生产消费者模型
生产消费者模型概念
生产消费者模型实际上就是通过一个容器,将生产者和消费者之间的强耦合问题解决掉。
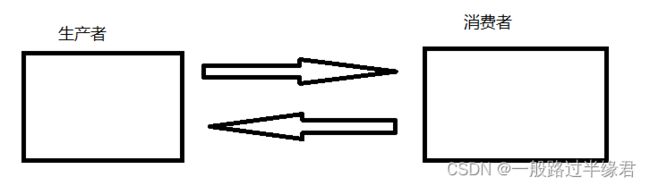
没有使用生产者消费者模型时,生产者和消费者之间直接相互联通,两者之间强耦合,若是一方更换,那另一方也需要随之更换,那样是十分不可取的。
而使用了生产者消费者模型就不会出现这样的情况。
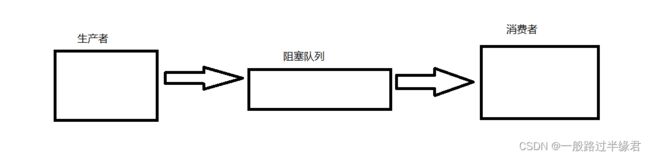
比如使用了阻塞队列使用的生产消费模型,在生产者和消费者之间有一个阻塞队列的介入,二者并不直接连接,若是一方更换也不会影响到另一方,大大减少了代码的改动。
321原则
生产者和消费者之间一个原则——“321原则”。
一般的生产消费模型都遵循该原则。
- 三种关系:生产者之间互斥,消费者之间互斥,生产者和消费者之间互斥和同步关系
- 两种角色:生产者线程和消费者线程
- 一个交易场所:一个特定结构的缓冲区
生产消费模型的特点
生产消费模型一般有两种特点
- 解耦合
- 削峰填谷
解耦合问题在开头已经说过,那么削峰填谷是怎么一回事呢?
在一般的工作场景中,有时入口服务器会出现请求暴涨的情况,但是由于入口服务器的请求计算量不大,即便计算量暴涨也不会导致服务器挂掉,但是作为响应服务器的一方的计算量很大,在没有生产消费者模型的情况下,会导致响应服务器崩溃。
而若是有生产消费模型作为中间容器,当入口服务器出现很多请求,阻塞队列会存储所有请求,而响应服务器则不需要一瞬间全部响应,而是维持原来的速度处理服务器,从而防止服务器崩溃。——削峰
像这种一瞬间出现大量请求的情况不会持续很长,等峰值过去,响应服务器不会因此减缓速度,而是按原来速度处理队列任务。——填谷
基于阻塞队列的生产消费模型
在这里就介绍基于阻塞队列的生产消费模型。
正如名字所说,该模型以阻塞队列作为容器来实现该模型。
而实现一个阻塞队列就需要队列以及两个用来阻塞的条件变量,我们先直接看代码。
#include
#include
#include
#include
using namespace std;
static int Max = 10;
template
class BlockingQueue{
public:
BlockingQueue(int MaxCap = Max)
:_MaxCap(MaxCap)
{
pthread_mutex_init(&mutex,NULL);
pthread_cond_init(&pcond,NULL);
pthread_cond_init(&ccond,NULL);
}
void Push(const T& data)
{
pthread_mutex_lock(&mutex);
//若是满了
if(is_Full())
{
pthread_cond_wait(&pcond,&mutex);
}
//此时确定有一个空位
q.push(data);
//此时确定有一个资源
pthread_cond_signal(&ccond);
pthread_mutex_unlock(&mutex);
}
void Pop(T* data)
{
pthread_mutex_lock(&mutex);
if(is_Empty())
{
pthread_cond_wait(&ccond,&mutex);
}
//此时确定有一个资源
*data = q.front();
q.pop();
pthread_cond_signal(&pcond);
pthread_mutex_unlock(&mutex);
}
~BlockingQueue()
{
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&pcond);
pthread_cond_destroy(&ccond);
}
private:
bool is_Full()
{
return q.size() == _MaxCap;
}
bool is_Empty()
{
return q.empty();
}
queue q;
pthread_mutex_t mutex;
pthread_cond_t pcond;//生产者
pthread_cond_t ccond;//消费者
int _MaxCap;
}; 一个用于多线程情况下的模型,当然需要具备同步和互斥的功能,而且为了实现阻塞的功能,我们需要有条件变量的存在,并且由于该模型是由生产者线程和消费者线程互斥且同步的访问队列这个临界资源,且二者看待资源的角度是不一样的,所以需要两个条件变量。
生产者的角度
从生产者的角度来看,生产者所需要的资源是队列的剩余空间。
若是队列中的空间已满,那么生产者应该停下来阻塞式的等待消费者消费,直到队列中出现新的空位。
因而在Push函数中,我们需要先判断队列是否已满,再来决定是否放入数据。

假设我们判断队列已满,那么生产者就会在wait函数这里阻塞式的等待。
而若是队列未满,那么生产者就会向队列放入数据,并且唤醒等待的消费者线程——因为我们默认队列没数据——那么消费者线程一开始就会阻塞式等待唤醒,并且解锁。
消费者的角度
从消费者角度来说,消费者所需要的是队列中的资源。
若是队列中为空,那么消费者就应该阻塞式的等待生产者生产数据,直到队列中出现新的资源。
因而在Pop函数中,我们需要先判断队列是否为空,再来决定是否取出数据。

假设我们判断队列已空,那么消费者就会在wait函数这里阻塞式的等待。
而若是队列未空,那么消费者就会从队列取出数据,并且唤醒等待的生产者线程——因为有可能队列已满,生产者会等待消费者消费,直到被消费者唤醒。
为了方便理解,此处我们使用单消费者单生产者的情况来理解。
#include
#include
#include
#include
#include "BlockingQueue.hpp"
void *pstart_routine(void *args)
{
BlockingQueue *bq = static_cast *>(args);
while (true)
{
int data = rand() % 1000;
bq->Push(data);
cout<<"Pthread has push one data ! data : "< *bq = static_cast *>(args);
while (true)
{
int data ;
bq->Pop(&data);
cout<<"Cthread has pop one data ! data : "< *bq = new BlockingQueue;
pthread_t pt, ct;
pthread_create(&pt, NULL, pstart_routine, bq);
pthread_create(&ct, NULL, cstart_routine, bq);
pthread_join(pt, NULL);
pthread_join(ct, NULL);
return 0;
} 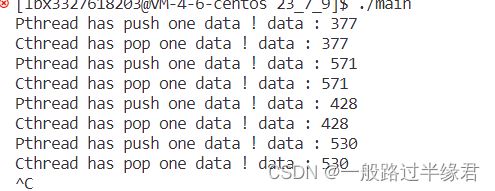
能看到我们确实是生产者刚生产,消费者才回去消费。
基于环形队列的生产消费模型
在阻塞队列的生产消费模型中,有一个漏洞。
当我们的生产者或者消费者访问阻塞队列时,它会将该队列给保护住,其他生产者或者消费者就无法访问了,然而访问的资源也许并不是全部,而是一部分资源,这样就会导致效率低下。
为了解决该问题,又出现了基于环形队列的生产消费模型。
基于环形队列的生产消费模型是利用信号量来实现的。
我们都知道信号量的原理就是一个计数器,每个执行流在访问临界资源之前都应该访问该计数器,失败就阻塞,直到成功。
信号量的PV操作
- P操作:使信号量-1,若信号量为负数,那么线程就会阻塞等待。
- V操作:使信号量+1,若信号量为负数,则说明有现成正在阻塞等待,V操作就会唤醒一个线程。
信号量的PV操作也是原子的,因而不用上锁。
回归正题,基于环形队列的生产消费模型是利用数组下标取模和数组模拟一个环形队列进行的,其阻塞的功能是由信号量的PV操作进行的。
接下来我们直接看看代码。
#include
#include
#include
#include
#include
using namespace std;
template
class RingQueue
{
private:
void P(sem_t &sem)
{
int n = sem_wait(&sem); // 表示该资源已经被占用了
assert(n == 0);
(void )n;
}
void V(sem_t &sem)
{
int n = sem_post(&sem); // 表示该资源已经用完了.
assert(n == 0);
(void )n;
}
public:
RingQueue(int cap = 10)
: _cap(cap), q(cap)
{
sem_init(&space, 0, _cap); // 默认刚开始没有资源
sem_init(&datas, 0, 0);
pstep = cstep = 0;
}
void Push(const T &data)
{
P(space);
q[pstep++] = data;
pstep %= _cap;
V(datas);
}
void Pop(T *data)
{
P(datas);
*data = q[cstep++];
cstep %= _cap;
V(space);
}
~RingQueue()
{
sem_destroy(&space);
sem_destroy(&datas);
}
private:
vector q;
sem_t space; // 有多少空间
sem_t datas; // 有多少任务
int pstep;
int cstep;
int _cap;
};
该模型的生产者所需要的资源是队列中的剩余空间。由于最开始没有资源,因此我们设置space信号量为队列大小。
而消费者所看重的资源是队列中的剩余资源,最开始没有资源,因此设置datas信号量为0;
此外,由于此处的环形队列是用数组模拟的,因此需要使用两个整数分别记录存放数据的位置和取出数据的位置。
基于环形队列的生产消费模型的注意事项
- 消费者不可超过生产者
消费者无法取出不存在的数据,而只在生产者前面存在数据,因此消费者不可超过生产者
- 生产者不可超过消费者一圈
当生产者超过消费者一圈时,若是还放入数据,就会覆盖未来得及被消费的数据。
- 生产者和消费者不可同时访问同一位置
当生产者和消费者同时访问一个位置,就相当于同时访问了一块临界资源,这是错误的。
生产者和消费者的互相制约
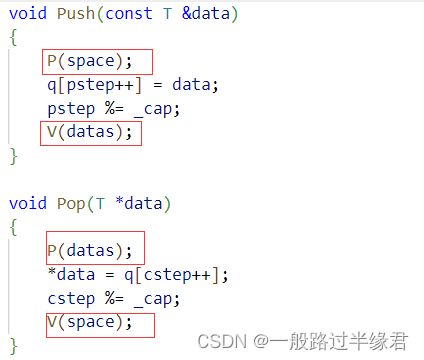
当我们看到Push函数和Pop函数时,我们发现Push一个数据前,需要对space进行P操作,而且Push一个数据后,还需要对datas进行V操作,相对的Pop也是进行着相反的操作。
实际上这是生产者和消费者相互唤醒,防止堵死。
接着我们看看实操,通过单生产者和单消费者来进行实验。
#include "RingQueue.hpp"
#include
#include
void *pstart_routine(void *args)
{
RingQueue *rq = static_cast*>(args);
while (true)
{
int data = rand() % 100;
rq->Push(data);
cout << "P thread has push a data ! data : " << data << endl;
sleep(1);
}
}
void *cstart_routine(void *args)
{
RingQueue *rq = static_cast*>(args);
while (true)
{
int data;
rq->Pop(&data);
cout << "c thread has pop a data ! data : " << data << endl;
sleep(1);
}
}
int main()
{
srand((unsigned int)time(NULL));
pthread_t p, c;
RingQueue *rq = new RingQueue();
pthread_create(&p, NULL, pstart_routine, rq);
pthread_create(&c, NULL, cstart_routine, rq);
pthread_join(p, NULL);
pthread_join(c, NULL);
return 0;
}

从代码中我们发现,肯定是先生产一个任务,再消费一个任务,这是因为模型内部信号量大小决定的。