使用机器学习协助灾后救援
2023 年 2 月 6 日,土耳其东南部发生 7.7 级和 7.6 级地震,影响 10 个城市,截至 2 月 21 日已造成 42,000 多人死亡和 120,000 多人受伤。
地震发生几个小时后,一群程序员启动了一个 Discord 服务,推出了一个名为 afetharita 的应用程序,字面意思是 灾难地图。该应用程序将为搜救队和志愿者提供服务,以寻找幸存者并为他们提供帮助。当幸存者在社交媒体上发布带有他们的地址和他们需要的东西 (包括救援) 的文本截图时,就需要这样一个应用程序。一些幸存者还在发布了他们需要的东西,这样他们的亲属就知道他们还活着并且需要救援。需要从这些推文中提取信息,我们开发了各种应用程序将它们转化为结构化数据,并争分夺秒的开发和部署这些应用程序。
当我被邀请到 Discord 服务时,关于我们 (志愿者) 将如何运作以及我们将做什么的问题弄得非常混乱。我们决定协作训练模型,并且我们需要一个模型和数据集注册表。我们开设了一个 Hugging Face 组织帐户,并通过拉取请求进行协作,以构建基于 ML 的应用程序来接收和处理信息。

其他团队的志愿者告诉我们,需要一个应用程序来发布屏幕截图,从屏幕截图中提取信息,对其进行结构化并将结构化信息写入数据库。我们开始开发一个应用程序,该应用程序将拍摄给定图像,首先提取文本,然后从文本中提取姓名、电话号码和地址,并将这些信息写入将交给当局的数据库。在尝试了各种开源 OCR 工具之后,我们开始使用 easyocrOCR 部分和 Gradio 为此应用程序构建界面。我们还被要求为 OCR 构建一个独立的应用程序,因此我们从界面打开了接口。使用基于 transformer 的微调 NER 模型解析 OCR 的文本输出。

为了协作和改进该应用程序,我们将其托管在 Hugging Face Spaces 上,并且我们获得了 GPU 资助以保持该应用程序的正常运行。Hugging Face Hub 团队为我们设置了一个 CI 机器人,让我们拥有一个短暂的环境,这样我们就可以看到拉取请求如何影响 Space,并且帮助我们在拉取请求期间审查。
后来,我们从各种渠道 (例如 Twitter、Discord) 获得了带有标签的内容,其中包括幸存者求救电话的原始推文,以及从中提取的地址和个人信息。我们开始尝试使用闭源模型的少量提示和微调来自 transformers 的我们自己的 token 分类模型。我们使用 bert-base-turkish-cased 作为 token 分类的基础模型,并提出了第一个地址提取模型。
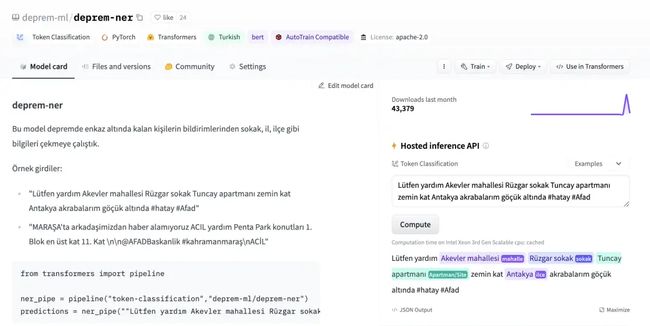
该模型后来用于 afetharita 提取地址。解析后的地址将被发送到地理编码 API 以获取经度和纬度,然后地理定位将显示在前端地图上。对于推理,我们使用了 Inference API,这是一个托管模型进行推理的 API,当模型被推送到 Hugging Face Hub 时会自动启用。使用 Inference API 进行服务使我们免于拉取模型、编写应用程序、构建 Docker 镜像、设置 CI/CD 以及将模型部署到云实例,这些对于 DevOps 和云团队来说都是额外的开销工作以及。Hugging Face 团队为我们提供了更多的副本,这样就不会出现停机时间,并且应用程序可以在大量流量下保持健壮。
后来,我们被问及是否可以从给定的推文中提取地震幸存者的需求。在给定的推文中,我们获得了带有多个标签的数据,用于满足多种需求,这些需求可能是住所、食物或物流,因为那里很冷。我们首先开始在 Hugging Face Hub 上使用开源 NLI 模型进行零样本实验,并使用闭源生成模型接口进行少量样本实验。我们已经尝试过 xlm-roberta-large-xnli 和 convbert-base-turkish-mc4-cased-allnli_tr. NLI 模型非常有用,因为我们可以直接推断出候选标签,并在数据漂移时更改标签,而生成模型可能会编造标签,在向后端提供响应时导致不匹配。最初,我们没有标记的数据,因此任何东西都可以使用。
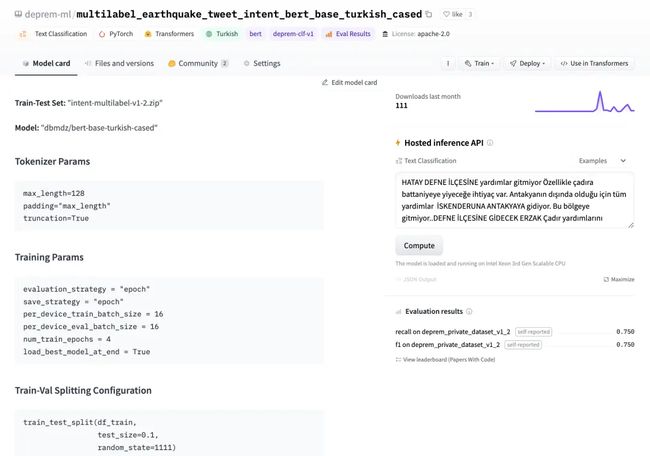
最后,我们决定微调我们自己的模型,在单个 GPU 上微调 BERT 的文本分类头大约需要三分钟。我们进行了标记工作来开发数据集去训练该模型。我们在模型卡的元数据中记录了我们的实验,这样我们以后就可以出一个 leaderboard 来跟踪应该将哪个模型部署到生产环境中。对于基本模型,我们尝试了 bert-base-turkish-uncased 和 bert-base-turkish-128k-cased 并发现它们的性能优于 bert-base-turkish-cased 。你可以在 下面的链接 找到我们的 leaderboard。
考虑到手头的任务和我们数据类别的不平衡,我们专注于消除假阴性并创建了一个 Space 来对所有模型的召回率和 F1 分数进行基准测试。为此,我们将元数据标签添加 deprem-clf-v1 到所有相关模型存储库中,并使用此标签自动检索记录的 F1 和召回分数以及模型排名。我们有一个单独的基准测试集,以避免泄漏到训练集,并始终如一地对我们的模型进行基准测试。我们还对每个模型进行了基准测试,以确定每个标签的最佳部署阈值。
我们希望对我们的命名实体识别模型进行评估,并发起了众包努力,因为数据标记者正在努力为我们提供更好和更新的意图数据集。为了评估 NER 模型,我们使用 Argilla 和 Gradio 搭建了一个标注界面,人们可以输入一条推文,并将输出标记为正确/不正确/模糊。
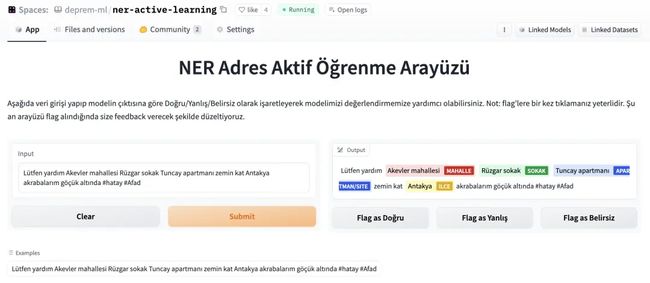
后来,数据集被去重并用于基准测试我们的进一步实验。
机器学习团队中的另一个小组使用生成模型 (通过门控 API) 来获取特定需求 (因为标签过于宽泛) 的自由文本,并将文本作为每个帖子的附加上下文传递。为此,他们进行了提示工程,并将 API 接口包装为单独的 API ,并将它们部署在云端。我们发现,使用 LLM 的少样本提示有助于在快速发展的数据漂移存在的情况下适应细粒度的需求,因为我们需要调整的唯一的东西是提示,而且我们不需要任何标记的数据。
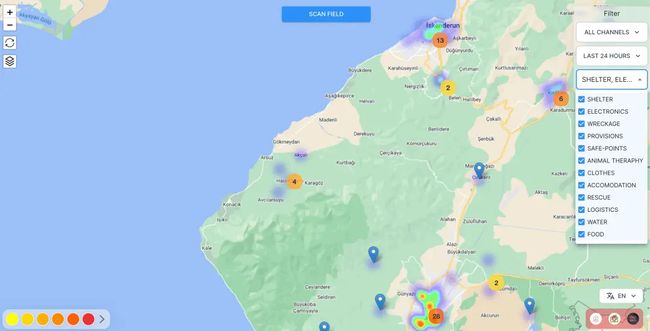
这些模型目前正在生产中使用,以创建下面热图中的点,以便志愿者和搜救团队可以将需求带给幸存者。
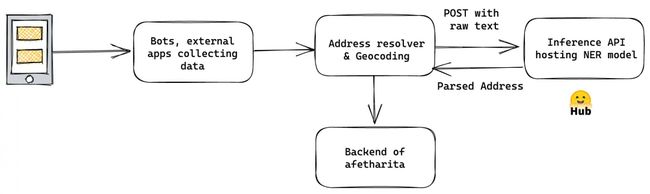
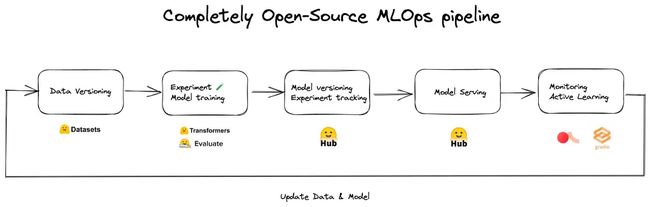
我们已经意识到,如果没有 Hugging Face Hub 和其生态系统,我们将无法如此快速地协作、制作原型和部署。下面是我们用于地址识别和意图分类模型的 MLOps 流水线。
这个应用程序及其各个组件背后有数十名志愿者,他们不眠不休地工作以在如此短的时间内就完成了。
遥感应用
其他团队致力于遥感应用,以评估建筑物和基础设施的损坏情况,以指导搜索和救援行动。地震发生后的最初 48 小时内,电力和移动网络都没有稳定,再加上道路倒塌,这使得评估损坏程度和需要帮助的地方变得极其困难。由于通讯和运输困难,搜救行动也因建筑物倒塌和损坏的虚假报告而受到严重影响。
为了解决这些问题并创建可在未来利用的开源工具,我们首先从 Planet Labs、Maxar 和 Copernicus Open Access Hub 收集受影响区域的震前和震后卫星图像。
我们最初的方法是快速标记卫星图像以进行目标检测和实体分割,并使用“建筑物”的单一类别。目的是通过比较从同一地区收集的震前和震后图像中幸存建筑物的数量来评估损坏程度。为了更容易训练模型,我们首先将 1080x1080 的卫星图像裁剪成更小的 640x640 块。接下来,我们微调了用于建筑物检测的 YOLOv5、YOLOv8 和 EfficientNet 模型以及用于建筑物语义分割的 SegFormer 模型,并将这些应用部署到 Hugging Face Spaces。
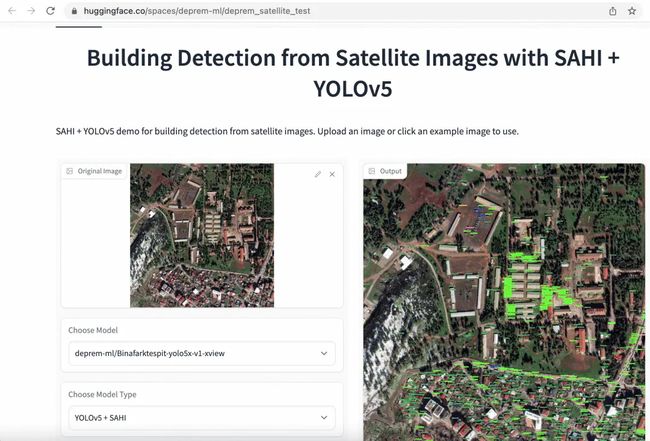
同样,数十名志愿者致力于标记、准备数据和训练模型。除了个人志愿者外,像 Co-One 这样的公司也自愿为卫星数据进行更详细的建筑和基础设施注释标记,包括 无损伤、被摧毁、受损、受损设施 和 未受损设施 标签。我们当前的目标是发布一个广泛的开源数据集,以便在未来加快全球的搜救行动。
总结
对于这种极端应用案例,我们必须迅速行动,并优化分类指标,即使 1% 的改进也很重要。在此过程中有许多伦理讨论,因为甚至选择要优化的指标也是一个伦理问题。我们已经看到了开源机器学习和民主化是如何使个人能够构建挽救生命的应用程序