作者: 有猫万事足 原文来源: https://tidb.net/blog/15d0fbf6
新的问题
之前弄好了TiDB集群,也弄好了dm集群,把写入流量整个切入了TiDB集群运行起来了。但是有个别比较大的日志表,OLAP查询的表现还是不太行。正好7.1版本发布了,我看到tiflash支持存算分离且可以把数据放在s3上——没错,这是我当时最关注的特性。
然而和老板沟通了一下,没有得到预算上的支持,上列存的计划泡汤。
在老板看来,已经在一个可以接受的成本下得到了超过预期的成果。某些OLAP查询时间是1分钟还是10s,对他来说都是可以接受的。
然而这对我来说就是一个严重的问题。
metabase对时间戳的处理
在metabase中,给mysql的查询的时间限制是1分钟,如果一个mysql查询1分钟没有结果。metabase就会直接断掉查询,没有任何数据。
也就是说任何一个查询超过1分钟,都可能导致我回到之前的工作流程。需要我定时的把查询的结果放到另一个表里。这是我极力避免的。
我的目标还是不割裂查询结果和原始记录之间的联系。以便对数据有疑问的时候,可以通过去掉聚合维度,快速定位到最细粒度的原始记录。
没有办法,没有列存的支持,那就只能具体问题具体分析。来看看这类查询为啥会慢。
查下来的结果,发现基本都和时间戳有关。
mysql中时间戳运用的是如此广泛,基本上只要用到时间的地方都是时间戳而不是datetime。
当我在metabase中,把timestamp字段映射到datetime之后。

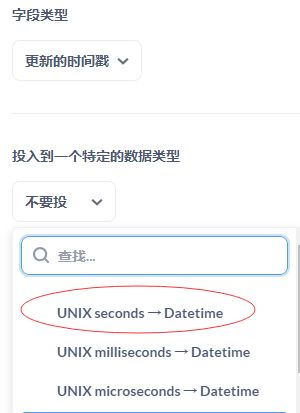
matebase生成的查询的sql是类似下面这样的:
SELECT FROM_UNIXTIME(`Log`.`Time`) AS `Time`
...
WHERE (FROM_UNIXTIME(`Log`.`Time`) >= DATE(NOW(6)))
AND (FROM_UNIXTIME(`Log`.`Time`) < DATE(DATE_ADD(NOW(6), INTERVAL 1 day)))
可以看到metabase对时间戳的处理,都是直接用FROM_UNIXTIME把时间戳转成datetime。这当然会导致原来在时间戳上建立的索引失效。这就是查询慢的根源。
对症下药,首先想到的是,需要一个表达式索引。
从表达式索引到存储生成列
本来我打算建立一个表达式索引,这个问题就算解决了。不料在文档的末尾看到这么一段。
https://docs.pingcap.com/zh/tidb/stable/sql-statement-create-index#%E8%A1%A8%E8%BE%BE%E5%BC%8F%E7%B4%A2%E5%BC%95
表达式索引的语法和限制与 MySQL 相同,是通过将索引建立在隐藏的虚拟生成列 (generated virtual column) 上来实现的。因此所支持的表达式继承了虚拟生成列的所有限制。
我才第一次开始关注7.1的新特性——生成列。
https://docs.pingcap.com/zh/tidb/stable/generated-columns#%E7%94%9F%E6%88%90%E5%88%97
固然文档通篇说的都是json,FROM_UNIXTIME也不在推荐使用的表达式的范围内。
但是在反复思考下,我觉得用存储生成列来解决时间戳到datetime的转换会更好。我需要这个特性。至于实验特性有没有什么问题,那也得先用用看才知道。
datetime用来展示还是作为维度聚合都是不可或缺的。如果有一列可以物化这个时间戳的转换结果,应该对整体的性能有很大的提升。无论是对业务人员还是metabase,时间戳的使用都不够友好。有了一列是datetime并和时间戳转换的结果保持一致,那我就再也用不到时间戳了。
有风险的地方是和dm工具的配合:下游的表加了存储生成列,是否会让dm认为下游的表和上游的表结构是不一致的,从而无法进行同步任务。
思考下来概率不大,但文档没有确认这一点,还得试试。另就是存储生成列,不能直接alter table添加,改造表结构需要重新导入数据。
那就开始吧。
设置allow-expression-index=true
首先我要用到的函数不在tidb_allow_function_for_expression_index变量的范围内。所以我需要设置tidb的变量allow-expression-index = true
tiup cluster edit-config
添加如下配置:
server_configs:
tidb:
experimental.allow-expression-index: true
之后重启所有角色为tidb的节点:
tiup cluster reload -R tidb
建立新表
CREATE TABLE `Log` (
...
`dt_time` datetime GENERATED ALWAYS AS ((from_unixtime(`Time`))) STORED, -- 创建存储生成列dt_time值是from_unixtime(`Time`)
PRIMARY KEY (`Id`) /*T![clustered_index] NONCLUSTERED */,
...
KEY `dt_Time` (`dt_Time`) -- 最后别忘了还要给这个存储生成列添加索引
) ENGINE=InnoDB /*T! SHARD_ROW_ID_BITS=5 PRE_SPLIT_REGIONS=5 */ -- 为了防止写入热点的参数不能忘。
为了验证存储生成列是否会导致dm同步失败,这里不采用 insert into t_new select * from t 的方式回填数据。
用dm重新导入数据
dm篇的时候,我提到过,凡是这种大数据量的日志表都推荐一个task一个表。
所以需要重新导入也很简单,至少要停掉这个表的同步任务再提交一次任务就可以了。
tiup dmctl stop-task
注意,要从头做全量导入,用tiup dmctl stop-task删掉了任务,还需要把dm_meta库下,对应的4张表删掉。但是如果你用dm openapi里面的删除同步任务接口来做,就不需要这一步。
https://docs.pingcap.com/zh/tidb/stable/dm-open-api#%E5%88%A0%E9%99%A4%E5%90%8C%E6%AD%A5%E4%BB%BB%E5%8A%A1
这也是之前写过的,dm openapi的行为和tiup dmctl并不是完全一致的。使用过程中需要留意。
重新开始提交任务start-task没有报错就知道应该是稳了,只要dm不认为上下游两个表是异构的,提交任务的时候就通过了检查,那就之后的导入就不太可能会有问题。
结果对比
以同样对比某种游戏内资源各个服务器当日获取和消耗统计为例
metabase使用时间戳字段
-- Metabase:: userID: 1 queryType: MBQL queryHash: e9ba9dd52355d3bef6b3ab4c9303dca1ff7ef2c9b368f7f5a83d1e457272acf8
SELECT
LogAll.server_name AS server_name,
Log_type.isGet AS Log_type__isGet,
SUM( LogAll.Cash ) AS sum
FROM
LogAll
LEFT JOIN Log_type AS Log_type ON LogAll.Type = Log_type.Id
WHERE
(
FROM_UNIXTIME( LogAll.Time ) >= DATE (
NOW( 6 )))
AND (
FROM_UNIXTIME( LogAll.Time ) < DATE (
DATE_ADD( NOW( 6 ), INTERVAL 1 DAY )))
GROUP BY
LogAll.server_name,
Log_type.isGet
ORDER BY
LogAll.server_name ASC,
Log_type.isGet ASC;
基本就是从日志表中获取这个行为的类型,再和类型的字典表做关联,确定这种行为是消耗还是获取资源,然后把数据分别累加。
因为这个LogAll是个视图,union all了一堆日志表。执行计划完整的非常长,只列一部分:

就每一个被union all的日志表来说,索引失效了,所以只查一天,也需要全表扫描。

整体看我只统计一天,需要在2.4亿的数据量里面扫描一遍。
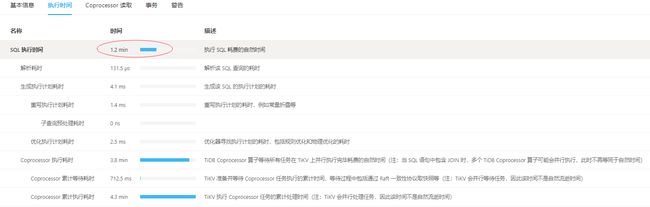
从某种程度上说,TiDB能在1.2分钟的时间内,硬扫2.4亿数据,并返回结果也挺强大。
metabase使用类型为datetime的生成列
改用了datetime的生成列,同样统计一天,已经进不了慢查询了。我给了它更高的挑战,统计上一个月到现在的数据。
-- Metabase:: userID: 1 queryType: MBQL queryHash: c9c9c4d282ef43ff8dc1470351a9abafa7c08ab09ab321ab5ab9fbd6e82408fd
SELECT
LogAll.server_name AS server_name,
Log_type.isGet AS Log_type__isGet,
SUM( LogAll.Cash ) AS sum
FROM
LogAll
LEFT JOIN Log_type AS Log_type ON LogAll.Type = Log_type.Id
WHERE
(
LogAll.dt_Time >= STR_TO_DATE( CONCAT( DATE_FORMAT( DATE_ADD( NOW( 6 ), INTERVAL - 1 MONTH ), '%Y-%m' ), '-01' ), '%Y-%m-%d' ))
AND (
LogAll.dt_Time < STR_TO_DATE( CONCAT( DATE_FORMAT( DATE_ADD( NOW( 6 ), INTERVAL 1 MONTH ), '%Y-%m' ), '-01' ), '%Y-%m-%d' ))
GROUP BY
LogAll.server_name,
Log_type.isGet
ORDER BY
LogAll.server_name ASC,
Log_type.isGet ASC;
和上一个查询相比,我们的时间范围来到了2个月。
![]()
在每个union all的日志表中,虽然不是全部,但大部分都用上索引。

统计一个多月,执行时间也就13s+。

扫描的记录量也大幅降低。
结论
存储生成列完美做到了:物化某一列的表达式计算结果,同时不影响dm导入。
再回到metabase,调整时间聚合的字段到添加的存储生成列上,原来这类查询执行速度从平均40s+降到了平均4-5s,提升巨大。