Linux数据处理三剑客
目录:
- Linux 三剑客之 grep
- linux三剑客之awk
- linux三剑客之sed
- linux三剑客与管道使用
- 【实战】三剑客实战之nginx日志分析实战
- 【实战】三剑客实战之性能、网络统计实战
- linux进阶命令
- linux环境配置
- Linux与Bash编程实战
1.Linux 三剑客之 grep
内容检索:(注意:pattern 是模式参数,可以是一个正则表达式或简单的文本匹配。)
获取行 grep pattern file:(这个命令用于在文件中搜索匹配给定模式(pattern)的行。模式可以是正则表达式或简单的文本匹配。该命令返回所有匹配的行,不进行任何排序或过滤。)

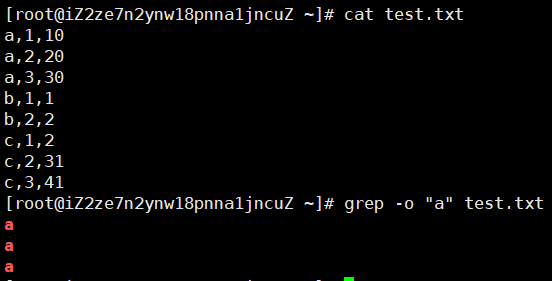
获取内容 grep -o pattern file (这个命令与上一个命令类似,但它只返回匹配模式的行,而不是整个行。这意味着它会返回匹配模式的文本行,而不是包含这些文本的行。)
获取上下文 grep -A -B -C pattern file(将返回匹配模式的行,并显示匹配行的前2行和后3行,以及匹配行的上下文(即匹配行的前1行和后1行)。

-C:理解-C参数 ,返回匹配行的前2行,后俩行

文件检索:
递归搜索 grep pattern -r dir/

展示匹配文件名 grep -H pattern file

只展示匹配文件名 grep -l pattern file

范围约束:
忽略大小写 grep -i pattern file

不显示匹配的行 grep -v pattern file

使用扩展正则表达式 grep -E pattern file

文件范围和目录范围约束 grep 111 -r /tmp/demo/ --include "11*"(这个命令将搜索 /tmp/demo/ 目录及其子目录中以 111 开头的文件,并输出包含文本 111 的行。)

进程检索:
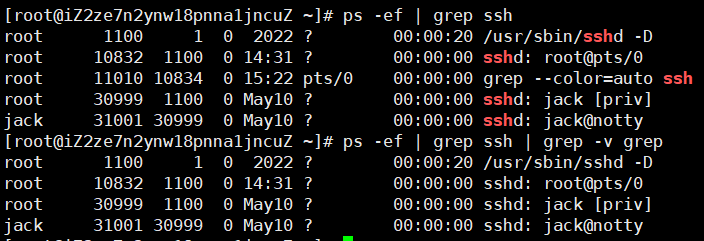
进程过滤场景比较特殊,需要注意 grep 本身会开启新进程,所以需要单独过滤掉 grep 进程
ps -ef | grep ssh
ps -ef | grep ssh | grep -v grep
2.linux三剑客之awk
awk简介:
awk是一个强大的文本处理工具,它可以用于处理各种类型的文本数据,包括文件、管道、标准输入等。awk命令可以对文本进行逐行处理,并且可以根据指定的规则对文本进行格式化和输出。
awk命令的主要功能包括:
- 逐行处理文本:awk命令可以从文件或标准输入中读取文本,并对每一行进行处理。可以使用awk命令对每一行进行操作,例如查找、替换、删除等。
- 数据格式化:awk命令可以对文本进行格式化输出,例如按照指定的格式对文本进行分行、缩进、对齐等。
- 变量和条件语句:awk命令可以使用变量和条件语句来控制处理流程,例如根据指定的条件对文本进行过滤、选择、排序等操作。
- 函数和宏:awk命令可以使用自定义函数和宏来扩展其功能,例如定义自定义函数来处理特定的文本操作。
awk命令通常与其他命令和工具结合使用,例如cat、find、ls等,以便更有效地处理大规模的文本数据。awk命令可以用于各种应用程序,包括数据处理、数据分析、文件格式转换、文本解析等。
awk 基本语法:
- awk 是 linux 下的一个命令,同时也是一种语言解析引擎
- awk 具备完整的编程特性。比如执行命令,网络请求等
- 精通 awk,是一个 linux 工作者的必备技能
- 语法
awk 'pattern{action}'
awk 上下文变量:
- 开始 BEGIN 结束 END
- 行数 NR
- 字段与字段数 $1 $2 .. $NF NF
- 整行 $0
- 字段分隔符 FS
- 输出数据的字段分隔符 OFS
- 记录分隔符 RS
- 输出字段的行分隔符 ORS
字段变量用法:
- -F 参数指定字段分隔符,可以用|指定多个- 多分隔符 -F ‘<|>’
- BEGIN{FS=“_”} 也可以表示分隔符
- $0 代表当前的记录
- $1 代表第一个字段
- $N 代表第 N 个字段
- $NF 代表最后一个字段
- $(NF-1) 代表倒数第二个字段
pattern 表达式:
- 正则匹配
$1~/pattern//pattern/ - 比较表达式
$2>2$1=="b"
awk pattern 匹配表达式案例:
- 开始和结束
awk 'BEGIN{}END{}' - 正则匹配
- 整行匹配
awk '/Running/' - 字段匹配
awk '$2~/xxx/'
- 整行匹配
- 行数表达式
- 取第二行
awk 'NR==2' - 去掉第一行
awk 'NR>1'
- 取第二行
- 区间选择
awk '/aa/,/bb/'awk '/1/,NR==2'
action 行为表达式 {action}:
- 打印
{print $0}{print $2} - 赋值
{$1="abc"} - 处理函数
- 原始内容 $0
- 更新后内容
{$1=$1;print $0}
单行转多行:
echo 1:2:3 | awk 'BEGIN{RS=":"}{print $0}' 1 2 3
多行变单行:
echo '1 2 3' | awk 'BEGIN{RS="";FS="\n";OFS=":"}{$1=$1;print $0}' 1:2:3
echo '1 2 3' | awk 'BEGIN{ORS=":"}{$1=$1;print $0}' 1:2:3:
计算平均数:
echo '1,10 2,20 3,30' | awk 'BEGIN{total=0;FS=","}{total+=$2}END{print total/NR}' 20
awk 的词典结构 array:
- array 是稀疏矩阵,类似 python 的词典类型
- 统计多家机构的营业额
- 统计多家机构的营业额平均值
echo 'a, 1, 10 a, 2, 20 a, 3, 30 b, 1, 5 b, 2, 6 b, 3, 7' | awk '{data[$1]+=$3} END{for(k in data) print k,data[k]}' a, 60 b, 18 echo 'a, 1, 10 a, 2, 20 a, 3, 30 b, 1, 5 b, 2, 6 b, 3, 7' | awk '{data[$1]+=$3;count[$1]+=1;} END{for(k in data) print k,data[k]/count[k]}' a, 20 b, 6
3.linux三剑客之sed
4.linux三剑客与管道使用
5.【实战】三剑客实战之nginx日志分析实战
6.【实战】三剑客实战之性能、网络统计实战
7.linux进阶命令
8.linux环境配置
9.Linux与Bash编程实战