IDE /完整分析C4819编译错误的本质原因
文章目录
- 概述
- 基本概念
-
- 代码页标识符
- 字符集和字符编码方案
- 源字符集和执行字符集
- 编译器使用的字符集
-
- 'VS字符集配置' 有何作用
- 编译器 - 源字符集
- 编译器 -执行字符集
- Qt Creator下配置MSVC编译器参数
- 动态库DLL字符集配置不同于可执行程序EXE
- 总结
概述
本文将从根本原因上来分析和解决 “C4819” 编译告警问题。“C4819: 该文件包含不能在当前代码页(936)中表示的字符,请将该文件保存为Unicode格式以防止数据丢失”。
使用 QtCreator + MSVC 编译器组成的集成开发环境时,若不合理配置IDE编辑器和编译器的文件编码格式选项,则很可能遇到如下告警,“C4819: 该文件包含不能在当前代码页(936)中表示的字符,请将该文件保存为Unicode格式以防止数据丢失”。甚至是更严重的编译错误,那种看上去很无厘头的错误。
使用一个简单的示例程序便可以复现上述问题,
环境: QtCreator + MSVC2017_x64,其中 QtCreator 工具 - 文本编辑器 - 行为 - 文件编码,使用默认的 UTF -8 编码配置,关于此配置的含义和使用方法,可参考 《IDE /Qt Creator 文本编辑器之文件编码设置》中的相关讲解,这里不再赘述。
void Widget::on_pushButton_clicked() {
ui->textEdit->append("青云志");
}
编译报错,

如上,QtCreator 和 MSVC 均使用了默认字符编码配置,即,QtCreator文本编辑器配置文件编码格式为UTF-8无BOM,没有意识到MSVC还需要进行字符编码方向上的编译配置。此时,若你的代码文件中包含中文字符,哪怕汉字是在注释中,都可能会遇到C4819编译告警,或其他奇怪的编译错误。
基本概念
为了彻底地解决这个问题,有些基础概念必须先了解到。
代码页标识符
代码页标识符(Code Page Identifier)是用于标识特定字符编码方案的数字或名称。每个代码页标识符对应于一种字符编码,用于指定如何将字符映射到二进制数据。例如,UTF-8编码的代码页标识符是 65001,简体中文GB2312编码的代码页标识符是 936,中文GB18030编码的代码页标识符是54936。
在 Windows 系统中,代码页标识符用于指定文本文件的编码方式、控制台的默认字符编码以及在代码中使用的字符串的编码方式。在编程中,可以使用代码页标识符来指定文件读取、字符串转换和字符集处理等操作所使用的编码方式。随着 Unicode 的普及,推荐使用 Unicode 编码(如 UTF-8 或 UTF-16)来处理文本和字符串,以确保更好的字符支持和跨平台的兼容性。
GB2312是中国国家标准简体中文字符集,于1980年发布,使用双字节表示每个汉字。它覆盖了汉字的基本字符集,共收录了6763个汉字和682个非汉字字符。GBK(Guojia Biaozhun Kuozhan)是中国国家标准(GB2312)的扩展版本,也被称为GB2312-1980,使用双字节编码。GBK字符集支持简体中文和繁体中文字符,包括基本汉字、常用标点符号、部分生僻字以及一些特殊符号。GB18030也是GB2312的扩展版本,于2000年发布,也称作中国国家标准的超大字符集。它增加了更多的汉字字符,包括繁体字和少数民族文字,包含GB2312和GBK中的字符,以及其他语言的字符,如日文、韩文等,使用1到4个字节表示一个字符。GB18030 正逐渐取代GB2312,成为更为广泛使用的中文字符编码标准。
字符集和字符编码方案
字符集和字符编码是两个概念,字符集是一组字符的集合,而字符编码则是将字符映射到具体的字节序列的规则。
最符合这个定义的是,Unicode字符集。它有多种字符编码方式,
UTF-8 (Unicode Transformation Format 8-bit):是一种变长编码方式。它使用1至4个字节表示Unicode字符集不同的字符,能够表示几乎所有的Unicode字符,包括ASCII字符。
UTF-16 (Unicode Transformation Format 16-bit):也是一种变长编码方式。它使用2或4个字节表示Unicode字符集不同的字符,其中大部分字符使用2个字节表示,而一些辅助字符需要4个字节表示。
UTF-32 (Unicode Transformation Format 32-bit):是一种固定长度编码方式,使用4个字节表示Unicode字符集中的每个字符。每个字符都使用相同的固定长度,简化了字符处理和索引操作,但需要更多的存储空间。
猿们容易搞混字符集和字符编码的概念,主要因为,
像GB2312、GBK、GB18030等名称,它们通常既可以代表字符集也可以代表字符编码方案。以GBK为例,当其作为字符集时,它定义了一组字符的范围和对应的编码;同时其也作为字符编码方案,规定了如何将字符映射为字节序列。GBK字符集定义了包括汉字、符号和其他字符在内的一系列字符。而GBK字符编码方案规定了每个字符在计算机存储和传输时所使用的字节序列。GBK使用双字节编码,每个字符由两个字节表示,其中高字节和低字节分别表示字符的区位码。因此,更合适的描述方式是,GBK字符集和GBK字符编码方案,而不是笼统的说GBK。
大家都兼容ASCII字符集和字符编码,
单说,ASCII(American Standard Code for Information Interchange)时,它既是字符集也是字符编码。它是最早的字符集之一,最早于1963年制定并在1967年得到广泛采用,包括英文字母、数字、标点符号和一些控制字符,例如换行符和制表符。ASCII 字符集并不是只有ASCII编码这一种编码方式,就是我们常见的那张ASCII字符编码表。
早期ASCII字符编码使用7位二进制来表示字符,称为ASCII-7。在ASCII-8编码中,前128个字符的编码与7位ASCII完全一致,后128个字符则用来表示特殊字符、扩展字符和非英文字符,例如特殊符号、重音符号、货币符号等。要注意的是,扩展出来的这些表示,存在多种变种,以满足特定地区或语言的需求。
其实,其他的字符集都可以看做是 ASCII-7 的扩展,因此响应的编码方案上,也都兼容ASCII编码方案。如,UTF-8编码使用1个字节表示ASCII字符,其编码范围与ASCII编码完全相同。UTF-16编码使用2个字节表示ASCII字符,其中高字节为0,低字节与ASCII编码完全相同。看一张表,了解下中文字符集GBK,
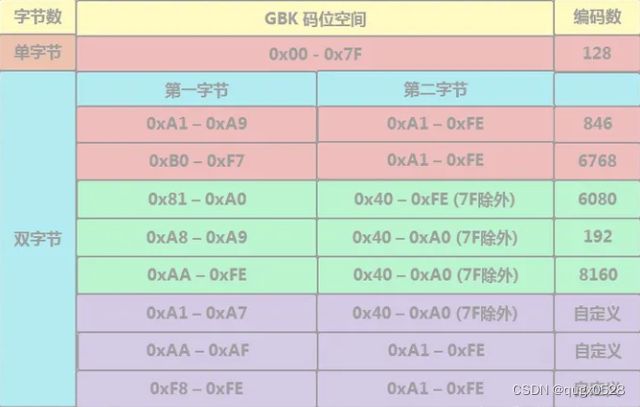
我们通常说,GBK编码的编码范围是8140-FEFE,那是因为,它是直接包含了上图红色标注部分的ASCII编码和GB2312编码。也就是说,GB18030/GBK/GB2312都是完全的兼容ASCII字符集和字符编码的。只有极少数不常见的编码不兼容ASCII字符集的ASCII字符编码,此处不深究。
因此,一个重要的结论是,
由于英文和数字字符在主流的字符编码中都有一致的表示方式,因此无论是使用 ASCII、UTF-8、UTF-16 还是其他常见的字符编码,对于只包含英文和数字的文件,它们在加载和处理时都会得到相同的结果。
源字符集和执行字符集
几年前首次尝试解决 C4819 告警问题时候,记录了 MicroSoft 官网下的 “将源字符集和执行字符集设置为 UTF-8” 这篇文章,当时没有细看,只知道里头提到了,源字符集和执行字符集 这么两个名词。
设置源字符集,

源字符集是用于解释程序源代码文本的编码方式。在编译前,源代码文本会被转换成内部表示形式(它应该是指我们的可见字符,这里偏向于指代C++语言中定义的那些字符),作为预处理阶段的输入。然后,内部表示形式会被转换成执行字符集,用于在可执行文件中存储字符串和字符值,这个具体的过程,后续章节还有涉及。
扩展的源字符集,
您可以使用/source-charset选项来指定扩展的源字符集,用于处理源文件中包含的不在基本源字符集中表示的字符。其中所谓扩展的源字符集,是指除了基本源字符集(C++语言标准规定的字符集)之外,可能需要额外的字符集来表示一些特殊字符或非标准字符。
C++语言标准规定的字符集是基本源字符集(Basic Source Character Set)。该字符集包含了C++语言中可以直接使用的字符,包括数字、大小写字母、一些标点符号和特殊符号等。基本源字符集是C++语言标准所定义的,对于所有符合C++标准的编译器,都必须支持这个字符集。如此说来,我们常见的UTF-8、UTF-16、GB2312 等都算是C++基本字符集的扩展的源字符集。
设置执行字符集,

编译阶段(compilation phase)是指将源代码转换成可执行代码的过程中的各阶段,通常包括:
预处理阶段(Preprocessing phase 在预处理阶段,预处理器会对源代码进行处理,包括宏展开、条件编译、头文件包含等操作)、词法分析阶段(Lexical analysis phase)、语法分析阶段(Syntax analysis phase)、语义分析阶段(Semantic analysis phase)、代码生成阶段(Code generation phase)、优化阶段(Optimization phase)。
如上图所示,执行字符集的作用阶段是,预处理阶段后的程序文本处理。这个字符集用于编译后的代码中任何字符串或字符字面量的内部表示。设置此选项可指定扩展的执行字符集,用于处理源文件中包含的C++基本执行字符集无法表示的字符,如中文字符。
通俗点讲,执行字符集是指编译器生成的可执行文件中用于存储字符串和字符值的编码方式。编译器在预处理阶段分析了源代码文件的编码方式并将其加载为字符,对于代码中的字符串字符,编译器会使用相同或不同的字符编码,以二进制数据写入到可执行程序中。
另外,执行字符集是指程序运行时使用的字符编码集合。它定义了程序执行过程中处理字符数据的方式,包括输入、输出、内存存储和处理等。执行字符集通常与操作系统和环境相关,例如,在Windows操作系统中,默认的执行字符集是根据系统区域设置确定的,如 GBK、UTF-8 等。
编译器使用的字符集
一开始,我对 "VS项目属性 -> 常规 -> 项目默认值 -> 字符集” 配置的主要作用存在较大的误解,对 MSVC编译器 字符编码相关的编译参数也是理解的一塌糊涂。直至,我整理完成《IDE /字符串 /字符编码与文本文件(如cpp源代码文件)》、《IDE/VS项目属性中的 <字符集> 配置项,它到底是干什么用的?》、《IDE /Qt Creator 文本编辑器之文件编码设置》等相关文章的整理,它们都始于我对C4819编译告警的追究。
‘VS字符集配置’ 有何作用
VS项目下可查看 “项目属性 -> 常规 -> 项目默认值 -> 字符集” 配置,其Tip提示为:通知编译器使用指定的字符集。此配置项一共有三个选项值:
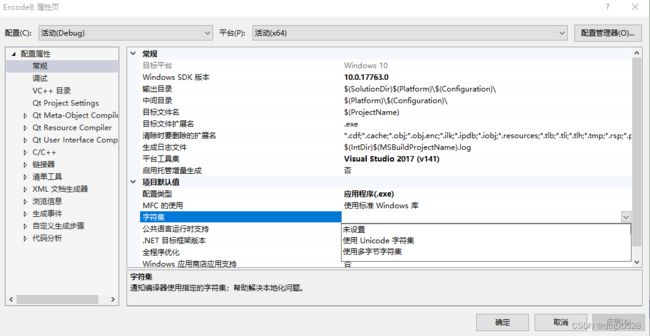
关于 VS项目属性 -> 常规 -> 项目默认值 -> 字符集,配置的具体作用,可参考 MFC下对Unicode 和多字节字符集 (MBCS) 支持、《IDE/VS项目属性中的 <字符集> 配置项,它到底是干什么用的?》中的相关表述,此处不再赘述。
最终的结论是,
VS项目属性 - 常规 -项目默认配置 - 字符集配置,既不是源字符集、也不是执行字符集,更不会影响到VS文本编辑器的编码格式,它仅影响了 MSVC 编译器 预处理器宏 UNICODE 是否被定义。
编译器 - 源字符集
如果你喜欢或者被迫必须在MSVC编译器下使用UTF-8无BOM的源代码文件。如,你的项目原先是在QtCreator下创建的,源代码文件都是UTF-8无BOM格式。此时可以参照官方给出的如下方法:
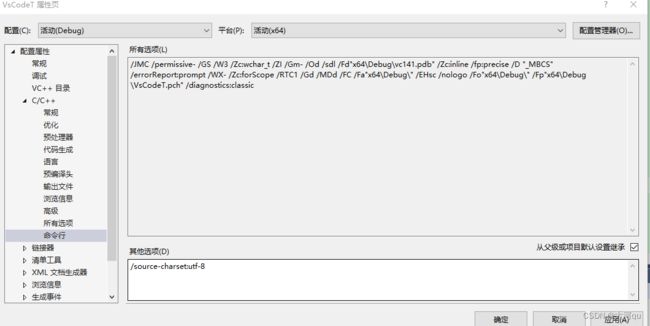
在以前VS2015或更低版本的时候,我是用过如下指令的,将其放在cpp的开头,我记得测试是生效的,但是如今VS2017已经不识别此指令,可能是废弃了。
//原本是支持的
#pragma execution_charset_set("utf-8")
//打我记事就没有此指令
#pragma source_charset_set("utf-8")
至于,如何在 Qt Creator下配置MSVC编译器参数,请参见后续章节。
编译器 -执行字符集
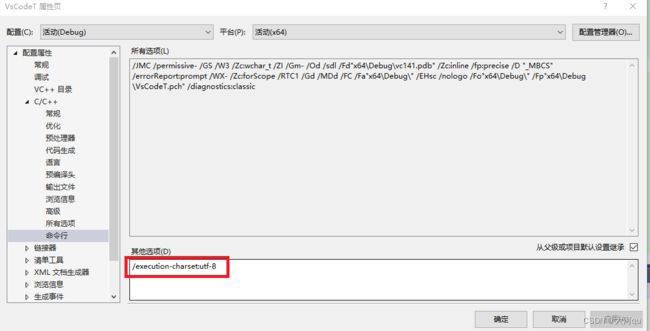
编译参数中支持同时设置源字符集和执行字符集,

Qt Creator下配置MSVC编译器参数
在QtCreator+MSVC集成开发环境下,文件编辑器文本编码默认为UTF-8无BOM格式,使用概述章节中的测试代码。在项目pro文件中,使用qmake 变量 QMAKE_CXXFLAGS 来配置 VC++ 编译器参数,
#plan-1
#QMAKE_CXXFLAGS += /execution-charset:utf-8
#plan-2
#QMAKE_CXXFLAGS += /source-charset:utf-8
#plan-3
QMAKE_CXXFLAGS += /utf-8
经过测试,使用方案1并不能消除编译错误;使用方案2可以消除编译错误,但是运行时会在textEdit中输出乱码;使用方案3,同时修改源字符集和执行字符集,则编译和运行都是正常的。
方案1和方案3的测试效果都好理解,我们重点再分析下方案2的测试效果。因为在 《IDE/VS项目属性中的 <字符集> 配置项,它到底是干什么用的?》文中,我们已经测试过,在VS集成开发环境下,代码文件若使用utf-8无BOM格式,我们只需修改源字符集配置为utf-8,而无论执行字符集使用何种编码,都可以使得中文字符串是正常输出的。
在没有进行MSVC执行字符集配置的时候,其默认是使用ANSI字符集将代码中的字符串编码到二进制的可执行程序中的。由于Qt框架的QString和输出控制台窗口(它是D:\Qt\Qt5.9.3\Tools\QtCreator\bin\qtcreator_process_stub.exe,而不是系统命令窗口),它们的内部都默认使用 Unicode 编码。
以示例代码中用到的 void append(const QString &text) 函数为例,此时字符串的ANSI编码值将被QString按照Unicode进行解析,理解到这里,方案2下的路那么就不足为奇啦。但是VS控制台应用程序使用的系统命名窗口,是可以接收任何编码值的,没有QString那样的硬性限制,因此,无论使用何种执行字符集,都不会乱码。
虽然上述方案是可行的,但我并不建议去这么搞。如果想要使用MSVC编译器,你应该尽量使的源代码文件为ANSI编码格式。当然,到底如何选择,还得看实际情况。
其他,
#pragma execution_charset_set(“utf-8”)
以前确实用过,但发现其在VS2017以及VS2015+update3的MSVC编译器下,无论是使用QtCreator还是VS,都不再被识别。
动态库DLL字符集配置不同于可执行程序EXE
又想起个问题,如果DLL使用的字符集和EXE使用的字符集配置不一样,会有问题吗?这里的不一致,可能包括:源字符集不一样、执行字符集不一样、VS属性字符集设置不一样。从另一个角度描述此问题的话,也可以问:字符集的问题会从编译阶段延伸到运行阶段吗?
从理论上,动态库和可执行程序,它们编译过程是相互独立的。顾,各自愿意以何种编码加载代码文件,是相互无影响的,可得,它们的源字符集配置不会相互影响;DLL和EXE也都是在编译阶段生成的二进制文件,既是编译相关的,也可得,它们的执行字符集配置不会相互影响。
从理论上分析,动态库和可执行程序是两个独立的VS项目,而前文讲到的VS字符集配置,它是针对具体项目的。因此不同项目的VS字符集配置理应不会相互影响。那么,Windows API 在涉字符串处理的接口上,何苦要搞A和W两套接口呢?
Windows API 在涉及字符串处理的接口上提供了A和W两套接口主要是为了兼容历史遗留问题和支持不同的字符编码方式。在 Windows 系统中,ANSI API (以 “A” 结尾的函数名)通常使用的是当前系统的本地字符编码,也称为本地代码页(Code Page)。Unicode API(以 “W” 结尾的函数名)使用的是 Unicode 字符编码,通常为 UTF-16 编码。在现代 Windows 开发中,推荐使用 Unicode API 进行字符串处理,以支持更广泛的字符集和避免字符编码的问题。
在 《IDE/VS项目属性中的 <字符集> 配置项,它到底是干什么用的?》文中,我们将字符串 “我爱你中国” 编写进入不同编码格式下的代码文件中,并进行了较完善的测试。如下,对"Windows API 之 A 和 W 接口"章节中的测例稍加修改,使得DLL和EXE使用不同的VS字符集配置,源代码文件均使用ANSI编码格式,源字符集和执行字符集保持默认。
DLL项目-配置使用Unicode字符集,配置预处理器TEST_LIBRARY,配置输出目录…\bin\
//dll if_export.h
#ifndef DLL_C_IF_H_
#define DLL_C_IF_H_
#include //dll if_export.cpp
#include "if_export.h"
std::string Test_Printf(void)
{
#ifdef UNICODE
return "DLL:我爱你Unicode!\r\n";
#else
return "DLL:我爱你ANSI!\r\n";
#endif // !UNICODE
}
EXE项目-配置使用多字节字符集,配置增加连接器输入DemoDll.lib,配置输出目录和链接器附加库目录…\bin\
//exe //main.cpp //river.qu 20220701
#include 执行结果,
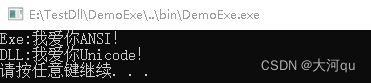
结论,
DLL和EXE中使用不同VS字符集配置,并不会相互影响。
总结
在源字符集配置的加持下,编译器预处理阶段将源代码翻译为字符的过程中,如果字符集不匹配导致翻译异常,但不会影响到后续编译过程的词法分析、语法分析、语义分析等,则通常只是进行C4819告警。如果这种错误的解析,使得后续编译过程发生混乱,则会导致严重的编译错误。
解决 “C4819: 该文件包含不能在当前代码页(936)中表示的字符” 问题的关键在于,使得编译器可以正确的字符编码加载源代码文件。对于MSVC编译器,它可以轻松识别带BOM的UTF-8、UTF-16等。但是对于无BOM的UTF-8编码的源代码文件,要想使得MSVC在编译预处理阶段能加载它,则必须进行编译器的源字符集配置。
通常在QtCreator + MSVC 组成的IDE下,我们建议修改QtCCreator文本编辑器文件编码格式为GB2310或GB18030等ANSI编码格式,以保持与MSVC编译器默认使用的源字符集和执行字符集一致。
假设可执行程序EXE_M使用了动态库DLL_N的导出接口,通常,DLL的源字符集配置、执行字符集配置、VS项目字符集配置,都不会与EXE使用的响应类型有冲突。
关于字符集、字符编码、编译器源字符集、编译器执行字符集、VS项目属性默认字符集配置的相关问题,还可参考本IDE专栏下的其他文章。后续本文可能持续更新。(20230710 river.qu weifang)