VoxelNet:End_to_End Learning for Point Cloud Based 3D Object Detection 论文学习与解读
写给读者
文章的内容主要是我个人在学习论文的过程中按模块对论文进行了粗略的翻译并且加入了一定的理解,其中对于一些我不太了解的额外知识进行了一个补充,欢迎大家指正。
Introduction
-
LiDAR(激光雷达)获取到的点云数据存在存在很高的随机点密度,这是由非均匀的3D空间采样,对一系列有效的传感器的遮盖和相关的动作。为了解决解决这个问题,很多方法采用人为手工制作点云的特征表现来用于3D物体识别。
-
然而手工的方法在获取3D类型信息和获取侦测任务所需的不变信息中会产生瓶颈
RPN
Region Proposal Network,用于生成候选区域(Region Proposal)
RPN 包括以下部分:
- 生成 anchor boxes(锚框)
- 判断每个 anchor box 为 foreground(包含物体) 或者 background(背景) ,二分类
- 边界框回归(bounding box regression) 对 anchor box 进行微调,使得 positive anchor 和真实框(Ground Truth Box)更加接近
anchor boxes
训练阶段:
- 把anchor box作为训练样本,为了训练样本我们需要为每个锚框标注两类标签:一是锚框所含目标的类别,简称类别;二是真实边界框相对锚框的偏移量,简称偏移量(offset)。
- 标注锚框的方法是假设图像中有Xa个锚框,Xb个真实边界框,这样的话就形成了一个anchor box与真实边界框之间的对应关系矩阵,那么就根据这个对应关系找出与每个anchor box交并比最大的真实边界框,然后真实边界框的标签作为anchor box的标签,然后计算anchor box相对于真实边界框的偏移量。这样的话就标记好了每个anchor box:标签和偏移量。
- 训练阶段就是对特征图像进行卷积训练,然后将训练出来的锚框和和预先标注好的锚框进行比较获得损失,通过降低损失来训练权重矩阵。
预测阶段:
- 首先在图像中生成一系列的anchor box,然后根据训练好的模型参数去预测这些anchor box的类别和偏移量,进而得到预测的边界框。
- 如果得到多个预测出来的边界框,接下来可以使用NMS(非极大值抑制)的方法来挑选出最合适的anchor box框
PRN中的卷积
当我们已经得到锚框(anchor boxes)后,需要完成以下两项任务:
(1)anchor box 中是否包含识别物体,foreground/background,二分类问题
(2)如果 anchor box 包含物体,怎么调整,才能使得 anchor box 与 ground truth 更接近。
总结
简而言之,RPN 只挑选出了可能包含物体的区域(rpn_rois)以及其包含物体的概率(rpn_roi_probs)。在后续处理中,设定一个阈值 threshold,通过比较包含物体的概率和阈值的大小关系来判断是忽略还是进行类别判定。
VEF Layer
- 通过将点状特征与局部聚集的特征相结合,实现了体素内的点间交互。堆叠多个VFE层可以学习复杂的特征来描述局部的三维形状信息
Related work
- 其他方法大多使用手动标记的数据,没有办法很好的适应复杂情况
- 很多算法是从2D的图像中获取到3D的检测框,然而然而,基于图像的三维检测方法的准确性受到深度估计的准确性的限制。
- 一些模型采用融合图像和3D点云的多模态融合的方法来提高检测的准确率。但是这一种方法需要一个和LiDar同步并且校准过的相机,而这样限制了他们的使用并且让解决方案对传感器故障模式更加敏感。
VoxelNet
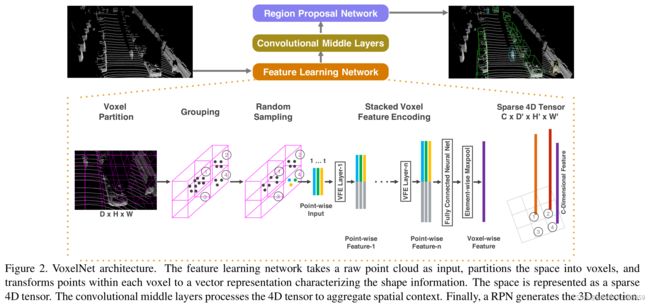
Architecture
Feature Learning Network
Voxel Partition
首先将点云分割成等量大小的空间,假设点云涵盖了三维空间,其范围为D、H、W,分别沿Z、Y、X轴分布,因此我们将每一个体素的大小定义为 v D , v H 和 v W v_D,v_H和v_W vD,vH和vW所以最后每一个3D体素的大小是 D ′ = D / v D D^′= D/v_D D′=D/vD, H ′ = H / v H H^′= H/v_H H′=H/vH和 W ′ = W / v W W^′=W/v_W W′=W/vW
Grouping
根据点所在的体素进行分组,因为各种原因LiDAR获得的点在不同空间中的密度是不同的,因此经过分组之后每一个体素中会含有不同数量的点
Random Sampling
因为一个高清晰度的LiDAR每次采样都会大量的点,因此采用随机采样的方法。设定一个阈值T,从包含数据点数大于T的体素中进行随机采样。这样做包含两个原因:一是可以计算的saving,二是减少不同体素间点数量上的不平衡
Stacked Voxel Feature Encoding
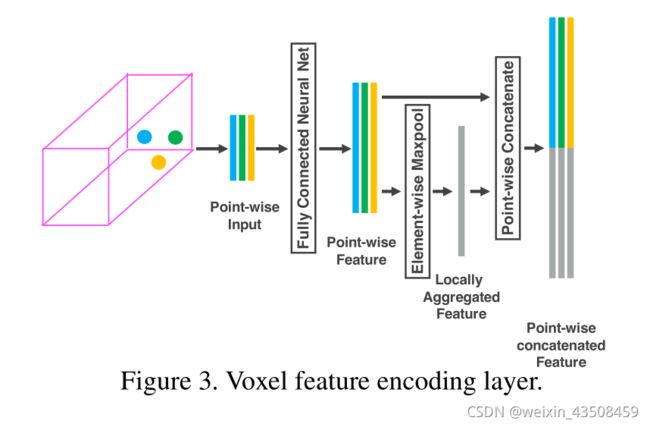
这个模型的关键创新是一系列的VFE层
VFE Layer-1
假设 V = { p i = [ x i , y i , z i , r i ] T ∈ R 4 } i = 1... t V=\{p_i = [x_i ,y_i ,z_i ,r_i ]^T∈R^4 \}_{i=1...t} V={pi=[xi,yi,zi,ri]T∈R4}i=1...t是一个非空且包含t
首先用V中所有点的均值作为所有点的中心,然后得到一个包含每个点和中心偏移量的新的点集 V = { p i = [ x i , y i , z i , r i , x i − v x , y i − v y , z i − v z ] T ∈ R 7 } i = 1... t V=\{p_i = [x_i ,y_i ,z_i ,r_i,x_i−v_x ,y_i−v_y ,z_i −v_z ]^T∈R^7 \}_{i=1...t} V={pi=[xi,yi,zi,ri,xi−vx,yi−vy,zi−vz]T∈R7}i=1...t
之后每一个 p i p_i pi通过一个全连接层(Fully Connected Layer)转换进一个特征空间 f i ∈ R m f_i∈ R^m fi∈Rm。其中FCN包括了线性层、Batch Normalization Layer和ReLU Layer。
之后过一个MaxPooling来获得局部聚合的特征 f ~ ∈ R m \widetilde{f}∈ R^m f ∈Rm之后将 f i 和 f ~ f_i和\widetilde{f} fi和f 连接起来形成 f i o u t = [ f i , f ~ ] T ∈ R 2 m f^{out}_i= [f_i,\widetilde{f}]_T ∈ R^{2m} fiout=[fi,f ]T∈R2m之后我们就获得了输出 V o u t = { f i o u t } i . . . t V_{out}=\{f^{out}_i\}_{i...t} Vout={fiout}i...t所有的非空体素都用相同的共享权重的FCN方式进行Encode
其它的VFE层和这个类似
因为输出特征同时包含了基于点的特征和局部聚合特征,VFE层编码了点在体素中的相互作用,并且允许最后的特征表达能够学习到描述性的类型信息
Sparse Tensor Representation
一系列通过刚刚对非空体素集合的处理,我们获得了一列表的体素特征,每一个都独一无二的对应一个非空体素的空间坐标。这一系列的体素特征可以通过一个4D的系数张量表示 ( C × D ′ × H ′ × W ′ ) (C\times D^′ \times H^′ \times W^′) (C×D′×H′×W′)这也是算法高效的核心所在。
Convolutional Middle Layers
C o n v M D ( c i n , c o u t , k , s , p ) ConvMD(c_{in},c_{out},k,s,p) ConvMD(cin,cout,k,s,p)来表达M维度的卷积操作。其中cin和cout是输入和输出channels数量
这一块用在RPN输入之前,用于获取基于体素的特征,输入是Sparse Tensor Representation的四维tensor,输出是一个三维的tensor,在training detail中的三维tensor的大小为 ( C × H ′ × W ′ ) (C × H^′ × W^′ ) (C×H′×W′) C o n v M D ( c i n , c o u t , k , s , p ) ConvMD(c_{in},c_{out},k,s,p) ConvMD(cin,cout,k,s,p)来表达M维度的卷积操作。其中cin和cout是输入和输出channels数量
Region Proposal Network
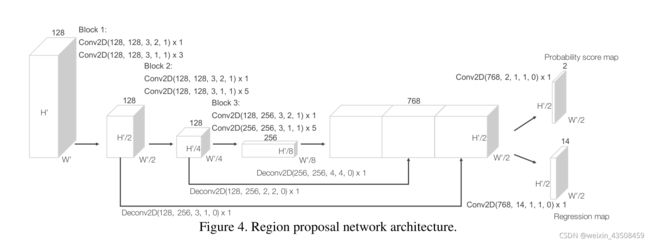
RPN的输入层是convolutional middle layers提供的一个特征图。
RPN网络由三块卷积层组成,第一层中每一个Conv2D通过设置stride为2来进行下采样,紧接着是一系列stride为1的卷积。每一个卷积层之后都会有Batch Normalization和ReLU激活函数。
最终我们对每一个block进行上采样到一个固定的大小,之后将其合并去构建一个高分辨率的特征图。这个特征图会被映射到两个目标图中,一个是概率分数图(Probability Score map),一个是回归图(Regression map)。
Loss Function
- Let { a i p o s } i = 1... N p o s \{a^{pos}_i\}_{i=1...N_{pos}} {aipos}i=1...Npos be the set of N p o s N_{pos} Npos positive anchors and { a i n e g } i = 1... N n e g \{a^{neg}_i\}_{i=1...N_{neg}} {aineg}i=1...Nneg be the set of N n e g N_{neg} Nnegnegative anchors.
- 将真实的3D框参数化为 ( x c g , y c g , z c g , l g , w g , h g , θ g ) (x^g_c,y^g_c,z^g_c,l^g,w^g,h^g,θ^g ) (xcg,ycg,zcg,lg,wg,hg,θg),其中 x c g , y c g , z c g x^g_c,y^g_c,z^g_c xcg,ycg,zcg表示中心点坐标, l g , w g , h g l^g,w^g,h^g lg,wg,hg表示box的长宽高, θ g θ^g θg表示在Z轴上的旋转
- 为了检测matching positive box和其对应的ground truth坐标,我们将其parameterize as ( x c a , y c a , z c a , l a , w a , h a , θ a ) (x^a_c,y^a_c,z^a_c,l^a,w^a,h^a,θ^a ) (xca,yca,zca,la,wa,ha,θa),然后定义一个残差向量(residual vector) $u∗∈R7 包 含 了 7 个 回 归 目 标 包含了7个回归目标 包含了7个回归目标(∆x,∆y,∆z,∆l,∆w,∆h,∆θ)$每一个的计算方法如图中所示
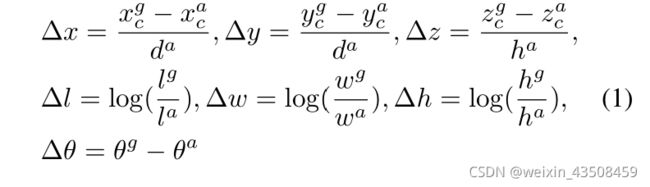
其中 d a = ( l a ) 2 + ( w a ) 2 d^a=\sqrt{(l^a)^2+(w^a)^2} da=(la)2+(wa)2是box底部的对角线
- 在这里,我们想直接估计定向的3D box,并通过对角线 d a d^a da将∆x和∆y标准化。因此我们定义出的Loss Function如下
L = α 1 N p o s ∑ i L c l s ( p i p o s , 1 ) + β 1 N n e g ∑ j L c l s ( p j n e g , 0 ) + 1 N p o s ∑ i L r e g ( u i , u i ∗ ) L=\alpha\frac{1}{N_{pos}}\sum_iL_{cls}(p^{pos}_i,1)+\beta\frac{1}{N_{neg}}\sum_jL_{cls}(p^{neg}_j,0)+\frac{1}{N_{pos}}\sum_iL_{reg}(u_i,u^*_i) L=αNpos1i∑Lcls(pipos,1)+βNneg1j∑Lcls(pjneg,0)+Npos1i∑Lreg(ui,ui∗)
- 其中 p i p o s p^{pos}_i pipos和 p j p o s p^{pos}_j pjpos分别代表了positive anchor a i p o s a^{pos}_i aiposand negative anchor a j n e g a_j^{neg} ajneg的softmax的结果。 u i ∈ R 7 u_i∈R^7 ui∈R7和 u i ∗ ∈ R 7 u^*_i∈R^7 ui∗∈R7分别是positive anchor a i p o s a^{pos}_i aipos的regression output 和 ground truth值。前两个部分是positive和negative集合的归一化的分类损失,其中 L c l s L_{cls} Lcls表示二分类损失,而 α \alpha α和 β \beta β是平衡相对重要性的正向常数。 L r e g L_{reg} Lreg代表了回归损失,其中使用了SmoothL1损失。
Efficient Implementation
直接工作存在的问题是点的分布是很稀疏的且每个体素有不同数量的点。因此我们设计一个可以将点云转换为tensor的结构,利用GPU使得堆叠的VFE层可以并行处理
首先初始化一个 K × T × 7 K\times T\times 7 K×T×7来存储体素输入特征缓冲,其中K表示非空体素数量的最大值,T是一个体素中所含有的点数的最大值,7是每个点的encoding dimension。所有点在处理前会先随机分组
对于在点云中的每一个点,我们会检测相关的体素是否已经存在了,这种检测主要靠的是hash算法,其中体素的坐标用作keys。如果体素已经存在切其中点的数量小于T,我们将该点插入进去,否则忽略该点。
如果体素还没有创建,则创建该体素,将其坐标加入hash算法的keys中,然后将点插入其中。体素输入特征和坐标缓冲区可以通过对点列表的一次传递来构建。
Training Details
Network Details
Data Augmentation
-
定义 M = { p i = [ x i , y i , z i , r i ] T ∈ R 4 } i = 1... t M=\{p_i = [x_i ,y_i ,z_i ,r_i ]^T∈R^4 \}_{i=1...t} M={pi=[xi,yi,zi,ri]T∈R4}i=1...t作为点云的全集,定义一个3D bonding box b i = ( x c , y c , z c , l , w , h , θ ) b_i=(x_c,y_c,z_c,l,w,h,θ) bi=(xc,yc,zc,l,w,h,θ)其中 x c , y c , z c x_c,y_c,z_c xc,yc,zc表示中心点坐标, l , w , h l,w,h l,w,h表示box的长宽高, θ θ θ表示在Z轴上的旋转 Ω i = { p ∣ x ∈ [ x c − l / 2 , x c + l / 2 ] , y ∈ [ y c − w / 2 , y c + w / 2 ] , z ∈ [ z c − h / 2 , z c + h / 2 ] , p ∈ M } Ω_i=\{p|x∈[x_c−l/2,x_c+l/2],y∈[y_c−w/2,y_c+w/2],z∈[z_c−h/2,z_c+h/2],p∈M\} Ωi={p∣x∈[xc−l/2,xc+l/2],y∈[yc−w/2,yc+w/2],z∈[zc−h/2,zc+h/2],p∈M}作为包含在 b i b_i bi中的全部点
-
第一种augmentation方法
第一种augumentation的方法是对真实标记的3D box和其中的point运用一个独立的扰动(perturbation),其中 ∆ θ ∆θ ∆θ在一个符合均匀分布范围内随机抽取, ( ∆ x , ∆ y , ∆ z ) (∆x,∆y,∆z) (∆x,∆y,∆z)通过均值为0方法为1的高斯分布在 Ω i Ω_i Ωi中的每一个点进行独立的抽取。最后为了避免出现从物理层面上不可能的点,对任意两个box使用了碰撞检测,如果出现问题则回复到最初始的样子。采用这种方法可以大幅度的增加可以学习的变量
-
第二种augmentation方法
对所有的ground truth box b i b_i bi和整个点云M应用全局缩放。具体来说,我们将XYZ三个维度大小和每个 b i b_i bi的三个维度,以及M中所有点的XYZ坐标与一个从均匀分布[0.95,1.05]中抽取的随机变量相乘。这样可以提高图分类和检查任务的鲁棒性
-
第三种augmentation方法
对点云M和所有的ground truth box进行在Z轴上的一个小范围的扰动,扰动的大小取决于一个小范围的均匀分布。通过旋转点云,模拟了自行车的转弯。
Conclusion
大部分现有的方法在基于雷达的3D检测任务重用的是手工录入的特征表示,而本文移除了因为人工处理而产生的瓶颈并提出了VoxelNet:一个全新的端到端的可以训练的基于点云的3D检测的深度结构。
本文提出的方法可以直接对离散的3D点云数据进行处理并且有效的获取到3D物体的类型信息。本文还介绍了VoxelNet的有效实现,它得益于点云的稀疏性和体素网格的并行处理。
我们在KITTI汽车检测任务上的实验表明,VoxelNet比最先进的基于LiDAR的三维检测方法有很大优势。在更具挑战性的任务中,如行人和骑车人的三维检测,VoxelNet也显示出令人鼓舞的结果,表明它提供了更好的三维表现。未来的工作包括将VoxelNet扩展为基于LiDAR和图像的端到端三维检测,以进一步提高检测和定位的准确性。
我们在KITTI汽车检测任务上的实验表明,VoxelNet比最先进的基于LiDAR的三维检测方法有很大优势。在更具挑战性的任务中,如行人和骑车人的三维检测,VoxelNet也显示出令人鼓舞的结果,表明它提供了更好的三维表现。未来的工作包括将VoxelNet扩展为基于LiDAR和图像的端到端三维检测,以进一步提高检测和定位的准确性。