【Mycat 2】详解分库分表设计方案及实操测试(一)
文章目录
- 1. 数据库架构
-
- 1.1 Mycat 配置
- 1.2 MySQL 实例配置
- 2.分库不分表
-
- 2.1 数据分片映射关系
- 2.2 测试用例
- 2.3 测试过程
-
- 2.3.1 用例1
- 2.3.1 用例2
- 2.3.1 用例3
- 2.3.1 用例4
- 2.3.1 用例5
1. 数据库架构
1.1 Mycat 配置
- Mycat 服务实例使用默认 Mycat 端口
8066。 - 逻辑方案, 名称采用
sharding,对应各存储节点上同名的物理方案。 - 分片算法统一采用
MOD_HASH()。
注释
Schema,即方案或模式,在 MySQL 中等同于数据库。
| 集群 | 数据源 | 连接串 |
|---|---|---|
| cls0 | part0 | jdbc:mysql://source:3308/sharding |
| cls0 | part0_ | jdbc:mysql://replica1:3308/sharding |
| cls1 | part1 | jdbc:mysql://replica2:3308/sharding |
连接 Mycat ,使用 Mycat 注释功能创建 sharding 逻辑方案。
/*+ mycat:createSchema{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"sharding",
"shardingTables":{},
"targetName":"cls02"
} */;
重要
因在 Mycat 2 中使用CREATE TABLE建表时默认使用的是以c+数字(c0起始)为名的集群,故如果集群或数据源名称不是以此种方式命名时,使用该方法建表会报错。因而笔者在本文所有测试均采用注释的方式建表,也可以采用直接编辑配置文件的方式,特此说明。

1.2 MySQL 实例配置
| 主机名 | 端口 | 实例名 | 架构 | 角色 |
|---|---|---|---|---|
| source | 3308 | rep01Src | 主从 | 主 |
| replica1 | 3308 | rep01Rep01 | 主从 | 从 |
| replica2 | 3308 | part2 | 单节点 | 单节点 |
2.分库不分表
2.1 数据分片映射关系
| 逻辑表 | 分片 ID | 分片键 | 物理实例(存储节点) | 物理库 | 物理表 | 描述 |
|---|---|---|---|---|---|---|
| db_not_tb | 1 | id | rep01Src | sharding | db_not_tb | id 双数 |
| db_not_tb | 2 | id | part2 | sharding | db_not_tb | id 单数 |
| db_not_tb__city | 1 | city | rep01Src | sharding | db_not_tb__city | city 散列化后双数 |
| db_not_tb__city | 2 | city | part2 | sharding | db_not_tb__city | city 散列化单数 |
2.2 测试用例
| 测试用例 | 用例描述 | 序列类型 | 序列名 | 是否必须配置序列 | 逻辑表 | 分片键 | 物理实例(存储节点) | 物理表 |
|---|---|---|---|---|---|---|---|---|
| 1 | 序列采用默认雪花算法,表名含“_”,分片键为 id | 雪花 | sharding_db_not_tb | 否 | db_not_tb | id | rep01Src | db_not_tb |
| 2 | 序列采用默认雪花算法,表名不含“_”,分片键为 id | 雪花 | sharding_dbnottb | 否 | dbnottb | id | rep01Src | donottb |
| 3 | 序列采用由 MySQL 生成方式,表名含“_”,分片键为 id | MySQL | sharding_db_not_tb_m | 是 | db_not_tb_m | id | rep01Src | db_not_tb_m |
| 4 | 序列采用由 MySQL 生成方式,表名不含“_”,分片键为 id | MySQL | sharding_dbnottbm | 是 | dbnottbm | id | rep01Src | dbnottbm |
| 5 | 序列采用默认雪花算法,表名含“_”,分片键为 city | 雪花 | sharding_db_not_tb__city | 是 | db_not_tb__city | city | rep01Src | db_not_tb__city |
2.3 测试过程
2.3.1 用例1
测试时实际并没有手动创建sharding_db_not_tb 序列,而是使用 Mycat 的默认行为。
# drop old table, and delete old data record
drop table if exists db_not_tb;
delete from mycat_sequence where name = 'sharding_db_not_tb';
# create table
/*+ mycat:createTable{
"schemaName":"sharding",
"shardingTable":{
"createTableSQL":"create table db_not_tb(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10)) dbpartition by MOD_HASH(id) dbpartitions 2",
"function":{
"properties":{
"dbNum":2,
"dbMethod":"mod_hash(id)",
"mappingFormat":"cls${targetIndex}/sharding/db_not_tb",
"storeNum":2
}
}
},
"tableName":"db_not_tb"
} */;
# insert relative sequence record into `mycat_sequence`
insert into mycat_sequence values('sharding_db_not_tb',0,1);
# insert data
insert into db_not_tb(name,city) values('a','sh'),('b','sh'),('c','bj'),('d','sh'),('e','sz'),('f','bj'),('g','bj'),('h','sz');
# check data
select * from db_not_tb t order by id;
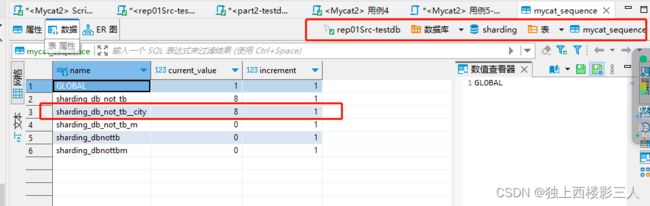
测试结果表明所有数据按 id 分片键进行了分库,且相应的全局序列值变化符合预期,但并未自动创建相应的 sequence.json Mycat 序列配置文件。截图如下:
Mycat 逻辑库
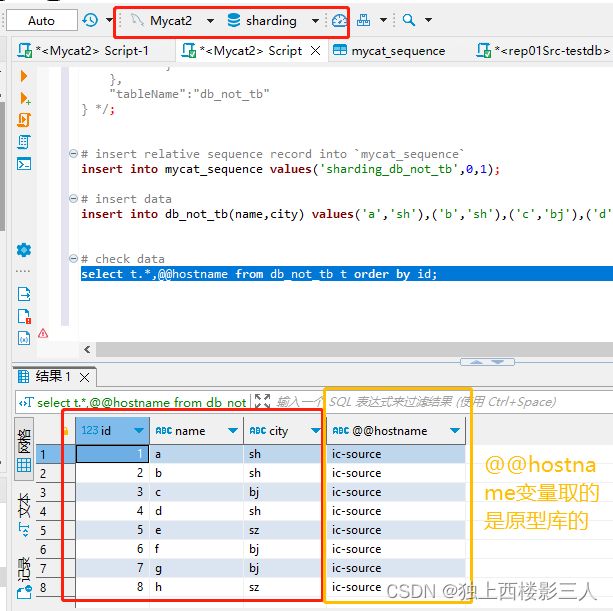
cls0 对应的物理库
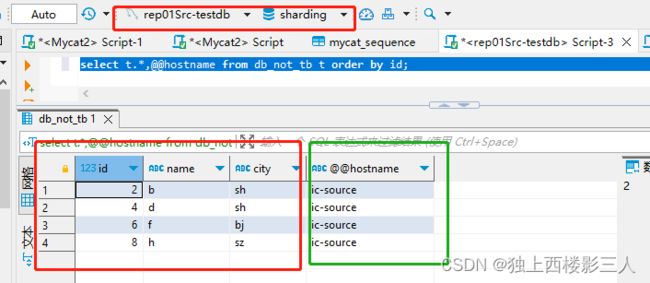
cls1 对应的物理库

mycat_sequence 表中对应的序列值变化
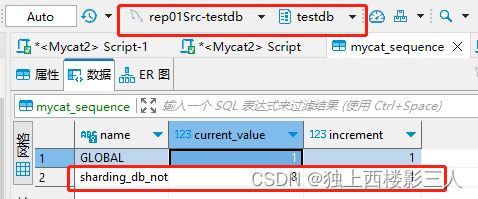
注意
一定要手动向mycat_sequence表插入相应的序列记录。否则,所有数据都会插入到原型库所在的主机的同一个物理库,并未进行分库。
2.3.1 用例2
因笔者最开始测试用例1时,没理解 Mycat 官网 的描述,未“手动向 mycat_sequence 表插入相应的序列记录”,加上文章底下的评论,导致误以为表名含“_”对全局序列、分库分表有影响。所以设计了如上的测试用例。这官网文档实在是做的不好,中间穿插没用的代码块,没用不说,还误导读者。
后测试纠正的用例1后,足以证明表名含“_”对全局序列、分库分表无影响。故无需进行本用例的测试,但为了证据充分,笔者还是做了,测试代码即结果如下,其他不予详述:
# drop old table, and delete old data record
drop table if exists dbnottb;
delete from mycat_sequence where name = 'sharding_dbnottb';
# create table
/*+ mycat:createTable{
"schemaName":"sharding",
"shardingTable":{
"createTableSQL":"create table dbnottb(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10)) dbpartition by MOD_HASH(id) dbpartitions 2",
"function":{
"properties":{
"dbNum":2,
"dbMethod":"mod_hash(id)",
"mappingFormat":"cls${targetIndex}/sharding/dbnottb",
"storeNum":2
}
}
},
"tableName":"dbnottb"
} */;
# insert relative sequence record into `mycat_sequence`
insert into mycat_sequence values('sharding_dbnottb',0,1);
# insert data
insert into dbnottb(name,city) values('a','sh'),('b','sh'),('c','bj'),('d','sh'),('e','sz'),('f','bj'),('g','bj'),('h','sz');
# check data
select t.*,@@hostname from dbnottb t order by id;
太漂亮了,本以为不会出问题的,结果居然报错了(SQL 错误 [1264] [22001]: Data truncation: Data truncation: Out of range value for column 'id' at row 1
)!
难道使用一个普通表名反倒成了问题?难道是无法识别区分出库名和表名?那要原型库、元数据是干啥的?!
Mycat 逻辑库

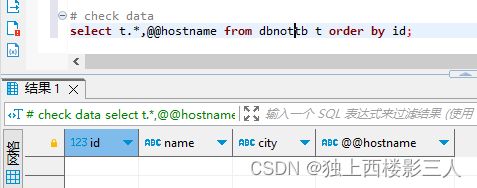
全局序列值无变化。
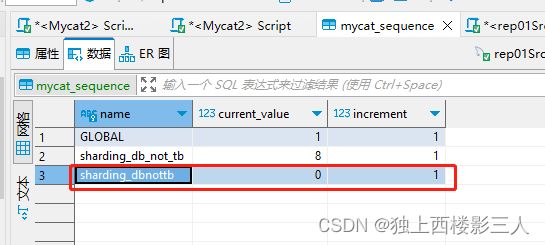
而直接调用操作序列的函数时,序列是可以按预期变化的。
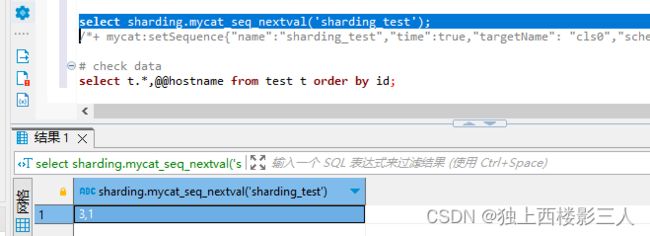
2.3.1 用例3
需要分别在各分片(我的是两个)的物理库中建表,设置 auto_increment_offset和auto_increment_increment 会话变量,然后插入数据。
# drop old table, and delete old data record
drop table if exists db_not_tb_m;
delete from mycat_sequence where name = 'sharding_db_not_tb_m';
# create sequence.json
# 其实没必要,使用 MySQL 生成序列时,感觉 Mycat 不会创建、维护全局序列,需要数据库设计者自行设计。
insert into mycat_sequence values('sharding_dbnottbm',0,1);
/*+ mycat:setSequence{"name":"sharding_db_not_tb_m","clazz":"io.mycat.plug.sequence.SequenceMySQLGenerator"} */;
# create table and insert data
## execute separately at physical MySQL dbs
### db1
set @@auto_increment_offset=1, @@auto_increment_increment=2;
SHOW VARIABLES LIKE 'auto_inc%';
create table db_not_tb_m(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10));
insert into db_not_tb_m(name,city) values('a','sh'),('b','sh'),('c','bj'),('d','sh');
select t.*,@@hostname from db_not_tb_m t order by id;
### db2
set @@auto_increment_offset=2, @@auto_increment_increment=2;
SHOW VARIABLES LIKE 'auto_inc%';
create table db_not_tb_m(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10));
insert into db_not_tb_m(name,city) values('e','sz'),('f','bj'),('g','bj'),('h','sz');
select t.*,@@hostname from db_not_tb_m t order by id;
## create table and check table data at mycat
/*+ mycat:createTable{
"schemaName":"sharding",
"shardingTable":{
"createTableSQL":"create table db_not_tb_m(id int primary key,name varchar(10),city varchar(10)) dbpartition by MOD_HASH(id) dbpartitions 2",
"function":{
"properties":{
"dbNum":2,
"dbMethod":"mod_hash(id)",
"mappingFormat":"cls${targetIndex}/sharding/db_not_tb_m",
"storeNum":2
}
}
},
"tableName":"db_not_tb_m"
} */;
select t.*,@@hostname from db_not_tb_m t order by id;
Mycat 逻辑库
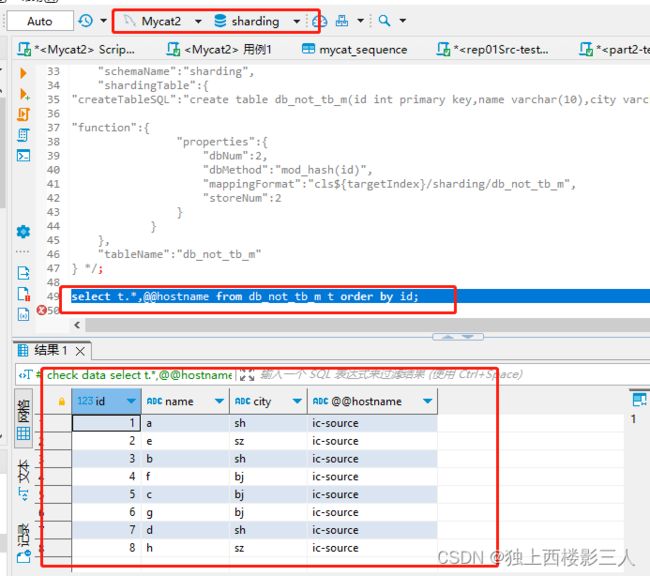
cls0 对应的物理库
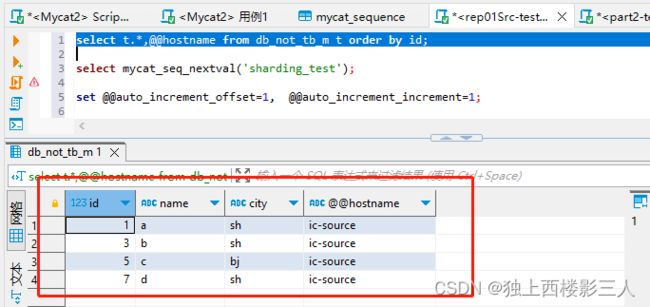
cls1 对应的物理库
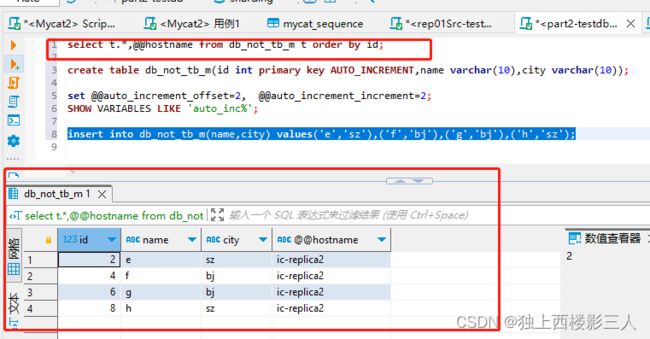
Mycat 在用例3场景下我理解什么也没做,定义就是交由 MySQL 自增功能处理,因而不管你是否通过注释创建序列配置文件,是否向 Mycat 全局序列表 mycat_sequence 插入相应的序列数据,用户插入数据时需要直连 MySQL 物理库,而不是通过 Mycat 逻辑库。Mycat 此时只用于查询汇总数据。
这很好理解,Mycat 全局序列表的目的就是只负责管理、维护 Mycat 生成的序列,而此用例场景下是 MySQL 生成的序列,因而维护 Mycat 中该序列的信息没有任何意义!
2.3.1 用例4
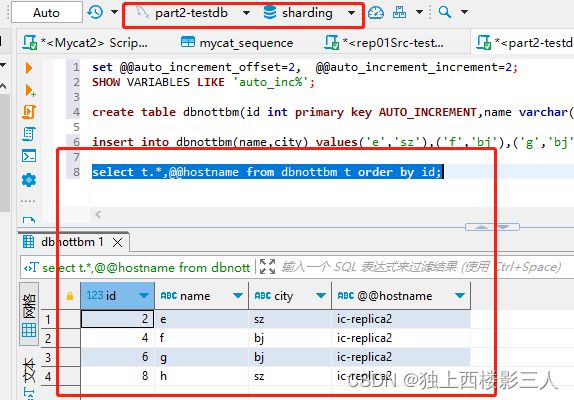
因为不涉及在 Mycat 逻辑库中执行 INSERT 操作,所以结果与用例3类似,此处不加赘述,只展示结果。
# drop old table, and delete old data record
drop table if exists dbnottbm;
delete from mycat_sequence where name = 'sharding_dbnottbm';
# create sequence.json
# 其实没必要,使用 MySQL 生成序列时,感觉 Mycat 不会创建、维护全局序列,需要数据库设计者自行设计。
insert into mycat_sequence values('sharding_dbnottbm',0,1);
/*+ mycat:setSequence{"name":"sharding_dbnottbm","clazz":"io.mycat.plug.sequence.SequenceMySQLGenerator"} */;
# create table and insert data
## execute separately at physical MySQL dbs
### db1
set @@auto_increment_offset=1, @@auto_increment_increment=2;
SHOW VARIABLES LIKE 'auto_inc%';
create table dbnottbm(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10));
insert into dbnottbm(name,city) values('a','sh'),('b','sh'),('c','bj'),('d','sh');
select t.*,@@hostname from dbnottbm t order by id;
### db2
set @@auto_increment_offset=2, @@auto_increment_increment=2;
SHOW VARIABLES LIKE 'auto_inc%';
create table dbnottbm(id int primary key AUTO_INCREMENT,name varchar(10),city varchar(10));
insert into dbnottbm(name,city) values('e','sz'),('f','bj'),('g','bj'),('h','sz');
select t.*,@@hostname from dbnottbm t order by id;
## create table and check table data at mycat
/*+ mycat:createTable{
"schemaName":"sharding",
"shardingTable":{
"createTableSQL":"create table dbnottbm(id int primary key,name varchar(10),city varchar(10)) dbpartition by MOD_HASH(id) dbpartitions 2",
"function":{
"properties":{
"dbNum":2,
"dbMethod":"mod_hash(id)",
"mappingFormat":"cls${targetIndex}/sharding/dbnottbm",
"storeNum":2
}
}
},
"tableName":"dbnottbm"
} */;
select t.*,@@hostname from dbnottbm t order by id;
Mycat 逻辑库

cls0 对应的物理库
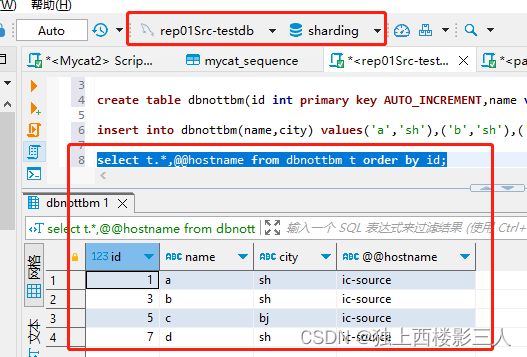
cls1 对应的物理库
序列相关

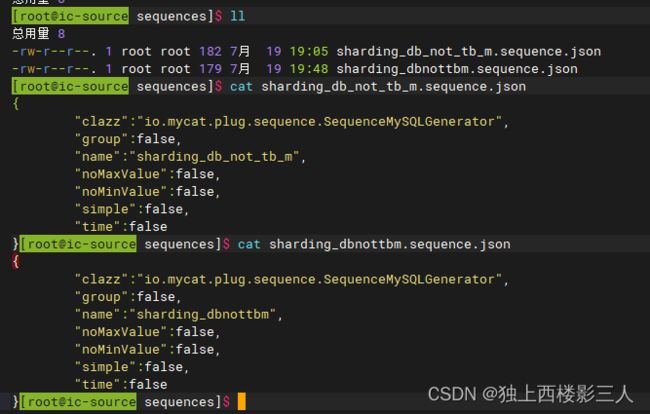
2.3.1 用例5
与用例1大致相同,只是分片键是 city 而非 id 。按 Mycat 的说明,MOD_HASH 算法是先将字符型的 city 字段散列化为固定长度的数值型后,再进行取模运算分库。
# drop old table, and delete old data record
drop table if exists db_not_tb__city;
delete from mycat_sequence where name = 'sharding_db_not_tb__city';
# create sequence.json
# 故意创建一个矛盾的由 MySQL 生辰的序列
# 其实没必要,使用 MySQL 生成序列时,感觉 Mycat 不会创建、维护全局序列,需要数据库设计者自行设计。
insert into mycat_sequence values('sharding_db_not_tb__city',0,1);
/*+ mycat:setSequence{"name":"sharding_db_not_tb__city","clazz":"io.mycat.plug.sequence.SequenceMySQLGenerator"} */;
# create table and insert data
/*+ mycat:createTable{
"schemaName":"sharding",
"shardingTable":{
"createTableSQL":"create table db_not_tb__city(id int auto_increment primary key,name varchar(10),city varchar(10)) dbpartition by MOD_HASH(city) dbpartitions 2",
"function":{
"properties":{
"dbNum":2,
"dbMethod":"mod_hash(city)",
"mappingFormat":"cls${targetIndex}/sharding/db_not_tb__city",
"storeNum":2
}
}
},
"tableName":"db_not_tb__city"
} */;
insert into db_not_tb__city(name,city) values('a','sh'),('b','sh'),('c','bj'),('d','sh'),('e','sz'),('f','bj'),('g','bj'),('h','sz');
# check data
select t.*,@@hostname from db_not_tb__city t order by id;
用例5证明了两点:
- 可以使用字符型字段分库,产生预期的分库结果;
- Mycat 2 的序列功能起决定性作用的是
AUTO_INCREMENT和mycat_sequence中序列对应的记录。即便用例5中手动创建序列时设置为由 MySQL 生成,但 Mycat 最终依旧选用了默认的雪花算法。
Mycat 逻辑库
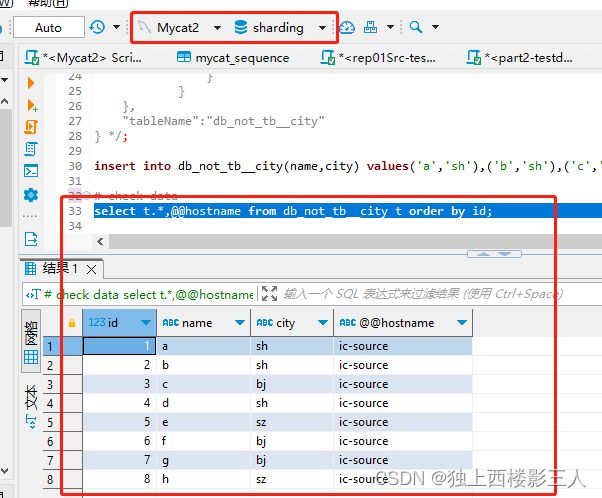
cls0 对应的物理库
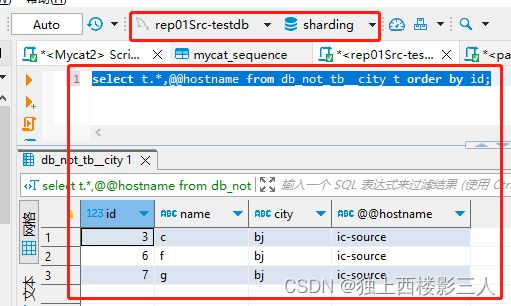
cls1 对应的物理库
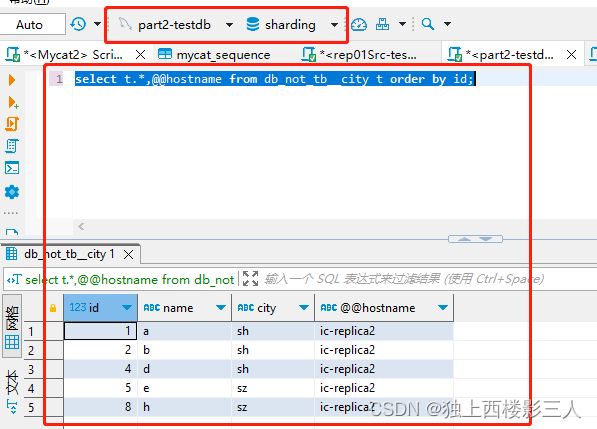
序列相关