python读取.txt、.dat等文件,将其中特定内容存到其他文件
我想要用的数据存在一个.dat文件中,但是这个文件中除了我想要的数据还有很多其他杂乱的内容,所以需要有一个寻找我想要内容的过程,见下图,我想要的是图中标亮部分及以后的数据;我需要将这些数据按顺序读出,并将其转换成数值类型,然后再按顺序写入csv文件。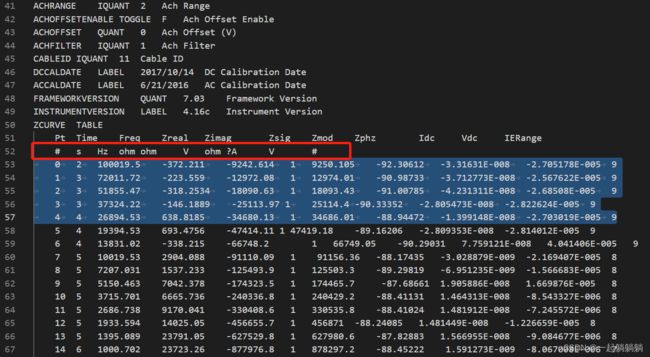 首先分析一下思路,这个.dat文件可以直接用python打开读取内容,如下图所示,所以不用另外进行格式转换;
首先分析一下思路,这个.dat文件可以直接用python打开读取内容,如下图所示,所以不用另外进行格式转换;
可以通过关键字来查找到我需要的数据的位置,比如我这个文件中有一行表示单位的字符(红框),并且在该文件中独一无二,就可以作为关键字;
找到我需要的数据的位置后,需要把数据读取出来,可以看到文件中两个数据间是用tab或者space隔开,可以用这个来进行数据的识别;
两个tab间就是一个完整的数据,因为是.dat格式,里面的内容都是str格式,相当于每一个数字和每一个空格都是一个字符(后面会进行验证),以" 100019.5 "为例,检测到tab,将后面的‘1’存入一个变量a中,‘0’、‘0’....‘5’依a中,因为在python中字符串可以直接相加,所以直接可以:a+'0'这样来相加;
这样把数据完整的取出来后,这时的数据还是str格式的,所以需要先将其转换成float格式,再存入到csv文件中;
这就是一个完整的过程,下面来看具体实现。
fp=open('171017-1656_#23.DTA')
lines = fp.readlines()
fp.close()
for x in lines:
print(x)
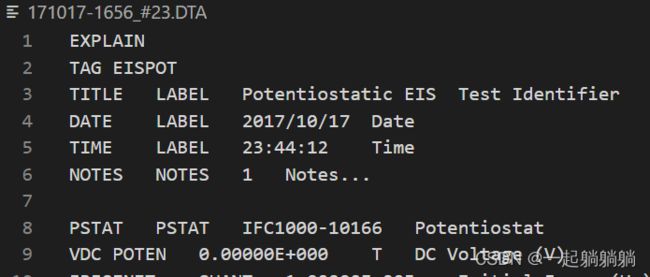
左图是函数输出,右图是打开的.dat,可以看出内容没有错乱,可以正常读取。
接下来找关键字的位置来找到我需要的数据,原文件比较大,为方便实验展示,我新建了一个小的456.dat文件。
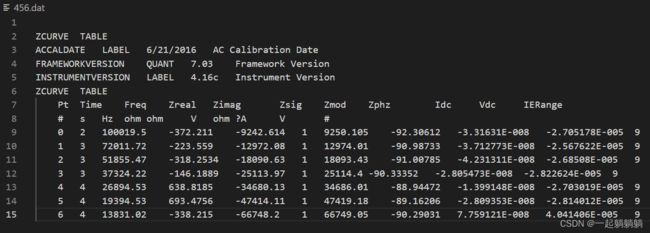
先用readlines函数读取全部内容到内存,并输出一下,看看是什么格式,如果这一步遇到编码格式错误的问题,请看(47条消息) UnicodeDecodeError: ‘‘ codec can‘t decode byte 0xb0 in position : invalid start byte,批量读取不同编码文件的解决方法_一起躺躺躺的博客-CSDN博客
fp=open('456.dat')
lines = fp.readlines()
print(lines)
fp.close()
和文件中内容对应看,可以看出再lines中的想要作为关键字的内容,复制出来作为关键字,并且我需要的是关键字后面的内容,可以设置一个状态变量,找到之前为0,找到后为1
t = 0
for line in lines:
if t == 1:
print(line)
print(len(line))
else:
if line == "\t#\ts\tHz\tohm\tohm\t\tV\tohm\t?A\t\tV\t\t#\n":
t = 1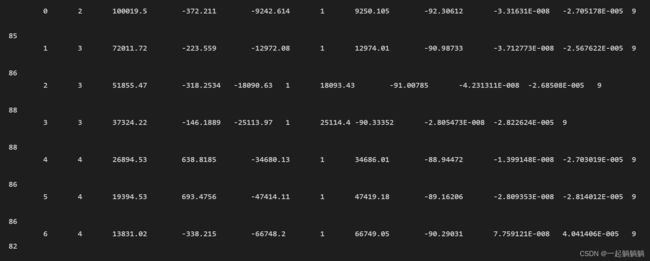
并且可以看到每一行的长度,明显是一个数字一个字符,可以输出看一下,这个时候的line是最后一行
for x in line:
print(x) 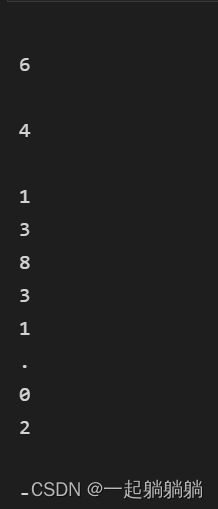
对照可以看出每一个字符都是单独存储,没有字符串,并且有tab和空格的存在,下一步就是准确读出里面的数据
为方便实验,我们先对一行数据进行处理。每一行数据都是11个,很规整,建立一个长度为11的列表,并对其进行初始化,相邻的两个tab或者space间的数据是一个完整的数据,可以设置两个状态变量,t1代表前一个字符的内容,t2代表当前字符内容,0表示为str,1表示为space或者tab
a = [i for i in range(11)]
t1 = 1 #0表示为str,1表示为空
t2 = 1
i = 0
for x in line:
if t1 == 0 and t2 == 1: #01 str-空 我这个数据文件当中每一行开头是tab,所以我选01
#状态的时候i+1,根据实际情况来改变
i += 1
t1 = t2
if x !=' ' and x != ' ':
t2 = 0
else: t2 = 1
if t1 ==1 and t2 == 0 : #10 空-str
a[i] = x
else :
if t1 ==0 and t2 == 0: #00 str-str
a[i] += x
print(a)![]()
和文件对照,没有任何错误,加上关键字的寻找,看在全部数据上是否适用
fp=open('171017-1656_#23.DTA')
lines = fp.readlines()
fp.close()
i = 0
j = 0
a = [[0] * 11 for i in range(50)]
t = 0
for line in lines:
t1 = 1
t2 = 1
j = 0
if t == 1:
for x in line:
if t1 == 0 and t2 == 1 : #01 str-空
j += 1
t1 = t2
if x !=' ' and x != ' ': #如果x为str,t2等于0
t2 = 0
else: t2 = 1 #如果x为空,t2=1
if t1 == 1 and t2 == 0 : #10 空-str
a[i][j] = x
else :
if t1 == 0 and t2 == 0: #00 str-str
a[i][j] += x
i += 1
else:
if line == "\t#\ts\tHz\tohm\tohm\t\tV\tohm\t?A\t\tV\t\t#\n":
t = 1
for i in range(len(a)):
print(a[i])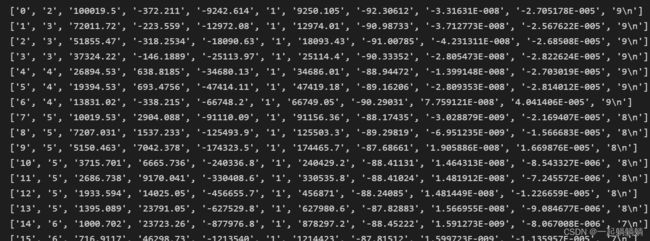
和文件对照是没有任何问题的,接下来只需要将其转换成float格式接可以了
for w in range(len(a)):
for e in range(len(a[0])):
a[w][e] = float(a[w][e])
for i in range(len(a)):
print(a[i])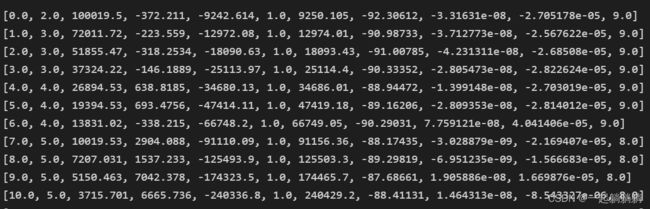
转换成功,接下来写入csv文件,写入其他格式的文件也一样
import csv
filelina =['Pt','Time','Freq','Zreal','Zimag','Zsig','Zmod','Zphz','Idc','Vdc','IERange']
f = open('bbb.csv', 'w', encoding='UTF8', newline='')
writer = csv.writer(f)
writer.writerow(filelina)
for i in range(len(a)):
writer.writerow(a[i])
f.close()因为文件中标题和数据之间有一行多余的表示单位的字符,所以就没有把标题读取进来,需要在写入的时候加上这个标题,运行结果如下

完成任务。