分布式事务应用场景及案例分享
分布式事务应用场景及案例分享
参考文章:
https://blog.csdn.net/JavaShark/article/details/125350886
https://zhuanlan.zhihu.com/p/183753774
https://blog.csdn.net/xhaimail/article/details/115601013
https://blog.csdn.net/weixin_42886699/article/details/122356911
感谢以上博主的分享
1、事务的基础知识
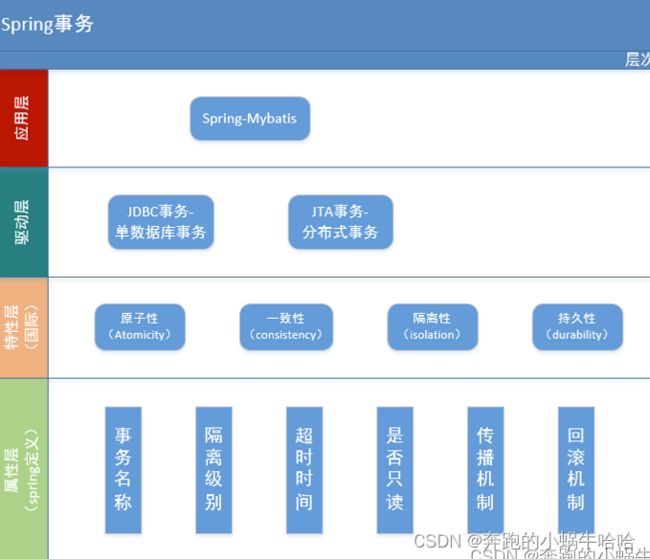
--事务是指数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成
Java事务的类型有三种:JDBC事务、JTA(Java Transaction API)事务和容器事务。
--JDBC的事务操作用法比较简单,适合于处理同一个数据源的操作。
--JTA事务相对复杂,可以用于处理跨多个数据库的事务,是分布式事务的一种解决方案。
--常见的容器事务如Spring事务,容器事务主要是J2EE应用服务器提供的,容器事务大多是基于JTA完成。
--事务的6个属性:
1)事务名称:用户可手动指定事务的名称,当多个事务的时候,可区分使用哪个事务。对应注解中的@Transactional(value = "",transactionManager = "")
2)隔离级别: 为了解决数据库容易出现的问题,分级加锁处理策略。对应注解中的isolation
3)超时时间: 定义一个事务执行过程多久算超时,以便超时后回滚。可以防止长期运行的事务占用资源。对应注解中的timeout
4)是否只读:表示这个事务只读取数据但不更新数据, 这样可以帮助数据库引擎优化事务。对应注解中的readOnly
5)传播机制: 对事务的传播特性进行定义,共有7种类型。对应注解中的propagation
6)回滚机制:定义遇到异常时回滚策略。对应注解中的属性rollbackFor等
--七种传播机制:

--四种隔离级别:
1)读未提交(Read Uncommitted)可能读取其它事务未提交的数据。(-脏读问题(脏读+不可重复读+幻读))
2)读已提交(Read Committed)一个事务只能看见已经提交事务所做的改变。(其他事务可能会有新的commit,所以同一select可能返回不同结果-不可重复读问题)
3)可重复读(Repeatable Read)
4)可串行化(Serializable)这是最高的隔离级别,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争,主要用于分布式事务。
2、什么是分布式事务
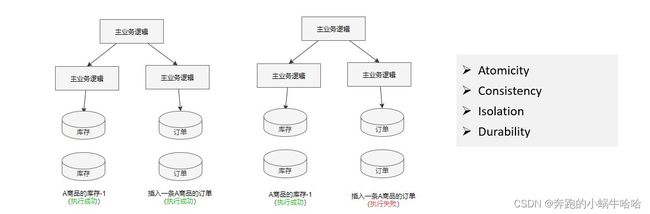
分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性
--CAP定理:
又被称为布鲁尔定理,指出在分布式系统中,不可能同时满足以下三点:
1)C(一致性):各个数据备份的数据内容要保持一致且都为最新数据
2)A(可用性):保证每个请求不管成功或者失败都有响应
3)P(分区容错性):系统中任意信息的丢失或失败不会影响系统的继续运作
一个分布式系统不可能同时很好的满足这三个点,最多只能同时较好的满足两个
--BASE理论
Base是基本可用(Basical Availabel)、软状态(Soft State)和最终一致性(Eventually consistent)的缩写。
BASE理论是对CAP理论中AP的一个扩展,通过牺牲强一致性,来获得可用性,当出现故障,允许部分不可用,但要保证核心功能可用,允许数据在一段时间内是不一致的,但需要采用适当的方式来使系统达到最终一致性。
1)基本可用(Basically Available)当分布式系统出现故障时,允许损失部分可用性,保证核心模块的可用性。
2)软状态(Soft state)软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
3)最终一致性(Eventually consistent)系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
3、分布式事务应用场景
1)服务内跨数据库:在同一个方法内,访问两个或两个以上的数据库
Java事务是通过Connection对象控制的。不同的数据库,是不同的数据库链接,通过不同的Connection对象实现。传统数据库事务无法实现事务控制,需要引入事务协调者的概念。这个场景中分布式体现在数据库的部署上
2)跨内部服务
一个服务通过微服务框架或者RPC调用其他的服务,多个子服务需要同时成功或失败。每个子服务都有自己的持久化方式,不一定是数据库,体现事务的持久性。每个子服务部署在不同的服务容器中,不同的服务容器部署在不同的服务器节点上。这个场景中分布式体现在服务(或应用)的部署上。
3)跨外部服务
服务的具体实现在我们控制范围之外。我们不能限制其实现语言,不能要求指定方法上加标注(注解)。这个场景中,我们只能在通信协议层面做约定,是最彻底的分布式场景
4、分布式事务解决方案
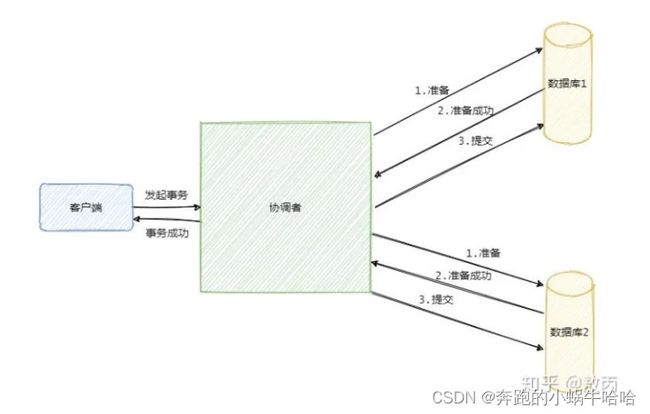
1)两阶段提交(Two-phase Commit,2PC)--数据库层面
在该分布式系统中,其中 需要一个系统担任协调器的角色,其他系统担任参与者的角色。主要分为Commit-request阶段和Commit阶段。
请求阶段:首先协调器会向所有的参与者发送准备提交或者取消提交的请求,然后会收集参与者的决策。
提交阶段:协调者会收集所有参与者的决策信息,当且仅当所有的参与者向协调器发送确认消息时协调器才会提交请求,否则执行回滚或者取消请求。
--缺陷:
同步阻塞:所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
单点故障:一旦协调器发生故障,系统不可用。
数据不一致:当协调器发送commit之后,此时网络发生异常,只有部分的参与者收到commit消息,事务执行成功,而有的没有收到,处于阻塞状态,这段时间会使系统数据不一致。
不确定性:任意一个节点失败就会导致整个事务失败,没有完善的容错机制。当协调器发送commit之后,并且此时只有一个参与者收到了commit,那么当该参与者与协调器同时宕机之后,重新选举的协调器无法确定该条消息是否提交成功。
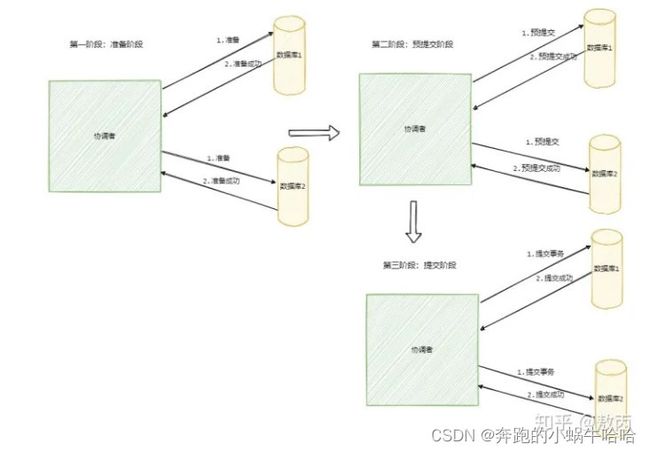
2)三阶段提交(Three-phase Commit,3PC)--数据库层面
3PC 的出现是为了解决 2PC 的一些问题,相比于 2PC 它在参与者中也引入了超时机制,并且新增了一个阶段使得参与者可以利用这一个阶段统一各自的状态。
3PC 包含了三个阶段,分别是准备阶段、预提交阶段和提交阶段,对应的英文就是:CanCommit、PreCommit 和 DoCommit
--参与者超时能带来什么样的影响?
我们知道 2PC 是同步阻塞的,上面我们已经分析了协调者挂在了提交请求还未发出去的时候是最伤的,所有参与者都已经锁定资源并且阻塞等待着。
那么引入了超时机制,参与者就不会傻等了,如果是等待提交命令超时,那么参与者就会提交事务了,因为都到了这一阶段了大概率是提交的;如果是等待预提交命令超时,那该干啥就干啥了,反正本来啥也没干。
然而超时机制也会带来数据不一致的问题,比如在等待提交命令时候超时了,参与者默认执行的是提交事务操作,但是有可能执行的是回滚操作,这样一来数据就不一致了。
从维基百科上看,3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题。
新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
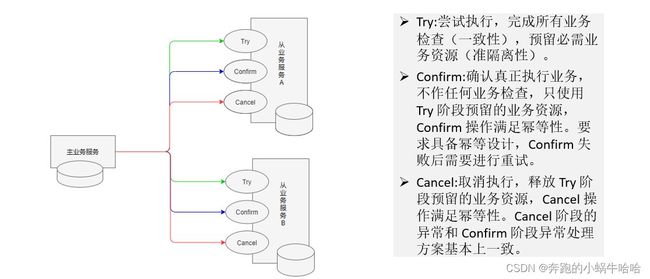
3)补偿事务(TCC)--业务层面
TCC事务是Try、Commit、Cancel三种指令的缩写,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
--Try:指的是预留,即资源的预留和锁定,注意是预留
--Commit:指的是确认操作,这一步其实就是真正的执行了(使用Try阶段预留的业务资源,失败后需要进行重试,需要保证幂等)
--Cancel:指的是撤销操作,可以理解为把预留阶段的动作撤销了(释放Try阶段预留的业务资源,满足幂等)
TCC可以跨数据库、跨不同的业务系统来实现事务
撤销和确认操作的执行可能需要重试,因此还需要保证操作的幂等
--解决了协调者单点:由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
--同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
--数据一致性,有了补偿机制之后,由业务活动管理器控制一致性
案例:
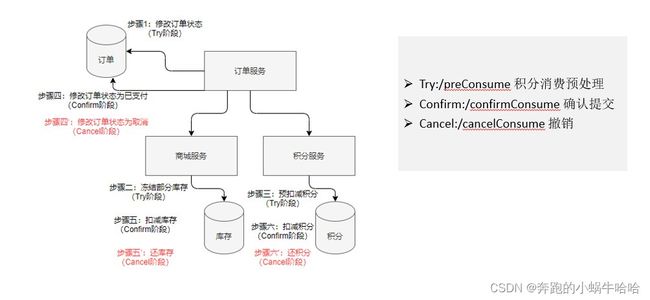
--注意:@LocalTCC 适用于SpringCloud+Feign模式下的TCC
@TwoPhaseBusinessAction 注解try方法
commitMethod指向提交方法,rollbackMethod指向事务回滚方法。seata会根据事务的成功或失败,通过动态代理去帮我们自动调用提交或者回滚
@BusinessActionContextParameter 注解可以将参数传递到二阶段(确认commitMethod/取消rollbackMethod)的方法
BusinessActionContext 便是指TCC事务上下文
--引入依赖:
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>最新版本</version>
</dependency>
--添加seata配置
一、TCC接口代码实现示例:
/**
* 这里定义tcc的接口
* 一定要定义在接口上
* 我们使用springCloud的远程调用
* 那么这里使用LocalTCC便可
*
*/
@LocalTCC
public interface TccService {
/**
* 定义两阶段提交
* name = 该tcc的bean名称,全局唯一
* @param params -入参
* @return String
*/
@TwoPhaseBusinessAction(name = "insert", commitMethod = "commitTcc", rollbackMethod = "cancel")
String insert(@BusinessActionContextParameter(paramName = "params") Map params);
/**
* 确认方法、可以另命名,但要保证与commitMethod一致
* context可以传递try方法的参数
*
* @param context 上下文
* @return boolean
*/
boolean commitTcc(BusinessActionContext context);
/**
* 二阶段取消方法
*
* @param context 上下文
* @return boolean
*/
boolean cancel(BusinessActionContext context);
}
二、Tcc接口的业务实现示例
--注意:
1)在try方法中使用@Transational可以直接通过spring事务回滚关系型数据库中的操作,而非关系型数据库等中间件的回滚操作可以交给rollbackMethod方法处理
2)使用context.getActionContext("params")便可以得到一阶段try中定义的参数,在二阶段对此参数进行业务回滚操作
3)二阶段commitMethod可以空确认
@Slf4j
public class TccServiceImpl implements TccService {
@Autowired
TccDAO tccDAO;
/**
* tcc服务t(try)方法
* 实际业务方法
*
* @param params - name
* @return String
*/
@Override
@Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRED)
public String insert(@RequestBody Map params) {
log.info("------------------> xid = " + RootContext.getXID());
//实际的操作,或操作MQ、redis等
tccDAO.insert(params);
//throw new RuntimeException("服务tcc测试回滚");
return "success";
}
/**
* tcc服务 confirm方法
* 可以空确认
*
* @param context 上下文
* @return boolean
*/
@Override
public boolean commitTcc(BusinessActionContext context) {
log.info("xid = " + context.getXid() + "提交成功");
return true;
}
/**
* tcc 服务 cancel方法
*
* @param context 上下文
* @return boolean
*/
@Override
public boolean cancel(BusinessActionContext context) {
//todo 这里写中间件、非关系型数据库的回滚操作
System.out.println("please manually rollback this data:" + context.getActionContext("params"));
return true;
}
}
4)本地消息表(异步确保)
本地消息表其实就是利用了各系统本地的事务来实现分布式事务。
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
然后再去调用下一个操作,如果下一个操作调用成功了好说,消息表的消息状态可以直接改成已成功。
如果调用失败也没事,会有后台任务定时去读取本地消息表,筛选出还未成功的消息再调用对应的服务,服务更新成功了再变更消息的状态。
本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况。
本地消息表的核心思路就是将分布式事务拆分成本地事务进行处理,在该方案中主要有两种角色:事务主动方和事务被动方。事务主动发起方需要额外新建事务消息表,并在本地事务中完成业务处理和记录事务消息,并轮询事务消息表的数据发送事务消息,事务被动方基于消息中间件消费事务消息表中的事务。
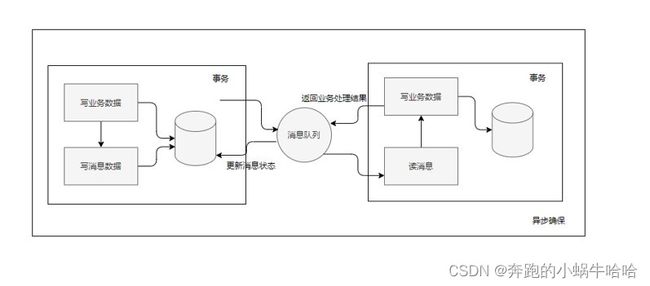
案例:

5)RocketMQ消息事务
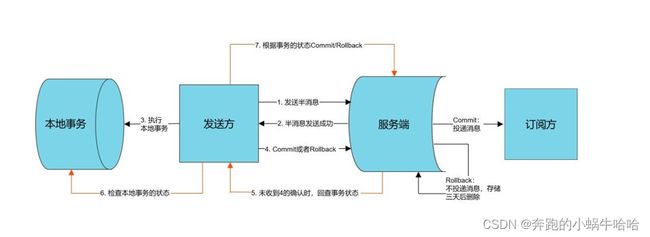
RocketMQ提供的分布式事务功能来确保业务发送方和MQ消息的最终一致性,其本质是通过半消息(prepare消息和commit消息)的方式把分布式事务放在MQ端来处理。
--处理流程:
1)发送方向消息队列 RocketMQ 服务端发送消息。
2)服务端将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功,此时消息为半消息。
3)发送方开始执行本地事务逻辑。
4)发送方根据本地事务执行结果向服务端提交二次确认(Commit 或是 Rollback),服务端收到 Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;服务端收到 Rollback 状态则删除半消息,订阅方将不会接受该消息。
--补偿流程:
5)在断网或者是应用重启的特殊情况下,上述步骤 4 提交的二次确认最终未到达服务端,经过固定时间后服务端将对该消息发起消息回查。
6)发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
7)发送方根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤 4 对半消息进行操作
--RocketMQ的半消息机制的注意事项:
1)根据第六步可以看出他要求发送方提供业务回查接口。
2)不能保证发送方的消息幂等,在ack没有返回的情况下,可能存在重复消息
3)消费方要做幂等处理。
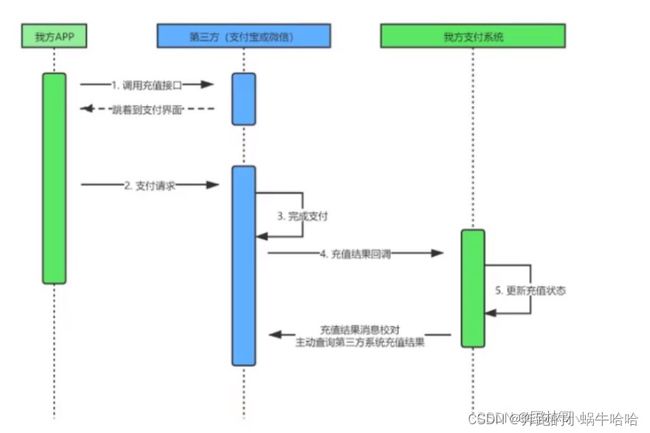
6)最大努力通知
目标:发起通知方通过一定机制最大努力将业务处理结果通知到接收方
本地消息表和事务消息也可以算最大努力,
--就本地消息表来说会有后台任务定时去查看未完成的消息,然后去调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃。这其实算是最大努力了。
--事务消息也是一样,当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者消费不了则会一直重试,到最后进入死信队列。其实这也算最大努力。
所以最大努力通知其实只是表明了一种柔性事务的思想:我已经尽力我最大的努力想达成事务的最终一致了。
适用于对时间不敏感的业务,例如短信通知。
最大努力通知方案,即:你最大努力通知我,我也尽我最大努力去你那里查
7)Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
Seata 为用户提供了 AT、TCC、SAGA 和 XA(二阶段提交、三阶段提交) 事务模式,为用户打造一站式的分布式解决方案
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。但AT模式存在的不足就是 当操作的数据 是共享型数据,会存在脏写的问题,所以如果是 用户独有数据可以使用AT模式。