spark笔记
spark笔记
- 1.Spark核心编程
-
- 1.1RDD
-
- 1.1.1RDD原理
- 1.1.2 RDD转换算子
- 1.1.3 RDD行动算子
- 1.1.4 RDD依赖关系
- 1.1.5 RDD 序列化,持久化
- 1.2累加器
- 1.3广播变量
- 2.Spark_SQL
-
- 2.1 SparkSQL的特点
- 2.2 RDD 、DataFrame 、DataSet 三者的关系
- 3.Spark_Streaming
-
- 3.1 Spark_Streaming 特点
- 3.2 DStream
-
- SparkStreaming小案例
1.Spark核心编程
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,RDD : 弹性分布式数据集。累加器:分布式共享只写变量。广播变量: 分布式共享只读变量
1.1RDD
RDD弹性分布式数据集,是Spark中最基本的数据处理模型。具有以下特点:
内存与磁盘的自动切换,数据丢失可以自动恢复,计算出错重试机制,可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD封装了计算逻辑,并不保存数据
数据抽象:RDD是一个抽象类,需要子类具体实现
不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的RDD里面封装计算逻辑
可分区、并行计算
1.1.1RDD原理
Spark框架在执行时需要将计算资源和计算模型进行协调和整合。先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务,将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
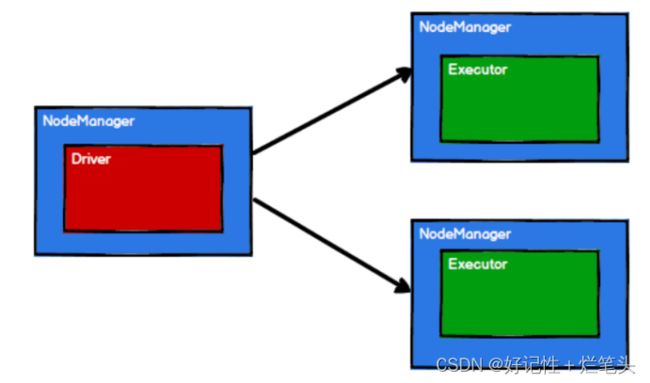
图1.1 Spark通过申请资源创建调度节点和计算节点。
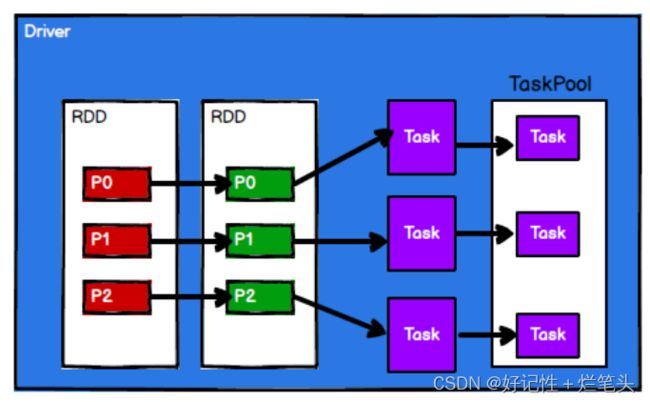
图1.2 Spark框架根据需求将计算逻辑根据分区划分成不同的任务
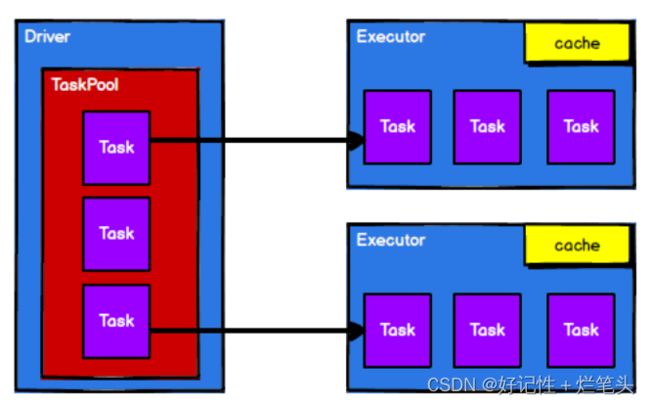
图1.3调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给 Executor节点执行计算。
1.1.2 RDD转换算子
RDD根据数据处理方式的不同将算子整体上分为 :
1)Value 类型:map(数据逐条进行映射转换)
mapPartitions(将待处理的数据以分区为单位发送到计算节点进行处理)mapPartitionsWithIndex(将待处理的数据以分区为单位发送到计算节点进行处理)
flatMap(将处理的数据进行扁平化后再进行映射处理)
glom(将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变)
groupBy(shuffle操作,将数据根据指定的规则进行分组)
Filter(根据指定的规则进行筛选过滤)
Sample(根据指定的规则从数据集中抽取数据)
distinct(将数据集中重复的数据去重 )
coalesce(根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率)
sortBy(排序操作)
2)双Value类型:
intersection(对源RDD和参数 RDD求交集后返回一个新的RDD)
union(对源RDD和参数 RDD求并集后返回一个新的RDD)
subtract(以一个RDD元素为主,去除两个RDD 中重复元素,求差集)
zip(将两个RDD 中的元素,以键值对的形式进行合并。)
3)Key-Value 类型:
partitionBy(将数据按照指定 Partitioner 重新进行分区)
reduceByKey(将数据按照相同的 Key对Value进行聚合)
groupByKey(将数据源的数据根据 key对Value进行分组)
aggregateByKey(将数据根据不同的规则进行分区内计算和分区间计算)
foldByKey(分区内计算规则和分区间计算规则相同时的aggregateByKey)
combineByKey(类似aggregate(),combineByKey()允许用户返回值的类型与输入不一致),
(reduceByKey: 相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同;
FoldByKey: 相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相
同;
AggregateByKey:相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规 则可以不相同 ;
CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区
内和分区间计算规则不相同。)
sortByKey(在一个(K,V)的RDD上调用,根据V进行排序)
join(在类型为(K,V)和(K,W)的RDD上调用,返回一个相同 key类型为(K,(V,W))的 RDD)
leftOuterJoin(类似于SQL语句的左外连接)
cogroup(在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的 RDD ),
1.1.3 RDD行动算子
reduce(聚集 RDD中的所有元素,先聚合分区内数据,再聚合分区间数据)
collect(在驱动程序中,以数组 Array 的形式返回数据集的所有元素)
count(返回 RDD中元素的个数)
first(返回 RDD中的第一个元素)
take(返回一个由 RDD的前 n 个元素组成的数组)
takeOrdered(返回该 RDD排序后的前 n 个元素组成的数组)
aggregate(分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合)
fold(折叠操作,aggregate 的简化版操作)
countByKey(统计每种 key 的个数)
foreach(调用指定函数,分布式遍历 RDD中的每一个元素)
1.1.4 RDD依赖关系
窄依赖: 每一个上游RDD的Partition 最多被下游 RDD的一个Partition使用,比喻为独生子女。
宽依赖:同一个上游RDD的Partition 被多个下游 RDD的Partition 依赖,会引起Shuffle,比喻为多生。
RDD血缘关系:RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage (血统) 记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
1.1.5 RDD 序列化,持久化
RDD序列化是将RDD中的数据序列化为二进制格式,以便在网络传输或持久化到磁盘时进行传输或存储。
RDD持久化是将计算结果存储在内存或磁盘中,以便后续的操作可以更快地访问这些数据。这样可以:1. 提高计算速度:RDD持久化可以避免重复计算,当RDD被持久化到内存或磁盘时,后续操作可以直接从缓存中读取数据,而不需要重新计算。2. 减少数据倾斜:当RDD分区不均衡时,一些分区的计算负载可能会很重,而另一些分区的计算负载却很轻。如果这些计算结果被持久化到内存或磁盘中,可以将计算结果转移到负载较轻的节点上,从而减少数据倾斜。
1.2累加器
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
1.3广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark 操作使用。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
2.Spark_SQL
2.1 SparkSQL的特点
Shark早期的结构化数据处理是基于Hive的,Shark对于Hive太过依赖,导致Shark的发展速度会受到Hive的影响。所以提出了SparkSQL项目,使得Shark的发展不再受限于Hive。并且SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快。SparkSQL有一下优势:
易整合:无缝的整合了SQL查询和Spark编程
统一的数据访问:使用相同的方式连接不同的数据源
兼容 Hive:在已有的仓库上直接运行SQL或者HiveQL
标准数据连接:通过JDBC或者ODBC来连接
2.2 RDD 、DataFrame 、DataSet 三者的关系
在SparkSQL中Spark 提供了两个新的抽象, 分别是DataFrame和DataSet。同样的数据都给到这三个数据结构,分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。
RDD :RDD一般和spark mllib 同时使用,不支持 sparksql 操作。
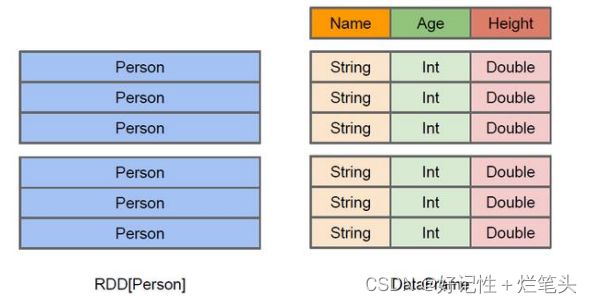
图2.1 RDD和DataFrame的区别
DataFrame :DataFrame 是一种以 RDD为基础的分布式数据集,类似于传统数据库中的二维表格,DataFrame 所表示的二维表数据集的每一列都带有名称和类型。与 RDD和 Dataset不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值,支持 SparkSQL 的操作,如 select ,groupby 之类,还能 注册临时表/视窗,进行 sql 语句操作,支持一些特别方便的保存方式。
DataSet:是DataFrame的一个扩展。添加了了 RDD的优势(强类型,使用强大的 lambda 函数的能力)以及Spark SQL优化执行引擎的优点。DataSet也可以使用功能性的转换(操作 map,flatMap,filter 等等)。与DataFrame类似,DataSet也是由行和列组成的数据表,每列都有自己的数据类型,但是DataSet是强类型的,可以使用面向对象的编程方式进行操作。

图2.2 RDD 、DataFrame 、DataSet 三者相互转换
3.Spark_Streaming
3.1 Spark_Streaming 特点
Spark Streaming用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

图3.1 Spark Streaming流式数据处理
3.2 DStream
和Spark基于RDD的概念很相似,Spark Streaming 使用离散化流作为抽象表示,叫作DStream。DStream是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。所以简单来将,DStream就是对 RDD 在实时数据处理场景的一种封装。
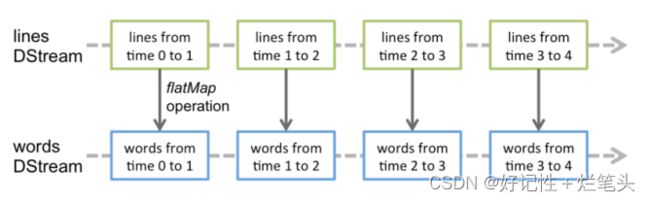
图3.2 Spark Streaming内部实现
在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据,对数据的操作也是按照 RDD 为单位来进行的。

图3.3 Spark Streaming计算过程
计算过程由 Spark Engine 来完成。
SparkStreaming小案例
实现实时的动态黑名单机制,将每天对某个广告点击超过 30 次的用户拉黑。
1.数据生成
模拟生成实时数据,并将数据通过Kafka生产者发送到Kafka集群中。
1.import java.util.{Properties, Random}
2.import com.atguigu.bean.CityInfo
3.import com.atguigu.utils.{PropertiesUtil, RanOpt, RandomOptions}
4.import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
5.import scala.collection.mutable.ArrayBuffer
6.
7.object MockerRealTime {
8. /**
9. * 模拟的数据
10. *
11. * 格式 :timestamp area city userid adid
12. * 某个时间点 某个地区 某个城市 某个用户 某个广告
13. */
14. def generateMockData(): Array[String] = {
15. val array: ArrayBuffer[String] = ArrayBuffer[String]()
16. val CityRandomOpt = RandomOptions(
17. RanOpt(CityInfo(1, "北京", "华北"), 30),
18. RanOpt(CityInfo(2, "上海", "华东"), 30),
19. RanOpt(CityInfo(3, "广州", "华南"), 10),
20. RanOpt(CityInfo(4, "深圳", "华南"), 20),
21. RanOpt(CityInfo(5, "天津", "华北"), 10)
22. )
23. val random = new Random()
24. // 模拟实时数据:
25. // timestamp province city userid adid
26. for (i <- 0 to 50) {
27. val timestamp: Long = System.currentTimeMillis()
28. val cityInfo: CityInfo = CityRandomOpt.getRandomOpt
29. val city: String = cityInfo.city_name
30. val area: String = cityInfo.area
31. val adid: Int = 1 + random.nextInt(6)
32. val userid: Int = 1 + random.nextInt(6)
33. // 拼接实时数据
34. array += timestamp + " " + area + " " + city + " " + userid + " " + adid
35. }
36. array.toArray
37. }
38.
39. def createKafkaProducer(broker: String): KafkaProducer[String, String] = {
40. // 创建配置对象
41. val prop = new Properties()
42. // 添加配置
43. prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, broker)
44. prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
45. prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
46. // 根据配置创建 Kafka 生产者
47. new KafkaProducer[String, String](prop)
48. }
49.
50. def main(args: Array[String]): Unit = {
51. // 获取配置文件 config.properties 中的 Kafka 配置参数
52. val config: Properties = PropertiesUtil.load("config.properties")
53. val broker: String = config.getProperty("kafka.broker.list")
54. val topic = "test"
55. // 创建 Kafka 消费者
56. val kafkaProducer: KafkaProducer[String, String] = createKafkaProducer(broker)
57. while (true) {
58. // 随机产生实时数据并通过 Kafka 生产者发送到 Kafka 集群中
59. for (line <- generateMockData()) {
60. kafkaProducer.send(new ProducerRecord[String, String](topic, line))
61. println(line)
62. }
63. Thread.sleep(2000)
64. }
65. }
66.}
2.数据处理
对广告点击流数据中的黑名单进行管理。通过统计每日每个用户对每个广告的点击次数,将超过一定阈值的用户添加到黑名单,并对广告点击流数据进行黑名单过滤,确保只处理非黑名单用户的广告点击数据。
1.import java.sql.Connection
2.import java.text.SimpleDateFormat
3.import java.util.Date
4.import com.atguigu.bean.Ads_log
5.import com.atguigu.utils.JdbcUtil
6.import org.apache.spark.streaming.dstream.DStream
7.
8.object BlackListHandler {
9. // 时间格式化对象
10. private val sdf = new SimpleDateFormat("yyyy-MM-dd")
11.
12. def addBlackList(filterAdsLogDSteam: DStream[Ads_log]): Unit = {
13. // 统计当前批次中单日每个用户点击每个广告的总次数
14. // 1.将数据接转换结构 ads_log=>((date,user,adid),1)
15. val dateUserAdToOne: DStream[((String, String, String), Long)] =
16. filterAdsLogDSteam.map(adsLog => {
17. // a.将时间戳转换为日期字符串
18. val date: String = sdf.format(new Date(adsLog.timestamp))
19. // b.返回值
20. ((date, adsLog.userid, adsLog.adid), 1L)
21. })
22.
23. // 2.统计单日每个用户点击每个广告的总次数
24. // ((date,user,adid),1)=>((date,user,adid),count)
25. val dateUserAdToCount: DStream[((String, String, String), Long)] =
26. dateUserAdToOne.reduceByKey(_ + _)
27.
28. dateUserAdToCount.foreachRDD(rdd => {
29. rdd.foreachPartition(iter => {
30. val connection: Connection = JdbcUtil.getConnection
31. iter.foreach {
32. case ((dt, user, ad), count) =>
33. JdbcUtil.executeUpdate(
34. connection,
35. """
36. |INSERT INTO user_ad_count (dt,userid,adid,count)
37. |VALUES (?,?,?,?)
38. |ON DUPLICATE KEY
39. |UPDATE count=count+?
40. """.stripMargin,
41. Array(dt, user, ad, count, count)
42. )
43. val ct: Long = JdbcUtil.getDataFromMysql(
44. connection,
45. "select count from user_ad_count where dt=? and userid=? and adid =?",
46. Array(dt, user, ad)
47. )
48. if (ct >= 30) {
49. JdbcUtil.executeUpdate(
50. connection,
51. "INSERT INTO black_list (userid) VALUES (?) ON DUPLICATE KEY update userid=?",
52. Array(user, user)
53. )
54. }
55. }
56. connection.close()
57. })
58. })
59. }
60.
61. def filterByBlackList(adsLogDStream: DStream[Ads_log]): DStream[Ads_log] = {
62. adsLogDStream.transform(rdd => {
63. rdd.filter(adsLog => {
64. val connection: Connection = JdbcUtil.getConnection
65. val bool: Boolean = JdbcUtil.isExist(
66. connection,
67. "select * from black_list where userid=?",
68. Array(adsLog.userid)
69. )
70. connection.close()
71. !bool
72. })
73. })
74. }
75.}
3.实现实时应用程序
主要负责处理广告点击流数据,并根据MySQL中的黑名单信息对数据进行过滤和管理。实时读取Kafka中的数据并进行转换,然后根据需求进行黑名单过滤和黑名单管理操作。最后,将经过处理的数据进行统计和输出。
1.import com.atguigu.bean.Ads_log
2.import com.atguigu.handler.BlackListHandler
3.import com.atguigu.utils.MyKafkaUtil
4.import org.apache.kafka.clients.consumer.ConsumerRecord
5.import org.apache.spark.SparkConf
6.import org.apache.spark.streaming.{Seconds, StreamingContext}
7.import org.apache.spark.streaming.dstream.{DStream, InputDStream}
8.
9.object RealTimeApp {
10. def main(args: Array[String]): Unit = {
11. //1.创建 SparkConf
12. val sparkConf: SparkConf = new SparkConf().setAppName("RealTimeApp ").setMaster("local[*]")
13.
14. //2.创建 StreamingContext
15. val ssc = new StreamingContext(sparkConf, Seconds(3))
16.
17. //3.读取数据
18. val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream("ads_log", ssc)
19.
20. //4.将从 Kafka 读出的数据转换为样例类对象
21. val adsLogDStream: DStream[Ads_log] = kafkaDStream.map(record => {
22. val value: String = record.value()
23. val arr: Array[String] = value.split(" ")
24. Ads_log(arr(0).toLong, arr(1), arr(2), arr(3), arr(4))
25. })
26.
27. //5.需求一:根据 MySQL 中的黑名单过滤当前数据集
28. val filterAdsLogDStream: DStream[Ads_log] = BlackListHandler.filterByBlackList(adsLogDStream)
29.
30. //6.需求一:将满足要求的用户写入黑名单
31. BlackListHandler.addBlackList(filterAdsLogDStream)
32.
33. //测试打印
34. filterAdsLogDStream.cache()
35. filterAdsLogDStream.count().print()
36.
37. //启动任务
38. ssc.start()
39. ssc.awaitTermination()
40. }
41.}