ANSI、Unicode、Unicode big endian、UTF-8编码
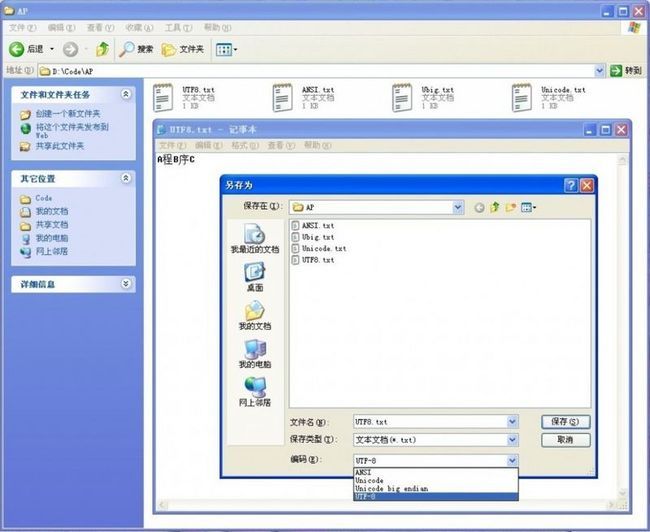
保存文本文件的时候,可以选择的编码有ANSI、Unicode、Unicode big endian、UTF-8四种。
不同的编码,保存在文件中的0、1代码是不同的,我们新建一文本文件,输入“A程B序C”,分别以上面四种编码形式保存为4个文件ANSI.txt、Unicode.txt、Ubig.txt和UTF8.txt,并使用cmd中的debug程序查看文件内容如下:
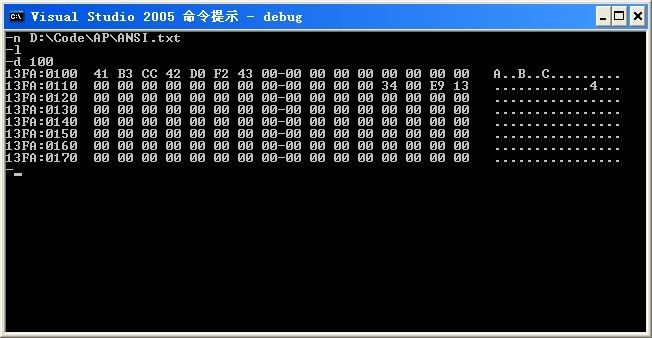
1、ANSI.txt
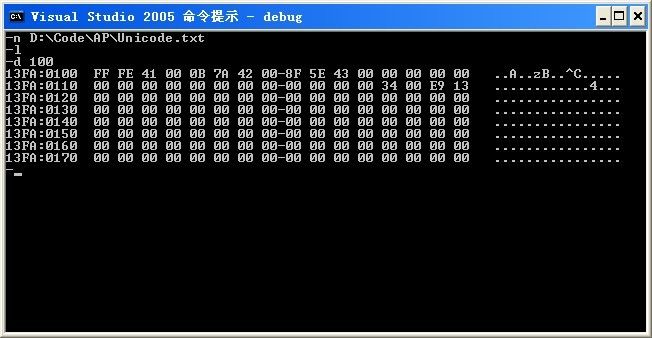
2、Unicode.txt
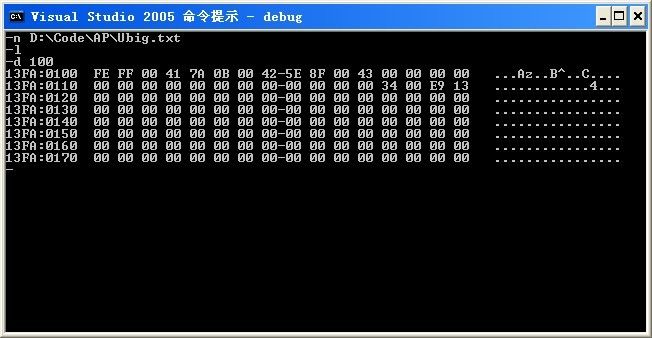
3、Ubig.txt
4、UTF8.txt
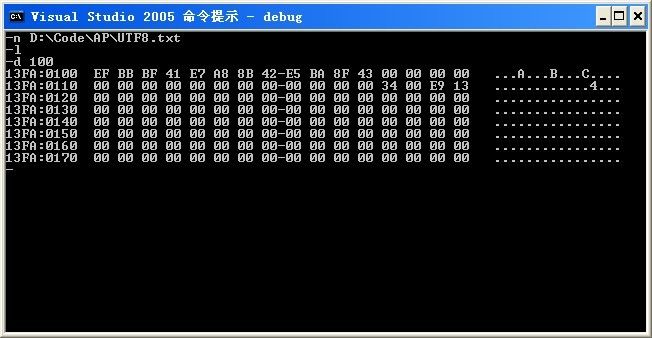
我们发现,“A程B序C”保存在文件中的0、1代码分别为:
- ANSI编码:
41 B3 CC 42 D0 F2 43
- Unicode编码:
FF FE 41 00 0B 7A 42 00 8F 5E 43 00
“FF FE”文件编码标识
- Unicode big endian编码:
FE FF 00 41 7A 0B 00 42 5E 8F 00 43
“FE FF”文件编码标识
- UFT-8编码:
EF BB BF 41 E7 A8 8B 42 E5 BA 8F 43
“EF BB BF”文件编码标识
一、ANSI编码:
ANSI是默认的编码方式。对于英文字符是ASCII编码,对于简体中文字符是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
二、Uincode编码:
Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
三、Unicode big endian编码:
“endian”一词来源于英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是”大头方式“(Big endian),第二个字节在前就是”小头方式“(Little endian)。小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为Big-endians和Little-endians。
对比Unicode编码,可发现,Unicode big endian编码只是字符的两个字节的存放顺序不同而已。
四、UFT-8编码:
UTF-8是UNICODE的一种变长字符编码又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如日文,韩文)。
【结束语】
这几种编码当然都有它的编码规则,不过,对于我们使用者来说,只需要知道不同的编码,保存在文件中的0、1代码是不同的,使用不同的编码规则浏览文件,很显然会出现乱码。
这就需要我们在编写文件的时候,养成一个良好的习惯,特别声明一下我们使用的编码,例如,在网页文件中使用META内容元素声明我们的编码:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
参考网址:
http://baike.baidu.com/view/40801.htm
http://baike.baidu.com/view/1485693.htm
http://baike.baidu.com/view/742823.htm
http://blog.sina.com.cn/s/blog_6d71f75301016xm0.html