构建能够使用 CPU 运行的 MetaAI LLaMA2 中文大模型
本篇文章聊聊如何使用 GGML 机器学习张量库,构建让我们能够使用 CPU 来运行 Meta 新推出的 LLaMA2 大模型。
写在前面
GGML 是前几个月 llama.cpp 和 whisper.cpp 项目背后的关键支撑技术,使用 C 语言编写,没有任何三方依赖的高性能计算库。
这个开源项目集成了模型量化方案,能够自动针对不同的平台进行优化,目前支持几十种不同的大模型项目。
本文相关的内容,已经更新到了开源项目 soulteary/docker-llama2-chat 中,欢迎一键三连,支持项目继续更新。

相关的模型也已经上传到了 HuggingFace,感兴趣的同学自取吧。
当然,如果你还是喜欢在 GPU 环境下运行,可以参考这几天分享的关于 LLaMA2 模型相关的文章。
接下来,我们和以往一样,进行准备工作。
准备工作,以及重要的模型下载部分操作,可以参考《使用 Docker 快速上手中文版 LLaMA2 开源大模型》或《使用 Docker 快速上手官方版 LLaMA2 开源大模型》文章中的部分,完成准备工作和模型下载工作。
文章里所有的方法,我们都可以参考并在非 Docker 容器中使用。 如果你也想偷懒一些,只要你安装好 Docker 环境,配置好能够在 Docker 容器中调用显卡的基础环境,就可以进行下一步啦,如果你还不清楚如何操作,仔细阅读前两篇文章中的准备工作即可。
本文使用的 LLaMA2 中文模型,基于 LinkSoul 团队出品的LinkSoul/Chinese-Llama-2-7b,感谢他们为中文开源模型做出的贡献
获取 GGML 模型构建镜像环境
为了简单的转换 LLaMA2 官方镜像或中文镜像为 GGML 格式,我做了一个工具镜像,镜像不大,只有 93MB。
使用下面的命令,先下载能够转换模型为 GGML 格式的工具镜像:
docker pull soulteary/llama2:converter
接着,使用下面的命令,进入容器的交互式终端:
docker run --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/LinkSoul:/app/LinkSoul -v `pwd`/soulteary:/app/soulteary soulteary/llama2:converter bash
在交互式终端中,我们可以用下面的命令将中文模型转换为 GGML 格式:
python3 convert.py /app/LinkSoul/Chinese-Llama-2-7b/ --outfile /app/soulteary/Chinese-Llama-2-7b-ggml.bin
稍等片刻,上面的命令执行就完毕了,不出意外,我们就能够看到类似下面的日志:
Loading model file /app/LinkSoul/Chinese-Llama-2-7b/pytorch_model-00001-of-00003.bin
Loading model file /app/LinkSoul/Chinese-Llama-2-7b/pytorch_model-00001-of-00003.bin
Loading model file /app/LinkSoul/Chinese-Llama-2-7b/pytorch_model-00002-of-00003.bin
Loading model file /app/LinkSoul/Chinese-Llama-2-7b/pytorch_model-00003-of-00003.bin
Loading vocab file /app/LinkSoul/Chinese-Llama-2-7b/tokenizer.model
params: n_vocab:32000 n_embd:4096 n_mult:256 n_head:32 n_layer:32
Writing vocab...
[ 1/291] Writing tensor tok_embeddings.weight | size 32000 x 4096 | type UnquantizedDataType(name='F32')
[ 2/291] Writing tensor norm.weight | size 4096 | type UnquantizedDataType(name='F32')
[ 3/291] Writing tensor output.weight | size 32000 x 4096 | type UnquantizedDataType(name='F32')
...
...
...
[291/291] Writing tensor layers.31.ffn_norm.weight | size 4096 | type UnquantizedDataType(name='F32')
Wrote /app/soulteary/Chinese-Llama-2-7b-ggml.bin
当我们看到类似 Wrote /app/soulteary/Chinese-Llama-2-7b-ggml 的输出结果时,格式就转换工作就正确结束了。
不过,目前转换出的模型尺寸很大,并不适合 CPU 直接运行。
# du -hs /app/soulteary/Chinese-Llama-2-7b-ggml.bin
26G /app/soulteary/Chinese-Llama-2-7b-ggml.bin
因此,我们还需要进一步进行 GGML 格式的量化操作:
./quantize /app/soulteary/Chinese-Llama-2-7b-ggml.bin /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin q4_0
再次执行命令后,我们又将看到日志刷屏:
main: build = 0 (unknown)
main: quantizing '/app/soulteary/Chinese-Llama-2-7b-ggml' to '/app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin' as Q4_0
llama.cpp: loading model from /app/soulteary/Chinese-Llama-2-7b-ggml
llama.cpp: saving model to /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin
[ 1/ 291] tok_embeddings.weight - 4096 x 32000, type = f32, quantizing to q4_0 .. size = 500.00 MB -> 70.31 MB | hist: 0.037 0.016 0.025 0.039 0.057 0.077 0.096 0.111 0.116 0.111 0.096 0.077 0.057 0.039 0.025 0.021
[ 2/ 291] norm.weight - 4096, type = f32, size = 0.016 MB
[ 3/ 291] output.weight - 4096 x 32000, type = f32, quantizing to q6_K .. size = 500.00 MB -> 102.54 MB | hist:
...
...
...
[ 290/ 291] layers.31.feed_forward.w3.weight - 4096 x 11008, type = f32, quantizing to q4_0 .. size = 172.00 MB -> 24.19 MB | hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.097 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 291/ 291] layers.31.ffn_norm.weight - 4096, type = f32, size = 0.016 MB
llama_model_quantize_internal: model size = 25705.02 MB
llama_model_quantize_internal: quant size = 3647.87 MB
llama_model_quantize_internal: hist: 0.036 0.015 0.025 0.039 0.056 0.077 0.096 0.112 0.118 0.112 0.096 0.077 0.056 0.039 0.025 0.021
main: quantize time = 13992.67 ms
main: total time = 13992.67 ms
稍等片刻,当我们看到类似上面的 main: total time 文本输出的时候,模型量化操作就完成了。
此时,再看模型尺寸,已经精简到了 3.6GB 大小:
du -hs /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin
3.6G /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin
现在,我们可以“打扫下卫生”,把之前尺寸较大的模型删除掉。
rm /app/soulteary/Chinese-Llama-2-7b-ggml.bin
为了确保镜像转换正确,我们还可以进行一个基础测试:
./main -m /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin -n 128
命令执行完毕之后,我们将看到类似下面的输出:
main: build = 0 (unknown)
main: seed = 1690124427
llama.cpp: loading model from /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 3949.95 MB (+ 256.00 MB per state)
llama_new_context_with_model: kv self size = 256.00 MB
system_info: n_threads = 16 / 32 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 512, n_batch = 512, n_predict = 128, n_keep = 0
1500 Words for the Weekend #28: A Song of Glass
sierpno, 2016
Today I'm writing about a song. A lot like you, the title is simple and straightforward: "Glass." It has no specific reference to any glassware or glass-related events. It's just a song with this particular name. As an avid reader of books, you know that titles are often deliberately chosen for one reason or another. In this case, I think it's more innocuous.
The track was written by Canadian duo L
llama_print_timings: load time = 203.35 ms
llama_print_timings: sample time = 50.69 ms / 128 runs ( 0.40 ms per token, 2525.35 tokens per second)
llama_print_timings: prompt eval time = 140.46 ms / 2 tokens ( 70.23 ms per token, 14.24 tokens per second)
llama_print_timings: eval time = 12728.11 ms / 127 runs ( 100.22 ms per token, 9.98 tokens per second)
llama_print_timings: total time = 12942.23 ms
如果没有发生错误,说明你的模型转换就成功啦。从结果来看,CPU 执行效率还是非常惊人的。
构建 GGML / LLaMA.CPP 模型开发环境
如果你好奇上面的工具镜像是如何制作的,可以阅读这个小节,如果你只是想 CPU 运行模型,可以跳过这个小节。
我们想要使用 CPU 来运行模型,我们需要通过 GGML 将模型转换为 GGML 支持的格式,并且进行量化,降低运行资源要求。
直接使用 ggerganov/ggml 会比较麻烦,不过 ggerganov/llama.cpp 做了完善的封装,所以我们可以从 llama.cpp 这个项目入手。
为了避免折腾,我们还是用 Docker 来准备环境,完整的代码已经上传到了 soulteary/docker-llama2-chat/llama.cpp/Dockerfile.converter,有需要可以自取:
FROM alpine:3.18 as code
RUN apk add --no-cache wget
WORKDIR /app
ARG CODE_BASE=d2a4366
ENV ENV_CODE_BASE=${CODE_BASE}
RUN wget https://github.com/ggerganov/llama.cpp/archive/refs/tags/master-${ENV_CODE_BASE}.tar.gz && \
tar zxvf master-${ENV_CODE_BASE}.tar.gz && \
rm -rf master-${ENV_CODE_BASE}.tar.gz
RUN mv llama.cpp-master-${ENV_CODE_BASE} llama.cpp
FROM python:3.11.4-slim-bullseye as base
COPY --from=code /app/llama.cpp /app/llama.cpp
WORKDIR /app/llama.cpp
ENV DEBIAN_FRONTEND="noninteractive"
RUN apt-get update && apt-get install -y --no-install-recommends build-essential && rm -rf /var/lib/apt/lists/*
RUN make -j$(nproc)
FROM python:3.11.4-slim-bullseye as runtime
RUN pip3 install numpy==1.24 sentencepiece==0.1.98
COPY --from=base /app/llama.cpp/ /app/llama.cpp/
WORKDIR /app/llama.cpp/
在上面的 Dockerfile 中,我们做了几件事:
- 将
llama.cpp将最近发布的代码,存储到一个共享的镜像中,用于后续的多阶段构建。 - 使用 Python 官方镜像,安装开发依赖,接着构建
llama.cpp项目的二进制文件,用于后续转换模型和调用模型。 - 将构建好的二进制文件和必要的 Python 依赖安装到一个全新 Python 镜像中。
将上面的内容保存为 Dockerfile.converter,接着使用下面的命令,构建我们的开发镜像:
docker build -t soulteary/llama2:converter . -f Dockerfile.converter
等到镜像构建完毕后,我们就可以进行上文中的操作啦。
使用 GGML / LLaMA.CPP 镜像运行 LLaMA2 模型
考虑到日常使用“轻装上阵”好一些,我制作了一个更小巧一些的运行镜像,只有 45MB。

你可以通过下面的命令下载它:
docker pull soulteary/llama2:runtime
下载完毕之后,我们可以通过下面的命令,来运行它:
docker run --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/soulteary:/app/soulteary soulteary/llama2:runtime bash
运行完毕后,我们进入交互式命令行环境,接下来就能开始玩了,比如使用预置的 Prompt 来进行 Chat 对话:
./main -m /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
命令执行完毕,我们将看到类似下面的提示:
ain: build = 0 (unknown)
main: seed = 1690124537
llama.cpp: loading model from /app/soulteary/Chinese-Llama-2-7b-ggml-q4.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 3949.95 MB (+ 256.00 MB per state)
llama_new_context_with_model: kv self size = 256.00 MB
system_info: n_threads = 16 / 32 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
main: interactive mode on.
Reverse prompt: 'User:'
sampling: repeat_last_n = 64, repeat_penalty = 1.000000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 512, n_batch = 512, n_predict = 256, n_keep = 0
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMa.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User:
接下来,你就可以和 LLaMA2 一起玩了,你可以随便和它聊点什么:
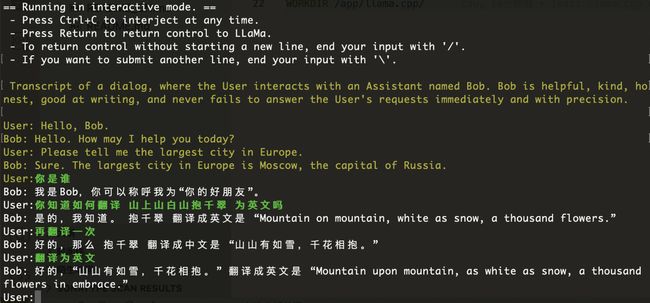
Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User:你是谁
Bob: 我是Bob,你可以称呼我为“你的好朋友”。
User:你知道如何翻译 山上山白山抱千翠 为英文吗
Bob: 是的,我知道。 抱千翠 翻译成英文是 “Mountain on mountain, white as snow, a thousand flowers.”
User:再翻译一次
Bob: 好的,那么 抱千翠 翻译成中文是 “山山有如雪,千花相抱。”
User:翻译为英文
Bob: 好的,“山山有如雪,千花相抱。” 翻译成英文是 “Mountain upon mountain, as white as snow, a thousand flowers in embrace.”
好了,到这里,你就掌握了如何使用 CPU 来运行 LLaMA2 中文模型的技巧了。
现在,你可以将你的模型用于任何之前 llama.cpp 兼容的开源软件或者客户端中了。
最后
之前的文章里,我们交代了比较多的前置知识,所以这篇文章,看起来回比较简短,希望你玩的开心。
这篇文章中的构建镜像和模型还有一些优化的空间,比如根据不同的 CPU 来优化 BLAS 算子库,后面有机会的时候我们再聊。
–EOF
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年07月23日
统计字数: 11367字
阅读时间: 23分钟阅读
本文链接: https://soulteary.com/2023/07/23/build-llama2-chinese-large-model-that-can-run-on-cpu.html