Spark的安装部署和客户端使用
- 下载Spark
Spark下载地址:http://spark.apache.org/downloads.html
- 通过工具上传Spark压缩包

- 解压Spark
[hadoop@master software]$ tar zxvf spark-2.4.1-bin-hadoop2.7.tgz -C /opt/module/
- 安装Spark
4.1配置Spark
- 进入到Spark安装目录
[hadoop@master software]$ cd /opt/module/spark-2.4.1-bin-hadoop2.7/conf/
- 将slaves.template复制为slaves和spark-env.sh.template复制为spark-env.sh
[hadoop@master conf]$ cp slaves.template slaves
[hadoop@master conf]$ cp spark-env.sh.template spark-env.sh
- 修改slaves文件,将work的hostname输入
[hadoop@master conf]$ vim slaves

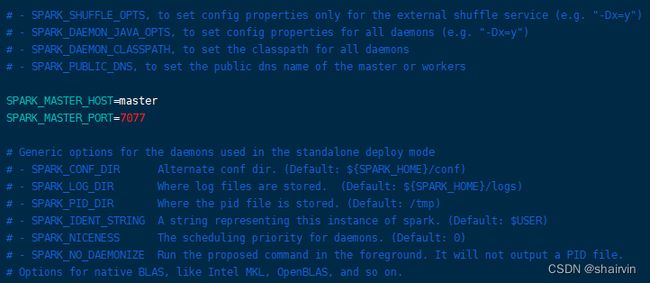
- 修改spark-env.sh文件,添加如下配置
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
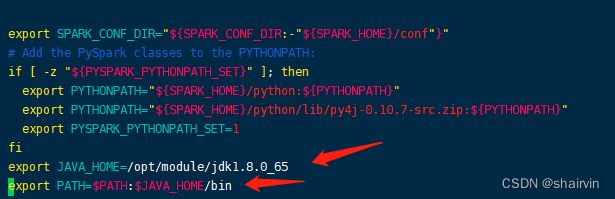
- 修改spark-config.sh文件,添加jdk路径。
[hadoop@master conf]$cd /opt/module/spark-2.4.1-bin-hadoop2.7/sbin
[hadoop@master sbin]$ vim spark-config.sh
export JAVA_HOME=/opt/module/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
- 将spark拷贝到其他的节点上
[hadoop@master module]$ scp -r spark-2.4.1-bin-hadoop2.7/ slave1:/opt/module/
[hadoop@master module]$ scp -r spark-2.4.1-bin-hadoop2.7/ slave2:/opt/module/
- 启动spark
[hadoop@master sbin]$ ./start-all.sh
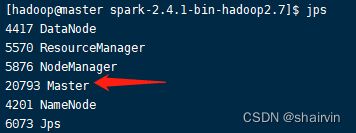
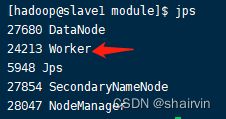
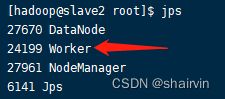
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master:8080/

如果aliver workers为0,jps查看又有worker进程,查看防火墙状态:
systemctl status firewalld.service(为running)
关闭防火墙:systemctl stop firewalld.service
如hadoop用户无法执行该命令,切换用户执行(忘记密码修改passwd username)。
4.2配置Job History Server
- 进入到Spark安装目录的conf
cd /opt/module/spark-2.4.1-bin-hadoop2.7/conf
- 将spark-default.conf.template复制为spark-default.conf
[hadoop@master conf]$ cp spark-defaults.conf.template spark-defaults.conf
- 修改spark-default.conf文件,开启Log:
[hadoop@master conf]$ vim spark-defaults.conf
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory

- 修改spark-env.sh文件,添加如下配置:
[hadoop@master conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/directory"
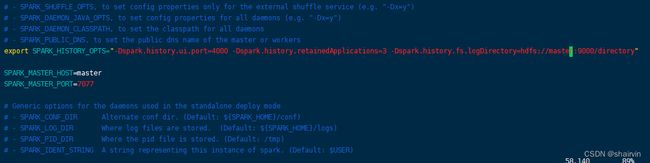
参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=4000 调整WEBUI访问的端口号为4000
spark.history.fs.logDirectory=hdfs://master01:9000/directory 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=3 指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 将配置好的Spark文件拷贝到其他节点上
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ scp -r conf/ slave1:/opt/module/spark-2.4.1-bin-hadoop2.7/
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ scp -r conf/ slave2:/opt/module/spark-2.4.1-bin-hadoop2.7/
- 打开HDFS的服务,并创建directory文件夹
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ start-all.sh
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ hdfs dfs -mkdir /directory
- 启动spark
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ sbin/start-all.sh
- 启动Job History Server
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ sbin/start-history-server.sh

到此为止,Spark History Server安装完毕.
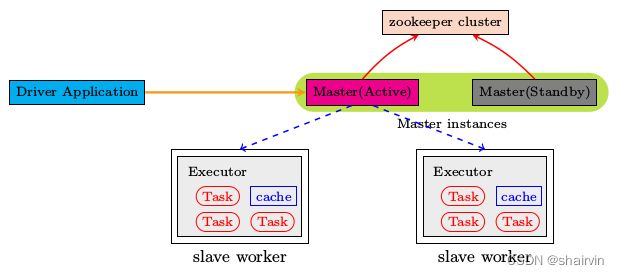
4.3配置Spark HA
集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠(本课程只使用三台服务器,所以将第二个master部署在slave1上,也就是说slave1既是master也是worker),配置方式比较简单:
- 进入到Spark安装目录的conf
cd /opt/module/spark-2.4.1-bin-hadoop2.7/conf
- 安装配置Zookeeper集群,并启动Zookeeper集群
- 停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
[hadoop@master conf]$ vim spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1,slave1,slave2 -Dspark.deploy.zookeeper.dir=/spark"

- 在 master节点上修改slaves配置文件内容指定worker节点
- 将配置文件同步到所有节点。
- 在master01(就是master主机)上执行sbin/start-all.sh脚本,启动集群并启动第一个master节点,然后在master02(在slave1节点上开启)上执行sbin/start-master.sh启动第二个master节点。
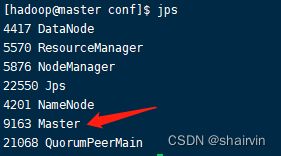

- 程序中spark集群的访问地址需要改成:
spark://master01:port1,master02:port2
- Spark客户端命令
5.1执行第一个spark程序
/opt/module/spark-2.4.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
--executor-memory 512m \
--total-executor-cores 2 \
/opt/module/spark-2.4.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.1.jar \
100

参数说明:
--master spark://master:7077 指定Master的地址
--executor-memory 1G 指定每个executor可用内存为1G
--total-executor-cores 2 指定每个executor使用的cpu核数为2个
(注意数字后面的反斜杠跟数字要留有空格)
该算法是利用蒙特·卡罗算法求PI
5.2 Spark应用提交
一旦打包好,就可以使用bin/spark-submit脚本启动应用了. 这个脚本负责设置spark使用的classpath和依赖,支持不同类型的集群管理器和发布模式:
./bin/spark-submit \
--class
--master
--deploy-mode
--conf
... # other options
[application-arguments]
一些常用选项:
- --class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
- --master: 集群的master URL (如 spark://23.195.26.187:7077)
- --deploy-mode: 是否发布你的驱动到worker节点(cluster) 或者作为一个本地客户端 (client) (default: client)*
- --conf: 任意的Spark配置属性, 格式key=value. 如果值包含空格,可以加引号“key=value”. 缺省的Spark配置
- application-jar: 打包好的应用jar,包含依赖. 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar.
- application-arguments: 传给main()方法的参数
| local |
本地以一个worker线程运行(例如非并行的情况). |
| local[K] |
本地以K worker 线程 (理想情况下, K设置为你机器的CPU核数). |
| local[*] |
本地以本机同样核数的线程运行. |
| spark://HOST:PORT |
连接到指定的Spark standalone cluster master. 端口是你的master集群配置的端口,缺省值为7077. |
| mesos://HOST:PORT |
连接到指定的Mesos 集群. Port是你配置的mesos端口, 缺省是5050. 或者如果Mesos使用ZOoKeeper,格式为 mesos://zk://.... |
| yarn-client |
以client模式连接到YARN cluster. 集群的位置基于HADOOP_CONF_DIR 变量找到. |
| yarn-cluster |
以cluster模式连接到YARN cluster. 集群的位置基于HADOOP_CONF_DIR 变量找到. |
5.3 启动Spark shell
1. 启动spark shell
/opt/module/spark-2.4.1-bin-hadoop2.7/bin/spark-shell \
--master spark://master:7077 \
--executor-memory 2g \
--total-executor-cores 1
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的cluster模式,如果spark是单节点,并且没有指定slave文件,这个时候如果打开spark-shell 默认是local模式
Local模式是master和worker在同同一进程内
Cluster模式是master和worker在不同进程内
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
- 在spark shell中编写WordCount程序
- 首先启动hdfs
- 将Spark目录下的RELEASE文件上传一个文件到hdfs://master:9000/RELEASE
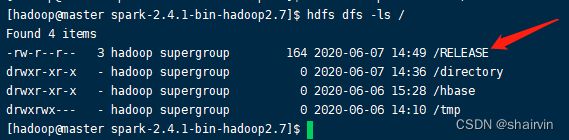
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ hdfs dfs -put RELEASE /
[hadoop@master spark-2.4.1-bin-hadoop2.7]$ hdfs dfs -ls /
- 在Spark shell中用scala语言编写spark程序
sc.textFile("hdfs://master:9000/RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://master:9000/out")
- 使用hdfs命令查看结果
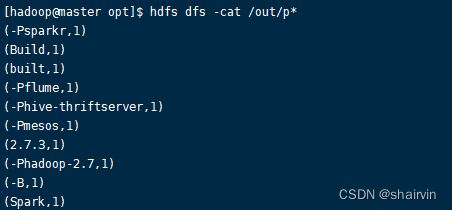
[hadoop@master opt]$ hdfs dfs -cat /out/p*
说明:
sc是SparkContext对象,该对象时提交spark程序的入口
textFile(hdfs://master01:9000/RELEASE)是hdfs中读取数据
flatMap(_.split(" "))先map在压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("hdfs:// master01:9000/out")将结果写入到hdfs中
5.4 Spark-SQL客户端使用
1.读取数据
val df = spark.read.json("/opt/module/spark-2.4.1-bin-hadoop2.7/examples/src/main/resources/people.json")

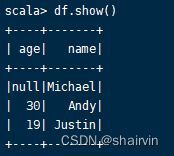
2.查看df变量
df.show()
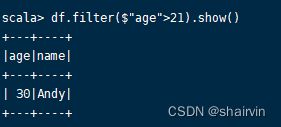
- 过滤查询
df.filter($"age">21).show()
- 创建临时视图
df.createOrReplaceTempView("persons")
- 使用类SQL语句查询persons临时视图。
spark.sql("SELECT * FROM persons").show()

- 使用Sql语句过滤查询
scala> spark.sql("SELECT * FROM persons where age > 20").show()
更多内容请关注公众号“测试小号等闲之辈”~