HTTP 缓存机制 强制缓存/协商缓存

为什么被缓存,如何命中缓存以及缓存什么时候生效的,我们却很少在实际开发中去了解。借助动画形式来从根上理解 HTTP 缓存机制及原理。
HTTP 缓存,对于前端的性能优化方面来讲,是非常关键的,从缓存中读取数据和直接向服务器请求数据,完全就是一个在天上,一个在地下。
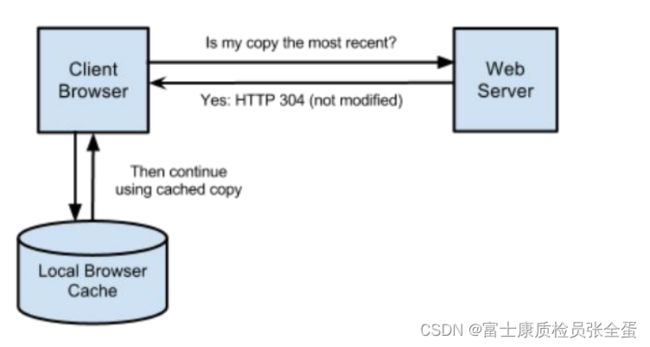
我们最熟悉的是 HTTP 服务器响应返回状态码 304,304 代表表示告诉浏览器,本地有缓存数据,可直接从本地获取,无需从服务器获取浪费时间。
如果缓存过期,则继续从服务器验证
为什么会有缓存?
单纯的从计算机角度去说,比较抽象,咱们看一个实际的例子。比如,我们通常喜欢把没看完的书放在书架上,而看完以及没有看的书放在箱子中保存。
如果我们把所有的书保存在箱子中,每次看书都要去箱子中找,所以非常麻烦和耗时(这里的箱子,可以想象成服务器)。
当我们开始看新书时,第一次从箱子中取出,看了一半,然后我们直接放到书架上,当下次再看书的时候,直接从书架中取出,这里的书架,就是我们下边要讲到的缓存(一个缓存仓库)。
Web 缓存大致可以分为:数据库缓存、服务器端缓存(代理服务器缓存、CDN 缓存)、浏览器缓存。
浏览器缓存也包含很多内容: HTTP 缓存、indexDB、cookie、localstorage 等等。这里我们只讨论 HTTP 缓存相关内容。
在具体了解 HTTP 缓存之前先来明确几个术语:
- 缓存命中率:从缓存中得到数据的请求数与所有请求数的比率,理想状态是越高越好。
- 过期内容:超过设置的有效时间,被标记为“陈旧”的内容。通常过期内容不能用于回复客户端的请求,必须重新向源服务器请求新的内容或者验证缓存的内容是否仍然准备。
- 验证:验证缓存中的过期内容是否仍然有效,验证通过的话刷新过期时间。
- 失效:失效就是把内容从缓存中移除。当内容发生改变时就必须移除失效的内容。
浏览器缓存主要是 HTTP 协议定义的缓存机制。HTML meta 标签,例如:
Cache-Control:no-store
含义是让浏览器不缓存当前页面,但是代理服务器不解析 HTML 内容,一般应用广泛的是用 HTTP 头信息控制缓存。
HTTP 头信息控制缓存
大致分为两种:强缓存和协商缓存,强缓存如果命中缓存不需要和服务器端发生交互,而协商缓存不管是否命中都要和服务器端发生交互,强制缓存的优先级高于协商缓存。具体内容下文介绍。
Cache-Control:通过指定首部字段 Cache-Control 的指令,就能操作缓存的工作机制。
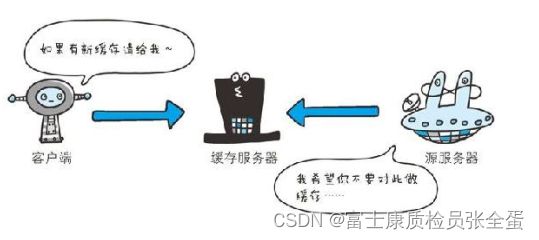
图:首部字段 Cache-Control 能够控制缓存的行为,指令的参数是可选的,多个指令之间通过“,”分隔。
首部字段Cache-Control 的指令可用于请求及响应时。Cache-Control: private, max-age=0, no-cache
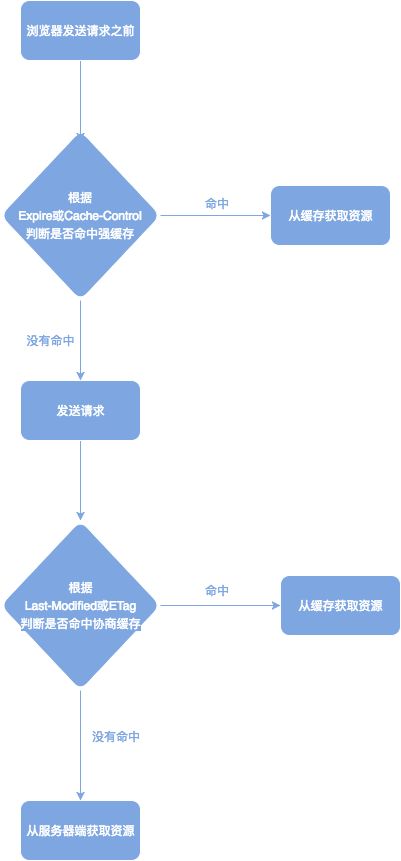
匹配流程(已有缓存的情况下):
缓存的“龟”则
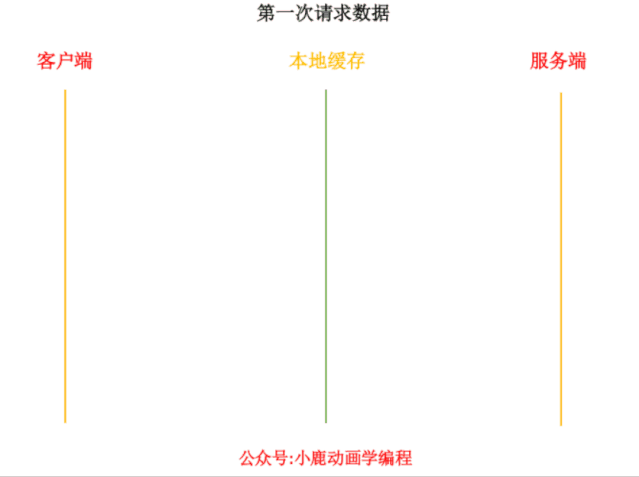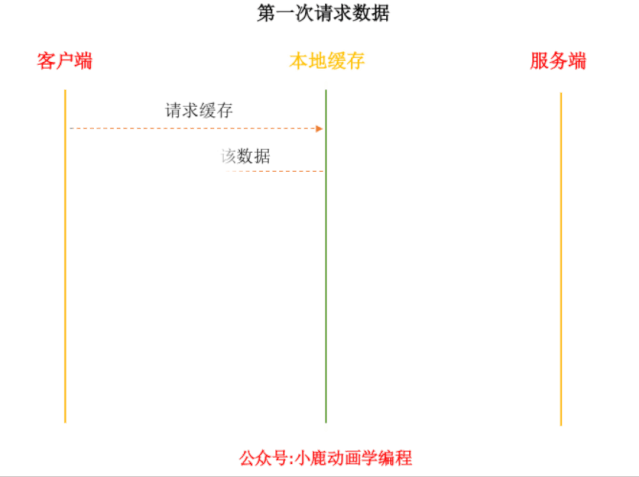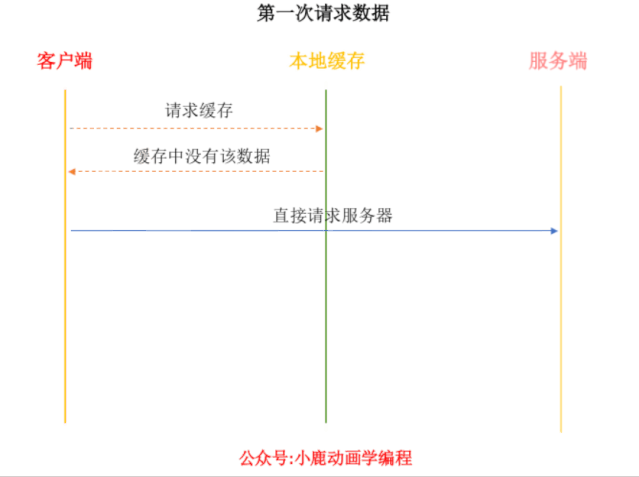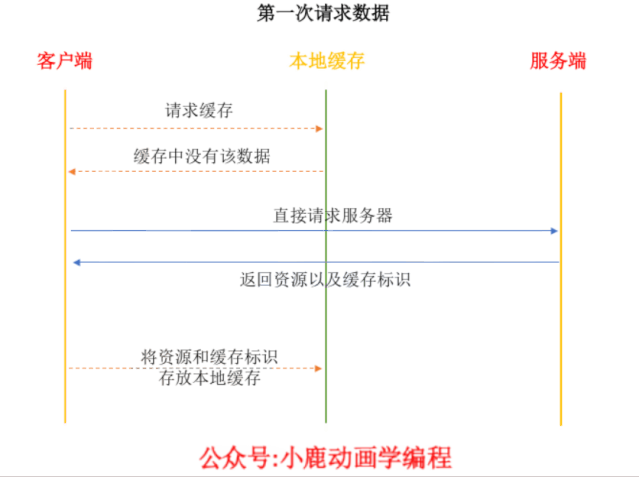
当浏览器发出请求到数据请求回来的过程,就像是上述中的取书过程。
- 浏览器在加载资源时,根据请求头的Expires 和 Cache-control 判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。
- 如果没有命中强缓存,浏览器一定会发送一个请求到服务器,通过 Last-Modified 和 Etag 验证资源是否命中协商缓存,如果命中,服务器会将这个请求返回,但是不会返回这个资源的数据,依然是从缓存中读取资源。
- 如果前面两者都没有命中,直接从服务器加载资源。
动画演示:
强缓存
可以理解为无须验证的缓存策略。对强缓存来说,响应头中有两个字段 Expires/Cache-Control 来表明规则。
Expires
Expires 指缓存过期的时间,超过了这个时间点就代表资源过期。有一个问题是由于使用具体时间,如果时间表示出错或者没有转换到正确的时区都可能造成缓存生命周期出错,并且 Expires 是 HTTP/1.0 的标准,现在更倾向于用 HTTP/1.1 中定义的 Cache-Control,两个同时存在时也是 Cache-Control 的优先级更高。
Cache-Control
Cache-Control 可以由多个字段组合而成,主要有以下几个取值:
1. max-age:指定一个时间长度,在这个时间段内缓存是有效的,单位是s。例如设置 Cache-Control:max-age=31536000,也就是说缓存有效期为(31536000 / 24 / 60 * 60)天,第一次访问这个资源的时候,服务器端也返回了 Expires 字段,并且过期时间是一年后。
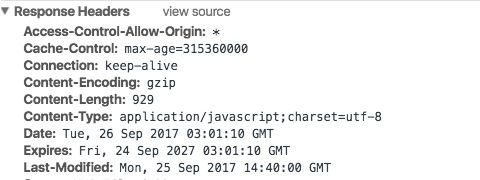
在没有禁用缓存并且没有超过有效时间的情况下,再次访问这个资源就命中了缓存,不会向服务器请求资源而是直接从浏览器缓存中取。
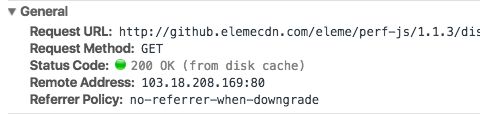
2. s-maxage:同 max-age,覆盖 max-age、Expires,但仅适用于共享缓存,在私有缓存中被忽略。
3. public:表明响应可以被任何对象(发送请求的客户端、代理服务器等等)缓存。
4. private:表明响应只能被单个用户(可能是操作系统用户、浏览器用户)缓存,是非共享的,不能被代理服务器缓存。
5. no-cache:强制所有缓存了该响应的用户,在使用已缓存的数据前,发送带验证器的请求到服务器。不是字面意思上的不缓存。
6. no-store:禁止缓存,每次请求都要向服务器重新获取数据。