大数据管理平台DataSophon-1.1.1安装部署详细流程
1 DataSophon介绍
1.1 DataSophon愿景
DataSophon致力于快速实现部署、管理、监控以及自动化运维大数据云原生平台,帮助您快速构建起稳定、高效、可弹性伸缩的大数据云原生平台。
1.2 DataSophon是什么
《三体》,这部获世界科幻文学最高奖项雨果奖的作品以惊艳的"硬科幻"风被大家所熟知,其作者刘慈欣更是被誉为"单枪匹马将中国科幻提高到世界级水平
作为三体中非常重要的角色,智子(Sophon)是将九维的质子进行二维展开,通过电路蚀刻改造成超级计算机后,再转回到微观的十一维来监控人类的一举一动,并利用量子纠缠实现瞬时通信报告给4光年之外的三体文明。说白了智子是三体文明部署在地球的AI实时远程监控和管理平台。
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务
1.3 DataSophon主要特性
① 快速部署,可快速完成300个节点的大数据集群部署
② 兼容复杂环境,极少的依赖使其很容易适配各种复杂环境
③ 监控指标全面丰富,基于生产实践展示用户最关心的监控指标
④ 灵活便捷的告警服务,可实现用户自定义告警组和告警指标
⑤ 可扩展性强,用户可通过配置的方式集成或升级大数据组件
1.4 整体架构
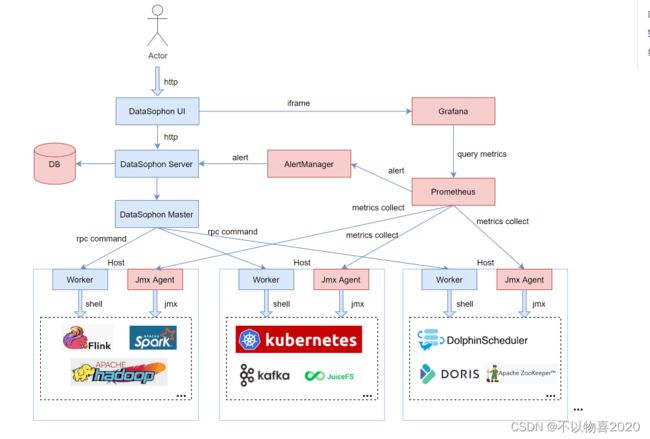
1.5 集成组件
各集成组件均进行过兼容性测试,并稳定运行于300+个节点规模的大数据集群,日处理数据量约4000亿条。在海量数据下,各大数据组件调优成本低,平台默认展示用户关心和需要调优的配置。
| 序号 | 名称 | 版本 | 描述 |
|---|---|---|---|
| 1 | HDFS | 3.3.3 | 分布式大数据存储 |
| 2 | YARN | 3.3.3 | 分布式资源调度与管理平台 |
| 3 | ZooKeeper | 3.5.10 | 分布式协调系统 |
| 4 | FLINK | 1.15.2 | 实时计算引擎 |
| 5 | DolphoinScheduler | 3.1.1 | 分布式易扩展的可视化工作流任务调度平台 |
| 6 | StreamPark | 1.2.3 | 流处理极速开发框架,流批一体&湖仓一体的云原生平台 |
| 7 | Spark | 3.1.3 | 分布式计算系统 |
| 8 | Hive | 3.1.0 | 离线数据仓库 |
| 9 | Kafka | 2.4.1 | 高吞吐量分布式发布订阅消息系统 |
| 10 | Trino | 367 | 分布式Sql交互式查询引擎 |
| 11 | Doris | 1.1.5 | 新一代极速全场景MPP数据库 |
| 12 | Hbase | 2.4.16 | 分布式列式存储数据库 |
| 13 | Ranger | 2.1.0 | 权限控制框架 |
| 14 | ElasticSearch | 7.16.2 | 高性能搜索引擎 |
| 15 | Prometheus | 2.17.2 | 高性能监控指标采集与告警系统 |
| 16 | Grafana | 9.1.6 | 监控分析与数据可视化套件 |
| 17 | AlertManager | 0.23.0 | 告警通知管理系统 |
2 环境准备
2.0 DataSophon安装包
链接:https://pan.baidu.com/s/1QWTMadCGLiAL-XqeS6AygQ
提取码:2gd2
选择需要安装的DataSophon版本,并选择对应的datasophon-manager版本。本文以最新的DataSophon-1.1.1版本为例。
2.1 网络要求
要求各机器各组件正常运行提供如下的网络端口配置:
| 组件 | 默认端口 | 说明 |
|---|---|---|
| DDHApplicationServer | 8081、2551、8586 | 8081为http server端口,2551为rpc通信端口,8586为jmx端口 |
| WorkerApplicationServer | 2552、9100、8585 2552 | rpc通信端口,8585为jmx端口,9100为主机数据采集器端口 |
| nginx | 8888 | 提供 UI 端通信端口 |
注:
① DDHApplicationServer为API接口层即web后端,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。
② WorkerApplicationServer负责执行DDHApplicationServer发送的指令,包括服务安装、启动、停止、重启等指令。
2.2 配置hosts
大数据集群所有机器需配置主机host。
配置主机名: hostnamectl set-hostname 主机名
配置/etc/hosts文件
2.3 关闭防火墙
2.4 集群免密
部署机器中,DataSophon节点以及大数据服务主节点与从节点之间需免密登录。
配置免密
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
集群之间完成免密
ssh-copy-id -i ~/.ssh/id_rsa.pub root@主机
2.5 环境要求
Jdk环境需安装。建议mysql版本为5.7.X,并关闭ssl。
2.6 创建目录
mkdir -p /opt/datasophon/DDP/packages
将下载的部署包上传到/opt/datasophon/DDP/packages目录下,作为项目部署包仓库地址。
注:需要将默认安装包建立在这个目录下,否则会报找不到目录错,如下:

3 部署
3.1 部署mysql
注意需关闭mysql ssl功能。在部署过程中,部分组件会执行sql生成库表,不同环境的mysql在配置上存在差异,可根据sql执行情况,变更mysql配置。
3.1.1 关闭ssl
#使用如下命令查看ssl是否关闭,如果have_ssl的值为YES,说明SSL已经开启
SHOW VARIABLES LIKE '%ssl%';

修改配置文件my.cnf,在MySQL的配置文件my.cnf中加入以下内容:
#disable_ssl
skip_ssl
这个配置的作用是告诉MySQL不要使用SSL协议。在修改配置文件之前,最好备份一下,以免出错后无法恢复。
重启mysql服务
修改了my.cnf文件之后,需要重启MySQL才能使修改生效。可以使用以下命令重启MySQL:
service mysqld restart
再次查看,可以发现此时have_ssl值为DISABLED

3.1.2 执行初始化脚本
执行如下数据库脚本:
CREATE DATABASE IF NOT EXISTS datasophon DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to datasophon@"%" identified by 'datasophon' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'datasophon'@'%';
FLUSH PRIVILEGES;
执行datasophon-manager安装目录sql目录下datasophon.sql,创建数据表。
source datasophon.sql
3.2 解压
在安装目录下解压datasophon-manager-{version}.tar.gz,解压后可以看到如下安装目录:
tar -zxvf datasophon-manager-1.1.1.tar.gz

bin:启动脚本git
conf :配置文件
lib :项目依赖的jar包
logs:项目日志存放目录
jmx:jmx插件
3.3 安装并配置nginx
注:1.1.1之前的版本需要执行该步操作,需要配置nginx。1.1.1及以后版本可以跳过该步骤
3.3.1 安装依赖包
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel
3.3.2 下载并解压
#创建一个文件夹
cd /usr/local
mkdir nginx
cd nginx
#下载tar包
wget http://nginx.org/download/nginx-1.13.7.tar.gz
tar -xvf nginx-1.13.7.tar.gz
3.3.3 安装nginx
#进入nginx目录
cd /usr/local/nginx/nginx-1.13.7
#执行命令 考虑到后续安装ssl证书 添加两个模块
./configure --with-http_stub_status_module --with-http_ssl_module
#执行make命令
make
#执行make install命令
make install
3.3.4 启动nginx服务
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
看到如下页面说明nginx安装成功

3.3.5配置nginx.conf
# 打开配置文件
vim /usr/local/nginx/conf/nginx.conf
注意:这里需要获取前端配置包dist.zip并解压
新增配置
server {
listen 8888;# 访问端口(自行修改)
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/local/nginx/dist; # 前端解压的 dist 目录地址(自行修改)
index index.html index.html;
}
location /ddh {
proxy_pass http://doris-1:8081; # 接口地址(自行修改)
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x_real_ipP $remote_addr;
proxy_set_header remote_addr $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 30s;
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
3.3.6 重启nginx
/usr/local/nginx/sbin -s reload
3.4 修改配置
修改 conf 目录下的application.yml 配置文件中数据库链接配置:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql:192.168.5.189:3306/datasophon?useUnicode=true&characterEncoding=utf-8
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver

3.4 启动服务
#启动
sh bin/datasophon-api.sh start api
#停止
sh bin/datasophon-api.sh stop api
#重启
sh bin/datasophon-api.sh restart api
部署成功后,可以进行日志查看,日志统一存放于logs文件夹内:
logs/
├── ddh-api.log
├── ddh-api-error.log
|—— api-{hostname}.out

3.5 访问页面
访问前端页面地址,接口ip(自行修改) [http://192.168.xx.xx:8081/ddh,默认用户名和密码为admin/admin123

4 创建集群
登录进入系统页面后在集群管理页面创建集群,DataSophon支持多集群管理和授予用户集群管理员权限
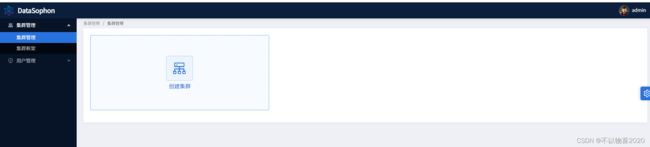
点击【创建集群】,输入集群名称,集群编码(集群唯一标识),集群框架。

创建成功后点击【配置集群】:
根据提示,输入主机列表(注意:主机名需与在准备环境中hostnamectl set-hostname 设置的主机名一致),ssh用户名默认为root和ssh端口默认为22。

配置完成后,点击【下一步】,系统开始链接主机并进行主机环境校验。

主机环境校验成功后点击【下一步】,主机agent分发步骤将自动分发datasophon-worker组件,并启动WorkerApplicationServer。

主机管理Agent分发完成后,点击【下一步】,开始部署服务。
初始化配置集群先选择部署AlertManager,Grafana和Prometheus三个组件。

点击【下一步】,分配AlertManager,Grafana和Prometheus服务的master服务角色部署节点,此三个组件需部署在同一台机器上。

点击【下一步】,分配AlertManager,Grafana和Prometheus服务的worker与client服务角色部署节点,没有worker和client服务角色的可以跳过之间点击【下一步】。

修改各服务配置。系统已给出默认配置,大部分情况下无需修改。

点击【下一步】开始服务安装,可实时查看服务安装进度。
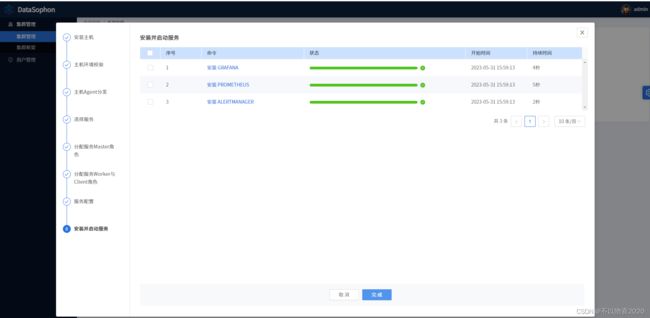
点击【完成】,在集群管理页面点击【进入】,即可进入集群服务组件管理页面。

5 添加服务
5.1 安装ZK
选择添加服务,选择zk
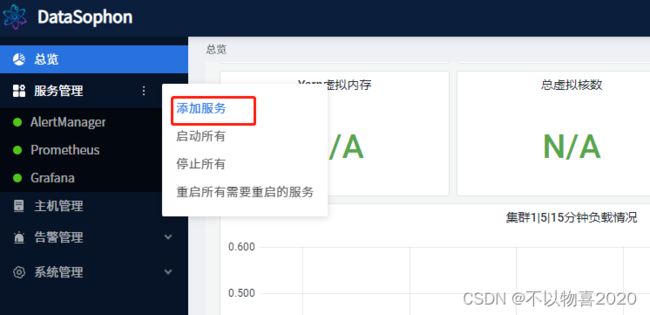
分配ZooKeeper master服务角色部署节点,zk需部3台或5台。

Zk没有worker与client服务角色,直接点击【下一步】跳过。
根据实际情况修改Zk服务配置。
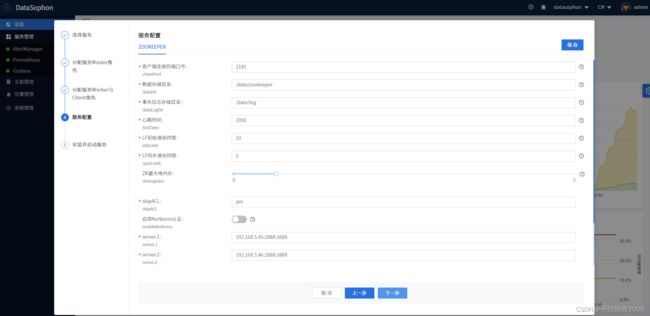
点击【下一步】,进行zk服务安装

安装成功后即可查看Zookeeper服务总览页面。

5.2 安装HDFS
部署HDFS,其中JournalNode需部署三台,NameNode部署两台,ZKFC和NameNode部署在相同机器上。如下图
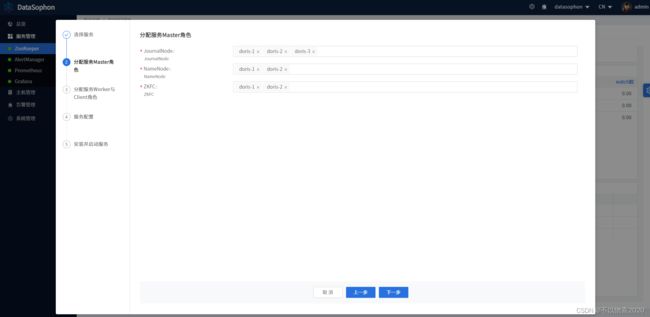
点击【下一步】,选择DataNode部署节点。
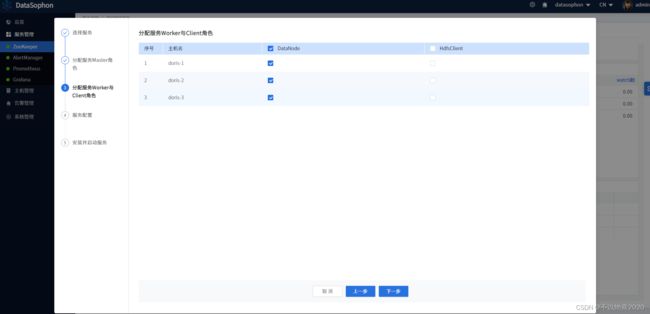
根据实际情况修改配置,例如修改DataNode数据存储目录。

点击【下一步】,开始安装Hdfs。
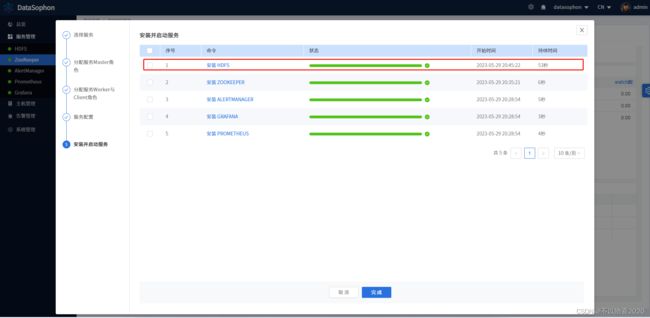
安装成功后,即可查看HDFS服务总览页面。

5.3 添加Yarn服务
部署YARN,其中ResourceManager需部署两台作高可用。如下图:

点击【下一步】,选择NodeManager部署节点。
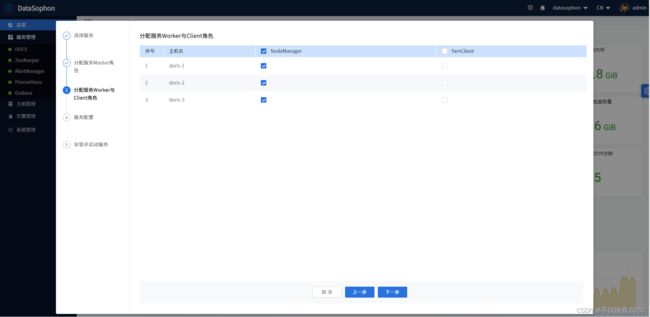
根据实际情况修改配置。

等待安装完成

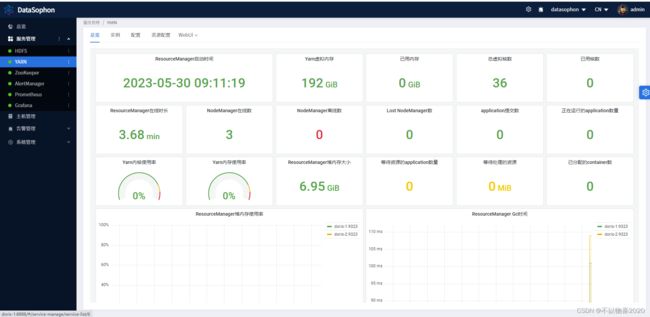
安装成功后,即可查看YARN服务总览页面
5.4 添加hive服务
5.4.1 准备工作
1)在数据库中创建Hive数据库。
CREATE DATABASE IF NOT EXISTS hive DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to hive@"%" identified by 'hive' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%';
FLUSH PRIVILEGES;

5.4.2 安装hive
选择需要安装hiveserver2和metastore角色的节点

选择需要安装hiveclient角色的节点
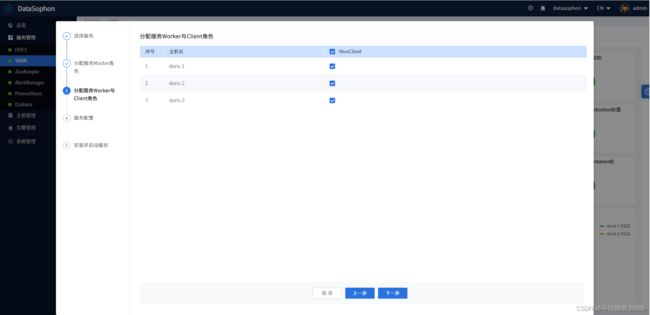
根据实际情况修改配置

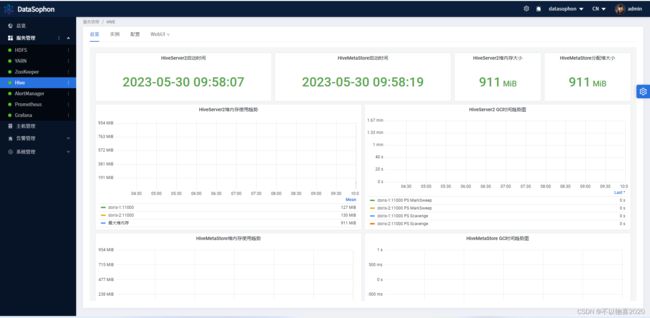
等待安装完成,安装成功后即可查看YARN服务总览页面
5.5 安装dolphinscheduler服务
5.5.1 准备工作
1)初始化DolphinScheduler数据库。
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost' IDENTIFIED BY 'dolphinscheduler';
flush privileges;

2)执行/opt/datasophon/DDP/packages目录下dolphinscheduler_mysql.sql创建dolphinscheduler数据库表
5.5.2 安装dolphinscheduler
添加dolphinscheduler服务

分配api-server/alert-server/master-server/worker-server角色

根据实际情况,修改DolphinScheduler配置。

开始安装DolphinScheduler,安装成功后可以看到DolphinScheduler总览页面

可以通过WebUi打开DolphinScheduler页面.
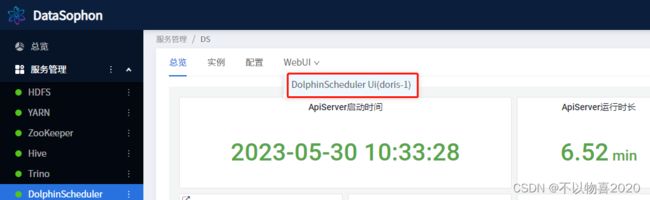

5.6 添加trino
点击【添加服务】,选择Trino。
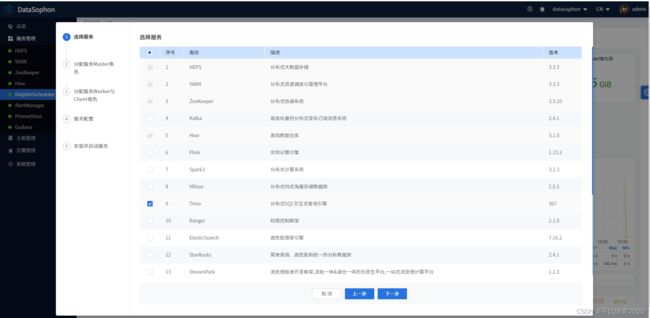
选择TrinoCoordinator。

选择TrinoWorker。注意:TrinoCoordinator和TrinoWorker不要部署在同一台机器上。

注意"Trino最大堆内存","每个查询在单个节点可使用最大内存"这两个配置,其中"每个查询在单个节点可使用最大内存"不可超过"Trino最大堆内存"的80%,“总共可使用最大内存"为"每个查询在单个节点可使用最大内存”* TrinoWorker数.

点击【下一步】,开始安装Trino。等待安装完成,可以看到Trino总览页面

选择trino的webui,可以访问trino的连接


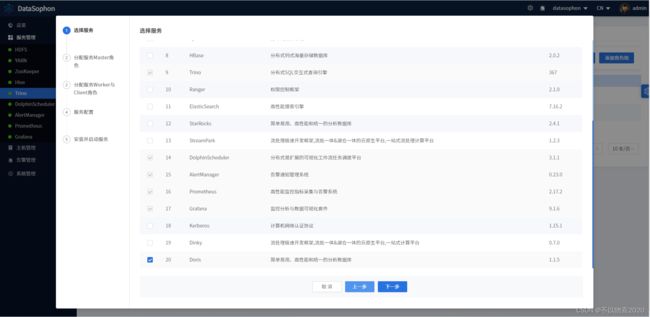
5.7 添加doris服务
点击【添加服务】,选择Doris。
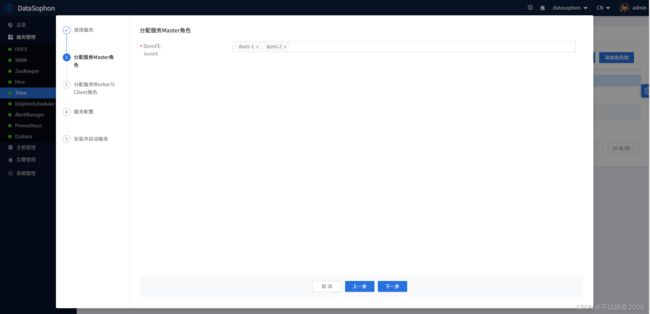
分配FE服务角色部署节点。
分配BE服务角色部署节点。

根据需要修改Doris配置,其中FE优先网段和BE优先网段需要配置,如配置成172.31.86.0/24
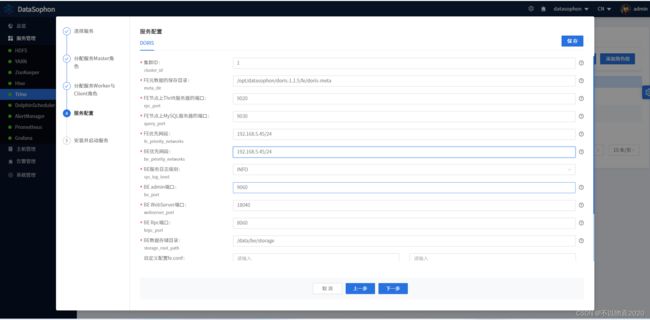
点击【下一步】,开始安装Doris。

5.8 安装kafka

选择安装kafka服务broker角色的节点

根据实际情况调整Kafka参数。

Kafka安装成功后,即可在Kakfa服务总览页查看Kafka详情。

5.9 安装ranger
创建ranger数据库
CREATE DATABASE IF NOT EXISTS ranger DEFAULT CHARACTER SET utf8;
grant all privileges on *.* to ranger@"%" identified by 'ranger' with grant option;
GRANT ALL PRIVILEGES ON *.* TO 'ranger'@'%';
FLUSH PRIVILEGES;

点击【添加服务】,选择Ranger。
选择RangerAdmin部署节点。

输入数据库root用户密码,数据库地址,Ranger数据用户密码等配置信息。

安装成功后,即可在Kakfa服务总览页查看Ranger详情。

5.10 安装StreamPark
初始化StreamPark数据库。
CREATE DATABASE streampark DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON streampark.* TO 'streampark'@'%' IDENTIFIED BY 'streampark';
GRANT ALL PRIVILEGES ON streampark.* TO 'streampark'@'localhost' IDENTIFIED BY 'streampark';
flush privileges;

执行/opt/datasophon/DDP/packages目录下streampark.sql创建streampark数据库表。
use streampark;
source /opt/datasophon/DDP/packages/streampark.sql
分配streampark角色

根据实际情况修改配置。

安装成功后可查看StreamPark总览页面,可通过WebUi跳转到StreamPark用户页面。
还有其他组件,如spark/flink/hbase/elasticsearch等,这里就不再一一例举安装了,感兴趣的小伙伴可以自己上手试一试。
6 多集群部署
DataSophon支持部署和管理集群,在管理页面点击创建新的集群,输入集群id等信息

部署其他集群的节点同样需要上述2.1-2.5的环境准备。
6.1 扫描节点和分发安装包
输入需要安装集群的节点ip


分发worker安装包

6.2 选择需要安装的服务

6.3 分配角色


6.4 确认服务配置参数
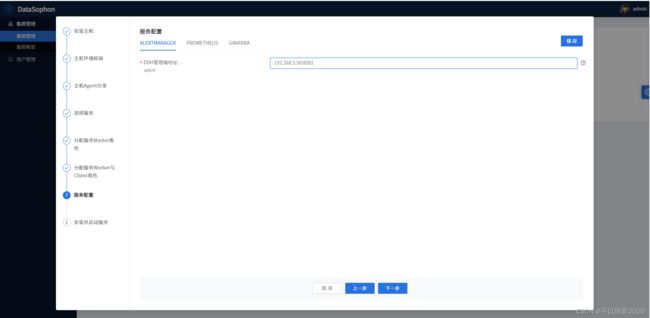
6.5 安装服务
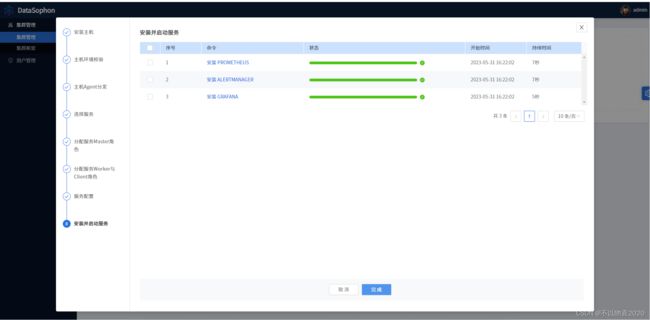
6.6 进入集群2
安装成功之后,进入集群2查看总览页面


6.7 集群2中添加服务
在集群2中添加zk/kafka/doris服务
zk页面总览

kafka页面总览

doris页面总览

6.8 集群间切换
可以选择不同的集群id,查看对应不同集群的节点信息、组件安装信息、告警信息等
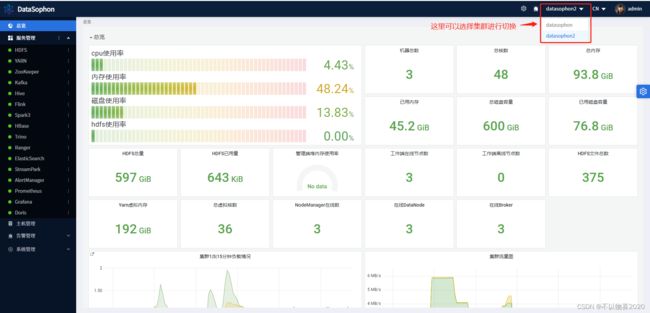
不同集群安装的服务和节点均可不一致:
集群1主机管理

集群2主机管理
