八股文之linux常用指令
文章目录
- 不敢用命令:rm -rf *
- 八股文之linux指令
-
- 文件和目录
-
- cd
- ls
- mkdir
- pwd&dirs
- cp
- mv
- touch
- rz,sz
- 查看文件内容
-
- cat
- head
- tail
- more
- less
- grep
- sed
- uniq
- wc
- 综合使用
- 搜索文件
-
- find
- ll
- ps
- 文本处理
-
- vim
-
- insert
- delete
- update
- select
- sed
-
- INSERT
- DELETE
- UPDATE
- SELECT
- 打包,压缩
- 用户
-
- 用户和用户组管理
- 进程
- 网络信息
- 磁盘
-
- df
- du
- linux如何查询系统负载情况
- 软链接和硬链接
- 权限管理
-
- chmod:改变文件或者文件夹权限
- chown:改变文件所有者
- 线上排查命令
-
- 高负载,CPU过高解决
-
- 通过jdk,linux相关命令解决
- 通过athas开源线上监控诊断产品排查
- 问题:jvm疯狂Gc导致cpu升高
- 问题:jvm相关oom问题
- 问题:记一次FullGC的排查经历--从日志到业务代码
不敢用命令:rm -rf *
八股文之linux指令
文件和目录
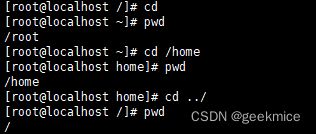
cd
cd /home
cd .. # 返回上一级目录
ls
List information about the FILEs (the current directory by default).
列出目录信息,默认是当前目录
ls
ls *[0-9]* # 列出当前目录所有包含数字文件,目录

mkdir
介绍:用来创建目录,目录树
语法:
mkdir (选项)(参数)
mkdir dir1 dir2 # 创建目录dir1,dir2 ,前提dir1,dir2不存在
mkdir -p tmp/dir1/dir2 # 创建目录树

![]()
pwd&dirs
查询文件目录
pwd # 查询当前位置所在目录
dirs # 查询当前位置所在目录

cp
介绍:将源文件或目录复制到目标文件或目录中
参数:
源文件:制定源文件列表。默认情况下,cp命令不能复制目录,如果要复制目录,则必须使用-R选项;
目标文件:指定目标文件。当“源文件”为多个文件时,要求“目标文件”为指定的目录。
cp cp.md cp_backup.md # 如果cp_backup.md存在询问是否覆盖,y覆盖
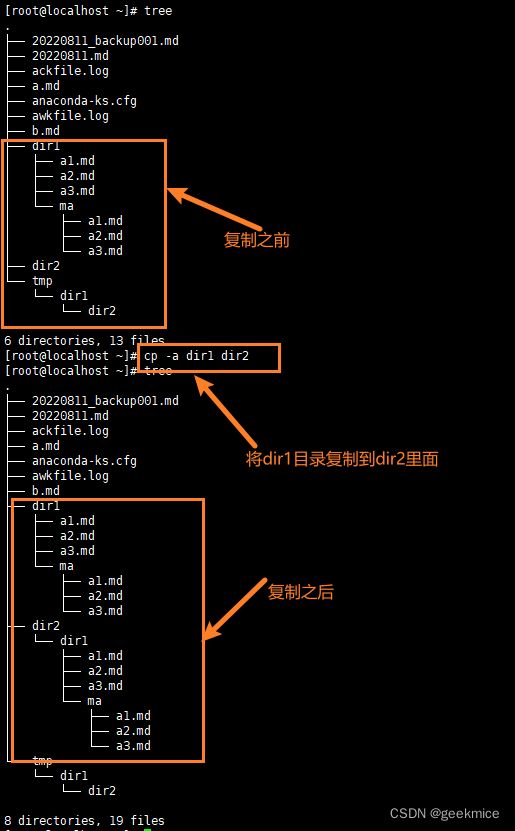
cp -a dir1 dir1_backup # 如果dir1目录,备份需要-a
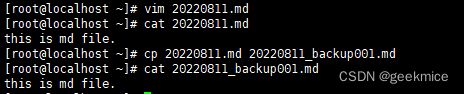
cp 20220811.md 20220811_backup001.md # 将20220811.md文件复制一份,变为20220811_backup001.md
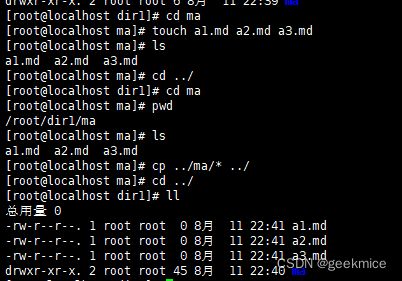
cp tmp/* . # 将tmp目录下所有文件复制到当前目录
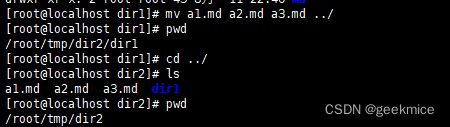
mv
mv命令 用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。source表示源文件或目录,target表示目标文件或目录。如果将一个文件移到一个已经存在的目标文件中,则目标文件的内容将被覆盖
# 将目录dir2中移动到tmp目录
mv dir2 tmp
# 移动多个文件,将三个md文件移动上一级目录
mv a1.md a2.md a3.md ../
mv *.md .. # 移动以md结尾的文件到上一个目录
# 重命名文件,目录
mv a2.md a2_backup.md
mv dir1 dir1_backup
# 提示是否覆盖文件
mv -i a.md /tmp/dir1

touch
创建新的空文件
touch a.md

rz,sz
服务器接收文件
rz
# 选择本地需要上传文件
# 上传
服务器下载文件
sz 待下载文件
# 本地目录选择,c:\users\用户\Downloads
# 本地查看
SecureCRT的zmodem transfer canceled by remote side错误
原因:下载文件中可能包含控制字符的问题
解决:rz -e 命令可以解决
查看文件内容
cat
介绍:连接多个文件并打印到标准输出。
# 从上往下查看文件内容,内容少可以采纳,多的话搭配其他指令使用head,tail,grep,more
cat application.log
# 打印行号并且打印从上往下所有信息
cat -n application.log
# 创建文件,将文件内容输入之后Ctrl+D结束
cat > temp.log
# 合并文件
[root@localhost ~]# cat > a1.md
this is a1.md
[root@localhost ~]# cat > a2.md
this is a2.md
[root@localhost ~]# cat a1.md a2.md > a3.md
[root@localhost ~]# cat a3.md
this is a1.md
this is a2.md
# 追加内容
touch temp.log
vi temp.log
cat << EOF >> temp.log
> 追加的内容
> EOF
cat temp.log
this is temp.log
追加的内容
head
显示文件的开头部分。
参数说明
-n, --lines=[-]NUM 显示前NUM行而不是默认的10行;如果NUM前有"-",
那么会打印除了文件末尾的NUM行以外的其他行。
head application.log # 查看文件application.log前十行内容
head -n 3 application.log # 查看文件application.log前三行内容
head -n +3 application.log # 查看文件application.log前三行内容
head -n -3 application.log # 查看文件application.log倒数三行之外内容
cat -n application.log | head -n -10 # 查看文件application.log最后十行之外内容
cat -n application.log | tail -n +10 | head -n 11 # 查看文件第10行到20行内容
tail
在屏幕上显示指定文件的末尾若干行
注意:如果表示字节或行数的NUM值之前有一个+号,则从文件开头的第NUM项开始显示,而不是显示文件的最后NUM项
-n, --line=NUM 输出文件的尾部NUM(NUM位数字)行内容。
tail application.log # 查看文件最后十行内容
tail -n -3 application.log # 查看文件application.log最后三行内容
tail -n 3 application.log # 查看文件最后三行内容
tail -n +3 application.log # 查看文件第三行到最后内容
tail 200f application.log # 实时查询最后200行数据
more
显示文件内容,每次显示一屏
是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)
# 用法一 -n
more -3 application.log # 每页三行数据展示
more application.log # 分页查询,enter下一行,空格下一页
q # 结束浏览
Ctrl + C # 结束浏览
查询日志,有时候生产环境禁止使用vim,less查询日志命令,这时候可以使用more
1、more 文件名
2、进入文件之后,英文状态点击 ‘v’,进入vim模式
3、输入斜杠,斜杠之后输入关键字,比如/java
4、单击“enter”,查找关键字
5、单击“n”,查找下一个关键字,单击“shift + n”,查找上一个关键字
6、查询结束,输入“:q”,退出vim模式,进入more命令模式
7、单击“q”或输入“ctrl + c”,退出more命令
more application.log
v
/java
enter
n
:q
enter
less
分屏上下翻页浏览文件内容
less命令 的作用与more十分相似,都可以用来浏览文字档案的内容,不同的是less命令允许用户向前或向后浏览文件,而more命令只能向前浏览。用less命令显示文件时,用PageUp键向上翻页,用PageDown键向下翻页。要退出less程序,应按Q键。
less application.log # 分页查询,enter下一行,空格下一页
q # 结束浏览
cat -n application.log | less # 分页查询,enter下一行,空格下一页
less application.log # 分页查看搜索关键字
# 1、英文状态输入 /
# 2、关键字复制进去+enter
# 3、输入字母 n 下一个
grep
(全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能配合多种命令使用,使用上十分灵活
参数说明
-n 显示行号 line-number
-i 不区分大小写 -i, --ignore-case
# 标记匹配颜色 --color=auto 选项
grep 'abc' application.log --color=auto
# 查看日志applicaion.log含有abc行内容
grep 'abc' application.log
# 查看日志这个时间点的内容
grep '2022-08-11 18:17' application.log | more
# 查看日志这个时间段的内容(分钟)
grep '2022-08-11 18:1[0-9]' application.log | more
# 不区分大小写查询abc所在行内容
grep -ni 'Abc' application.log
sed
介绍:它是文本处理中非常重要的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等
sed -n 1,2p application.log # 查看第1到第2行内容
sed -n 10p application.log # 查看第十行内容
cat -n application.log | sed -n '/多渠道实时进件/'p # 查看字符串“多渠道实时进件”所在的行
cat -n application.log | sed -n '/java/'p # 查看java 关键字所在行

uniq
介绍: uniq是对文本文件进行行去去重的工具
以行为单位,进行行与行之间的字符串比较并进行去重
只能对有序的文本行进行有效去重,所以常与sort命令结合使用
| 参数 | 解释说明 |
|---|---|
| -c | 统计行出现的次数 |
| -d | 只显示重复的行并且去重 |
| -u | 只显示唯一的行 |
| -i | 忽略字母大小写 |
| -f | 忽略前N个字段(字段间用空白字符分隔) |
1、与sort结合使用
cat -n uniqfile.log
---
[root@localhost ~]# cat -n uniqfile.log
1 111111111111
2
3
4
5 222222222222
6 abcdefg
7 ABCdeFG
8 aaaa
9 aaaa
10 bbbb
11 this
12 cccc
13 eeee
14 llll
15
16 222222222222
---
# 单独使用uniq命令
uniq uniqfile.log
---
[root@localhost ~]# uniq uniqfile.log
111111111111
222222222222
abcdefg
ABCdeFG
aaaa
bbbb
this
cccc
eeee
llll
222222222222
---
# 说明:可以看出单独使用uniq命令时只对相邻重复行进行去重,无法进行有效去重
# 与sort结合使用
cat uniqfile.log | sort | uniq
---
[root@localhost ~]# cat uniqfile.log | sort | uniq
111111111111
222222222222
aaaa
abcdefg
ABCdeFG
bbbb
cccc
eeee
llll
this
---
# 先排序使重复的行相邻,然后使用uniq可以有效去重
2、统计出现的次数,使用-c参数
使用-c,–count可以统计重复行出现的次数
cat uniqfile.log| sort | uniq -c
---
[root@localhost ~]# cat uniqfile.log | sort | uniq -c
4
1 111111111111
2 222222222222
2 aaaa
1 abcdefg
1 ABCdeFG
1 bbbb
1 cccc
1 eeee
1 llll
1 this
---
3、只显示唯一的行,使用-u参数
使用-d,–repeated只显示重复的行并且重复的行只显示一次
cat uniqfile.log | sort | uniq -dc
---
[root@localhost ~]# cat uniqfile.log | sort | uniq -dc
4
2 222222222222
2 aaaa
---
# 可以看到末尾的三行不重复的行没有显示,将重复的行进行去重后显示
4、忽略字母大小写,使用-i参数
[root@localhost ~]# cat uniqfile.log | sort | uniq -ci
4
1 111111111111
2 222222222222
2 aaaa
2 abcdefg
1 bbbb
1 cccc
1 eeee
1 llll
1 this
5、忽略前N个字段进行去重,使用-f参数
[root@localhost ~]# cat uniqfile.log | sort | uniq
10 222222222222
11 111111111111
12 222222222222
1 llll
2 eeee
3 cccc
4 this
5 bbbb
6 aaaa
7 aaaa
8 ABCdeFG
9 abcdefg
[root@localhost ~]# cat uniqfile.log | sort | uniq -f 1
10 222222222222
11 111111111111
12 222222222222
1 llll
2 eeee
3 cccc
4 this
5 bbbb
6 aaaa
8 ABCdeFG
9 abcdefg
test.txt文件中每一行之前有行号,无法使用sort和uniq进行去重,可以使用-f参数忽略每一行的第一个字段,这样就可以忽略每一行之前的行号,对每一行之后的内容进行去重处理。
注意:字段之间必须是空白字符(空格或者tap键均属于空白字符)分隔,使用其他字符无法识别
对于这种情况也可以使用awk命令工具进行处理去除第一列的行号,然后通过管道符丢给sort和uniq命令处理,后续会继续更新awk等重要的文本处理工具。
wc
获取文件行数,字数,字节数
格式 wc option file
option说明
-c # 统计字节数,或--bytes或——chars:只显示Bytes数;。
-l # 统计行数,或——lines:只显示列数;。
-m # 统计字符数。这个标志不能与 -c 标志一起使用。
-w # 统计字数,或——words:只显示字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L # 打印最长行的长度。
-help # 显示帮助信息
--version # 显示版本信息
application.log文件内容
[root@VM-4-16-centos ~]# cat application.log
1
2
3
4
5
6
7
8
9
10
11
12
13
1、默认没有选项获取行数,字数,字节数
wc application.log
[root@VM-4-16-centos ~]# wc application.log
13 13 30 application.log
2、用wc命令怎么做到只打印统计数字不打印文件名
wc -l < application.log
[root@VM-4-16-centos ~]# wc -l < application.log
13
[root@VM-4-16-centos ~]# wc -l application.log | awk '{print$1}'
13
[root@VM-4-16-centos ~]# cat application.log | wc -l
13
综合使用
cat -n application.log | tail -200f | grep '多渠道实时进件' | more
# 查询日志,实时最后200行,含有字符串“多渠道实时进件” 分页
![]()
搜索文件
find
# 查找当前目录名字是application.log文件
find . -name application.log
# 模糊查询含有application的文件
find / -name '*application*'
# 查找结尾是log的文件
find / -name '*.log'
ll
# 查找当前目录含有application的文件
ll *application*
# 查找当前目录含有数字的文件或者目录
ll *[0-9]*
# 查看目录数字结尾的文件
ll*[0-9]
# 查看目录数字开头文件
ll [0-9]*
# 查看当前目录 log结尾的文件
ll *.log
ps
ps -ef | grep java
文本处理
vim
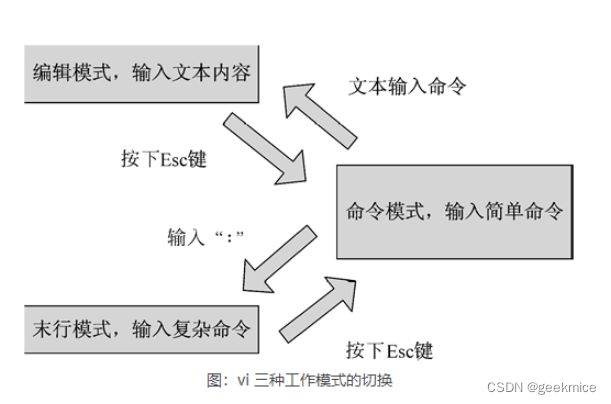
vi命令 是UNIX操作系统和类UNIX操作系统中最通用的全屏幕纯文本编辑器。Linux中的vi编辑器叫vim,它是vi的增强版(vi Improved),与vi编辑器完全兼容,而且实现了很多增强功能。
vi编辑器支持编辑模式和命令模式,编辑模式下可以完成文本的编辑功能,命令模式下可以完成对文件的操作命令,要正确使用vi编辑器就必须熟练掌握着两种模式的切换。默认情况下,打开vi编辑器后自动进入命令模式。从编辑模式切换到命令模式使用“esc”键,从命令模式切换到编辑模式使用“A”、“a”、“O”、“o”、“I”、“i”键
文本输入模式
aio操作
编辑模式
查找,替换,保存
命令行模式
默认进入,上下左右移动,复制,替换操作
三种模式转换
注意:为了防止修改错误,无法返回上一个版本数据内容,提前说明两个指令
u 回退上一步
ctr + r 下一步
insert
介绍:在Vim的Normal模式中输入A/I/O,a/i/o字符进行对应的增加操作
如何开启:
1、执行命令 vi application.log
2、即可进入文本编辑模式
3、输入a,i,o相关命令进行对应操作
# a命令:光标所在字符后面添加需要的字符
# A命令:光标所在行尾部添加需要的字符
# i命令:光标所在字符前面添加需要的字符
# I命令:光标所在字符头部添加需要的字符
# o命令:光标所在字符下一行需要的字符
# O命令:光标所在字符上一行需要的字符
delete
如何进入:
1、执行命令 vi application.log
2、即可进入文本编辑模式
3、输入相关命令x,d,g,$,0相关命令进行删除
- 输入x 删除光标对应的一个字符(4x代表删除4个字符)
- 输入dd删除光标所在行的整行数据(4dd 代表删除4行)
- 输入d0删除自当前光标至行首的内容
- 输入d$删除自当前光标至行尾的内容
- 输入dw 删除自当前光标至下一个word的开头
- 输入db 删除自当前光标至前一个word的开始
- 输入dG 删除当前行至文件尾的内容(注意知道就行,不推荐使用,危险性极大,类似于rm -rf)
- 输入 dgg 删除当前行至文件头的内容(注意知道就行,不推荐使用,危险性极大,类似于rm -rf)
update
- 输入r修改光标所在位置的字符(4r代表将4个字符替换); 输入R修改光标所在行的字符(4R代表将4组字符替换);
- 输入s删除光标所在行的字符,并进入插入状态(4s代表将4个字符删除);
- 输入S删除光标所在行的字符,并进入插入状态(4S代表将4个行删除); 输入cw删除一个词,并进入到插入状态(4cw代表将4个词删除)
select
- 在命令模式中,使用/或者?正向和逆向搜索
- 使用n和N在搜索结果中从前向后或者从后向前移动
- 使用*或者#进行该单词的顺序或者逆序匹配
sed
注意:关于sed命令都是在内存中进行的,所以不会写入原文件,如果需要修改源文件 -i
关于单引号和双引号说明
单引号:变量 P A T H 会 将 文 本 内 容 原 封 不 动 插 入 , 不 会 解 释 成 路 径 双 引 号 : 变 量 PATH会将文本内容原封不动插入,不会解释成路径 双引号:变量 PATH会将文本内容原封不动插入,不会解释成路径双引号:变量PATH会解析当做文本进行插入
总结
如果是普通字符串,使用单引号和双引号没问题
如果引号里面是变量或者反引号的话,需要解析变量后结果,就是用双引号
INSERT
# a 追加文本到指定行
# i 插入文本到指定行前
cat -n a.md
sed -i '2a abc' a.md
sed -i '2i ABC' a.md

DELETE
# 删除单行
# 删除第三行内容
sed 3d a.md
# 删除多行内容
# 删除第三到第四行内容
sed 3,4d a.md
# 根据正则删除
# 删除包含a这一行内容
sed '/a/d' a.md
# 删除空行
sed '/^$/d' a.md
UPDATE
# 替换操作:s命令
sed 's/abc/bo/' a.md
# -n选项 和 p命令 一起使用表示只打印那些发生替换的行:
sed -n 's/test/TEST/p' a.md
# 使用后缀 /g 标记会替换每一行中的所有匹配:
sed 's/book/books/g' file
SELECT
# 根据行号查询指定行信息
sed -n '5p' a.md
# 根据行号范围进行显示
sed -n 3,4p a.md
# 进行过滤
# 查询文档中包含字母内容
sed -n '/[a-zA-Z]/p' a.md
# 查询文档中包含a内容行
sed -n '/a/p' a.md
打包,压缩
tar:可以把一大堆文件和目录全部打包一个文件,对于备份文件或者将几个文件组合成一个文件便于网络传输
两个概念:
打包:将一大堆文件目录变成一个总的文件 tar
压缩:将一个的文件通过一些压缩算法变成一个文件 gzip,bzip2
tar
解包:tar zxvf filename.tar
打包:tar czvf filename.tar dirname
eg:tar czvf m1.tar m1 # 打包一个文件
gz命令
解压1:gunzip filename.gz
解压2:gzip -d filename.gz
压缩:gzip filename
.tar.gz 和 .tgz
解压:tar zxvf filename.tar.gz
压缩:tar zcvf filename.tar.gz dirname
压缩多个文件:tar zcvf filename.tar.gz dirname1 dirname2 dirname3.....
eg: tar -zxvf apache-zookeeper-3.6.1.tar.gz # 解压一个zookeeper的压缩文件
eg:tar zcvf m1.tar.gz m1
打包:tar zcvf ab.tar.gz a.md b.md
解压:tar zxvf ab.tar.gz
bz2命令
解压1:bzip2 -d filename.bz2
解压2:bunzip2 filename.bz2
压缩:bzip2 -z filename
-d --decompress
# 强制解压缩。 bzip2, bunzip2 以及 bzcat 实际上是同一个程序,进行何种操作将根据程序名确定。 指定该选项后将不考虑这一机制,强制 bzip2 进行解压缩。
-z --compress
# -d 选项的补充:强制进行压缩操作,而不管执行的是哪个程序。
压缩:bzip2 -z b.md
解压:bzip2 -d b.md.bz2
# z:gzip压缩
# z:解压
# v:显示解压压缩过程
# f:接着压缩
# c:创建压缩包
# -C:解压到指定目录
zip命令
解压:unzip filename.zip
压缩:zip -r -q filename.zip dirname

用户
用户和用户组管理
用户账号的添加、删除与修改。
用户口令的管理。
用户组的管理。
一、Linux系统用户账号的管理
用户账号的管理工作主要涉及到用户账号的添加、修改和删除。
添加用户账号就是在系统中创建一个新账号,然后为新账号分配用户号、用户组、主目录和登录Shell等资源。刚添加的账号是被锁定的,无法使用。
1、添加新的用户账号使用useradd命令
useradd 选项 用户名
选项:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组 指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
eg1:
[root@jack ~]# useradd -d /home/sam -m sam
[root@jack home]# cd sam
[root@jack sam]# ll
total 0
2、删除帐号
语法:userdel 选项 用户名
常用的选项是 -r,它的作用是把用户的主目录一起删除。
例如:
# userdel -r sam
此命令删除用户sam在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
3、修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
usermod 选项 用户名
例如:
# usermod -s /bin/ksh -d /home/z –g developer sam
此命令将用户sam的登录Shell修改为ksh,主目录改为/home/z,用户组改为developer。
4、用户口令的管理
passwd 选项 用户名
# passwd sam
5、查询用户信息
cat /etc/passwd 查看bai所有的用户du信息
[root@jack /]# cat etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
6、输入"cat /etc/passwd | grep 用户名 ",用于查找某个用户
[root@jack /]# cat /etc/passwd | grep test001
test001:x:1000:1000::/home/test001:/bin/bash
二、Linux系统用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
1、增加一个新的用户组使用groupadd命令。其格式如下:
groupadd 选项 用户组
可以使用的选项有:
-g GID 指定新用户组的组标识号(GID)。
-o 一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
实例1:
# groupadd group1
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
实例2:
# groupadd -g 101 group2
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
2、如果要删除一个已有的用户组,使用groupdel命令,其格式如下:
groupdel 用户组
例如:
# groupdel group1
此命令从系统中删除组group1。
3、修改用户组的属性使用groupmod命令。其语法如下:
groupmod 选项 用户组
常用的选项有:
-g GID 为用户组指定新的组标识号。
-o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。
-n新用户组 将用户组的名字改为新名字
实例1:
# groupmod -g 102 group2
此命令将组group2的组标识号修改为102。
实例2:
# groupmod –g 10000 -n group3 group2
此命令将组group2的标识号改为10000,组名修改为group3。
进程
ps -aux 显示系统所有进程
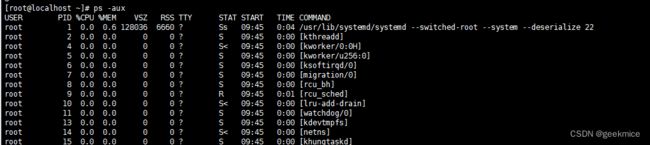
ps -ef
top
杀死进程
kill -9 pid
网络信息
网络端口查询
# 指定端口
# 1 开启防火墙
systemctl start firewalld
# 2 开放指定端口
firewall-cmd --zone=public --add-port=1935/tcp --permanent
# 命令含义:
--zone #作用域
--add-port=1935/tcp #添加端口,格式为:端口/通讯协议
--permanent #永久生效,没有此参数重启后失效
# 3、重启防火墙
firewall-cmd --reload
# 4 查看端口号
netstat -ntlp # 查看当前所有tcp端口·
netstat -ntulp | grep 1935 # 查看1935端口情况

磁盘
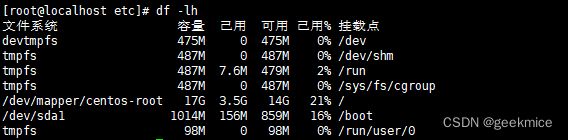
df
介绍:用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息
df -lh
du
介绍:也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
案例:
du -h
du -sh * :查询当前目录下所有的文件的大小以K,M,G为单位,提高信息的可读性。
场景:查看服务器中一个文件(比如日志)大小,在删除磁盘文件的时候能有一个对比,那个文件占用磁盘最大
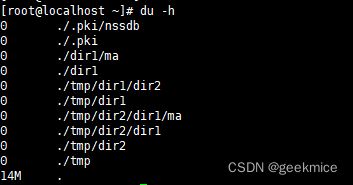
linux如何查询系统负载情况
w
top
uptime查看系统负载情况:uptime [option]
- -p 显示系统运行了多长时间
- -s 显示系统开始运行的时间和日期,并格式化输出:yyyy-mm-dd HH:MM:SS
- -v 获取版本信息
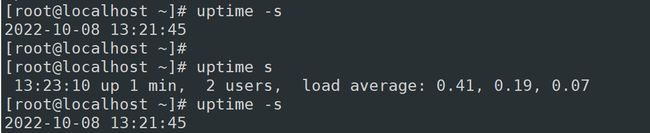
[root@izwz91quxhnlkan8kjak5hz ~]# uptime 13:53:50 up 20 days, 15:39, 2 users, load average: 0.34, 0.39, 0.32
// 13:53:50 当前时间
// up 20 days, 15:39 系统运行时间
// 2 user 正在登录用户数
// load average: 0.34, 0.39, 0.32 依次是 1分钟,5分钟,15分钟的平均负载 [root@izwz91quxhnlkan8kjak5hz ~]# uptime -s 2020-09-16 22:14:16 [root@izwz91quxhnlkan8kjak5hz ~]# uptime -p up 2 weeks, 6 days, 15 hours, 41 minutes
查看系统平均负载
[root@izwz91quxhnlkan8kjak5hz ~]# cat /proc/loadavg 0.37 0.22 0.25 2/414 4510
// 0.37 0.22 0.25 分别是1分钟、5分钟、15分钟内的平均负载
// 2/414 分母表示系统进程总数,分子表示正在运行的进程数
// 4510 表示最后一个数字表示最近运行的进程ID
系统平均负载:是指在特定时间间隔内运行队列中的平均进程数。
平均负载比CPU个数大的时候,系统就已经出现了过载:
1、当1分钟,5分钟,15分钟的三个值基本相同说明系统负载稳定。
2、如果1分钟的值远小于15分钟的值,就说明系统最近1分钟负载在减少,而过去15分钟内却有很大负载。
3、如果1分钟的值远大于15分钟的值,说明近1分钟负载在增加,这种情况可能是临时性的,也可能还会持续,要持续观察,一旦1分钟的平均负载超过了CPU的数量,意味着系统正在发生过载的问题。
top命令

软链接和硬链接
linux系统中,任何一个独立(注意:这里强调是独立的文件)的文件,都会为其分配一个i结点,它们是对应的,然后通过i结点再找到相应的文件的实际存储内容。
touch block.txt #建立一个源文件block.txt
ln block.txt block_hd #建立硬链接
ln block.txt block_hd2 #建立硬链接
ln -s block.txt block_soft #建立软链接

软链接则是重新建立了一个独立的文件。
硬链接的本质就是一条文件名和i结点的关联记录而已。
权限管理

-
chmod :修改当前用户对文件的权限
-
- r=4,w=2,x=1,所以想要rxw 读写和可执行权限,那就是
4+2+1=7,而一个位数表示一个角色,chmod a=rwx txt1.txt就可以理解为就是chmod 777 txt1.txt - u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是
- + 表示增加权限、- 表示取消权限、= 表示唯一设定权限
- r 表示可读取,w 表示可写入,x 表示可执行
- 场景:chmod这个命令实用比较广泛,但是说白了就是一点更改文件权限,但是权限这个东西怎么加,是加所有用户还是其他?是加读写还是去除读写?这个就需要理解 u、g、o、a、+、-、=、r、w、x等含义
- 扩展:
chmod ugo+r txt1.txt或者chmod a+r txt1.txt设置txt1.txt 对所有的用户角色可读 - 扩展:
chmod 777 file,chmod也可以用数字来代表权限问题
因为文件的权限分为3种用户,分别为
u(文件所有者)、g(文件的组用户)、o(其他用户),所以777表示u、g、o都是777的权限chmod 777 test.txt:表示将test.txt文件的读、写、执行权限赋权给所有的用户。 - r=4,w=2,x=1,所以想要rxw 读写和可执行权限,那就是
chmod:改变文件或者文件夹权限
ls -lh # 显示权限
chmod ugo+rwx file1 # 设置目录所有人,所属组,其他人以读,写,执行权限
chmod go-rwx file2 # 删除群组和其他人对目录读写权限
chown:改变文件所有者
用来变更文件或目录的拥有者或所属群组
chown -R mysql:mysql 目录
-- mysql:用户,mysql:用户组
chown -R user1 dir1 # 改变一个目录的所有人属性并且同时改变目录下所有文件
chown user1 file # 改变一个文件的所有人属性
线上排查命令
高负载,CPU过高解决
通过jdk,linux相关命令解决
1、top命令查看进程和cpu使用情况
top
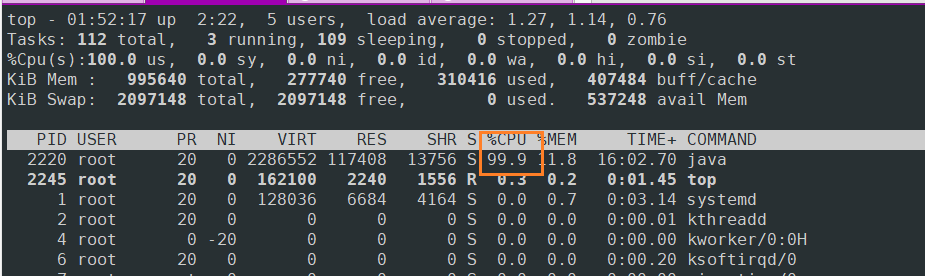
2、判断是否是GC导致CPU负载过高,主要看GC频率和内存使用情况
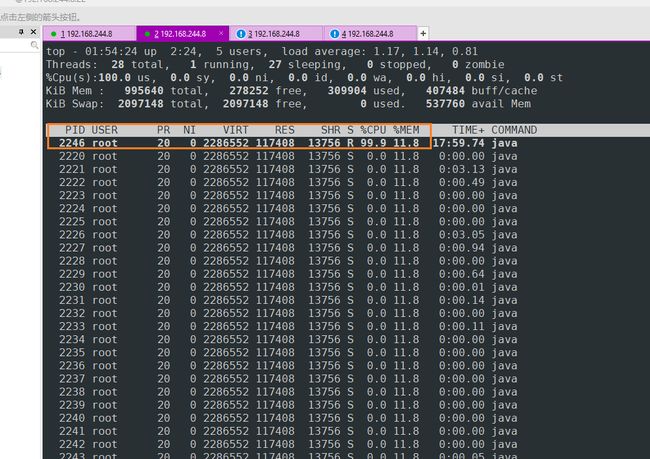
3、如果不是GC问题,查看负载最高的进程情况
top -Hp 进程ID
top -Hp 2220
4、确定线程之后,计算线程ID的十六进制值
printf "%x\n" 2246
[root@localhost ~]# printf “%x\n” 2246
8c6
5、下载堆栈信息,或者直接查询
jstack 2246 > show.txt
jstack 2246 | grep 8c6
6、对堆栈信息查询线程ID的十六进制,定位java代码,类,方法,行数
grep 8c6 a.dump -A 30
# 查询a.dump文件 当前行往后30行数据

7、找到业务代码修改
package com.geekmice.oomdemo.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
@RestController
public class OOMController {
public static Executor executor = Executors.newFixedThreadPool(5);
public static Object lock = new Object();
static class Task implements Runnable {
@Override
public void run() {
synchronized (lock) {
cal();
}
}
public void cal() {
int i = 0;
while (true) {
i++;
}
}
}
@RequestMapping("test")
public String test() {
Task task1 = new Task();
Task task2 = new Task();
executor.execute(task1);
executor.execute(task2);
return "test";
}
@RequestMapping("success")
public String success() {
return "success";
}
}
8、可能出现问题(Unable to open socket file: target process not responding or HotSpot VM not loaded)
经过检查发现jstack后面的进程不是在root用户执行的,jstack需要使用与进程一致的用户才能执行
jstack需要使用与进程一致的用户才能执行
总结
1.使用top命令定义异常进程,可以看见进程的CPU占用率特别高
top
2.使用top命令查看异常线程
top -Hp pid
3.转换线程为16进制
printf “%x\n” tid
4.使用命令jstack定位异常代码位置
jstack pid | grep 十六机制异常线程号 -A90 # 最后的-A90表示异常代码的之后90行记录
通过athas开源线上监控诊断产品排查
1、频繁收到准生产环境应用CPU告警邮件
2、通过jps命令查询Linux系统当前所有java进程pid的命令
[root@localhost ~]# jps
2359 Jps
2169 jar
2、打开容器,进入arths,开始查找有问题的线程
java -jar arthas-boot.jar 2169
3、使用arthas找到CPU占用最高线程
thread -n 3 # 列举出当前系统三个占用CPU最高的线程,根据展示情况可以定位代码行数
也可以是使用dashboard
dashboard # 可以看到占用CPU比较高的线程都是26

然后继续排查,通过命令thread 26 查看详细代码情况

问题:jvm疯狂Gc导致cpu升高
场景
之前遇到一个线上问题,服务器特别卡,然后进入容器登录服务器,使用top命令,看到有个进程cpu一直飙升,尝试重启对应模块的服务,还是时不时出现这个问题,之后猜测是不是某个定时任务引发大量计算或者某个请求导致死循环,然后对本次上线代码可能出现的地方,进行分析一番,并没有问题;添加部分日志,问题复现时候,也没有大量日志打印,暂时排除死循环;
开始考虑jvm问题,是不是jvm疯狂gc导致服务器压力大而飙升的,通过jstat命令查询每秒gc情况,发现s0频繁创建对象,疯狂gc,然后看了看堆栈信息发现有个文件,出现很多次,找到文件对应同事,进行沟通一番,发现这是他自定义的工具类,用来发送请求,但是请求的超时时间没有设置,这样一来,如果被请求的接口不响应或者响应时间很慢,这个请求一直等待,或者一直发送请求,触发了jvm疯狂gc把服务器飙到了极限,之后服务器响应就很慢了
最终解决:超时时间设置5s,服务器正常响应
jstat -gcutil PID 1000
# 每隔1s执行一次

问题:jvm相关oom问题
之前遇到一个线上问题,中午午休时间,我们商业服务收到告警,服务进程占用容器的物理内存(16G)超过了80%的阈值,并且还在不断上升。
监控系统调出图表查看,通过jstat命令看到,老年代90%,fgc非常多,老年代存在大量无法被回收的对象,老年代撑满,导致内存溢出
1 首先是监控,我们项目在部署后,会对JVM内存进行监控,CAT能监控JVM内存,一旦内存用量超过80%,且持续时间超过5分钟,我们就会收到告警邮件。
这里额外说下,为了确保项目的高可用,一般代码是会被部署到多个linux服务器上,比如把spring boot项目打成jar包,再通过jenkins,或干脆手动复制,部署到多个linux服务器上。每台部署项目的服务器,都会部署这套监控系统。
2 其次,收到告警邮件后,我们会看该服务器的dump文件,其中能看到当时的内存对象,同时会看业务日志,看当时是什么业务导致了内存用量大增。
这里大家可以去看下dump文件的结构,同时可以操作下通过arthas工具导出dump文件,visualvm分析堆栈信息,内存情况
3 可以说,在导入客户数据的过程中,我们是会从多个文件里读取数据再导入,在导入后,没有关闭IO对象,所以导致内存用量大增。
同样能导致内存用量大增的原因还有,用好HashMap等没有不关掉,或者是缓存Redis数据时没设置超时时间,这就导致缓存对象一直占内存。如果大家要说其它原因,最好也得结合业务说。
4 通过visualvm分析 导入dump文件之后,基本信息会显示异常错误OOM,找到对相应线程
5 查看类信息,可以看到实例一直在增加,大概5秒钟增加到30万,找到问题了,然后就来看专门堆转储上的线程,可以找到问题所在
6 然后截图给负责该业务的同事,finally处理一下流
heapdump /tmp/dump-1.hprof
# 等价于 jmap -dump
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSInitiatingOccupancyFraction=80
-XX:MaxDirectMemorySize=2g
-XX:+UnlockDiagnosticVMOptions
jvm启动参数说明
-Xmx:指定最大堆内存。 如 -Xmx4g。这只是限制了 Heap 部分的最大值为 4g。这个内存不包括栈内存,也不包括堆外使用的内存。
-Xms:指定堆内存空间的初始大小。 如 -Xms4g。 而且指定的内存大小,并 不是操作系统实际分配的初始值,而是GC先规划好,用到才分配。 专用服务 器上需要保持 –Xms 和 –Xmx 一致,否则应用刚启动可能就有好几个 FullGC。 当两者配置不一致时,堆内存扩容可能会导致性能抖动。
-Xss:设置每个线程栈的字节数,影响栈的深度-Xmn2g:指定新生代内存大小
-XX:+UseConcMarkSweepGC 使用cms垃圾回收器
-XX:+UseParNewGC 使用并行垃圾回收器
问题:记一次FullGC的排查经历–从日志到业务代码
问题场景:服务是一个使用类似dubbo的RPC框架以及若干Spring全家桶组合起来的微服务架构,Java服务使用的是CMS的垃圾回收器,然收到一台实例(即一个Java应用)产生FullGC日志的报警,老年代内存已经不足而触发了FullGC,并且由于应用虽然STW,但是请求确还是在堆积,导致一直在持续FullGC,没有自愈
然后逻辑上考虑出现fullgc场景,有人主动调用了System.gc(),基本上不会有人来调用这个方法,就算是有人调用了,我们服务启动时候开启了一个参数,这个参数可以将System.gc()转为CMS的并发gc,所以并不会触发FullGC.
老年代空间不足:对象出生于新生代,在挺过了一次次minorGC之后成功熬到了老年代,并且持续在老年代混吃等死,一直到大量的对象都这样在老年代混吃等死把老年代占满之后就会触发FullGC
元空间不足:代码中大量使用动态代理,生成了一大堆的代理类占用了方法区,如果是这个原因引起必然是所有服务都会报FullGC问题,然而其它机器的老年代内存很稳定,所以排查
为什么只有一个实例异常
只有单个服务出现了这样的问题,很有可能不是外部依赖的超时或者方法区空间不足造成,而是因为某个刚好落在这个服务上的超大请求占用了大量的内存并且耗时久,一直赖在老年代不走导致。
gc日志情况
第一次FullGC发生在2020-07-25 14:51:58,观察之前的日志可以发现历史上CMS并发回收一般都会将堆内存稳定在3608329K->1344447K,从3.6G左右回收到1.3G左右,但是从某个时间点开始开始回收效率变差了。
可以看到,这次回收从5G回收到3.5G,回收完之后还有这么多被占用!这个时间点2020-07-25 14:51:50左右一定发生了什么事情,导致老年代一直保留着一批老赖。
确定问题溯源
定位好时间段之后,接下来找到这个时间段附件的离谱的大请求,由于项目中通过aop全局配置处理日志情况,可以知道每个请求详细信息,通过日志找到一个一个请求,其中请求参数特别长,本来是修改了1000个文件夹的某个属性,但是业务逻辑是如果修改的是某个特殊属性时,会级联修改这些文件夹下的全部文件,实际上修改了1000个文件夹的请求,背后处理了1000个文件夹+几十万w个文件,而修改这些属性由于我们使用的框架的限制,100w个文件在修改前会查主属性表+所有辅属性表(内存根据主键id join),请求耗时90s。导致大量对象 长时间滞留在堆内存中挺过了一波波的minorGC和CMS GC干满老年代,最终触发了这个问题
优化思路
- 限制此类字段的修改,对于这样需要级联修改的情况时进行校验,不允许API用户传太多文件夹(1000个 --> 100个)
- 微服务的思想,在该服务上层再做一个分发服务,对于这样级联修改的请求将1000个的修改拆成10个每次修改100个的请求去并发请求下面的机器,均摊压力
- 异步化队列,修改文件夹本身属性后即立刻返回,后续级联修改的请求拆成n个放入队列,由其它服务订阅到请求后执行
- 能有监控手段在应用FullGC时从注册中心踢掉,待FullGC自愈后再加入,而不是人工干预重启
- 优化ORM框架,就算修改100w个文件的某个属性,也不需要查询出这些文件的全部属性,只查询出主表+需要修改的属性所在的表即可
命令练习之后注意删除无用文件
1.grep与正则的搭配使用
2.grep命令学习
3.vim命令每日学习
4.你了解Vim的增删改查吗 ?
5.vi工作模式(3种)以及模式切换(转换)
6.chmod到底是什么
7.线上高CPU问题解决