破解“一人用Java全员大买单”:版本任你发,我用java8
说在前面
在40岁老架构师 尼恩的读者社区(50+)中,最近有小伙伴拿到了一线互联网企业如美团、拼多多、极兔、有赞、希音的面试资格,遇到一几个很重要的面试题:
- 你们用什么版本的jdk?
- 为啥你们还在用java8?
- 聊一聊不同版本的jdk的新特性?
- Oracle JDK 和 OpenJDK 的对比
- ……
这里尼恩给大家做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V87版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲 》《尼恩Java面试宝典》 的PDF文件,请到公号【技术自由圈】获取
文章目录
-
- 说在前面
- Oracle的JAVA收费新规则:一人使用全员买单
- JDK各大版本的收费情况
- 最后的晚餐:jdk-8u202 免费版本
- jdk-8u202之后的版本,到底谁来收钱?
- 版本任你发,我用java8
- 著名中间件如spring依赖jdk17
- 免费的OpenJDK
-
- 如何选择免费的OpenJDK
- 主要的开源 OpenJDK 版本
- java 性能不高的核心原因
-
-
- 核心原因之一:一对一线程架构缺陷
- 核心原因之二:二元运行架构缺陷
-
- jdk的迭代之路,并没有治本
- 3高场景Java8应用如何降本增效
- 附录:从jdk9到jdk20(2023年3月)的升级过程
-
- jdk9(2017年9月)
-
- jdk 和jre的改变
- 访问资源的优化
- 模块化
- JShell
- 语法糖
-
- 接口的私有方法
- <> 操作符使用升级
- try语句
- 下划线_使用限制
- String 存储结构变更
- 快速创建只读集合
- 增强的Stream API
- 输出流直接转输入流
- 设置G1为JVM默认垃圾收集器
- jdk10(2018年3月)
-
- 局部变量类型推断(程序员的福音)
- 多线程并行 GC
- 应用程序类数据(AppCDS)共享
- 线程-局部管控
- 基于Java的实验性JIT编译器Graal
- jdk11(2018年9月 LTS)
-
- 增加字符串处理方法
- Files.readString() 和 Files.writeString()
- Collection.toArray()
- Optional.isEmpty()
- 允许在隐式类型 lambda 表达式的参数中使用var
- 支持TLS 1.3 协议
- HTTP Client
- jdk12(2019年3月)
-
- G1 收集器优化
- jdk13(2019年9月)
-
- SocketAPI 重构
- 增强ZGC释放未使用内存
- jdk14(2020年3月)
-
- Switch 表达式(正式版)
- 改进 NullPointerExceptions提示信息
- 删除 CMS 垃圾回收器
- 弃用 ParallelScavenge 和 SerialOld GC 的组合使用
- jdk15(2020年9月)
-
- 文本块
- 隐藏类Hidden Classes
- 可伸缩低延迟垃圾收集器ZGC 成功转正
- 禁用偏向锁
- 低暂停时间垃圾收集器Shenandoah 成功转正
- jdk16(2021年3月)
-
- instanceof 模式匹配
- Records
- ZGC 并发线程堆栈处理
- 弹性元空间
- jdk17(2021年9月 LTS)
-
- 恢复始终执行严格模式的浮点语义
- 增强型伪随机数发生器
- 强封装JDK的内部API
- 密封类sealed class,限制抽象类的实现
- 移除实验性的 AOT 和 JIT 编译器
- jdk18(2022年3月)
-
- 指定 UTF-8 作为标准 Java API 的默认字符集
- 互联网地址解析 SPI
- jdk19(2022年9月)
- jdk20(2023年3月)
- JVM GC 发展回顾
-
- 性能指标测试
-
- 吞吐量比较
- 延迟比较
- 暂停时间对比
- 资源占用
- 堆内存布局的变化
- 线程模型变化
- 收集行为变化
- 说在最后
- 推荐相关阅读
Oracle的JAVA收费新规则:一人使用全员买单
2023年1 月 23 日,甲骨文公司公布名为《 Oracle Java SE Universal Subscription Global Price List 》的文件,对 Java SE 制定了新的收费标准。
Oracle表示,全新的Java SE收费标准将基于企业员工的总数进行收费,
注意,是员工总数,而不是企业中使用Java的开发人员数量。
简单来说就是:1人使用,全员买单。
文件中,甲骨文公司在新发布订阅文件中将 Java SE 收费标准划分为 8 个不同档位:
- 总员工数量 1-999:$15 /人/月
- 总员工数量 1000-2999:$12 /人/月
- 总员工数量 3000-9999:$10.5 /人/月
- 总员工数量 10000-19999:$8.25 /人/月
- 总员工数量 20000-29999:$6.75 /人/月
- 总员工数量 30000-39999:$5.70 /人/月
- 总员工数量 40000-49999:$5.25 /人/月
- 总员工数量 50000+:没有给出具体定价,需要详询甲骨文。
按照文件 估计,我们假设有一家公司,员工总数为 500 人(包括全职和兼职员工以及代理、顾问和承包商),
在500 人中有 20 个 Java 开发人员。
按照旧模式的收费标准,每年将被收取 20 X 25 X 12 = 6000 美元(旧版本付费按 25 美元/月来举例);
按照新模式的收费标准,每年将被收取 500 X 15 X 12 = 90000 美元。
由此可见,一个 在500 人的公司每年在 Java SE 上的支付成本将上升 15 倍。
简单推算,一个5W人的公司,假设还是20 个 Java 开发人员, 每年提升 1500倍, 费用要到 900W 美元,5000千多人民币。
像阿里、华为这种员工人数在20W人以上的公司, 每年要给Oracle 纳贡 2个亿以上。
更要命的是,那种规模庞大、人数众多的外包公司,也是需要大量纳贡的。外包公司本来利润微薄,这次全部要给 Oracle 纳贡了。
据估算,全球约有 150 亿台设备在运行 Java™。约900万 Java 程序员… 看起来,oracle 可以狠狠的撸一波了。
JDK各大版本的收费情况
打开 oracle jdk的 下载链接,尼恩给大家 展示一下,各大 JDK 版本的收费情况
Java Archive | Oracle
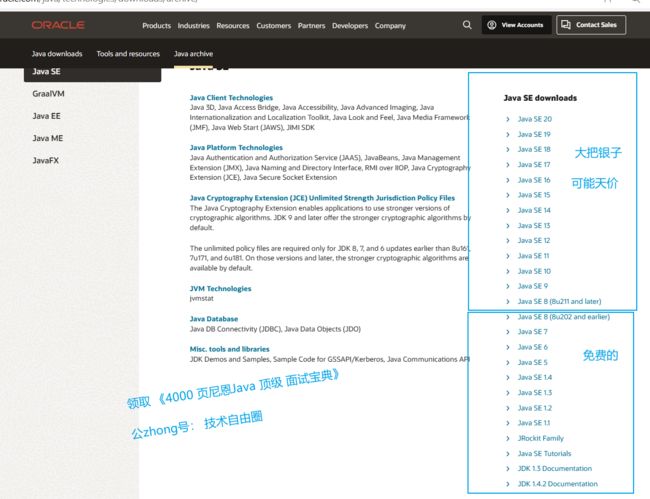
一个小小的例外情况:oracle 官方 曾经发过通知,说JDK17可以免费商用,但是那是有时间限制的,时间截止到2024年9月,共计3年。
这其实又是一个坑,为啥?如果 用了JDK17,就可能回不去了
所以,尼恩这里把JDK17 归类为 潜在收费版本,最终还是要费用的,所以,JDK17其实还是 收费版本。
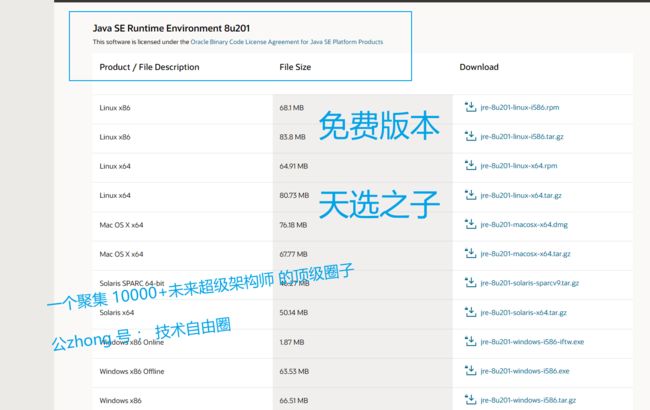
最后的晚餐:jdk-8u202 免费版本
从图中可以看到,Java8及之前的版本都是免费, jdk-8u202所有jdk中最后一个免费的版本,jdk-8u202就是最后的晚餐。
那是不是我们就下载jdk-8u202呢?并不是,而是他的前一个版本,也就是jdk-8u201。
这就是另一个知识要点。这也是 jdk版本的一个小常识
- Java SE 重要补丁更新 (CPU) 包含安全漏洞修复和重要漏洞修复。Java SE CPU 版本号采用奇数编号。
- Java SE 补丁集更新 (PSU) 包含相应 CPU 中的所有修复以及其他非重要修复。
Java SE CPU 版本号采用奇数编号。反过来说:奇数编号版本,包含了安全漏洞修复和重要漏洞修复。
并且,Oracle 官方也是强烈建议所有 Java SE 用户及时升级到最新的 CPU 版本。
换句话说,oracle官方推荐大家下载奇数编号的版本。
所以说,jdk-8u202之前的那个版本,也就是jdk-8u201是“天选之子”,
所以说,jdk-8u201天选打工人的最爱
天选之子的地址如下:
Java Archive Downloads - Java SE 8 (oracle.com)
jdk-8u202之后的版本,到底谁来收钱?
jdk-8u202之后的版本是收费版本,但是也没有支付链接,大家从官方也能下载的,不用付款也能安装的。
安装完了之后,大家直接用,也是没人来收钱的。
于是,大家对收费版本有一种误解:不用白不用,反正没人管。
尼恩只能说:呵呵。用吧。
如果大胆一点,甚至可以像 Google一样, 敞开了用。
要知道,世界级大厂 Google也就是不付钱,直接 敞开了 用 jdk。
没有过多久,最后收到的 法院一张超级大传票:“因为在Android中用了Java,Oracle向Google索赔88亿美元”
所以,大家 如果 敞开了用JDK收费版本,就得要像Google一样,有着雄厚的家底,最好就想google一样:有 超过88亿美元的雄厚家底。然后,等着法院的超级大传票.
如果没有超过88亿美元的雄厚家底,那就最好 不敞着用哈。
其实,除了JDK收费版本,到国外一些大公司的软件都能下载安装使用,比如IBM、Oracle都可以在官网上下载,
正常情况下,是要购买他们的lisence的,一般是按用户量收费或者按CPU核数收费。
那么,为什么他们没有来找你,两个原因:
- 第一,养猪要养肥后才杀,公司大了,肥了就有人联系你了;
- 第二, 打这种跨国官司也有成本的。如果 收费还不够 官司的成本,他们也不急于 收钱。
版本任你发,我用java8
从1996年初JDK1.0发布到现在已经二十多年了, Oracle的版本发布已经形成了一个规律:
- Oracle 每隔6个月就会有一个短期维护版本(non-LTS)发布出来;
- 然后每隔2年,就会发布一款得到8年长期支持维护(LTS)的JDK版本,
所谓LTS版本就是可以得到至少八年产品支持的版本。
到目前为止,有四个LTS版本,JDK 7、JDK 8、JDK 11、JDK 17,下一个LTS版本是JDK 21。
最新一个版本已经到 JDK 20,JDK17是最新的一个LTS(Long-Term Support)版本。
“版本任你发,我用java8”
虽然 JDK 疯狂升级,但是java社区一直都是 “版本任你发,我用java8”,
不管哪个版本发出来,很少有人愿意升级,不升级的原因,就是大家有两个大的担忧:
- 第一个大担忧:收费的 达摩克斯之剑
- 第二个大担忧:使用新版本 容易踩坑
那么,通过市场调查,来具体看看,大家的Jdk版本如何选择?
JDK的版本首选LTS版本。 根据调查,各个jdk LTS 版本的近三年的使用情况如下图:
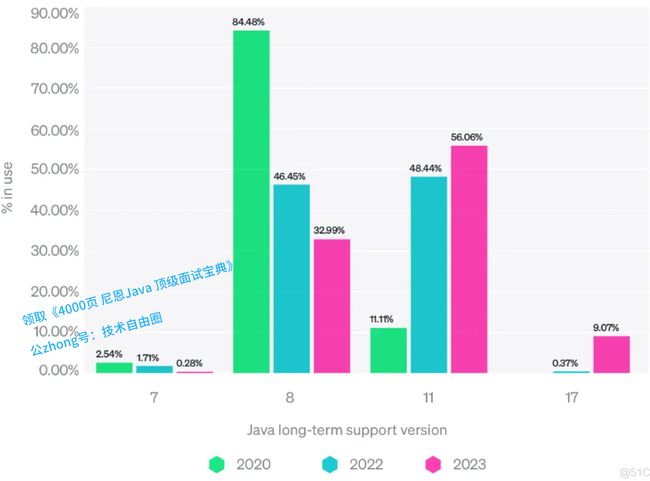 jdk LTS版本增长情况
jdk LTS版本增长情况
从这份结果可以看出,很多公司要么用了openjdk,如果是盲目用Oracle JDK新版本的,就慢慢被养成一条被宰的肥猪了。
2023年 , 56%的公司使用Java11 , 呵呵,这些公司估计得找 oracle 缴费了。如果没有缴费,并且有只要一个服务器使用了oracle jdk11,将来的某一天,就等着oracle公司发过来的巨大额度的收费清单吧
另外 %9 的公司,使用了Java17, 这些公司在时间截止到2024年9月,共计3年,是免费的。从明年开始,如果没有主动缴费,并且有只要一个服务器使用了oracle jdk17, 呵呵,将来的某一天,同样就等着oracle公司发过来的巨大额度的收费清单吧
用openjdk 固然能避免收费,但是用了就回不去了。
尼恩通过后面的分析给大家证明:
jdk新版本的250个特性的性能提升,指标不治本、外层挠痒痒, 根本没啥用。升了还不如别升,jdk8更稳定。
著名中间件如spring依赖jdk17
虽然企业不能轻易升级,但是oracle 有很多 好队友,小跟班,他们带节奏,跟着升,怎么办?
这些oracle小跟班,就是各大开源软件厂商
不知道这些oracle小跟班,是不是收到oracle的投资,总之就是,现在各开源软件前后呼应的追赶Jdk新版本,也正在全面拥抱jdk17.
另外,spring6 和springboot3 相继推出直接要求最低依赖是jdk17,spring 和springboot的版本升级强制要求JDK版本升级17。
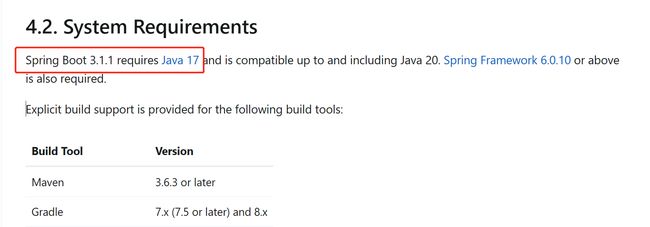

如果某些中间件,一定要用java 17, 然后咱们主要的java版本,是java8 或者java11,怎么办?
- 使用对于的免费版本,也就是OpenJDK版本, 能用阿里的就阿里的,不行就是Oracle的OpenJDK
- 使用容器的方式,容器里边用免费的OpenJDK版本
比如 ,尼恩在讲 云原生架构的时候, 发现 Jenkins 就是依赖了 jdk11,导致尼恩作为一个Java8的铁杆用户,最终只能通过 容器的方案绕过安装 Java11,去通过容器安装Jenkins。
免费的OpenJDK
虽然 Oracle JDK 是Java官方Oracle公司基于OpenJDK构建,收费。
除了官方的Oracle JDK,大家可以使用 开源的 OpenJDK。这个是免费的。
如何选择免费的OpenJDK
要注意的是,要关注第 三方openJDK的稳定性及可用度。
一般来说,建议使用经历过大规模生产历练、 长时间稳定运行、有强大的技术团队支撑的版本。
比如 建议是 阿里的 Dragonwell JDK。
只是, 阿里的 Dragonwell JDK只适配 Java 8 和 Java 11, 没有其他的JDK 版本的适配。
主要的开源 OpenJDK 版本
接下来,看看主要的开源 OpenJDK 版本:
1.OpenJDK
OpenJDK 是 JDK 的社区版,社区主要由Oracle主导,免费。
OpenJDK
Java的开源版本OpenJDK,OpenJDK目前由Oracle主导,汇聚了社区的力量进行开发,IBM,红帽等企业都有参与。
使用Oracle的openJDK,需要及时跟进版本更新,可能需要比较高的开发迁移能力。
另外,可以使用第三方发布的openJDK,不过,取决于三方openJDK的稳定性及可用度。
2.阿里巴巴Dragonwell JDK
Alibaba Dragonwell 是阿里巴巴公司基于OpenJDK的构建,免费。
Dragonwell-Java 开发工具包 (OpenJDK) - 阿里云 (aliyun.com)
3.腾讯Kona JDK
腾讯 Kona(Tencent Kona) 是腾讯公司基于OpenJDK的构建,免费。
腾讯开源的TencentKona 8是腾讯基于OpenJDK的一个免费的、生产级别的开源产品。Kona是腾讯内部默认JDK,针对超大规模的大数据、机器学习以及云计算环境做了特别的优化。
4.华为毕昇JDK
华为毕昇JDK 是华为公司基于OpenJDK的构建,免费
5.Eclipse Temurin
Eclipse Temurin(曾用名:AdoptOpenJDK) 是Eclipse基金会基于OpenJDK的构建,支持Oracle公司的HotSpot虚拟机和Eclipse基金会的OpenJ9虚拟机,免费。
6.Azul Zulu OpenJDK
Azul Zulu OpenJDK 是总部位于加州桑尼维尔的Azul公司基于OpenJDK的构建,免费。
7.SAP SapMachine
SAP SapMachine 是OpenJDK 项目的贡献者之一SAP公司基于OpenJDK的构建,免费。
8.Red Hat build of OpenJDK
Red Hat build of OpenJDK 是Red Hat(红帽子)公司基于OpenJDK的构建,免费。
9.Microsoft Build of OpenJDK
Microsoft Build of OpenJDK 是微软公司基于OpenJDK的构建,免费。
java 性能不高的核心原因
java 性能不高的原因很多,非常非常多, 很多人通过博客的形式,从不同的维度进行各种分析
但是尼恩在这里,浓缩再浓缩,归纳再归纳,
本质上java 性能不高的核心原因, 有两个本质的架构缺陷,具体如下
- 核心原因之一:一对一线程架构缺陷
- 核心原因之二:二元运行架构缺陷
一个一个来看吧。
核心原因之一:一对一线程架构缺陷
用户线程和内核线程一对一绑定,导致多线程场景 用户态和内核态频繁切换。
和Java相比,GO的线程架构就优越得多, 去掉了 用户线程和内核线程一对一绑定。
GO的业务线程的切换以及线程操作,发生在用户态,所以不需要系统调用,省去了大量的 系统调用开销和 用户态和内核态频繁切换开销。
核心原因之二:二元运行架构缺陷
为了跨平台,Java的执行架构进行了彻底的解耦,将一元的二进制程序,解耦为二元运行架构,包括一份 JVM程序 和 一份二进制业务程序。
Java 将执行 字节码程序的程序进行独立,独立为 JVM。
并且,不同的操作系统,Java提供不同的JVM实现版本,通过这种变JVM不变业务字节码的方式,实现跨平台。
不同的平台, 使用同一份 字节码业务程序,从而 实现: 一次编译,到处运行,最终完成 业务代码的跨平台执行。
Java二元的运行架构,实现了:跨平台执行。然而,任何事情都是双面的, Java二元的运行架构的有一个大的缺陷:运行速度慢、启动速度慢。
**运行速度慢的根本原因:**主要是字节码还不是机器码,字节码需要解释执行。
那么,JVM如何提升运行速度呢?通过进行热点字节码编译成为 二进制机器码的方式,进行不断的优化进行不断的性能提升,运行的速度也有质的飞越。运行速度慢慢慢得到了解决
但是,启动速度慢是一个巨大的硬伤,没法解决。Java 的JVM字节码执行程序和 业务程序 分离之后 ,启动的时候,需要把大量的 字节码文件,加载在内存, 然后进行解释执行,或者 预编译执行。Java中单个类的字节码文件的 加载过程,需要进行大量的 安全校验、 符号解析、初始化等工作,是非常耗时间的。一个Java应用可能涉及成百上千的Java类,这就是一个很长的时间周期。
在线上我们常常发现, 一个springboot应用的启动过程要 10s,甚至30s,这是一段非常长的时间周期。
和Java相比,GO不存在Java的这个问题,GO的一元运行架构。
GO的跨平台方式是跨平台编译, 不同平台,编译出一份不同的 可执行文件。GO程序在执行的时候,不存在 Java的那种单个类文件的 加载过程, 哪怕成百上千的GO结构体,也是很短的时间内实现启动。
这使得在Golang中,程序的启动速度非常快,可以在数十毫秒内启动一个应用程序。
jdk的迭代之路,并没有治本
接着,我们来简单看下,从jdk9到jdk17都有哪些新特性。
从 JDK 诞生到现在,其长期支持的版本主要有 JDK 7、JDK 8 、JDK 11以及 JDK 17,JDK 17 将是继 Java 8 以来最重要的LTS版本,是 Java 社区八年努力的成果。
首先,我们看下jdk 8 到jdk 19各版本新增特性的数量如下:
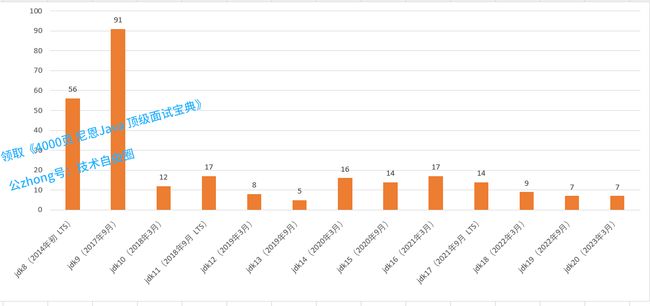 jdk各版本新特性
jdk各版本新特性
从上图可以看到从 Java 8 到 Java 19 总共引入了超过 250 个新特性,其中 Java 9 中包含了 91 个新特性,这是由于之前的发布周期较长所导致的,在应用新的发布模型后,各版本的新增特性数量都维持在 10 个左右的水平。
后面的内容,尼恩给大家列了250 个新特性。
虽然新特性足够多,但是这些特性都是指标不治本,没有解决 本质上java 性能不高的核心原因, 就是没有解决这两个本质的架构缺陷:
- 核心原因之一:一对一线程架构缺陷
- 核心原因之二:二元运行架构缺陷
Java当然想解决这个两个架构缺陷,但是这两个问题都是JVM里边核心的核心, 牵一发而动全身的架构。
总之,不论他们是没有魄力、或者他们是没有耐心,总之就是没有解决。所以,java的版本升级,就是指标不治本, 没有质的飞跃。
既然如此,与其用新版本导致后面被oracle 巨额收费,还不如用java 8。
3高场景Java8应用如何降本增效
Java由于其最早的开放性, 造就了他的 最为活跃的 开源社区, 最为全面的开源生态。
用Java开发的应用,如果 从1qps 一路成长,如果平滑升级到 1亿qps,而不去换语言的话,那么java是最佳选择,为什么? 很简单,java生态体系中的工具链、中间件是最全的、最完善的。
但是,使用java的劣势是:单体服务性能低,比较耗费资源,如果要提供其他高性能语言一样的能力,Java需要做大量的横向扩展。
尼恩的《golang 学习圣经》里有一组实验数据:
- 尼恩通过springcloud gateway 和 golang Bff的对比测试,java 性能弱8倍。
- 尼恩也通过 dubbo rpc 和 dubbo-go RPC 的对比测试, java 性能弱8倍。
也就是说,要提供golang 一样的能力,简单的测算,Java要提供 8倍的服务器资源。
3高场景Java应用如何降本增效?很简单,就是取长补短,借助其他语言提升性能。
- 没有go之前,在京东的架构中,大量的使用了Nginx lua, 也就是说,京东是 Java + Nginx lua 相结合的架构。
- 有了go之后,如果京东的重来,一定是大量的使用了go, 也就是说如果重来,京东一是 Java + go 相结合的架构。
为啥这么说?
现在很多的互联网公司,已经是 java +go 结合的架构:
- 3高+简单业务场景,用go提升性能
- 低并发场景或者负责业务场景, 仍然使用java
所以,结论是:
说一千道一万,目前的技术选择还是死守Java 8 。利用 golang 补齐Java的性能短板。
毕竟java 8 是那么的稳定,那么的稳若磐石。
未来,Java +Go 架构将会越来越普遍,主要的原因有两个:
- go的学习成本低:具体可以参考尼恩的《go 学习圣经》,java高手一周可以掌握
- 结合起来,才是最大的降本增效:使用go是节省服务器成本,使用java 是节省造轮子成本
站在Java +Go 架构这个大的架构下,已经不依赖java的版本升带来大的性能飞越。
咱们之前的架构师 Java + Lua, 未来的架构 是 Java+ GO。Java的版本就是 8。
所以,不用担心Java版本怎么升级。Oracle 爱怎么升级,就让他升级去吧。
附录:从jdk9到jdk20(2023年3月)的升级过程
jdk9(2017年9月)
java 9 提供了超过 150 项新功能特性,包括备受期待的模块化系统、可交互的 REPL 工具:JShell,JDK 编译工具,Java 公共 API 和私有代码,以及安全增强、扩展提升、性能管理改善等。
可以说 Java 9 是一个庞大的系统工程,完全做了一个整体改变。
新特性主要有以下几个:
- jdk 和jre的改变
- Java平台模块系统
- Jshell集合、Stream 和 Optional
- 进程 API
- 平台日志 API 和 服务
- 反应式流 ( Reactive Streams )
- 变量句柄
- 改进方法句柄(Method Handle)
- 并发
- Nashorn
- I/O 流新特性
- 改进应用安全性能
- 用户界面
- 统一 JVM 日志
重要特性:主要是API的优化,如支持HTTP2的Client API、JVM采用G1为默认垃圾收集器。
jdk 和jre的改变
在jdk SE 9 之前,jdk构建系统用于生成两种类型的运行时映射-JRE(java运行时环境)和JDK(java开发工具包)。
JRE 是java SE 平台的完整实现,JDK包含了JRE 和开发工具和类库。
java SE 9 之前的JDK文件目录
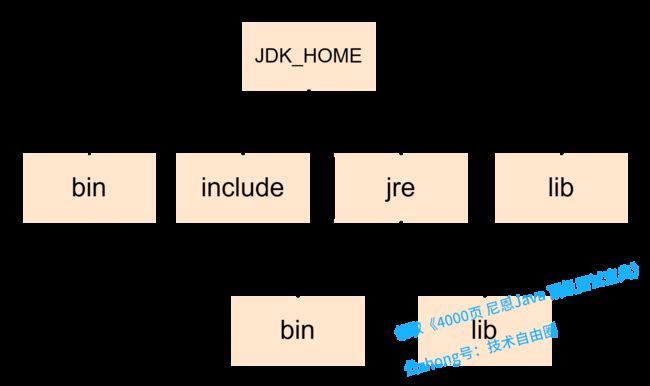 jdk9之前的目录
jdk9之前的目录
目录说明:
- bin目录用于包含命令行开发和调试工具,如javac,jar和javadoc。它还用于包含Java命令来启动Java应用程序。
- include目录包含在编译本地代码时使用的C/C++头文件。
- lib目录包含JDK工具的几个JAR和其他类型的文件。它有一个tools.jar文件,其中包含javac编译器的Java类。
- jre\bin目录包含基本命令,如 Java 命令。在 Windows 平台上,它包含系统的运行时动态链接库(DLL)
- jre\lib目录包含用户可编辑的配置文件,如 .properties 和 .policy 文件。包含几个 JAR。rt.jar文件包含运行时的 Java 类和资源文件。
Java SE 9调整了JDK的目录层次结构如下图所示:
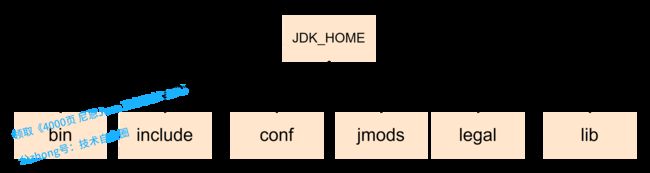 jdk9以后目录
jdk9以后目录
最大的区别:从jdk9开始删除了JDK和JRE之间的区别,在jdk9中,没有名为jre的目录。
目录说明:
- bin目录包含所有命令。在Windows平台上,它继续包含系统的运行时动态链接库。
- conf目录包含用户可编辑的配置文件,例如以前位于jre\lib目录中的.properties和.policy文件。
- include目录包含要在以前编译本地代码时使用的C/C++头文件。它只存在于JDK中。
- jmods目录包含JMOD格式的平台模块。创建自定义运行时映像时需要它。它只存在于JDK中。
- legal 目录包含法律声明。
- lib目录包含非Windows平台上的动态链接本地库。其子目录和文件不应由开发人员直接编辑或使用。
访问资源的优化
在jdk9之前,可以从类路径上的任何JAR访问资源。在java代码中,资源由资源名称标识,资源名称是由斜线(/)分隔的一串字符串。对于存储在JAR中的资源,资源名称仅仅是存储在JAR中的文件的路径。
例如,存储在rt.jar中的java.lang包中的Object.class文件,它也是一个资源,其资源名称是java/lang/Object.class。
可以使用以下两个类中的方法来访问资源:
- java.lang.Class
- java.lang.ClassLoader
资源由ClassLoader定位。一个Class代理中的资源寻找方法到它的ClassLoader。
在两个类中有两种不同的命名实例方法:
(1)URL getResource(String name)
(2)InputStream getResourceAsStream(String name)
两种方法都会以相同的方式找到资源。它们的差异仅在于返回类型。第一个方法返回一个URL,而第二个方法返回一个InputStream。第二种方法相当于调用第一种方法,然后在返回的URL对象上调用openStream()。
ClassLoader类包含三个额外的查找资源的静态方法:
//(1)返回找到的第一个资源的URL
static URL getSystemResource(String name);
//(2)返回找到的第一个资源的InputStream
static InputStream getSystemResourceAsStream(String name)
//(3)返回使用指定的资源名称找到的所有资源的URL枚举
static Enumeration<URL> getSystemResources(String name)
在考虑使用哪一种方式获取资源之前,先要弄清楚获取的资源是哪一种资源。
资源可以分为两种类型,如下:
- 系统资源:系统资源是在bootstrap类路径,扩展目录中的JAR和应用程序类路径中找到的资源。
- 非系统资源:可以存储在除路径之外的位置,例如在特定目录,网络上或数据库中。
getSystemResource()方法使用应用程序类加载程序找到一个资源,委托给它的父类,它是扩展类加载器,扩展类加载器又委托给它的父类(引导类加载器)。
如果你的应用程序是独立的应用程序,并且它只使用三个内置的JDK类加载器,getSystemResource*() 的静态方法是最佳选择。它将在类路径中找到所有资源,包括运行时映像中的资源,如rt.jar文件。
如果你的应用程序是在浏览器中运行的小程序,或在应用程序服务器和Web服务器中运行的企业应用程序,则应使用getResource(),它可以使用特定的类加载器来查找资源。
从jdk9开始,类和资源封装在模块中。
在第一次尝试中,JDK 9设计人员强制执行模块封装规则,模块中的资源必须对该模块是私有的,因此它们只能在该模块内的代码中访问。虽然这个规则在理论上看起来很好,但是对于跨模块共享资源的框架和加载的类文件作为来自其他模块的资源,就会带来问题。为了有限地访问模块中的资源,做了一些妥协,但是仍然强制执行模块的封装。
JDK 9包含三类资源查找方法:
java.lang.Class
java.lang.ClassLoader
java.lang.Module
Class和ClassLoader类没新增任何新的方法。
Module类包含一个getResourceAsStream(String name)方法,如果找到该资源,返回一个InputStream;否则返回null。
模块化
java从1995年发布,到现在java已经发展了快30年,但是java与相关生态在不断丰富的同时也暴露除了很多问题:
- java运行环境的膨胀与臃肿。在JVM启动的时候,至少会有30~60MB的内存加载,主要原因是JVM需要加载rt.jar,不管其中的类是否被classloader加载,第一步整个jar都会被JVM加载到内存中。
- 代码库越来越大,创建复杂。盘根错节的意大利面条式代码的几率呈指数级的增长。不同版本的 类库交叉依赖导致让人头疼的问题,这些都阻碍了 Java 开发和运行效率的提升。
- 每一个公共类都可以被类路径之下任何其它的公共类所访问到,这样就会导致无意中使用了并不想被公开访问的 API。
- 类路径本身也存在问题:无法知晓所需要的JAR是否是全都存在还是部分存在。
受兼容性、代码库庞大等问题的掣肘,想要对java进行大刀阔斧的革新是越来越困难,
Jigsaw 从 Java 7 阶段就开始筹备,Java 8 阶段进行了大量工作,最终在 Java 9 里落地,有一种千呼万唤始出来的意味。
提示:
Jigsaw 的中文直译为:
拼图; 线锯; 拼板玩具; 钢丝锯; 谜团; 镂花锯; 神秘莫测的事物(或状况);
Jigsaw是OpenJDK项目下的一个子项目,旨在为Java SE平台设计、实现一个标准的模块系统,并应用到该平台和JDK中。该项目由Java编程语言编译器小组赞助。
提及 Java 9,最大的功能莫过于 Jigsaw 项目下的核心 Java 平台模块化系统(JPMS,Java Platform Module System) 。Jigsaw 本身是一项很有野心的项目,它的目标是改进 Java SE 平台,使其可以适应不同大小的计算设备;改进其安全性,可维护性,提高性能;简化各种类库和大型应用的开发和维护,包括 JDK 本身的模块化。
JPMS(Java Platform Module System)是Java 9发行版的核心亮点。JPMS似于OSGI框架的功能,模块之间存在相互的依赖关系,可以导出一个公共的API,并且隐藏实现的细节。
JPMS包括为编写模块化应用程序提供支持,以及将JDK源代码模块化。JDK 9 附带了大约 92 个模块(在 GA 版本中可以进行更改)。其中JSR 376 Java 平台模块化系统(JPMS,Java Platform Module System)作为 Jigsaw 项目的核心,其主体部分被分解成 6 个 JEP(JDK Enhancement Proposals)。
Java 9 Module System有一个"java.base"模块,它被称为基本模块。它是一个独立的模块,不依赖于任何其他模块。默认情况下,所有其他模块都依赖于"java.base"。
在java模块化编程中,一个模块通常只是一个 jar 文件,在根目录下有一个文件module-info.class。
如果需要使用模块,请将 jar 文件包含到modulepath而不是classpath. 添加到类路径的模块化 jar 文件是普通的 jar 文件,module-info.class文件将被忽略。
典型的module-info.java 类如下:
module jdk9.client {
requires jdk9.test;
}
其项目结构如下:
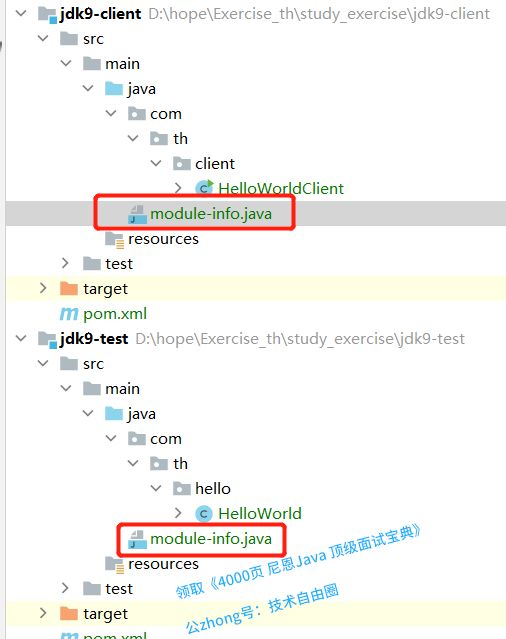
本质上将,模块其实就是package外再裹一层,用模块来管理各个package,通过声明某个 package 暴露,不声明默认就是隐藏。
因此,模块化使得代码组织上 更安全,因为它可以指定哪些部分可以暴露,哪些部分隐藏。
模块化(以 Java 平台模块系统的形式)将 JDK 分成一组模块,可以在编译时,运行时或者构建时进行组合。其实现目标如下:
- 主要目的在于减少内存的开销
- 只须必要模块,而非全部 JDK 模块,可 简化各种类库和大型应用的开发和维护
- 改进 Java SE 平台,使其可以 适应不同大小的计算设备
- 改进其安全性,可维护性,提高性能
Java发展到9之后,整个JDK的产品形态发生了一个很大的变化,从一个大的单体应用,作了一定的解耦,
模块化解耦之后,JMC、OpenJFX等以软件包的形式独立于JDK之外,Oracle也将其商业特性都开源了出来,所以Oracle JDK 9和OpenJDK 9仅存在License的不同。
JShell
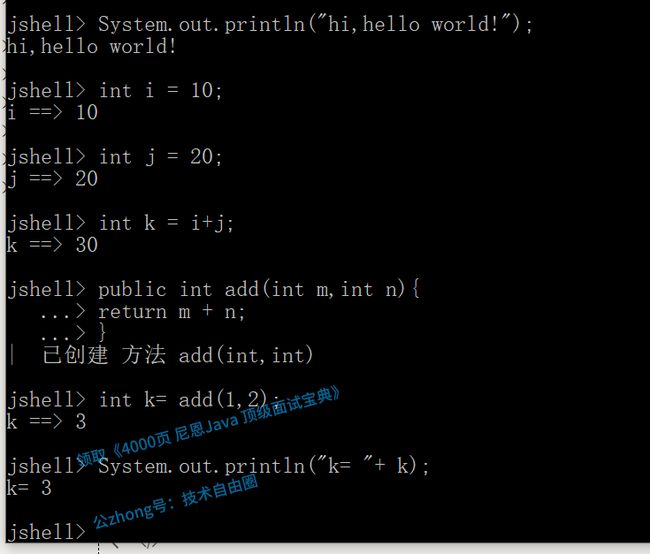
Python 和 Scala 之类的语言早就有交互式编程环境 REPL(read - evaluate - print - loop),以交互式的方式对语句和表达式进行求值。
开发者只需要输入一些代码,就可以在编译前获得对程序的反馈。而 之前的 Java 版本要想执行代码,必须创建文件、声明类、提供测试方法方可实现。
Java 9 中终于拥有了 REPL 工具:JShell。利用 JShell 在没有创建类的情况下直接声明变量,计算表达式,执行语句。即开发时可以在命令行里直接运行 Java 的代码,而无需创建 Java 文件,无需跟人解释 public static void main(String[] args) 这句废话。
JShell 也可以从 文件中加载语句 或者将语句保存到文件中。
JShell 也可以是 Tab 键进行自动补全 和 自动添加分号。
语法糖
接口的私有方法
在jdk8中规定了接口中的方法除了抽象方法之外,还可以定义静态方法和默认的方法。在一定程度上,扩展了接口的功能,这个时候的接口更像一个抽象类。
在jdk9中,接口就更加的灵活和强大,连方法的访问权限修饰符都可以声明为 private 的了,此时方法将不会成为你对外暴露的 API 的一部分。
public interface Animal {
//jdk 7 : 只能声明全局常量(public static final)和抽象方法(public abstract)
void setAnimalName(String name);
// jdk 8 : 声明静态方法 和 默认方法
static void setAge(int age){
System.out.println("age =" + age);
}
default void setColor(String color){
getWeight();
System.out.println("color =" + color);
}
//jdk9
private void getWeight(){
System.out.println("获取animal的体重");
}
}
public class Dog implements Animal{
@Override
public void setAnimalName(String name) {
System.out.println("name = " + name);
}
}
//测试单元
@Test
public void DogNameTest(){
Dog dog = new Dog();
dog.setAnimalName("黑妞");
dog.setColor("red");
}
执行结果如下:

<> 操作符使用升级
在jdk9之前,匿名实现类使用<>操作符会报错,如下:
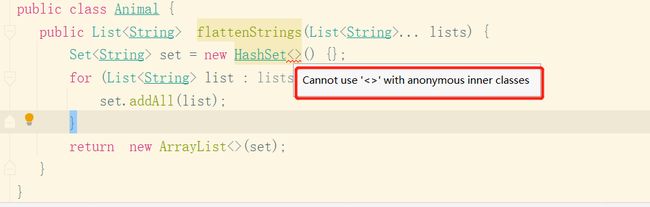
在jdk9中使用可以正常编译通过:
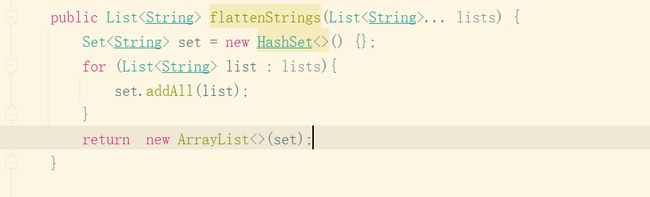
try语句
在jdk8之前,我们习惯使用如下方式关闭资源:
public void readFile() throws FileNotFoundException {
FileReader fr = null;
BufferedReader br = null;
try{
fr = new FileReader("d:/input.txt");
br = new BufferedReader(fr);
String s = "";
while((s = br.readLine()) != null){
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
br.close();
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java 8 中,可以实现资源的自动关闭,但是要求执行后必须关闭的所有资源必须在 try 子句中初始化,否则编译不通过。如下例所示:
public void readFile() throws FileNotFoundException {
try(FileReader fr = new FileReader("d:/input.txt");BufferedReader br = new BufferedReader(fr);){
String s = "";
while((s = br.readLine()) != null){
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
}
}
Java 9 中,用资源语句编写 try 将更容易,我们可以在 try 子句中使用已经初始化过的资源,此时的资源是 final 的:
public void readFile() throws FileNotFoundException {
FileReader fr = new FileReader("d:/input.txt");
BufferedReader br = new BufferedReader(fr);
try( fr ;br){
String s = "";
while((s = br.readLine()) != null){
System.out.println(s);
}
} catch (IOException e) {
e.printStackTrace();
}
}
下划线_使用限制
在jdk8中,标识符可以独立使用_命名,如下:
String _ ="hello";
System.out.println(_);
在 Java 9 中规定 _ 不再可以单独命名标识符了,如果使用, 会报错,如下
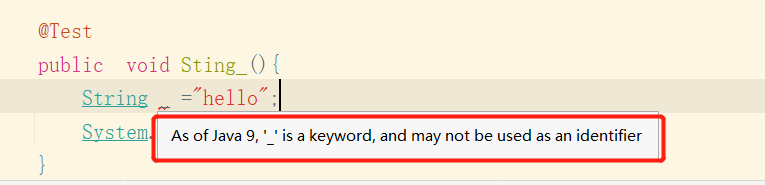
As of Java 9, '_' is a keyword, and may not be used as an identifier
String 存储结构变更
String 类的当前实现将字符存储在字符数组,每个字符使用两个字节(16 位)。
数据从许多不同的应用程序收集的数据表明字符串是堆使用的主要组成部分,而且最重要的是对象仅包含拉丁字母 1。这样的角色只需要一个字节的存储空间,因此占内部字符数组空间的一半许多这样的字符串对象将被闲置。
jdk9之前,String使用char[]来存储,如下:

从jdk9开始,使用byte[]加上编码标记,节约了一些空间:
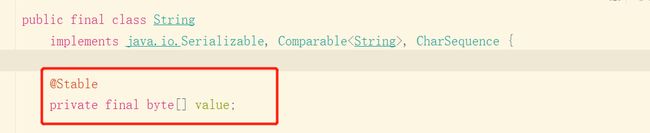
与字符串相关的类,如 AbstractStringBuilder、StringBuilder、StringBuffer 底层也更新为使用byte[]存储,
快速创建只读集合
在jdk9之前,要创建一个只读、不可改变的计划,必须构造和分配它,然后添加元素,最后包装成一个不可修改的集合。
例如使用 Collections 提供的 unmodifiableList 方法可以创建只读、不可改变 的 List 集合:代码如下:
public void test() {
List<String> namesList = new ArrayList <>();
//添加元素
namesList.add("Joe");
namesList.add("Bob");
namesList.add("Bill");
//包装成一个不可修改的集合
namesList = Collections.unmodifiableList(namesList);
System.out.println(namesList);
}
jdk9给各个集合引入了of()静态方法,该方法代替 Collections.unmodifiableXXX 创建出 只读、不可改变 的集合。

List firsnamesList = List.of("Joe", "Bob", "Bill");
调用集合中静态方法 of(),可以将不同数量的参数传输到此工厂方法中。此功能可用于 Set 和 List,也可用于 Map 的类似形式。此时得到的集合,是不可变的:在创建后,继续添加元素到这些集合会导致 UnsupportedOperationException。
增强的Stream API
Java 的 Steam API 是 Java 标准库最好的改进之一,让开发者能够快速运算,从而能够有效的利用数据并行计算。
Java 8 提供的 Steam 能够利用多核架构实现声明式的数据处理。
在 Java 9 中,Stream API 变得更好,Stream 接口中添加了 4 个新的方法:dropWhile、takeWhile、ofNullable,还有个 iterate 方法的新重载方法,可以让你提供一个 Predicate(判断条件)来指定什么时候结束迭代。
除了对 Stream 本身的扩展,Optional 和 Stream 之间的结合也得到了改进。现在可以通过 Optional 的新方法 stream() 将一个 Optional 对象转换为一个(可能是空的)Stream 对象。
takeWhile() 的使用
用于从 Stream 中获取一部分数据,接收一个 Predicate 来进行选择。在有序的 Stream 中,takeWhile 碰到不符合元素时,把前面符合的元素返回。
@Test
public void takeWhileTest(){
List<Integer> list = Arrays.asList(32,65,36,96,35,14,78,98,52,41,69,64,99);
Stream<Integer> stream = list.stream();
stream.takeWhile(x->x<70).forEach(System.out::println);
System.out.println();
}
执行结果:
32,65,36
找到不符合条件的元素后,停止寻找,虽然后面还有一些元素符合条件,也不会获取。
dropWhile() 的使用
dropWhile 的行为与 takeWhile 相反,碰到第一个不符合的元素后,把剩余的元素返回。
@Test
public void dropWhileTest(){
List<Integer> list = Arrays.asList(32,65,36,96,35,14,78,98,52,41,69,64,99);
Stream<Integer> stream = list.stream();
stream.dropWhile(x->x<50).forEach(System.out::println);
System.out.println();
}
执行结果:
96,35,14,78,98,52,41,69,64,99
ofNullable() 的使用
Java 8 中 Stream 不能完全为 null,否则会报空指针异常。而 Java 9 中的 ofNullable 方法允许我们创建一个单元素 Stream,可以包含一个非空元素,也可以创建一个空 Stream。
@Test
public void ofNullableTest() {
Stream<Integer> stream1 = Stream.of(1, 2, 3, null);
stream1.forEach(System.out::println); //1, 2, 3, null
System.out.println();
// 如果只有单个元素,此元素不能为 null.否则报 NullPointerException
// Stream
// jdk 9:新增 ofNullable(T t)
Stream<String> stream3 = Stream.ofNullable("Tom");
System.out.println(stream3.count()); // 1
Stream<String> stream4 = Stream.ofNullable(null);
System.out.println(stream4.count()); // 0
}
iterator() 重载的使用
Stream 的实例化有以下三种方式
(1)通过集合的 stream();
(2)通过数组工具类:Arrays.stream();
(3)Stream 中静态方法:of()、iterator() / generate()
输出流直接转输入流
InputStream类中提供了transferTo(),可以用来将数据直接传输到 OutputStream,这是在处理原始数据流时非常常见的一种用法。
@Test
public void transferToTest() throws IOException {
try(InputStream is = new FileInputStream("src/main/resources/input.txt");
OutputStream os = new FileOutputStream("out1.txt")) {
//把输入流中的所有数据直接自动地复制到输出流中
is.transferTo(os);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
执行结果:

从执行结果可以看到input.txt 与out.txt的内容一致。
设置G1为JVM默认垃圾收集器
Java 9 移除了在 Java 8 中 被废弃的垃圾回收器配置组合,同时把G1设为默认的垃圾回收器实现。替代了之前默认使用的Parallel GC,
相对于Parallel来说,G1会在应用线程上做更多的事情,而Parallel几乎没有在应用线程上做任何事情,它基本上完全依赖GC线程完成所有的内存管理。这意味着切换到G1将会为应用线程带来额外的工作,从而直接影响到应用的性能
jdk10(2018年3月)
jdk10的新特性主要有以下几个:
- 局部变量类型推断
- 整合 JDK 代码仓库
- 统一的垃圾回收接口
- 并行全垃圾回收器 G1
- 应用程序类数据共享
- 线程-局部管控
- 移除 Native-Header 自动生成工具
- 额外的 Unicode 语言标签扩展
- 备用存储装置上的堆分配
- 基于 Java 的 实验性 JIT 编译器
- 根证书认证
- 基于时间的版本发布模式
重要特性:通过var关键字实现局部变量类型推断,使Java语言变成弱类型语言、JVM的G1垃圾回收由单线程改成多线程并行处理,降低G1的停顿时间。
局部变量类型推断(程序员的福音)
许多流行的编程语言都已经支持某种形式的局部变量类型推断,如C++ (auto), C# (var), Scala (var/val), Go (declaration with :=)等。
java从jdk10 开始,也可以使用var作为局部变量类型推断标识符,仅适用于局部变量。
示例:
@Test
public void varTest(){
//根据推断为 字符串类型
var str = "ABC";
//根据10L 推断long 类型
var l = 10L;
//根据 true推断 boolean 类型
var flag = true;
//这里会推断boolean类型。0表示false 非0表示true
var flag1 = 1;
// 推断 ArrayList反编译class文件如下:
@Test
public void varTest() {
String str = "ABC";
long l = 10L;
boolean flag = true;
int flag1 = true;
ArrayList<String> list = new ArrayList();
Stream<String> stream = list.stream();
}
适合使用var场景如下:
(1)带有初始化程序的局部变量;
//正确用法
var numsList = List.of(1,3,5,9,10);
//错误用法
var str ;
(2)for循环,增强for循环索引;
(3)for循环内部的局部变量;
for (var number : numbers) {
System.out.println(number);
}
for (var i = 0; i < numbers.size(); i++) {
System.out.println(numbers.get(i));
}
var不适用情况:
(1)初始值为 null;
(2)方法引用;
(3)Lambda 表达式;
(4)为数组静态数组化。
JDK这么做的原因也是考虑到兼容的问题,兼容有些老系统使用了var作为变量名。
不用担心使用var会影响代码阅读,在鼠标放到由var声明的变量上时,IDEA会显示它真实的类型。
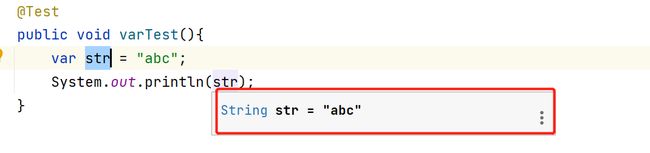
var 的工作原理是在处理var 时,编译器先是查看表达式右边部分,并根据右边变量值的类型进行推断,作为左边变量的类型,然后 将该类型写入字节码当中。
多线程并行 GC
在JDK9中G1被选定为默认的垃圾收集器,G1的设计目标是避免发生Full GC,由于Full GC较难产生所以在设计之初只有Young GC和Mixed GC是并行的,而Full GC是单线程使用标记-清理-合并算法进行垃圾回收。
G1只是避免发生Full GC,在极端情况下,当G1的回收速度相对于产生垃圾的速度不是足够快时,就会发生Full GC。
为了最大限度地减少 Full GC 造成的应用停顿的影响,在JDK10中添加了G1垃圾收集器并行Full GC。
同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
线程的数量可以由-XX:ParallelGCThreads选项来控制,这个参数也用来控制Young GC和Mixed GC的线程数。
应用程序类数据(AppCDS)共享
CDS 的全称是 Class-Data Sharing, CDS 的作用是让类可以被预处理放到一个归档文件中,后续 Java 程序启动的时候可以直接带上这个归档文件,这样 JVM 可以直接将这个归档文件映射到内存中,以节约应用启动的时间。
这个特性在 JDK 1.5 就开始引入, 但是 CDS 只能作用与 Boot Class Loader 加载的类,不能作用于 App Class Loader 或者自定义的 Class Loader 加载的类。
在 JDK 10 中, CDS 扩展为 AppCDS,AppCDS 不止能够作用于 Boot Class Loader,App Class Loader 和自定义的 Class Loader 也都能够起作用,进一步提高了应用启动性能。
线程-局部管控
这是在 JVM 内部相当低级别的更改,现在将允许在不运行全局虚拟机安全点的情况下实现线程回调。这将使得停止单个线程变得可能和便宜,而不是只能启用或停止所有线程。
基于Java的实验性JIT编译器Graal
Graal 是一个以 Java 为主要编程语言,面向 Java bytecode 的编译器。与用 C++ 实现的 C1 及 C2 相比,它的模块化更加明显,也更加容易维护。Graal 既可以作为动态编译器,在运行时编译热点方法;亦可以作为静态编译器,实现 AOT 编译。在 JDK 10 中,Graal 作为试验性 JIT compiler 一同发布
jdk11(2018年9月 LTS)
北京时间 2018 年 9 月 26 日,Oracle 官方宣布 Java 11 正式发布。
这是 Java 大版本周期变化后的第一个长期支持版本,也是继jdk8 版本发布之后第一个LTS版本。
从时间节点来看,jdk11的发布正好处于jdk 8 免费更新到期的前夕,同时jdk9、jdk10也将陆续成为历史版本。
jdk11的新特性主要有以下几个:
- 基于嵌套的访问控制
- 标准 HTTP Client 升级
- Epsilon:低开销垃圾回收器
- 简化启动单个源代码文件的方法
- 用于 Lambda 参数的局部变量语法
- 低开销的 Heap Profiling
- 支持 TLS 1.3 协议
- ZGC:可伸缩低延迟垃圾收集器
- 飞行记录器
- 动态类文件常量
重要特性:对于JDK9和JDK10的完善,主要是对于Stream、集合等API的增强、新增ZGC垃圾收集器。
增加字符串处理方法
jdk11 增加了一系列的字符串处理方法:
// 判断字符串是否为空
" ".isBlank(); // true
// 去除字符串首尾空格
" JDK11 ".strip();// "JDK11"
// 去除字符串首部空格
" JDK11 ".stripLeading(); // "JDK11 "
// 去除字符串尾部空格
" JDK11 ".stripTrailing(); // " JDK11"
// 重复字符串多少次
"JDK11 ".repeat(3); // "JDK11 JDK11 JDK11 "
// 返回由行终止符分隔的字符串集合
"A\nB\nC".lines().count(); // 3
Files.readString() 和 Files.writeString()
在jdk11中,Files 类中新增 readString 和 writeString 静态方法可以更容易读取和写入文件。
//把字符串写入文件
Path filePath = Files.writeString(Files.createTempFile(tempDir, "demo", ".txt"), "Sample text");
//读取文件内容为字符串
String fileContent = Files.readString(filePath);
assertThat(fileContent).isEqualTo("Sample text");
Collection.toArray()
在 Java 11 之前,Collection 接口提供了两个 toArray() 方法来将集合转换为数组。
List<String> list = List.of("foo", "bar", "baz");
//返回一个 Object 数组,由于类型擦除,在运行时不再知道 list 的类型信息。
Object[] strings1 = list.toArray();
//需要一个请求类型的数组。如果此数组至少与集合一样大,则元素将存储在此数组中 (strings2a)。否则,将创建所需大小的新数组 (strings2b)。
String[] strings2a = list.toArray(new String[list.size()]);
String[] strings2b = list.toArray(new String[0]);
从 Java 11 开始,我们还可以编写以下代码:
String[] strings = list.toArray(String[]::new);
此方法允许 Collection 类使用传递的数组构造函数引用创建必要大小的数组。
在 Java 11 中Collection接口新增了一个 default 方法,用 generator 创建一个空数组,然后调用现有的 toArray() 方法:
default <T> T[] toArray(IntFunction<T[]> generator) {
return toArray(generator.apply(0));
}
Optional.isEmpty()
Optional是一个容器对象,它可能包含也可能不包含非空值。
如果不存在任何值,则该对象被认为是空的。
isPresent()方法如果值存在则返回true,否则返回false。
isEmpty()方法与isPresent()方法相反,如果存在值则返回false,否则返回true
所以无论如何都不要写否定条件。适当时使用这两种方法中的任何一种。
public static void main(String[] args) {
String currentTime = null;
assertTrue(!Optional.ofNullable(currentTime).isPresent());
assertTrue(Optional.ofNullable(currentTime).isEmpty());
currentTime = "12:00 PM";
assertFalse(!Optional.ofNullable(currentTime).isPresent());
assertFalse(Optional.ofNullable(currentTime).isEmpty());
}
允许在隐式类型 lambda 表达式的参数中使用var
在理解隐形lambda表达式之前,我们先来看下显式类lambda表示式。
我们先来看个示例:
(List<String> l, String s) -> l.add(s);
在实例中,显式表示指定了 lambda 参数 l 和 s 的数据类型,即 List 和 String。
但是,编译器也可以从上下文派生类型,因此也允许使用以下 隐式类型表示法:
(List<String> l, String s) -> l.add(s);
从 Java 11 开始,我们可以使用 Java 10 中引入的“var”关键字来代替显式类型:
(var l, var s) -> l.add(s);
支持TLS 1.3 协议
实现TLS协议1.3版本, 替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能, 在安全性和性能方面也做了很多提升。
HTTP Client
在jdk11之前,使用原生JDK资源,例如通过HTTP POST 发生数据需要大量代码。
public String post(String url, String data) throws IOException {
URL urlObj = new URL(url);
HttpURLConnection con = (HttpURLConnection) urlObj.openConnection();
con.setRequestMethod("POST");
con.setRequestProperty("Content-Type", "application/json");
// Send data
con.setDoOutput(true);
try (OutputStream os = con.getOutputStream()) {
byte[] input = data.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// Handle HTTP errors
if (con.getResponseCode() != 200) {
con.disconnect();
throw new IOException("HTTP response status: " + con.getResponseCode());
}
// Read response
String body;
try (InputStreamReader isr = new InputStreamReader(con.getInputStream());
BufferedReader br = new BufferedReader(isr)) {
body = br.lines().collect(Collectors.joining("n"));
}
con.disconnect();
return body;
}
在 JDK 11 中 Http Client API 得到了标准化的支持。使用HTTPClient编写更短且更优雅的代码如下:
//方式一: 同步
public String post(String url, String data) throws IOException, InterruptedException {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create(url))
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString(data))
.build();
HttpResponse<String> response = client.send(request, BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new IOException("HTTP response status: " + response.statusCode());
}
return response.body();
}
//异步
public void postAsync(
String url, String data, Consumer<String> consumer, IntConsumer errorHandler) {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request =
HttpRequest.newBuilder()
.uri(URI.create(url))
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString(data))
.build();
client
.sendAsync(request, BodyHandlers.ofString())
.thenAccept(
response -> {
if (response.statusCode() == 200) {
consumer.accept(response.body());
} else {
errorHandler.accept(response.statusCode());
}
});
}
作为JDK11中正式推出的新Http连接器,支持的功能还是比较新的,主要的特性有:
(1)完整支持HTTP 2.0 或者HTTP 1.1
(2)支持 HTTPS/TLS
(3)有简单的阻塞使用方法
(4)支持异步发送,异步时间通知
(5)支持WebSocket
(6)支持响应式流
HTTP2.0其他的客户端也能支持,而HttpClient使用CompletableFuture作为异步的返回数据。WebSocket的支持则是HttpClient的优势。响应式流的支持是HttpClient的一大优势。
HttpClient中的NIO模型、函数式编程、CompletableFuture异步回调、响应式流让HttpClient拥有极强的并发处理能力,所以其性能极高,而内存占用则更少。
飞行记录器:JFR
Java飞行记录器(Java Flight Recorder)已经变成JDK 11的一部分了,之前它是一个商业功能,但是伴随JDK 11发布,它从OracleJDK开源到了OpenJDK。
飞行记录器类似飞机上的黑盒子,是一种低开销的事件信息收集框架,主要用于对应用程序和 JVM 进行故障检查、分析。飞行记录器记录的主要数据源于应用程序、JVM 和 OS,这些事件信息保存在单独的事件记录文件中,故障发生后,能够从事件记录文件中提取出有用信息对故障进行分析
Epsilon:低开销垃圾回收器
新增的垃圾回收器,一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间
jdk12(2019年3月)
jdk12的新特性主要有以下几个:
- 新功能和库的更新
- JVM常量API
- 默认CDS归档
- Microbenchmark测试套件
- 新的平台支持
- 移除多余ARM64实现
- JVM 优化
- G1的可中断 mixed GC
- G1归还不使用的内存
- 新功能的预览和实验
- 低暂停时间垃圾收集器(实验)
- Switch 表达式 (预览版本)
重要特性:switch表达式语法扩展、G1收集器优化、新增Shenandoah GC垃圾回收算法。
G1 收集器优化
jdk12 为垃圾收集器G1 带来了两项更新:
- 可中止的混合收集集合
为了达到用户提供的停顿时间目标,通过把要被回收的区域集(混合收集集合)拆分为强制和可选部分,使 G1 垃圾回收器能中止垃圾回收过程。G1 可以中止可选部分的回收以达到停顿时间目标。 - 集市返回未使用的已分配内存
由于 G1 尽量避免完整的 GC,并且仅基于 Java 堆占用和分配活动来触发并发周期,因此在许多情况下,除非从外部强制执行,否则它不会返还 Java 堆内存。JDK 12增强了 G1 GC,可以在空闲时自动将 Java 堆内存返回给操作系统。
jdk13(2019年9月)
jdk13的新特性主要有以下几个:
- 新功能和库的更新
- 动态应用程序类-数据共享
- Socket API 重构
- JVM 优化
- 增强 ZGC 释放未使用内存
- 新功能预览
- Switch 表达式扩展(预览功能)
- 文本块(预览功能)
重要特性:ZGC优化,释放内存还给操作系统、socket底层实现引入NIO。
SocketAPI 重构
Java 中的 Socket API 已经存在了二十多年了,尽管这么多年来,一直在维护和更新中,但是在实际使用中遇到一些局限性,并且不容易维护和调试。
Java Socket API(java.net.ServerSocket 和 java.net.Socket)包含允许监听控制服务器和发送数据的套接字对象。
可以使用 ServerSocket 来监听连接请求的端口,一旦连接成功就返回一个 Socket 对象,可以使用该对象读取发送的数据和进行数据写回操作,而这些类的繁重工作都是依赖于 SocketImpl 的内部实现,服务器的发送和接收两端都基于 SOCKS 进行实现的。
在 Java 13 之前,通过使用 PlainSocketImpl 作为 SocketImpl 的具体实现。
ava 13 中的新底层实现,引入 NioSocketImpl 的实现用以替换 SocketImpl 的PlainSocketImpl 实现,此实现与 NIO(新 I/O)实现共享相同的内部基础结构,并且与现有的缓冲区高速缓存机制集成在一起,因此不需要使用线程堆栈。
除此,还可以使用java.lang.ref.Cleaner 机制来关闭套接字(如果 SocketImpl 实现在尚未关闭的套接字上被进行了垃圾收集),以及在轮询时套接字处于非阻塞模式时处理超时操作。
增强ZGC释放未使用内存
ZGC 是 Java 11 中实验性的引入的最为瞩目的垃圾回收器,是一种可伸缩、低延迟的垃圾收集器,
ZGC 主要用来改善 GC 停顿时间,并支持几百 MB 至几个 TB 级别大小的堆,并且应用吞吐能力下降不会超过 15%,目前只支持 Linux/x64 位平台的这样一种新型垃圾收集器。
通过在实际中的使用,发现 ZGC 收集器中并没有像 Hotspot 中的 G1 和 Shenandoah 垃圾收集器一样,能够主动将未使用的内存释放给操作系统的功能。对于大多数应用程序来说,CPU 和内存都属于有限的紧缺资源,特别是现在使用的云上或者虚拟化环境中。
如果应用程序中的内存长期处于空闲状态,并且还不能释放给操作系统,这样会导致其他需要内存的应用无法分配到需要的内存,而这边应用分配的内存还处于空闲状态,处于”忙的太忙,闲的太闲”的非公平状态,并且也容易导致基于虚拟化的环境中,因为这些实际并未使用的资源而多付费的情况。由此可见,将未使用内存释放给系统主内存是一项非常有用且亟需的功能。
ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。
在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用。同时释放这些未使用的内存给操作系统不会导致堆大小缩小到参数设置的最小大小以下,如果将最小和最大堆大小设置为相同的值,则不会释放任何内存给操作系统。
Java 13 中对 ZGC 的改进,主要体现一下几点:
(1)释放未使用内存给操作系统;
(2)支持最大堆大小为16TB;
(3)添加参数:-XX:SoftMaxHeapSize 来软限制堆大小
Java 13 中,ZGC 内存释放功能,默认情况下是开启的,不过可以使用参数:-XX:-ZUncommit显式关闭,同时如果将最小堆大小 (-Xms) 配置为等于最大堆大小 (-Xmx),则将隐式禁用此功能。
还可以使用参数:-XX:ZUncommitDelay = (默认值为 300 秒)来配置延迟释放,此延迟时间可以指定释放多长时间之前未使用的内存。
jdk14(2020年3月)
jdk14的新特性主要有以下几个:
-
语言特性增强
- Switch 表达式(正式版)
-
新功能和库的更新
- 改进 NullPointerExceptions 提示信息
-
旧功能的删除和弃用
- 删除 pack200 和 unpack200 工具
-
JVM 相关
- G1 的 NUMA 可识别内存分配
- 删除 CMS 垃圾回收器
- ZGC 支持 MacOS 和 Windows 系统(实验阶段)
- 弃用 ParallelScavenge 和 SerialOld GC 的组合使用
-
新功能的预览和实验
- instanceof 模式匹配(预览阶段)
- Record 类型(预览功能)
- 文本块(第二预览版本)
- 打包工具(孵化器版本)
- 外部存储器访问 API(孵化器版)
Switch 表达式(正式版)
在jdk12之前,传统的Switch语句写法如下:
public static void main(String[] args) {
String season = "spring";
switch(season){
case "spring":
PrintOut.print("春暖花开");
break;
case "summer":
PrintOut.print("酷暑难耐");
break;
case "autumn":
PrintOut.print("艳阳高照");
break;
case "winter":
PrintOut.print("白雪皑皑");
break;
default:
PrintOut.print("四季如春");
break;
}
}
在 Java 12 中引入了 Switch 表达式作为预览特性,关于 Switch 表达式的写法改进为如下:
public static void main(String[] args) {
String season = "spring";
switch(season){
case "spring" -> PrintOut.print("春暖花开");
case "summer" -> PrintOut.print("酷暑难耐");
case "autumn" -> PrintOut.print("艳阳高照");
case "winter"-> PrintOut.print("白雪皑皑");
default -> PrintOut.print("四季如春");
}
}
在 Java 13 中对 Switch 表达式做了增强改进,在块中引入了 yield 语句来返回值,而不是使用 break。
这意味着,有返回值的Switch 表达式应该使用 yield,而 不返回值的Switch 语句应该使用 break。但是只是处于预览状态。
JDK13在简化的基础上增加了返回值:
public static void main(String[] args) {
String season = "spring";
String des =switch(season){
case "spring" -> "春暖花开";
case "summer" ->"酷暑难耐";
case "autumn" -> "艳阳高照";
case "winter"-> "白雪皑皑";
default -> "四季如春";
};
PrintOut.print(des);
}
yield 返回值形式如下:
public String getSeasondes(String season){
return switch (season){
case "spring" :
yield "春暖花开";
case "summer" :
yield "酷暑难耐";
case "autumn":
yield "艳阳高照";
case "winter":
yield "白雪皑皑";
default :
yield "四季如春";
};
}
Java 12 和 Java 13 中Switch 表达式的增强功能,在jdk14中终于成为稳定版本,能够正式使用。
switch 表达式将之前 switch 语句从编码方式上简化了不少,但是还是需要注意下面几点:
(1)需要保持与之前 switch 语句同样的 case 分支情况。
(2)之前需要用变量来接收返回值,而现在直接使用 yield 关键字来返回 case 分支需要返回的结果。
(3)现在的 switch 表达式中不再需要显式地使用 return、break 或者 continue 来跳出当前分支。
(4)现在不需要像之前一样,在每个分支结束之前加上 break 关键字来结束当前分支,如果不加,则会默认往后执行,直到遇到 break 关键字或者整个 switch 语句结束,在 Java 14 表达式中,表达式默认执行完之后自动跳出,不会继续往后执行。
(5)对于多个相同的 case 方法块,可以将 case 条件并列,而不需要像之前一样,通过每个 case 后面故意不加 break 关键字来使用相同方法块。
使用 switch 表达式来替换之前的 switch 语句,确实精简了不少代码,提高了编码效率,同时也可以规避一些可能由于不太经意而出现的意想不到的情况。
改进 NullPointerExceptions提示信息
应该每位开发者在实际编码过程中都经历过NullPointerException的痛,每当遇到这种异常的时候,都需要根据打印出来的详细信息来分析、定位出现问题的原因,以在程序代码中规避或解决。
public class Npe {
@Test
public void npeTest() {
Animal animal = new Animal();
animal.fly.fly();
}
class Animal{
Fly fly;
}
class Fly{
public void fly(){
PrintOut.print("一行白鹭上青天");
}
}
}
直接运行会提示一下的错误:

java.lang.NullPointerException
at com.th.test.Npe.npeTest(Npe.java:9)
针对这样的空指针异常打印,如果代码比较简单,并且异常信息中也打印出来了行号信息,开发者可以很快速定位到出现异常位置。
但是对于一些复杂或者嵌套的情况下出现 NullPointerException 时,仅根据打印出来的信息,很难判断实际出现问题的位置,就如示例代码中,就无法判断出来是animal是null还是fly是null。
jdk14中增强了对NullPointerException异常的处理,通过分析程序的字节码信息,能够做到准确的定位到出现 NullPointerException 的变量,并且根据实际源代码打印出详细异常信息。这对于开发者来说是一个福音。
这个功能需要通过选项-XX:+ShowCodeDetailsInExceptionMessages启用,如下所示:
-XX:+ShowCodeDetailsInExceptionMessages
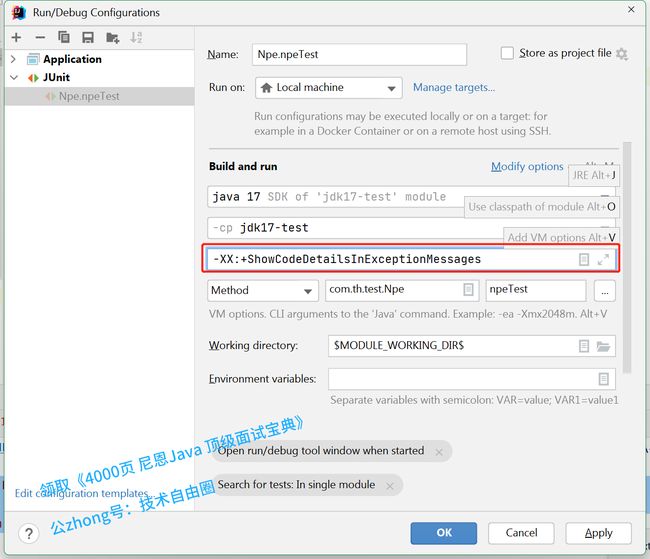
输出的信息如下所示。错误消息明确的指出了animal.fly为null。

java.lang.NullPointerException: Cannot invoke "com.th.test.Npe$Fly.fly()" because "animal.fly" is null
at com.th.test.Npe.npeTest(Npe.java:9)
......
可以看出,改进之后的 NullPointerException 信息,能够准确打印出具体哪个变量导致的 NullPointerException,减少了由于仅带行号的异常提示信息带来的困惑。该改进功能可以通过如下参数开启。
该增强改进特性,不仅适用于属性访问,还适用于方法调用、数组访问和赋值等有可能会导致 NullPointerException 的地方。
删除 CMS 垃圾回收器
CMS 是老年代垃圾回收算法,通过标记-清除的方式进行内存回收,在内存回收过程中能够与用户线程并行执行。
CMS 回收器可以与 Serial 回收器和 Parallel New 回收器搭配使用,CMS 主要通过并发的方式,适当减少系统的吞吐量以达到追求响应速度的目的,比较适合在追求 GC 速度的服务器上使用。
因为 CMS 回收算法在进行 GC 回收内存过程中是使用并行方式进行的,如果服务器 CPU 核数不多的情况下,进行 CMS 垃圾回收有可能造成比较高的负载。
同时在 CMS 并行标记和并行清理时,应用线程还在继续运行,程序在运行过程中自然会创建新对象、释放不用对象,所以在这个过程中,会有新的不可达内存地址产生,而这部分的不可达内存是出现在标记过程结束之后,本轮 CMS 回收无法在周期内将它们回收掉,只能留在下次垃圾回收周期再清理掉。这样的垃圾就叫做浮动垃圾。
由于垃圾收集和用户线程是并发执行的,因此 CMS 回收器不能像其他回收器那样进行内存回收,需要预留一些空间用来保存用户新创建的对象。
由于 CMS 回收器在老年代中使用标记-清除的内存回收策略,势必会产生内存碎片,内存当碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有空间但不能再保存对象的情况。
所以,在 Java 9 中已经决定放弃使用 CMS 回收器了,而这次在 Java 14 中彻底禁用CMS,并删除与 CMS 有关的选项,同时清除与 CMS 有关的文档内容,至此曾经辉煌一度的 CMS 回收器,也将成为历史。
当在 Java 14 版本中,通过使用参数:-XX:+UseConcMarkSweepGC,尝试使用 CMS 时,将会收到下面信息:

弃用 ParallelScavenge 和 SerialOld GC 的组合使用
由于 Parallel Scavenge 和 Serial Old 垃圾收集算法组合起来使用的情况比较少,并且在年轻代中使用并行算法,而在老年代中使用串行算法,这种并行、串行混搭使用的情况,本身已属罕见同时也很冒险。
由于这两 GC 算法组合很少使用,却要花费巨大工作量来进行维护,所以在 Java 14 版本中,考虑将这两 GC 的组合弃用。
具体弃用情况如下,通过弃用组合参数:-XX:+UseParallelGC -XX:-UseParallelOldGC,来弃用年轻代、老年期中并行、串行混搭使用的情况;同时,对于单独使用参数:-XX:-UseParallelOldGC的地方,也将显示该参数已被弃用的警告信息。
jdk15(2020年9月)
jdk15的新特性主要有以下几个:
- 语言特性增强
- 文本块(Text Blocks)
- 新功能和库的更新
- Edwards-Curve 数字签名算法 (EdDSA)
- 隐藏类 Hidden Classes
- 重新实现 DatagramSocket API
- JVM 优化
- ZGC: 可伸缩低延迟垃圾收集器
- 禁用偏向锁定
- Shenandoah:低暂停时间垃圾收集器(转正)
- 旧功能的删除和弃用
- 移除Nashorn JavaScript引擎
- 移除了 Solaris 和 SPARC 端口
- 废除 RMI 激活
- 新功能的预览和孵化
- instanceof 自动匹配模式(第二次预览)
- 密封的类和接口(预览)
- 外部存储器访问 API(二次孵化器版)
- Records (二次预览)
文本块
早些时候,为了在代码中嵌入 JSON,我们将其声明为字符串文字:
String json = "{\r\n" + "\"name\" : \"lingli\",\r\n" + "\"website\" : \"https://www.alibaba.com/\"\r\n" + "}";
jdk13预览发布文本块功能,jdk15正式发布文本框功能。文本块用来解决多行文本的问题,文本块以三重双引号开头,并以同样的以三重双引号结尾终止。
var block = """
lang: java
version: 13
dbname: mysql
ip: 192.168.9.202
usr: thtest
pwd: wekhd222
""";
// 6 行
block.lines().count();
文本块内允许插入 \ 阻止换行,如:
var block = """
lang: java\
version: 13\
dbname: mysql\
ip: 192.168.9.202\
usr: thtest\
pwd: wekhd222
""";
// 6 行
block.lines().count();
PS:每行末尾的空格会被忽略,除非主动将其替换为 /s。
隐藏类Hidden Classes
此功能可帮助需要在运行时生成类的框架。框架生成类需要动态扩展其行为,但是又希望限制对这些类的访问。
隐藏类很有用,因为它们只能通过反射访问,不能直接被其他类的字节码访问。
隐藏类可以独立于其他类加载、卸载,这可以减少框架的内存占用。
Hidden Classes 是什么呢?
Hidden Classes就是不能直接被其他class的二进制代码使用的class。
Hidden Classes主要被一些框架用来生成运行时类,但是这些类不是被用来直接使用的,而是通过反射机制来调用。
比如在JDK8中引入的lambda表达式,JVM并不会在编译的时候将lambda表达式转换成为专门的类,而是在运行时将相应的字节码动态生成相应的类对象。
另外使用动态代理也可以为某些类生成新的动态类。
动态生成的类具有什么特征呢?
- 不可发现性:为某些静态的类动态生成的动态类,所以我们希望把这个动态生成的类看做是静态类的一部分。
- 访问控制:希望在访问控制静态类的同时,也能控制到动态生成的类。
- 生命周期:动态生成类的生命周期一般都比较短,我们并不需要将其保存和静态类的生命周期一致。
我们需要一些API来定义无法发现的且具有有限生命周期的隐藏类。这将提高所有基于JVM的语言实现的效率。例如:
// 可以定义隐藏类作为实现代理接口的代理类。
java.lang.reflect.Proxy
// 可以生成隐藏类来保存常量连接方法;
java.lang.invoke.StringConcatFactory
//可以生成隐藏的nestmate类,以容纳访问封闭变量的lambda主体;
java.lang.invoke.LambdaMetaFactory
普通类是通过调用ClassLoader::defineClass创建的,而隐藏类是通过调用Lookup::defineHiddenClass创建的。
这使JVM从提供的字节中派生一个隐藏类,链接该隐藏类,并返回提供对隐藏类的反射访问的查找对象。
调用程序可以通过返回的查找对象来获取隐藏类的Class对象。
可伸缩低延迟垃圾收集器ZGC 成功转正
ZGC是Jdk 11引入的新的垃圾收集器(JDK9以后默认的垃圾回收器是G1),经过了多个实验阶段,终于Jdk 15中成为正式特性。
ZGC是一个重新设计的并发的垃圾回收器,可以极大的提升GC的性能。支持任意堆大小而保持稳定的低延迟(10ms以内),性能非常可观。
目前默认垃圾回收器仍然是 G1,后续很有可以能将ZGC设为默认垃圾回收器。jdk15之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseZGC来启用ZGC,从jdk15开始只需要-XX:+UseZGC就可以。
ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 在Linux/X64 平台上, 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。
ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:对象的分配速率,要保证在 GC 的时候,堆中有足够的内存分配新对象。一般来说,给 ZGC 的内存越多越好,但是也不能浪费内存,所以要找到一个平衡。
禁用偏向锁
JDK 15 中,默认情况下禁用偏向锁,并弃用所有相关的命令行选项。
目标是确定是否需要继续支持偏置锁定的 高维护成本 的遗留同步优化, HotSpot虚拟机使用该优化来减少非竞争锁定的开销。
尽管某些Java应用程序在禁用偏向锁后可能会出现性能下降,但偏向锁的性能提高通常不像以前那么明显。
该特性默认禁用了biased locking (-XX:+UseBiasedLocking)。
废弃了所有相关的命令行选型 (BiasedLockingStartupDelay, BiasedLockingBulkRebiasThreshold, BiasedLockingBulkRevokeThreshold, BiasedLockingDecayTime, UseOptoBiasInlining, PrintBiasedLockingStatistics and PrintPreciseBiasedLockingStatistics)
关于锁更多的内容请参考《Java高并发编程卷2(加强版)》
低暂停时间垃圾收集器Shenandoah 成功转正
Shenandoah垃圾回收算法从 JDK 12 引入的回收算法,在jdk15中成功转正。
Shenandoah在JDK12被作为experimental引入,在JDK15变为Production。
该算法通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间。Shenandoah 的暂停时间与堆大小无关,无论堆栈是 200 MB 还是 200 GB,都具有相同的一致暂停时间。
Shenandoah适用于高吞吐和大内存场景,不适合高实时性场景。
Shenandoah算法设计目标主要是响应性和一致可控的短暂停顿,对于垃圾回收生命周期中安全点停顿(TTSP)和内存增长监控的时间开销并无帮助。
Shenandoah算法为每个Java对象添加了一个间接指针,使得GC线程能够在Java线程运行时压缩堆。
标记和压缩是同时执行的,因此我们只需要暂停Java线程在一致可控的时间内扫描线程堆栈以查找和更新对象图的根。
Shenandoah和ZGC的关系如下
- 相同点:性能几乎可认为是相同的
- 不同点:
- ZGC是Oracle JDK的。Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK
- 版本打开方式:使用-XX:+UseShenandoahGC命令行参数打开。
之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC来启用,现在只需要-XX:+UseShenandoahGC即可启用。
jdk16(2021年3月)
jdk16的新特性主要有以下几个:
- 语言特性增强
- instanceof 模式匹配(正式版)
- Records (正式版)
- 新工具和库
- Unix-Domain 套接字通道
- 对基于值的类发出警告
- 打包工具(正式版)
- 默认强封装 JDK 内部元素
- JVM 优化
- ZGC 并发线程处理
- 弹性元空间
- 新功能的预览和孵化
- 向量 API(孵化器)
- 外部链接器 API(孵化器)
- 外部存储器访问 API(第三次孵化)
- 密封类(第二预览)
- 提升 OpenJDK 开发人员的生产力
- 启用 C++14 语言特性(在 JDK 源代码中)
JDK16相当于是将JDK14、JDK15的一些特性进行了正式引入,如instanceof模式匹配(Pattern matching)、record的引入等最终到JDK16变成了final版本。
instanceof 模式匹配
模式匹配(Pattern Matching)最早在 Java 14 中作为预览特性引入,在 Java 15 中还是预览特性,在Java 16中成为正式版。模式匹配通过对 instacneof 运算符进行模式匹配来增强 Java 编程语言。
instanceof 的增强的主要目的是为了创建对象更加简单、简洁和高效,并且可读性更强、提高安全性。
instanceof 主要用来检查对象的类型,然后根据类型对目标对象进行类型转换,之后进行不同的处理、实现不同的逻辑,jdk16之前的经典写入:
if(animal instanceof Dog){
Dog dog = (Dog)animal;
dog.eat();
}else if(animal instanceof Cat){
Cat cat = (Cat)animal;
cat.eat();
}
在示例代码中, 首先需要对animal 对象进行类型判断,判断animal具体是Dog 还是Cat,因为这两种角色对应不同操作,亦即对应到的实际逻辑实现,判断完 animal类型之后,然后强制对 animal进行类型转换为局部变量,以方便后续执行属于该角色的特定操作。
上面这种写法,有下面两个问题:
- 每次在检查类型之后,都需要强制进行类型转换。
- 类型转换后,需要提前创建一个局部变量来接收转换后的结果,代码显得多余且繁琐。
对 instanceof 进行模式匹配改进之后,上面示例代码可以改写成:
if(animal instanceof Dog dog){
dog.eat();
}else if(animal instanceof Cat cat){
cat.eat();
}
首先在 if 代码块中,对 animal对象进行类型匹配,校验 animal对象是否为 Dog 类型,如果类型匹配成功,则会转换为Dog类型,并赋值给模式局部变量 dog,并且只有当模式匹配表达式匹配成功是才会生效和复制,同时这里的dog 变量只能在 if 块中使用,而不能在 else if/else 中使用,否则会报编译错误。
注意,如果 if 条件中有 && 运算符时,当 instanceof 类型匹配成功,模式局部变量的作用范围也可以相应延长,示例代码如下:
if (obj instanceof String s && s.length() > 5) {.. s.contains(..) ..}
但是这种作用范围延长,并不适用于或 || 运算符,因为即便 || 运算符左边的 instanceof 类型匹配没有成功也不会造成短路,依旧会执行到||运算符右边的表达式,但是此时,因为 instanceof 类型匹配没有成功,局部变量并未定义赋值,此时使用会产生问题。
与传统写法对比,可以发现模式匹配不但提高了程序的安全性、健壮性,另一方面,不需要显式的去进行二次类型转换,减少了大量不必要的强制类型转换。
模式匹配变量在模式匹配成功之后,可以直接使用,同时它还被限制了作用范围,大大提高了程序的简洁性、可读性和安全性。
instanceof 的模式匹配,为 Java 带来的有一次便捷的提升,能够剔除一些冗余的代码,写出更加简洁安全的代码,提高码代码效率。
Records
Records 最早在 Java 14 中作为预览特性引入,在 Java 15 中还是预览特性,在Java 16中成为正式版。
Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
在jdk14之前,在开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法。
在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。
编译器会一次性代替用户生成 getters,constructors,toString 等方法。示例代码:
public record animal(String name,int weight){
public static String fly;
public static String getFly() {
return fly;
}
}
编译后结果如下:
public recordTest() {
}
public static record animal(String name, int weight) {
public static String fly;
public animal(String name, int weight) {
this.name = name;
this.weight = weight;
}
public static String getFly() {
return fly;
}
public String name() {
return this.name;
}
public int weight() {
return this.weight;
}
}
根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征:
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法:
RecordComponent[] getRecordComponents()
boolean isRecord()
方法说明:
(1) getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
(2) isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true
ZGC 并发线程堆栈处理
ZGC是JDK 11引入的新的垃圾收集器,JDK 15 正式发布成正式特性,ZGC是一个重新设计的并发的垃圾回收器,可以极大的提升GC的性能。支持任意堆大小而保持稳定的低延迟(10ms以内),性能非常可观。
JDK 16将 ZGC 线程栈处理从安全点转移到一个并发阶段,甚至在大堆上也允许在毫秒内暂停 GC 安全点。消除 ZGC 垃圾收集器中最后一个延迟源可以极大地提高应用程序的性能和效率。
弹性元空间
将未使用的 HotSpot 类元数据(即元空间,metaspace)内存更快速地返回到操作系统,从而减少元空间的占用空间。具有大量类加载和卸载活动的应用程序可能会占用大量未使用的空间。新方案将元空间内存按较小的块分配,它将未使用的元空间内存返回给操作系统来提高弹性,从而提高应用程序性能并降低内存占用。
jdk17(2021年9月 LTS)
jdk17的新特性主要有以下几个:
- 语言特性增强
- 密封的类和接口(正式版)
- 工具库的更新
- 恢复始终严格的浮点语义
- 增强的伪随机数生成器
- 新的macOS渲染管道
- 新的平台支持
- 支持macOS AArch64
- 弃用 Applet API
- 旧功能的删除和弃用
- 弃用 Applet API
- 删除实验性 AOT 和 JIT 编译器
- 弃用安全管理器以进行删除
- 新功能的预览和孵化API
- 新增switch模式匹配(预览版)
- 外部函数和内存api (第一轮孵化)
- Vector API(第二轮孵化)
- 外部链接器 API(孵化器)
- 外部存储器访问 API(第三次孵化)
虽然JDK17也是一个LTS版本,但是并没有像JDK8和JDK11一样引入比较突出的特性,主要是对前几个版本的整合和完善。
恢复始终执行严格模式的浮点语义
严格的浮点语义是IEEE(电气和电子工程协会)为浮点计算和以各种格式存储浮点值制定了一种标准,包括单精度(32位,用于java)float、双精度(64位,用于java)double,另外一些硬件还提供扩展精度格式,以提供更高的精度和更大的指数范围。
在这样的架构下,使用扩展格式计算中间结果可能更有效,还能避免可能发生的舍入错误、上溢和下溢,但是会导致程序在此类架构上产生不同的输出,且x87浮点架构在x86机器上使用扩展精度代价很昂贵。
在JVM1.2之前浮点计算是严格要求的,也就是说浮点值的计算结果都必须表现的和标准一样,这使得在常见的x87浮点指令集平台上在需要的地方发生溢出的代价变得昂贵。
在没有上溢和下溢的情况下,如果需要得到重复的结果,java提供了一个当前已过时且未使用的关键字 strictfp ,strictfp修饰符确保浮点计算在所有平台发生上溢和下溢的地方相同,且中间值表示为IEEE单精度和双精度值。
该关键字可用于类、接口、非抽象方法。在方法上添加时内部所有计算都使用严格的浮点数学计算;在类上添加时类中所有计算都使用严格的浮点数学计算。
由于当下支持SSE2指令集的x86处理器不再需要x87浮点指令集,因此JDK17再次严格要求所有浮点计算,恢复了1.2之前的语义。
增强型伪随机数发生器
JDK 17 之前,我们可以借助 Random、ThreadLocalRandom和SplittableRandom来生成随机数。
Random类典型的使用如下:
// random int
new Random().nextInt();
/**
* description 获取指定位数的随机数
*
* @param length 1
* @return java.lang.String
*/
public static String getRandomString(int length) {
String base = "abcdefghijklmnopqrstuvwxyz0123456789";
Random random = new Random();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
int number = random.nextInt(base.length());
sb.append(base.charAt(number));
}
return sb.toString();
}
ThreadLocalRandom 类提供线程间独立的随机序列。它只有一个实例,多个线程用到这个实例,也会在线程内部各自更新状态。它同时也是 Random 的子类,不过它几乎把所有 Random 的方法又实现了一遍。示例代码如下:
public void testNextIntBounded() {
for (int bound = 2; bound < MAX_INT_BOUND; bound += 524959) {
int f = ThreadLocalRandom.current().nextInt(bound);
assertTrue(0 <= f && f < bound);
int i = 0;
int j;
while (i < NCALLS &&
(j = ThreadLocalRandom.current().nextInt(bound)) == f) {
assertTrue(0 <= j && j < bound);
++i;
}
assertTrue(i < NCALLS);
}
}
SplittableRandom 类是非线程安全,但可以 fork 的随机序列实现,适用于拆分子任务的场景。示例代码如下:
public void testNextLong() {
SplittableRandom sr = new SplittableRandom();
long f = sr.nextLong();
int i = 0;
while (i < NCALLS && sr.nextLong() == f)
++i;
assertTrue(i < NCALLS);
}
JDK7为伪随机数生成器(pseudorandom number generator,RPNG,又称为确定性随机位生成器)提供新的接口类型和实现,使程序使用各种PRNG算法更加容易,更好的支持流式编程。
提供了一个新的接口 RandomGenerator ,为所有PRNG算法提供统一的API,同时提供了一个新的类 RandomGeneratorFactory 来构造各种 RandomGenerator 实例。
通过RandomGeneratorFactory.of(“随机数生成算法”) 方法获得生成器
public static void main(String[] args) {
RandomGeneratorFactory<RandomGenerator> randomgf = RandomGeneratorFactory.of("L128X1024MixRandom");
RandomGenerator randomGenerator = randomgf.create(System.currentTimeMillis());
for (int i = 0; i < 10; i++){
PrintOut.print(randomGenerator.nextInt(10));
}
}
执行结果:
6
4
4
5
0
2
5
5
1
4
RandomGeneratorFactory.all() 方法可以获得所有随机数生成算法,输出所有随机算法名称:
// 获取所有随机数生成算法
RandomGeneratorFactory.all().forEach(e ->PrintOut.print(e.group()+"-"+e.name()));
支持的随机数生成算法如下:
LXM-L32X64MixRandom
LXM-L128X128MixRandom
LXM-L64X128MixRandom
Legacy-SecureRandom
LXM-L128X1024MixRandom
LXM-L64X128StarStarRandom
Xoshiro-Xoshiro256PlusPlus
LXM-L64X256MixRandom
Legacy-Random
Xoroshiro-Xoroshiro128PlusPlus
LXM-L128X256MixRandom
Legacy-SplittableRandom
LXM-L64X1024MixRando
Process finished with exit code 0
强封装JDK的内部API
java内部的大部分类,除了关键的内部API,如sun.misc.Unsafe类,都进行强封装,默认情况下不允许开发人员利用反射等手段去访问内部非public的类、成员变量等,使java更加安全。
但是可以通过设置参数–add-export或–add-opens来指定哪些类可以被访问。
密封类sealed class,限制抽象类的实现
封闭类可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。这个特性由Java 15的预览版本晋升为正式版本。
密封类可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。
这个特性由JDK 15的预览版本在JDK 17晋升为正式版本。
密封类引入了sealedclass或interface,这些class或者interfaces只允许被指定的类或者interface进行扩展和实现。
使用修饰符sealed,可以将一个类声明为密封类。
密封的类使用关键字permits列出可以直接扩展它的类。子类可以是最终的,非密封的或密封的。
例如:需要限制Animal类只鞥能被Dog、Cat、Tiger 这三个类继承,不能被其他类继承,可以按如下方法来做
// 添加sealed修饰符,permits后面跟上只能被继承的子类名称
public sealed class Animal permits Dog,Cat,Tiger{
}
// 子类可以被修饰为final
final class Dog extends Animal{
}
// 子类可以被修饰为 non-sealed,此时Tiger类就成了普通类,谁都可以继承它
non-sealed class Tiger extends Animal{
}
// 任何类都可以继承Tiger,
class Tigress extends Tiger{
}
移除实验性的 AOT 和 JIT 编译器
实验性的基于 Java 的提前 (AOT) 和即时 (JIT) 编译器是实验性功能,并未得到广泛采用。
作为可选,它们已经从 JDK 16 中删除。这个 JEP 从 JDK 源代码中删除了这些组件。
jdk18(2022年3月)
jdk18的新特性主要有以下几个:
- 工具库的更新
- 指定 UTF-8 作为标准 Java API 的默认字符集
- 引入一个简单的 Web 服务器
- 支持在 Java API 文档中加入代码片段
- 用方法句柄重新实现核心反射
- 互联网地址解析 SPI
- 旧功能的删除和弃用
- 弃用 Finalization 功能
- 新功能的预览和孵化API
- 外部函数和内存 API(第二次孵化)
- switch 模式匹配表达式(第二次孵化)
- Vector API(第三次孵化)
指定 UTF-8 作为标准 Java API 的默认字符集
JDK 一直都是支持 UTF-8 字符编码,这次是把 UTF-8 设置为了默认编码,也就是在不加任何指定的情况下,默认所有需要用到编码的 JDK API 都使用 UTF-8 编码,这样就可以避免因为不同系统,不同地区,不同环境之间产生的编码问题。
互联网地址解析 SPI
对于互联网地址解析 SPI,为主机地址和域名地址解析定义一个 SPI,以便 java.net.InetAddress 可以使用平台内置解析器以外的解析器。
InetAddress inetAddress = InetAddress.getByName("www.wdbyte.com");
System.out.println(inetAddress.getHostAddress());
// 输出
// 106.14.229.49
jdk19(2022年9月)
jdk19的新特性主要有以下几个:
- 记录模式 (预览版)
- Linux/RISC-V 移植
- 外部函数和内存 API (预览版)
- 虚拟线程(预览版)
- Vector API (第四次孵化)
- 结构化并发(孵化阶段)
jdk20(2023年3月)
jdk20的新特性主要有以下几个:
- 作用域值(第一轮孵化)
- 记录模式 (第二轮预览)
- switch 模式匹配(第四轮预览)
- 外部函数和内存 API(第二轮预览)
- 虚拟线程(第二轮预览)
- 结构化并发(第二轮孵化)
- 结构化并发(第五轮孵化)
JVM GC 发展回顾
- JDK9: 设置G1为JVM默认垃圾收集器
- JDK10:并行全垃圾回收器 G1,通过并行Full GC, 改善G1的延迟。目前对G1的full GC的实现采用了单线程-清除-压缩算法。JDK10开始使用并行化-清除-压缩算法。
- JDK11:推出ZGC新一代垃圾回收器(实验性),目标是GC暂停时间不会超过10ms,既能处理几百兆的小堆,也能处理几个T的大堆。
- JDK14 :删除CMS垃圾回收器;弃用 ParallelScavenge + SerialOld GC 的垃圾回收算法组合;将 zgc 垃圾回收器移植到 macOS 和 windows 平台
- JDk 15 : ZGC (JEP 377) 和Shenandoah (JEP 379) 不再是实验性功能。默认的 GC 仍然是G1。
- JDK16:增强ZGC,ZGC获得了 46个增强功能 和25个错误修复,控制stw时间不超过10毫秒
性能指标测试
吞吐量比较
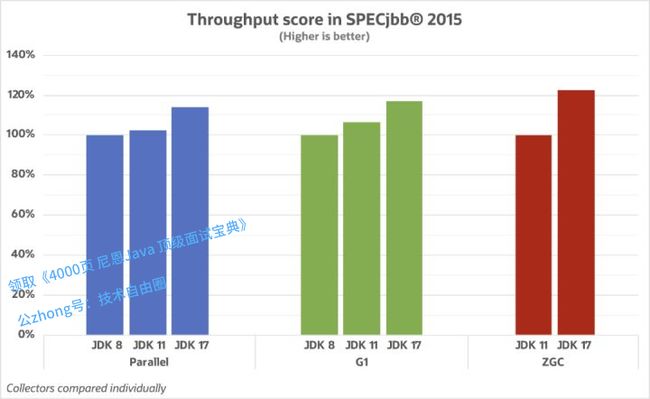 各GC 吞吐 量比较
各GC 吞吐 量比较
在吞吐量方面,Parallel 中 JDK 8 和 JDK 11 差距不大,JDK 17 相较 JDK 8 提升 15% 左右;G1 中 JDK 17 比 JDK 8 提升 18%;ZGC 在 JDK 11[2]引入,JDK 17 对比JDK 11 提升超过 20%。
延迟比较
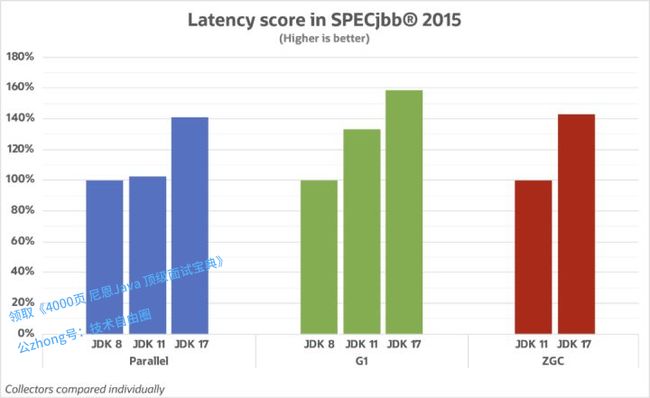 各GC延迟比较
各GC延迟比较
在 GC 延迟方面,JDK 17 的提升更为明显。我们可以看到为缩短 GC 暂停时间所做的努力都得到了回报,很多提升都是因为 GC 的改进。
在 Parallel 中 JDK 17 对比 JDK 8 和JDK 11 提升 40%;在 G1 中,JDK 11 对比 JDK 8 提升 26%,JDK 17 对比 JDK 8 提升接近 60%!ZGC 中 JDK 17 对比 JDK 11 提升超过 40%。
暂停时间对比
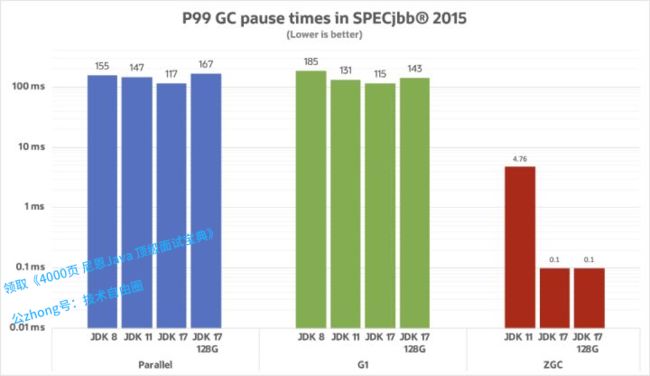 各GC 暂停时间对比
各GC 暂停时间对比
我们可以看到JDK 17 中的 ZGC 远低于目标:亚毫秒级的暂停时间。
G1 的目标是在延迟和吞吐量之间保持平衡,远低于其默认的目标:200 毫秒的暂停时间。
ZGC 的设计会保证暂停时间不随堆的大小而改变,我们可以清楚地看到当堆扩大到 128GB 时的情况。
从暂停时间的角度来看,G1比Parallel 更善于处理更大的堆,因为它能够保证暂停时间满足特定目标。
资源占用
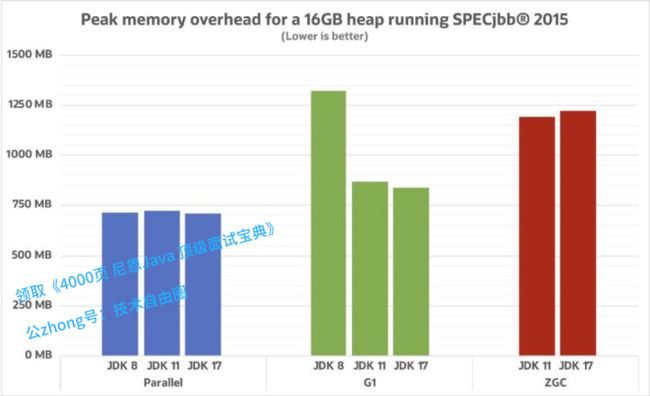 各GC资源占用情况
各GC资源占用情况
上图比较了三个不同收集器原生内存的使用峰值。
由于从这个角度来看 Parallel 和 ZGC 都非常稳定,因此我们应该看一看原始数字。
我们可以看到 G1 在这方面确实有所改进,主要原因是所有功能和增强功能都提高了记忆集管理的效率 。
总结:无论使用哪种收集器,与旧版本相比,JDK 17 [3]的整体性能都有很大的提升。在 JDK 8 中,Parallel是默认设置,但在 JDK 9 中改为了 G1。从那以后,G1 的改进速度就超过了 Parallel,但在有些情况下可能 Parallel 仍然是最佳选择。而 ZGC(JDK 15 正式使用)的加入,成为了第三种高性能替代方案。
堆内存布局的变化
JVM 堆内存布局最为经典的是分代模型,即年轻代和老年代进行区分,不同的区域采用的回收算法和策略也完全不一样。
在一个在线应用(如微服务形态)的 request <-> response 模型中,所产生的对象(Object)绝大多数是瞬时存活的对象,所以大部分的对象在年轻代就会被相对简单、轻量、且高频的 Minor GC 所回收。
在年轻代中经过几次 Minor GC 若依然存活则会将其晋升到老年代。在
老年代中,相比较而言由于对象存活多、内存容量大,所以所需要的 GC 时间相对也会很长,同时由于每一次的回收会伴随着长时间的 Stop-The-World (简称STW)出现。
在内存需求比较大且对于时延和吞吐要求很高的应用中,其老年代的表现就会显得捉襟见肘。而且由于不同的分代所采用的回收算法一般都不一样,随着业务复杂度的增加,GC 行为变得越来越难以理解,调优处理也就愈发的复杂 。
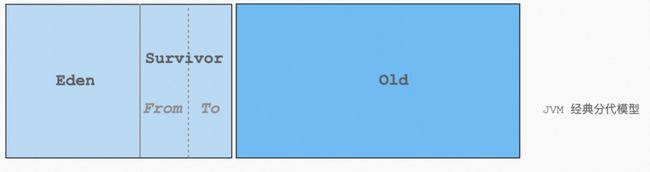
堆内存分布情况
单纯从堆内存布局来理解,一个简单的逻辑是内存区域越小,回收效率越高,经典分代模型中的 Young 区已经印证了这一点。为了解决上述问题,G1 算法横空出世,引出基于区域(Region)的布局模型,带来的变化是内存在物理上不再根据对象的“年龄”来划分布局,而是默认全部划分成等大小的 Region 和专门用来管理超级大对象的独占 Region,年轻代和老年代不再是一个物理划分,只是一个 Region 的一个属性。直观理解上,除了能管理的内存更大(G1 理论值 64G)之外,这样带来一个显而易见的好处就是可以预控制一次 FullGC 的 STW 的时间,因为 Region 大小一致,则可以根据停顿时间来推算这次 GC 需要回收的 Region 个数,而没有必要每次都将所有的 Region 全部清理完毕。
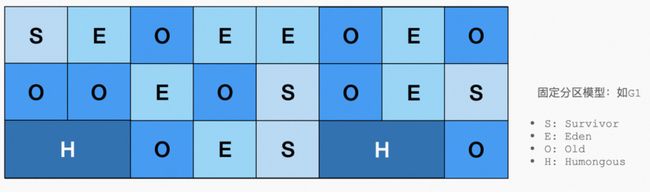 固定分区模型
固定分区模型
随着这项技术的进一步发展,到了现代化的 Pauseless(ZGC) 的算法场景中,有些算法暂时没有了分代的概念,同时 Region 按照大小划分了 Small/Medium/Large 三个等级,更精细的 Region 管理,也进一步来更少的内存碎片和内存利用率的提升、及其 STW 停顿时间更精准的预测与管理
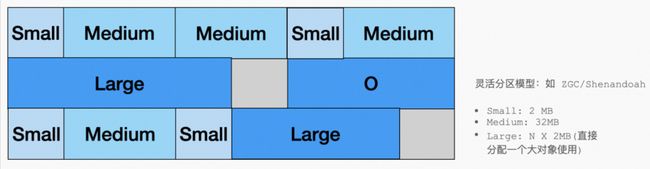 灵活分区模型
灵活分区模型
线程模型变化
在说线程模型之前,需要先了解一下GC 线程与业务线程,GC 线程是指 JVM 专门用来处理 GC 相关任务的线程,这在 JVM 启动时就已经决定。
在传统的串行算法中,是指只有一个 GC 线程在工作。在并行(Parallel)的算法中,存在多个 GC 线程一起工作的情况(CMS 中 GC 线程个数默认是 CPU 的核数)。
同时一些算法的某些阶段中(如:CMS 的并发标记阶段),GC 线程也可以和业务线程一起工作;这个机制就缩短了整体 STW 的时间,这也是我们所说的并发(Concurrent) 模式。
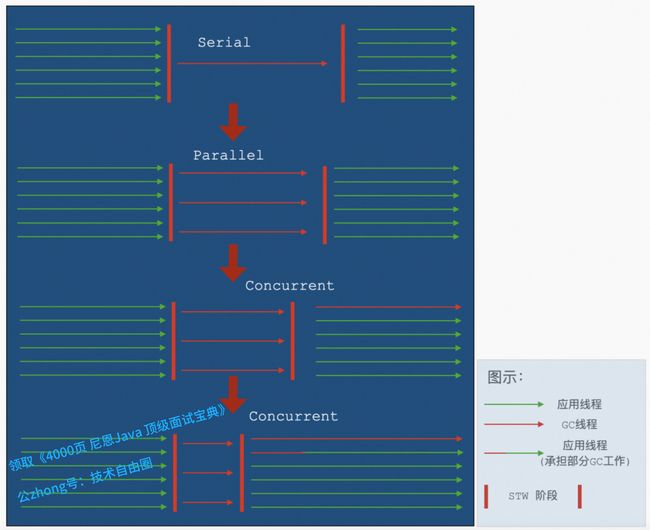
在现代化的 GC 算法中,并不是所有和 GC 相关的任务都只能由 GC 线程完成,如 ZGC 中的 Remap 阶段,业务线程可以通过内存读屏障(Read Barrier),来矫正对象在此阶段因为被重新分配到新区域后的指针变化,进而进一步减少 STW 的时间。
收集行为变化
收集行为是指的在识别出需要被收集的对象之后,JVM 对于对象和所在内存区域如何进行处理的行为。从早期版本至今,大致分为以下几个阶段:
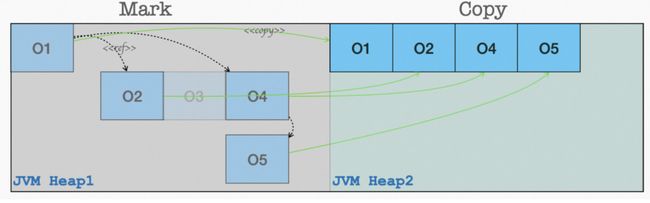
第一阶段:Mark Copy,指直接将存活对象从原来的区域拷贝至另外一个区域。这是一种典型的空间换时间的策略,好处显而易见:算法简单、停顿时间短、且调参优化容易;但同时也带来了近乎一倍的空间闲置。在早期的 GC 算法使用的是经典的分代模型。其中对于年轻代 Survivor 区的收集行为便是这种策略。如下图所示:
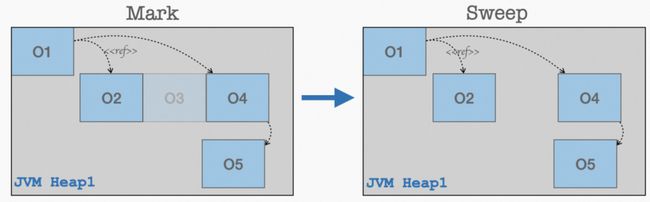
第二阶段:Mark Sweep:为了减少空间成倍的浪费,其中一个策略就是在原有的区域直接对对象 Mark 后进行擦除。但由于是在原来的内存区域直接进行对象的擦除,应用进程运行久了之后,会带来很多的内存碎片,其结果是内存持续增长,但真实利用率趋低。
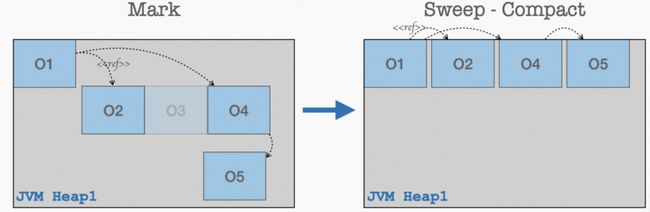
第三阶段:Mark Sweep-Compact: 这是对于 Mark Sweep 的一个改良行为,即擦除之后会对内存进行重新的压缩整理,用以减少碎片从而提升内存利用率。但是如果每次都进行整理,就会延长每次 FullGC 后的 STW 时间。所以 CMS 的策略是通过一个开关 (-XX:+UseCMSCompactAtFullCollection默认开) 和一个计数器 (-XX:CMSFullGCsBeforeCompaction默认值为 0) 进行控制,表示 FullGC 是否需要做压缩,以及在多少次 FullGC 之后再做压缩。这个两个配置配合业务形态去做调优能起到很好的效果。
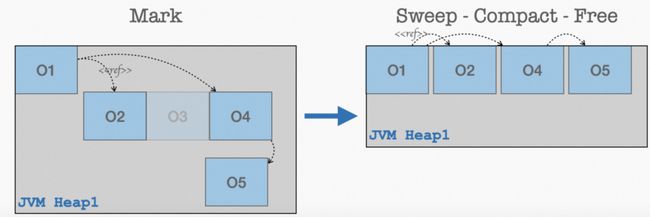
第四阶段:Mark Sweep-Compact-Free: JVM 的应用有一个“内存吞噬器”的恶名,原因之一就是在进程运行起来之后,他只会向操作系统要内存从来不会归还(典型只借不还的渣男)。不过这些在现代化的分区模型算法中开始有了改善,这些算法在 FullGC 之后,可以将整理之后的内存以区域(Region)为粒度归还给操作系统,从而降低这一个进程的资源水位,以此来提升整个宿主机的资源利用率。
说在最后
JDK相关面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
学习过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
推荐相关阅读
《10亿级用户,如何做 熔断降级架构?微信和hystrix的架构对比》
《虾皮一面:手写一个Strategy模式(策略模式)》
《问懵了…美团一面索命44问,过了就60W+》
《顶奢好文:3W字,穿透Spring事务原理、源码,至少读10遍》
《腾讯太狠:40亿QQ号,给1G内存,怎么去重?》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓