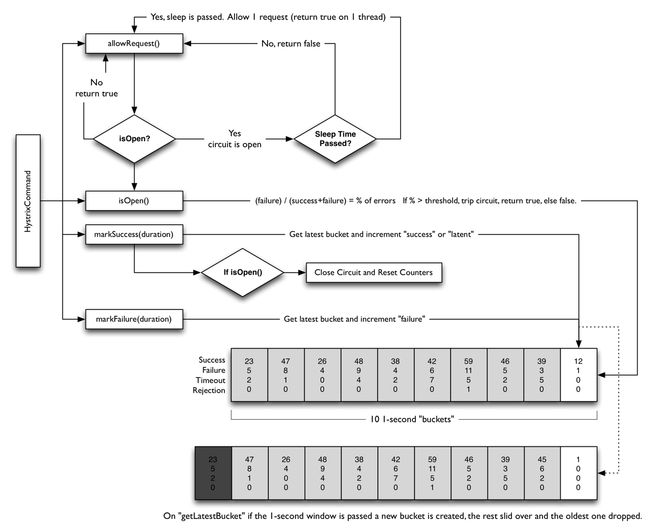
3)Spring Cloud Hystrix的熔断器状态
熔断器可以实现弹性容错,在一定条件下能够自动打开和关闭,有如下三种状态:
①关闭:线路未熔断,服务可正常调用
②打开:线路熔断,服务不可调用,调用方会进入fallback流程,快速返回结果
③半开:熔断器打开一段时间以后,进入半开状态,这时只允许一个请求通过,若请求调用成功,熔断器关闭,否则熔断器继续保持开打
熔断器的状态控制是通过当前服务健康状况(服务的健康状况=请求失败次数/请求总数)和设定的阈值(默认为10s内20次故障)
4)使用示例
之前示例的user服务会调用order服务,这样就形成了服务依赖链,order服务的不可用可能导致user的不可用,导致整个链路出错。因而在user服务层增加对order服务调用的熔断器
①user服务层导入hystrix依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-hystrixartifactId>
dependency>
②在User模块的启动类上添加注解,以开启hystrix功能
@EnableEurekaClient // 开启Eureka客户端功能
@EnableHystrix // 开启Hystrix功能
@SpringBootApplication
public class Application {
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
③在欲进行熔断的接口上指定服务调用失败的回调方法,注意接口返回值类型应与调用失败的回调放法的返回值一致
@GetMapping("queryOrderByUserId/{userId}")
@HystrixCommand(fallbackMethod = "queryOrderByUserIdFailed") // 指定失败的fallback
public OrderEntity queryOrderByUserId(@PathVariable Long userId){
long orderId = 1L;
String orderServiceAddress = "http://microservice-eureka-order/order/getOrderById/" + orderId;
return restTemplate.getForObject(orderServiceAddress,OrderEntity.class);
}
public OrderEntity queryOrderByUserIdFailed(@PathVariable Long userId){
System.out.println("service can not use");
return null;
}
5)Hystrix Dashboard
Hystrix除了能进行服务的熔断隔离外,还能对服务进行实时监控。Hystrix可也实时、累加地记录所有关于HystriCommand的执行信息
- 通过actuator监控某一服务
在欲监控的某一服务中添加,对该服务进行监控。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
通过访问:http://localhost:8000/hystrix.stream(端口号为对应服务的端口号) 可以监控服务调用的信息,该信息会按照一定频率一直刷新,但由于都是json格式数据,不易用
- 通过Hystrix Dashboard可视化监控服务应用
Hystrix Dashboard是通过实时获取Actuator端点提供的Hystrix流来实时监控这些被断路器保护的应用的健康情况;因此在这些被断路器保护的应用中需要开启Hystrix流的Actuator端点(即获取其余配置Actuator的服务)
①在根模块下新建microservice-hystrix-dashboard子模块,并引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-hystrix-dashboardartifactId>
dependency>
dependencies>
②编写配置文件
server:
port: 8030
spring:
application:
name: microservice-hystrix-dashboard
③启动类开启HystrixDashboard
@SpringBootApplication
@EnableHystrixDashboard
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
④使用监控应用
启动后,通过访问:http://localhost:8030/hystrix.stream (监控整个系统,端口号为监控应用的端口号)可以可视化的服务调用信息
在URL中输入欲监控服务的URL,(如http://localhost:8000/hystrix.stream)设置Tittle,设置delay轮询监控的时间间隔
dashboard中的各项参数可以参考这篇博客
6)原理分析
Ⅰ.调用服务的执行流程
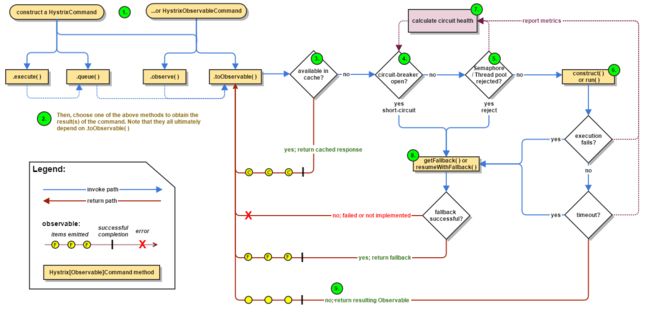
- 创建HystrixCommand或HystrixObservableCommand对象(使用了命令模式)
①HystrixCommand:用在依赖的服务返回单个操作结果的时候,实现了以下两个执行方式
// 同步执行,以依赖的服务返回一个单一的结果对象,或是在错误时抛出异常。在queue()产生异步结果Future对象之后,通过调用get()方法阻塞并等待结果的返回。
execute();
// 异步执行,直接返回一个Future对象,其中包含了服务执行结束时要返回的单一结果对象。将 toObservable()产生的原始Observable通过toBlocking() 方法转换成BlockingObservable对象, 并调用它的 toFuture()方法 返回异步的Future对象。
queue();
②HystrixObservableCommand:用在依赖的服务返回多个操作结果的时候,实现了另两种执行方式
// 返回Observable对象,表示操作的多个结果,是一个HotObservable,产生原始Observable之后立即订阅它,让命令能够马上开始异步执行 , 并返回一个Observable对象, 当调用它的subscribe 时,将重新产生结果和通知给订阅者
observe();
// 返回Observable对象,表示操作的多个结果,是一个ColdObservable,最原始的 Observable, 必须通过订阅它才会真正触发命令的执行流程
toObserveable();
Hystrix的底层实现中大量地使用了响应式编程RxJava(观察者模式)
- 结果是否被缓存
若当前命令的请求缓存功能被启用,且缓存命中,那么缓存的结果会立即以Observable对象的形式返回
- 断路器是否被打开
若缓存未命中,Hystrix在执行命令前需检查断路器是否被打开
①若断路器Open,则Hystrix不会执行命令,而是转到fallback处理逻辑
②若断路器Open,则Hystrix检查是否有可用资源来执行命令
- 线程池/请求队列/信号量是否占满
若与命令相关的线程池和请求队列或信号量(不使用线程池时)已被占满,则Hystrix也不会执行命令,而是转到fallback处理逻辑
Hystrix所判断的线程池并非容器的线程池,而是每个依赖服务的专有线程池,Hystrix为了保证不会因为某个依赖服务的问题影响到其他服务采用了舱壁模式Bulkhead Pattern(Docker就是采用舱壁模式实现进程的隔离,使得容器之间不会相互影响)来隔离每个依赖的服务
Hystrix还可以用信号量作为线程池的替代,内存开销更小(将execution.isolation.strategy设为SEMAPHORE)
Hystrix尝试降级服务时,会使用信号量,其默认值为10
- HystrixObervableCommand.construct()或HystrixCommand.run()
Hystrix会根据我们编写的方法决定采用什么样的方式来请求依赖服务
// 返回一个单一结果并产生onCompleted的结束通知或抛出异常
HystrixCommand.run();
// 返回一个Observable对象来发射多个结果,或通过onError发送错误通知
HystrixObervableCommand.construct();
如果run或construct方法的执行时间超过了命令设置的阈值,当前线程会抛出一个TimeoutException(若该命令不在自身线程中执行,则会通过单独的计时器线程来抛出),这时Hystrix会转到fallback处理逻辑
如果命令没有被取消或中断,那么Hystrix会忽略run或construct的方法返回。
如果命令没有抛出异常并返回了结果,Hystrix在记录一些日志并采集监控报告后会将该结果返回。
- 计算断路器的健康度
Hystrix会将“成功、失败、拒绝、超时”等信息报告给断路器,断路器会维护一组计数器来统计这些数据
断路器会根据这些统计数据来决定是否将断路器打开,来对某个依赖服务的请求进行熔断,直到恢复期结束。若在恢复期结束后,根据统计数据判断如果还是未达到建康指标,就再次熔断
- fallback处理
命令执行失败时,Hystrix会转到fallback尝试退回处理,该操作通常被称为服务降级,能引起服务降级处理的有以下几种情况:
①当前命令处于断路器Open状态
②当前命令的线程池、请求队列、信号量被占满时
③HystrixObservableCommand.construct或HystrixCommand.run抛出异常时
服务降级中通常需要一个通用的响应结果,且该结果的处理逻辑应该从缓存或根据一些静态逻辑来获取,而不依赖于网络请求获取。如果一定要在Hystrix中包含网络请求,那么请求也必须被包装在HystrixCommand或HystrixObservableCommand中,从而形成级联的降级策略,最终的降级逻辑一定不是一个依赖于网络请求的处理,而是一个能稳定返回结果的处理逻辑
①HystrixCommand通过实现HystrixCommand.getFallback()实现服务降级
②HystrixObservableCommand通过HystrixObservableCommand.resumeWithFallback()实现降级逻辑,该方法会返回一个Observable对象来发射一个或多个降级结果
降级逻辑返回后,Hystrix就会将该结果返回给调用者,会将HystrixCommand.getFallback()的返回结果返回给客户端,将HystrixObservableCommand.resumeWithFallback()的Observable对象直接返回给客户端
如果没有为命令设置服务降级逻辑或降级逻辑中出现了异常,Hystrix仍会返回一个Observable对象,该对象不会发射任何数据,而是通过onError方法通知命令立即中断请求,并通过onError方法引起命令失败的异常发送给调用者。实现一个可能失败的降级逻辑是一种非常糟糕的做法,我们应尽可能避免这种做法。
但出现永不失败的降级逻辑是不可能的,若降级服务时失败,Hystrix会根据不同的执行方法做出不同的处理
execute(); // 抛出异常
queue(); // 正常返回Future对象,但调用get来获取结果会抛出异常
observe(); // 正常返回Observable对象,但当订阅他时,立即通过订阅者的onError来通知中断请求
toObservable(); // 正常返回Observable对象,但当订阅他时,立即通过订阅者的onError来通知中断请求
Ⅱ.熔断器原理
断路器在HystrixCommand和HystrixObservableCommand执行过程中起到举足轻重的作用,是Hystrix中的核心
// 断路器接口定义
public interface HystrixCircuitBreaker{
// 静态类:维护了一个Hystrix命令与熔断器HystrixCircuitBreaker的关系集合:ConcurrentHashMap,String key是命令的唯一标识,每个命令也对应于一个熔断器实例(每个服务调用与熔断器是一一对应的关系)
public static class Factory{};
// 静态类HystrixCircuitBreakerImpl是断路器接口的实现类
static class HystrixCircuitBreakerImpl implements HystrixCircuitBreaker {};
// 静态类NoOpCircuitBreaker定义了一个什么都不做的熔断器的实现,它允许所有请求,保持Close
static class NoOpCircuitBreaker implements HystrixCircuitBreaker {};
// 每个Hystrix命令的请求都通过它来判断是否执行
public boolean allowRequest();
// 返回当前断路器是否打开
public boolean isOpen();
// 闭合断路器
void markSuccess();
}
public class HystrixCircuitBreakerImpl implements HystrixCircuitBreaker{
// 断路器对应的HystrixCommand实例的属性对象
HystrixCommandProperties properties;
// 让HystrixCommand记录各类度量指标的对象
HystrixCommandMetrics metrics;
// 熔断器是否打开的标志
AtomicBoolean circuitOpen;
// 熔断器打开或者是上一次测试的时间戳
AtomicLong circuitOpenedOrLastTestedTime;
// 返回当前断路器是否打开
public boolean isOpen();{
// 若熔断器Open,则返回Open
/*
否则,从metrics中获取HealthCounts统计对象(记录了一个滚动时间窗口的请求信息快照,默认为10s)做进一步判断
①若其请求总数QPS在预设的阈值内就返回false,该阈值参数为circuitBreakerRequestVolumeThreshold,默认为20
②若错误百分比在阈值内就返回false,该阈值参数为circuitBreakerErrorThresholdPercentage,默认为50
③若上面两个条件都不满足,则打开断路器,同时将当前时间戳存于circuitOpenedOrLastTestedTime对象中
*/
}
// 每个Hystrix命令的请求都通过它来判断是否执行
public boolean allowRequest(){
// 若配置强制Open熔断器,则都拒绝
// 若配置强制Close熔断器,则都通过
/*
否则通过isOpen逻辑以及打开时间(休眠时间)做判断
判断:断开的时间戳 + circuitBreakerSleepWindowInMilliseconds是否小于当前时间,若熔断器Open但休眠时间超过阈值,则再次尝试访问,此时熔断器处于半开状态,若这次请求成功,则关闭熔断器,否则重置关闭状态
*/
}
// 闭合断路器,并重置统计指标
void markSuccess(){};
}
4)使用详解
- 创建请求命令
默认的@HystrixCommand注解进行的服务调用是同步的,我们可以通过继承和注解方式来实现异步和响应式的调用
①继承方式:对应到对某个具体服务请求的封装
// 继承方式
public class Command extends HystrixCommand<{Class}>{
private RestTemplate restTemplate;
public Command(Setter setter,RestTemplate restTemplate){
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected {Class} run(){
return restTemplate.getForObject({url},{Class});
}
}
// 执行
// 同步执行
{Class} class = new Command(restTemplate).execute();
// 异步执行
Future<{Class}> future = new Command(restTemplate).queue();
②注解方式
// 注解方式
public class UserService{
@Autowired
private RestTemplate restTemplate;
@HystrixCommand
public Future<{Class}> asyncRequest(){
return new AsyncResult<{Class}>(){
@Override
public {Class} invoke(){
return restTemplate.getForObject({url},{Class})
}
}
}
}
③Observable继承方式
public class ObservableCommand extends HystrixObservableCommand<{Class}> {
private RestTemplate restTemplate;
private Long id;
public ObservableCommand(Setter setter,RestTemplate restTemplate,Long id){
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected Observable<{Class}> construct(){
return Observable.create(new Observable.OnSubscribe<{Class}>(){
@Override
public void call(Subscriber<? super {Class} observer){
try{
if(!observer.isUnsubscribed()){
{Class} classtype = restTemplate.getForObject(uri,{Class}.class,id);
observer.onNext(classtype);
observer.onComplated();
}
}catch(Exception e){
observer.onError(e);
}
}
});
}
}
// 通过Observable方式执行
Observable<String> hot = new ObservableCommand(restTemplate,1L).observe();
Observable<String> cold = new ObservableCommand(restTemplate,1L).toObservable();
④Observable注解方式
// 通过observableExecutionMode参数控制是通过observe还是toObservable的执行方式
// observe:@HystrixCommand(observableExecutionMode=ObservableExecutionMode.EAGER)
// observable:@HystrixCommand(observableExecutionMode=ObservableExecutionMode.LAZY)
@HystrixCommand
public Observable<{Class}> getUserId(final String id){
return Observable.create(new Observable.onSubscribe<{Class}>(){
@Override
public void call(Subscriber<? super {Class} observer){
try{
if(!observer.isUnsubscribed()){
{Class} classtype = restTemplate.getForObject(uri,{Class}.class,id);
observer.onNext(classtype);
observer.onComplated();
}
}catch(Exception e){
observer.onError(e);
}
}
});
}
- 定义服务降级
①注解方式
上面的示例已经提到通过注解定义服务降级回调的基本方式,这要求回调方法和服务调用方法在同一类中,因而回调方法的访问修饰符不限。如果在回调方法中执行的逻辑并不是一个稳定逻辑,即同样涉及到网络/服务的调用,存在失败的可能,则应该将其添加@HystrixConmmand注解,再度进行熔断控制
一些情况下,可以不去实现降级逻辑,只需给出错误提示即可:
[1]执行写操作的命令:返回void或空的Observable
[2]执行批处理命令或离线计算的命令
②继承方式
在定义调用服务的命令时,可以通过继承和重写的方式来定义具体的服务调用,在继承类中还可以重写服务降级的逻辑:
[1]继承HystrixCommand类,需重写getFallback,该方法返回泛型类
[2]继承HystrixObservableCommand类,需重写resumeWithFallback方法,该方法返回Observable对象
- 异常处理
在HystrixCommand实现的run方法抛出异常时,除了HystrixBadRequestException之外的异常都会被认为是命令的执行失败而触发降级逻辑
①通过注解忽略一些异常类型
@HystrixCommand(ignoreExceptions={BadRequestException.class})
②异常捕获
对于不同类型的异常,往往需要不同的降级策略。
[1]传统的继承方式,在降级逻辑中可以通过Throwable getExecutionException方法获取具体的异常,通过不同异常分支进入不同的降级策略
[2]通过注解的方式实现异常捕获,在降级方法的形参中加入Throwable类,以此获取不同的异常类型,再进入不同的降级处理分支
@HystrixCommand(fallbackMethod="fallback")
{Class} getUserById(String id){
throw new RuntimeException("fail");
};
{Class} fallback(String id,Throwable e){
assert "fail".equals(e.getMessage());
}
- 命令名称、分组、线程池划分
继承方式实现的Hystrix命令使用类名作为默认的命令名称
Hystrix会根据组来组织和统计命令的警告、仪表盘等信息,还根据组来为命令的执行划分线程池(舱壁模式),同组命令使用同一个线程池,由此我们有时需要对命令的组和线程池进行更灵活的自定义分类
①继承方式自定义命令的组和名称
// 继承类的构造函数
public Command(){
// 只有通过withGroupKey静态函数才能创建Setter实例,因而设置命令名称时需要先设置组名
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("组名"))
.addCommandKey(HystrixCommandKey.Factory.asKey("命令名称")););
}
②自定义命令的线程池(不通过组名)
推荐通过线程池名进行划分而非默认的组名,因为多个命令可能从业务逻辑上来看属于同一个组,但从实现本身上需要和其他命令进行隔离
// 继承类的构造函数
public Command(){
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("组名"))
.addCommandKey(HystrixCommandKey.Factory.asKey("命令名称"))
.addThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("线程池名")););
}
③注解方式
@HystrixCommand(commandKey="命令名",groupKey="组名",threadPoolKey="线程池名")
- 请求缓存
①优点
[1]减少重复请求数,降低依赖服务的并发度
[2]在同一用户请求的上下文中,相同依赖服务的返回数据始终保持一致
[3]请求缓存在run和construct执行之前生效,可以减少不必要的线程开销
②继承方式
public class Command extends HystrixCommand<{Class}>{
private RestTemplate restTemplate;
private Long id;
public Command(Setter setter,RestTemplate restTemplate,Long id){
super(setter);
this.restTemplate = restTemplate;
this.id = id;
}
@Override
protected {Class} run(){};
/*
在实现HystrixCommand或HystrixObservableCommand通过重载getCacheKey方法开启请求缓存
Hystrix会根据key来区分是否为同一请求
*/
@Override
protected String getCacheKey(){
return String.valueOf(id);
}
/*
清理失效缓存:提供静态方法,刷新缓存,在需要修改数据后调用
*/
public static void flushCode(Long id){
HystrixRequestCache.getInstance(GETTER_KEY,
HystrixConcurrencyStrategyDefault.getInstance())
.clear(String.valueOf(id));
}
}
③注解方式
@HystrixCommand
@CacheResult // 开启结果缓存,需与HystrixCommand联合使用,key默认使用方法的全部参数
@CacheResult(cacheKeyMethod="setKey") // 开启结果缓存,需与HystrixCommand联合使用,指定key函数,使用自定义的key
public {Class} getUserById(@CacheKey("id") Long id){ // 使用注解的方式指定自定义key,它的优先级比指定函数低,其中id为key名,Long id为value;value可为对象
}
// 指定key函数
private Long setKey(Long id){
return id;
};
// 缓存更新,commandKey必须指定,指定对应的结果缓存函数
@CacheRemove(commandKey="getUserById")
@HystrixCommand
public void update(@CacheKey("id") User user){};
- 请求合并
高并发下,通信次数增加,总的消耗时间会变得不理想,同时依赖服务的线程池容量有限,将出现等待的情况。为了减少请求数,Hystrix通过HystrixCollapser实现请求的合并,以减少通信量和线程数的占用。
HystrixCollapser在HystrixCommand之前放置一个合并处理器,将时间框(默认为10ms)内对同一依赖服务的请求进行合并,以批量方式发送请求(服务提供方也需要相应地提供批量实现接口)
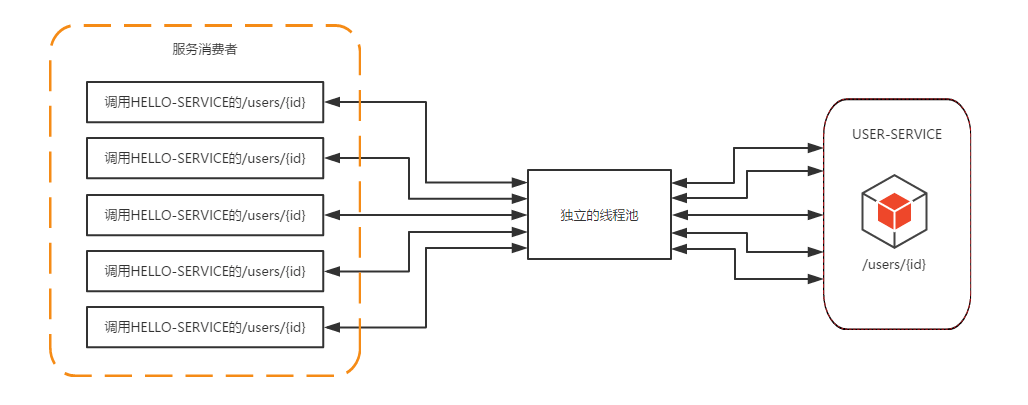
请求合并也并非在任何场景下都适用,它也存在着自己的额外开销:
[1]请求命令本身的延迟:如果依赖服务的请求是一个高延迟的命令,那么使用合并请求,延迟时间窗口便显得微不足道了
[2]延迟窗口内的并发量:如果延迟窗口内的并发量很小,则没必要进行请求合并
①继承方式
②注解方式
@Service
public class UserService{
@Autowired
private RestTemplate restTemplate;
// 为单个请求指定请求合并方法
@HystrixCollaper(batchMethod="findAll",collapserProperties={
@HystrixProperty(name="timerDelayInMilliseconds",value="100")
})
public User find(Long id){
return null;
}
@HystrixCommand
public List<User> findAll(List<Long> ids){
return restTemplate.getForObject(uri,List.class,StringUtils.join(ids,","));
}
}
7)属性配置
配置方式:全局默认配置 < 全局配置属性(配置文件中定义的全局属性) < 实例默认值(通过代码:继承的构造函数、注解的属性为实例配置) < 实例属性配置(配置文件中为指定实例进行属性配置)
其中通过配置文件方式的属性配置,可以通过Spring Cloud Config和Spring Cloud Bus动态刷新
8)Turbine集群监控
4.6API网关
1)客户端直接调用各服务的缺点
①增加开发和维护成本:客户端调用服务接口时会有一些额外的校验,如权限机制。若客户端直接调用各服务,则每个服务都需要一套自己的校验机制,这样一旦校验机制的增删改都需要逐一修改每一个服务
②微服务重构困难:随着时间的推移,我们可能会改变系统服务拆分的方案(如合并或拆分服务)如果客户端直接与各服务交互,这种重构就难以实施
③微服务协议限制:客户端直接请求的服务可能是与Web无关的协议,如Thrift的RPC、AMQP。这两种协议不适合浏览器或防火墙,最好在内部使用。应用应该在防火墙外采用HTTP或WEB Socket等协议。
2)API网关简介
API Gateway是一个服务器,是进入系统的唯一节点,它封装了内部系统的架构,并为客户端暴露了各个API。它还有其他功能:如权限、监控、负载均衡、缓存、请求分片和管理、静态响应处理等。
与客户端直接调用各个服务相比,客户端通过API网关调用服务更加简单。API网关给每一个客户端一个特定的API,减少了客户端与服务器的通信次数,也简化了客户端代码。API网关还可以在外部的Web协议与内部的非Web协议之间进行转换
API网关有多种实现方式,如Nginx、Zuul、Node.js等
3)Spring Cloud Zuul
Zuul是Netflix公司开发的基于JVM的路由器和服务端负载均衡器,后被加入到了Spring Cloud中。Zuul属于边缘服务可以用来执行认证、动态路由、服务迁移、负载均衡、安全和动态响应处理等
①创建API网关应用
在Spring Cloud根模块下创建API网关子模块,并引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eurekaartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zuulartifactId>
dependency>
dependencies>
②编写配置文件
server:
port: 8050
eureka:
instance:
prefer-ip-address: true
client:
service-url:
defaultZone: http://localhost:8761/eureka/
spring:
application:
name: microservice-gateway-zuul
zuul:
routes:
order-serviceId: # Zuul的唯一标识,可任设名称。若与serviceId相同,则可以省略
path: /order/**
service-id: microservice-eureka-order # 服务名称,Eureka中的serviceId
user-serviceId:
path: /user/**
service-id: microservice-eureka-user
# 不想暴露给外部的服务,该配置下的服务将不会被路由暴露
#ignored-services:
③编写启动类
@SpringBootApplication
@EnableEurekaClient
@EnableZuulProxy
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
④测试使用
通过直接与服务交互:http://localhost:8000/user/queryOrderByUserId/1
通过Zuul与服务交互:http://localhost:8050/microservice-eureka-user/user/queryOrderByUserId/1
⑤Zuul的单独使用
上述示例是将Zuul与Eureka整合使用的,这种方式可以让路由映射到具体服务。Zuul还可以单独使用:删除Eureka的依赖,修改配置文件
zuul:
routes:
order-url:
path: /order-url/**
service-id: http://localhost:7900/ # 服务名器地址和端口号
user-url:
path: /user-url/**
service-id: http://localhost:8000/
尽管这种方式也可以实现网关的作用,但在实际中不会使用。因为运维人员需要花费大量时间维护各个路由的path和url的关系,而与Eureka整合时,具体的url会交给Eureka管理。
4.7分布式配置管理
1)为何使用分布式配置管理
一个微服务可能有多个运行的实例,如果对其配置文件修改,则需要修改多处,并重启各个实例。分布式配置管理则是为了便于集中配置的统一管理。
目前比较流行的分布式配置中心组件有:百度的disconf、阿里的diamond、携程的apollo和Spring Cloud的Config
2)Spring Cloud Config简介
相比于同类产品,SpringCloud Config的最大优势就是可以和Spring无缝集成,迁移成本低,可以使项目具有更加统一的标准(依赖版本和约束规范),避免了组件集成时的版本、依赖冲突等问题
Spring Cloud Config是Spring Cloud团队创建的一个全新项目,主要用来为分布式系统中的外部配置提供服务器(Config Server)和客户端(Config Client)支持
①服务器端:也称为分布式配置中心,是一个独立的微服务应用,主要用于集中管理应用程序各个环境下的配置,默认使用Git存储配置文件内容,也可以使用SVN存储,或本地存储
②客户端:即微服务架构中的各个微服务,通过指定的配置中心来管理应用资源以及配置内容,并在启动时从配置中心获取和加载配置信息
3)工作流程
用户先将配置文件推送到Git或SVN中 → 服务启动时,通过配置中心获取配置信息,配置中心会从Git或SVN中获取对应的配置信息
4)使用本地存储方式实现配置管理
①搭建配置中心Config Server,并引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-config-serverartifactId>
dependency>
dependencies>
②编写配置文件
server:
port: 8899
spring:
application:
name: microservice-config-server
profiles:
active: native # 使用本地存储方式保存配置信息
③在配置中心本地创建配置文件
在src/main/resources/目录下放入本地存储的配置文件,配置文件的命名格式如下:
# application:应用名;profile:环境名,如dev开发、prod预发布、test测试;label:可选,Git分支名
/[{lable}/]{application}-{profile}.yml
/{application}/{profile}[/{lable}]
e.g.测试的配置文件名为:在resource下创建develop文件夹,用于存放开develop分支下的配置文件。将order的配置文件更名为oder-dev.yml放入develop文件夹中,其资源路径全称为:develop/order-dev.yml,其中develop是git分支名,order为application应用名,dev为profile环境名。
④创建启动类
@SpringBootApplication
@EnableConfigServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
⑤测试服务器端
启动应用,浏览器输入:http://localhost:8899/order/order/dev(name/profile/label)
直接访问配置文件资源:http://localhost:8899/develop/order-dev.yml(label/name-profile)
⑥搭建客户端
让服务通过配置中心来加载配置文件
引入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-configartifactId>
dependency>
删除order中的配置文件,新建bootstrap.yml/bootstrap.properties(文件名必须为bootstrap,它会在appllication.yml之前加载)
server:
port: 7900
spring:
application:
name: microservice-eureka-order
cloud:
config:
name: order
profile: dev
label: develop
uri: http://localhost:8899/application-order-dev.yml # 指定配置文件的uri
5)使用Git存储方式实现配置管理
Spring Cloud Config服务端默认采用Git配置仓库
①配置Git仓库
在Git(GitHub/Gitee)上创建microservice-config目录,将配置文件放入其中
②修改服务端配置文件
server:
port: 8899
spring:
application:
name: microservice-config-server
cloud:
config:
server:
# 使用git的方式
git:
# git仓库地址,共有仓库无需账户密码,私有需要账户密码
uri: https://gittee.com/namespace/project_name.git
③修改客户端配置文件
server:
port: 7900
spring:
application:
name: microservice-eureka-order
cloud:
config:
name: order
profile: dev
label: develop
uri: http://localhost:8899/application-order-dev.yml
6)不重启更新配置文件
在客户端通过POST请求refresh方法刷新配置内容
①客户端(服务)中添加spring-boot-starter-actuator依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
②启动类增加@RefreshScope注解,开启refresh机制
添加该注解后,执行refresh时会更新该注解类下的所有变量值,包括远程配置信息
③修改配置文件,关闭安全认证信息
managment:
security:
enabled: false # 是否开启actuator安全认证
④配置文件修改后,服务端会获取到Git中更新的配置文件,客户端通过POST请求调用refresh方法:http://localhost:port/refresh刷新配置信息
4.8声明式服务调用:Spring Cloud Feign
1)介绍
Spring Cloud Feign基于Netflix Feign实现,对Ribbon和Hystrix进行了更高层级的封装。对各个微服务自行封装了一些客户端来包装这些依赖服务的调用,以注解的方式配置接口,简化了服务调用时的代码。Spring Cloud Feign对其注解(Feign和JAX-RS)和主要组件(编码器和解码器)具有可拔插的支持。
2)使用
①引入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-feignartifactId>
dependency>
②启动类注解:@EnableFeignClients
③通过注解声明服务调用的接口
@FeignClient("eureka-client-kanxiuren") // 对应服务名
public interface KanXiuRenApi {
@RequestMapping(value="/kanxiuren/test",method = RequestMethod.GET) // 对应服务的接口
public String test();
@RequestMapping(value="/kanxiuren/getWorkById/{id}",method = RequestMethod.GET)
public String getWorkById(@PathVariable("id") Long id); // 注意参数注解需要指定value值,与平时默认的不同
@RequestMapping(value="/demo1",method = RequestMethod.GET)
public String demo1(@RequestParam("name") String name);
@RequestMapping(value="/demo2",method=RequestMethod.GET)
public User demo2(@RequestHeader("name") String name,@RequestHeader("age") Integer age);
@RequestMapping(value="/demo3",method=RequestMethod.POST)
String demo3(@RequestBody User user);
}
3)继承特性
尽管通过Feign的接口定义可以避免重复写RestTemplate调用服务,但是每个要调用的服务需要重复复制接口和DTO,一种方法是讲服务调用接口抽出成为单独的应用,然后通过Maven引入。但这样做也有其弊端,接口在构建期间就建立起了依赖,接口变动会对项目构建造成影响。
4)配置
1)Feign默认使用了Ribbon和Hystrix,可以通过配置设置其对应信息
# ribbon全局配置
ribbon:
ConnectTimeout: 500
ReadTimeout: 5000
# 对单独某个被调用的服务进行配置
eureka-client-kanxiuren:
ribbon:
ConnectTimeout: 500
ReadTimeout: 2000
# 开启重启机制
OkToRetryOnAllOperations: true
# 先对当前访问的服务实例进行重试
MaxAutoRetries: 1
# 再换服务实例进行重试
MaxAutoRetriesNextServer: 2
# Hystrix全局配置
hystrix:
command:
default:
execution:
isolation:
thread:
# 设置全局超时时间
timeoutInMilliseconds: 5000
# 指定命令配置
getWorkById:
execution:
isolation:
thread:
timeoutInMilliseconds: 5000
2)禁用Hystrix
// 自定义配置类
@Configuration
public class DisableHystrixConfiguration{
@Bean
@Scope("prototype")
public Feign.Builder feignBuilder(){
return Feign.builder();
}
}
// 为Feign接口指定配置类
@FeignClient(name="eureka-client-kanxiuren",configuration = DisableHystrixConfiguration.class)
public interface KanXiuRenApi{
...
}
3)服务降级
// 为某服务接口对应的降级服务建立统一的类
@Component
public class KanXiuRenApiFallback implements KanXiuRenApi{
@Override
public String test(){
return "error";
}
@Override
public String getWorkById(Long id){
return "error";
}
@Override
public String demo1(String name){
return "error";
}
@Override
public User demo2(String name, Integer age){
return null;
}
@Override
String demo3(User user){
return "error";
}
}
// 为Feign接口配置服务降级类
@FeignClient(name="eureka-client-kanxiuren",fallback = KanXiuRenApiFallback.class)
public interface KanXiuRenApi{
...
}
4)请求压缩
feign:
# 请求压缩
compression:
request:
# 开启请求发送
enabled: true
# 指定压缩的数据类型
mime-types: text/xml,application/xml,application/json
# 指定最小压缩大小,超过这个大小才会进行压缩
min-request-size: 2048
response:
enabled: true
5)日志配置
4.9消息中心:Spring Cloud Bus
使用轻量级的消息代理来构建一个公用的消息主题让系统中所有微服务实例都连接上来,由于主题中产生的消息会被所有实例监听和消费,因而被称为消息总线。在总线上的各个实例都可以方便地广播一些需要让该主题上的实例都知道的消息,如配置信息的变更或其他一些管理操作。
常用的消息代理中间件:ActiveMQ、Kafka、RabbitMQ、RocketMQ…
书中的Spring Cloud Bus仅支持Kafka、RabbitMQ
4.10消息驱动的微服务:Spring Cloud Stream
Spring Cloud Stream 为微服务应用构建消息驱动能力的框架。可以基于Spring Boot创建独立的、可用于生产的Spring应用程序。它通过Spring Integration来连接消息代理中间件以实现消息事件驱动。引入发布-订阅、消费组、分区三个概念,可以简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多精力关注于核心业务逻辑的处理。
4.11分布式服务跟踪:Spring Cloud Sleuth
随着业务的发展,系统规模会变得越来越大,各微服务间的调用关系也会变得越来越错综复杂。通常一个由客户端发起的请求在后端系统中会经过不同的微服务调用来协同产生最后的请求结果,形成一条复杂的分布式服务调用链路。
此时,通过Spring Cloud Sleuth对全链路调用进行跟踪以发现错误根源并监控分析每条链路上的性能瓶颈。