UI自动化框架 基于selenium+pytest和PO分层思想
最近在编写UI自动化框架,现在将一些碎片化东西进行梳理,便于记忆
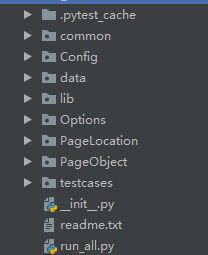
同时,为了方便于各个模块的独立管理,以及秉承高复用,低耦合的思想,这里是根据PO模型编写,同时将所有的模块进行了独立,页面和元素,以及用例和操作
框架用到的所有分层,梳理一下每个包的用途
-
.pytest_cache 这个是使用pytest框架系统默认导入的 -
commom公共管理方法
common_handle: 这里可以理解为base_page,这里对selenium里的方法进行了二次封装,同时对于一些操作,会在代码段里做注释,就不过多叙述
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 15:15
"""
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from JPT_UITEST.Config.path_name import PathName
from JPT_UITEST.common import time
from JPT_UITEST.common.log_handle import logger
class BasePage:
# 初始化,传入一个driver
def __init__(self, driver: WebDriver):
self.driver = driver
# 二次封装元素等待,如果错误,记录日志,并截图保存
def wait(self, loc, filename):
"""
元素等待
:param loc: 等待的元素
:param filename: 截图名字
:return:
这里使用的是隐式等待,同时将隐式等待和元素是否可见的判断进行了结合,这样更加稳定!
"""
logger.info('{}正待等待元素{}'.format(filename, loc))
try:
WebDriverWait(self.driver, timeout=30).until(EC.visibility_of_element_located(loc))
#首先是隐式等待表达式(driver对象,等待时长)
#同时每0.5秒会查看一次,查看元素是否出现,如果超过30s未出现,则报错timeout
#until()是等待元素可见,这里加入了元素是否可见的判断
except Exception as e:
self.error_screenshots(filename)
logger.exception('元素等待错误发生:{}元素为{}'.format(e, loc))
raise
def error_screenshots(self, name):
"""
保存截图
:param name:根据被调用传入的名字,生成png的图片
:return:
"""
try:
file_path = PathName.screenshots_path
times = time.time_sj()
filename = file_path + times + '{}.png'.format(name)
self.driver.get_screenshot_as_file(filename)
logger.info("正在保存图片:{}".format(filename))
except Exception as e:
logger.error('图片报存错误:{}'.format(e))
raise
def get_ele(self, loc, filename):
"""
查找元素
:param loc:
:param filename:
:return:
"""
logger.info('{}正在查找元素:{}'.format(filename, loc))
try:
# 这里使用的是find_element查找单个元素,这里需要传入的是一个表达式,需要告诉driver对象使用的是什么定位方法,以及元素定位!
# By是继承了selenium里面的8大定位方法,所以框架里操作元素的皆是By.XPATH或者By.id等等
# 同时因为需要传入的是一个表达式,而By.XPATH是一个元组,这里做了解包处理
ele = self.driver.find_element(*loc)
except Exception as e:
logger.exception('查找元素失败:')
self.error_screenshots(filename)
raise
else:
return ele
def send_key(self, loc, name, filename):
"""
输入文本
:param loc:元素
:param filename:截图名字
:param name: 输入的名字
:return:
"""
logger.info('{}正在操作元素{},输入文本{}'.format(filename, loc, name))
self.wait(loc, filename)
try:
self.get_ele(loc, filename).send_keys(name)
except:
logger.exception('元素错误 {}:')
self.error_screenshots(filename)
raise
def click_key(self, loc, filename):
"""
元素点击
:param loc:
:param filename:
:return:
"""
logger.info('{}正在操作元素{}'.format(filename, loc))
self.wait(loc, filename)
try:
self.get_ele(loc, filename).click()
except Exception as e:
logger.exception('点击元素错误:{}'.format(e))
self.error_screenshots(filename)
raise
def get_ele_text(self, loc, filename):
"""
获取元素文本
:param loc:
:param filename:
:return:
"""""
logger.info('{}正在获取文本{}'.format(filename, loc))
self.wait(loc, filename)
ele = self.get_ele(loc, filename)
try:
text = ele.text
logger.info('获取文本成功{}'.format(text))
return text
except:
logger.exception('获取文本错误:')
self.error_screenshots(filename)
def get_ele_attribute(self, loc, attribute_name, filename):
"""
获取元素属性
:param loc:
:param attribute_name:
:param filename:
:return:
"""
logger.info('{}正在获取元素{}的属性'.format(filename, loc))
self.wait(loc, filename)
ele = self.get_ele(loc, filename)
try:
value = ele.get_attribute(attribute_name)
logger.info('获取属性成功{}'.format(value))
return value
except:
logger.exception('获取属性失败')
self.error_screenshots(filename)
def wait_ele_click(self, loc, filename):
logger.info('{}正待等待可点击元素{}'.format(filename, loc))
try:
WebDriverWait(self.driver, timeout=20).until(EC.element_to_be_clickable(loc))
# logger.info('等待可点击元素{}'.format(loc))
except:
self.error_screenshots(filename)
logger.exception('等待可点击元素错误:元素为{}'.format(loc))
raise
def switch_to_iframe(self, loc, filename):
try:
WebDriverWait(self.driver, 20).until(EC.frame_to_be_available_and_switch_to_it(loc))
logger.info('正在进入嵌套页面:{}'.format(loc))
except:
logger.exception('进入嵌套页面失败{}'.format(loc))
self.error_screenshots(filename)
def click_wait_ele(self, loc, filename):
logger.info('正在等待{}中的可点击元素出现{}'.format(filename, loc))
self.wait_ele_click(loc, filename)
try:
self.get_ele(loc, filename).click()
logger.info('正在{}中点击元素{}'.format(filename, loc))
except:
logger.info('在{}当中点击{}元素失败'.format(filename, loc))
self.error_screenshots(filename)
这里应该有部分同学会对初始化时的位置参数比较疑惑,为什么是 driver: WebDriver这种写法!
这里的写法,是因为我们在封装时,不能在这里去实例driver会话对象!不然所有页面使用的就全部是一个会话对象了
但是如果不实例呢,pycharm就不知道driver是什么,就无法使用后续的一些操作,比如driver.find_element.by.id()这种方法!
所以我们就在初始化时,声明告诉了编译器,driver是一个webdriver对象
同时,这里二次封装的主要思想为:要做什么->日志打印->等待元素->判断->截图这样可以清晰的知道,那个地方出了问题,有日志,有截图
2.common_mysql:
这里是预留封装mysql的文件,因为暂时用不到,就没使用
3.log_handle:
这里封装的是log日志模块
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/11/23 17:19
"""
import logging
import os
from JPT_UITEST.Config.common_data import Context
from JPT_UITEST.Config.path_name import PathName
log_path_name = os.path.join(PathName.logs_path, Context.log_name)
# print(log_path_name)
class LogHandel(logging.Logger):
"""定义日志类"""
def __init__(self, name, file, level='DEBUG',
fmt="%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"):
super().__init__(name)
self.setLevel(level)
file_headers = logging.FileHandler(file)
file_headers.setLevel(level)
self.addHandler(file_headers)
fmt = logging.Formatter(fmt)
file_headers.setFormatter(fmt)
logger = LogHandel(Context.log_name, log_path_name, level=Context.level)
if __name__ == '__main__':
log = logger
log.warning('测试1')
这里是通用模板,不多说
4. time.py
这里是生成时间
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/15 14:56
"""
import datetime
def time_sj():
sj = datetime.datetime.now().strftime('%m-%d-%H-%M-%S')
return sj
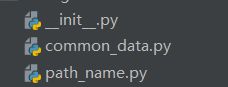
Config 这里我存放的是路径,以及公共操作里会用到的数据
common_data.py
这里就放了一些关于日志的等级和level
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/15 13:47
"""
class Context:
log_name = 'Ui自动化.txt'
level = 'DEBUG'
path_name.py
这里是存放了所有会用到的存放路径,以及读取数据路径
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/15 13:47
"""
import os
class PathName:
# 初始路径F:\jintie\JPT_UITEST
dir_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# F:\jintie\JPT_UITEST\Options\
options_path = os.path.join(dir_path, 'Options')
# Logs文件目录地址
logs_path = os.path.join(options_path, 'Logs/')
# report测试报告路径
report_path = os.path.join(options_path, 'report/')
screenshots_path = os.path.join(options_path, 'error_screenshots/')
case_name = os.path.join(dir_path, 'testcases/')
data文件包中存放的是项目相关的全局数据,和测试数据
Global_Data:存放了所有全局数据
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 15:21
"""
class GlobalData:
# 域名
host = ''
# url
BackGround = host + '/login'
Test_data:
test_data.py: 存放的测试数据
数据分离的好处在于,如果数据发生改变,我只需要在这个文件中将数据做修改即可,不需要去做其他的代码改动
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 15:56
"""
class TestData:
# 正确账号密码
just_data = {
'username': '',
'pwd': ''
}
# 错误测试数据
test_data = [{'username': '', 'pwd': ''},
{'username': '', 'pwd': ''},
{'username': '', 'pwd': ''}]
lib的包中原本存放的是一些修改过源码的三方库,比如HTMLTestRunner.py和ddt.py
但是后续将unittest改为了pytest所以这里的数据驱动模块,和测试报告模块变弃用了,不多做叙述
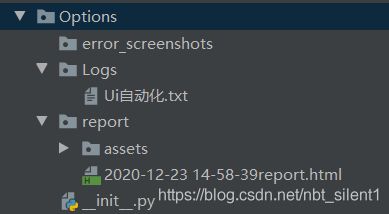
Options:这里存放的为输出的日志,报告,以及错误截图

因为使用了PO模型, PO模型是指在UI自动化中,将页面、操作、元素、和测试用例全部独立,减少耦合性,所以这里我存放的为xpath元素方法
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 15:13
"""
“”“涉及了实际项目,所以部分数据做脱敏处理”“”
from selenium.webdriver.common.by import By
class BackGroundLoc:
# 登陆窗口
input_user = (By.XPATH, '//input[@id="name"]')
# 输入密码
input_pwd = (By.XPATH, '//input[@id="password"]')
# 选择平台下拉框
select_platform_input = (By.XPATH, '//div[@unselectable="on"]')
# 选择子平台
select_platform = (By.XPATH, '//span[text()=""]')
# 记住用户名
Re_user_name = (By.XPATH, '//span[@class="ant-checkbox ant-checkbox-checked"]')
# 用户登录
user_login = (By.XPATH, '//button[@class="ant-btn login-form-button ant-btn-primary ant-btn-lg"]')
title_name = 'XX管理系统'
# error_msg
error_msg = (By.XPATH, '//div[@class="ant-form-explain"]')
这里是首页页面所有的元素定位!这样做的好处为,后续如果元素发生了改变,只需要去修改元素即可,不需要对其他地方做出修改!同时,改了这里,所有用到此元素的地方,都会发生改变
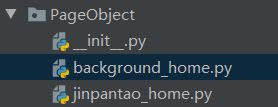
PageObject: 这里是所有关于页面操作的封装
background_home.py是关于后台首页的操作
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 14:49
"""
import time
from JPT_UITEST.PageLocation.background_home_loc import BackGroundLoc as BLC
from JPT_UITEST.common.common_handle import BasePage
class PlatformLogin(BasePage):
# 输入账号密码
def platform_login_succeed(self, username, pwd):
self.send_key(BLC.input_user, username, '登陆页_输入用户名')
self.send_key(BLC.input_pwd, pwd, '登陆页_输入密码')
time.sleep(2)
# 选择平台
def select_platform(self):
self.click_key(BLC.select_platform_input, '登陆页_选择下拉框')
self.click_key(BLC.select_platform, '登陆页_选择平台')
# 登陆
def login(self):
self.click_key(BLC.user_login, '登陆页_点击登陆')
# 记录用户名
def Res_users_name(self):
self.click_key(BLC.Re_user_name, '登陆页_记录用户名')
# 登陆后的首页
def login_home(self):
self.driver.title(BLC.title_name)
# if __name__ == '__main__':
#
# driver = webdriver.Chrome()
# driver.get()
testcases: 这里存放的是所有测试用例
conftest.py:这里是pytest的前后置条件,固定名字!不需要导入到用例中,pytest会自动遍历
这里因为我暂时只用到了一个function用例级别的前后置条件,所以只封装了一个
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/23 14:26
"""
from JPT_UITEST.data.Global_Data.global_data import GlobalData as GD
from JPT_UITEST.common.log_handle import logger
import pytest
from selenium import webdriver
# @pytest.fixture装饰器,是表示接下来的函数为测试用例的前后置条件
#fixture一共4个级别,默认scope=function(用例,对标为unittest中的setup以及tearDown)
#同时,fixture中包含了前置条件,以及后置条件
#function是每个用例开始和结束执行
#class是类等级,每个测试类执行一次
#modules 是模块级别,也就是当前.py文件执行一次
#session 是会话级别, 指测试会话中所有用例只执行一次
#pytest中区分前置后置是用关键字yield来区分的, yield之前,是前置!yield之后,是后置 yield同行,是返回数据
@pytest.fixture()
def open_browser():
logger.info('-----------正在执行测试用例开始的准备工作,打开浏览器,请求后台-----------')
driver = webdriver.Chrome()
driver.get(GD.BackGround)
driver.maximize_window()
yield driver
driver.quit()
test_login.py 测试用例
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/14 14:44
"""
import time
import pytest
from JPT_UITEST.PageObject.background_home import PlatformLogin
from JPT_UITEST.PageObject.jinpantao_home import JinpantaoHome
from JPT_UITEST.common.log_handle import logger
from JPT_UITEST.data.Test_Data.test_data import TestData as TD
data = TD.test_data
#pytest.mark.usefixtures()是使用前置条件,括号中填写要使用的前置条件函数名称
#因为封装前置条件的py文件名称固定,所以这里不需要导入,是由pytest自动遍历查找
#放在类方法上,是表示测试类下所有测试方法,都会使用这个前置条件
@pytest.mark.usefixtures('open_browser')
class TestLogin:
# @pytest.mark.parametrize('su_data', TD.just_data)
def test_login_01_succeed(self, open_browser, ):
"""
#正向场景
3.输入账号密码,点击登陆
4.选择对应子平台
6.判断首页元素是否可见
:return:
"""
logger.info('+++++正在执行正向登陆测试用例+++++')
try:
pf = PlatformLogin(open_browser)
pf.platform_login_succeed(TD.just_data['username'], TD.just_data['pwd'])
pf.select_platform()
pf.login()
JT = JinpantaoHome(open_browser)
JT.context_operation()
JT.tag_mg()
JT.money_mg()
JT.article_list()
JT.article_stat()
JT.article_decry()
logger.info('正在执行测试用例:账号{},密码{}'.format(TD.just_data['username'], TD.just_data['pwd']))
except Exception as e:
logger.error('用例执行错误:{}'.format(e))
raise AssertionError
“”“@pytest.mark.parametrize()装饰器是用来执行数据驱动的,需要传入两个值
1.数据名称,不固定,自由填写
2.数据
但是数据名称要在使用数据驱动的方法里当作参数传入,对标ddt当中的传值接收
”“”
@pytest.mark.parametrize('test_data', TD.test_data)
def test_login_02_fail(self, open_browser, test_data):
"""
3.输入账号密码
4.选择对应平台
5.点击登陆
6.查看失败提示
:return:
"""
logger.info('+++++正在执行逆向向登陆测试用例+++++')
try:
pf = PlatformLogin(open_browser)
pf.platform_login_succeed(test_data['username'], test_data['pwd'])
# time.sleep(1)
# pf.Res_users_name()
time.sleep(1)
pf.select_platform()
pf.login()
logger.info('正在执行逆向场景用例用户名{},密码{}'.format(test_data['username'], test_data['pwd']))
except Exception as e:
logger.error('逆向场景用件执行失败{}'.format(e))
同时pytest当中,更加灵活的是断言,如果在unittest中,需要使用self.assert.断言方式(实际结果,预期结果)
但是pytest当中,只需要使用assert 表达式 例如:assert 1+1=2 这种方式即可,如果结果为true,则代表断言成功!
最后一个文件是出于习惯使用了一个加载所有用例的.run_all.py
# encoding: utf-8
"""
@author:辉辉
@email: [email protected]
@Wechat: 不要静音
@time: 2020/12/17 20:13
"""
import datetime
import os
import pytest
from JPT_UITEST.Config.path_name import PathName
from JPT_UITEST.common.log_handle import logger
def run_all():
times = datetime.datetime.now().strftime('%Y-%m-%d %H-%M-%S')
report_name = os.path.join(PathName.report_path, (times + 'report.html'))
logger.info('生成测试用例,存放为{}'.format(report_name))
pytest.main(['-s', '-v', '--html={}'.format(report_name)])
if __name__ == '__main__':
run_all()
pytest执行用例有几种方法,我这里使用的是pytest.main()这个方法,实际上就是和在cmd命令符里使用
pytest -s -v的效果一样! '–html=xxx.html’是生成html测试用例!
到这里,就是一个完整的框架,剩下的就是根据项目的不同,去做一些定制化的操作!