Hadoop概念学习(无spring集成)
Hadoop
分布式的文件存储系统
三个核心组件

但是现在已经发展到很多组件的s

或者这个图

官网地址:
https://hadoop.apache.org
历史
hadoop历史可以看这个:
https://zhuanlan.zhihu.com/p/54994736

优点
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
高容错性: 能够自动将失败的任务重新分配。
架构变迁
Hadoop1.0
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)

Hadoop2.0
HDFS(分布式文件存储)
MapReduce(分布式数据处理)
YARN(集群资源管理,任务调度)

Hadoop3.0
专注于性能优化
1.精简内核,类路径隔离,shell脚本重构
2.Hadoop HDFS 上 EC纠删码,多NameNode支持
3.Hadoop MapReduce 任务本地优化,内存参数自动推断
Hadoop YARN timeline service v2 队列配置
集群介绍:

文件资源管理的集群与任务调度的集群在一起称为Hadoop集群
逻辑上分离,在物理上可以在一起,不同集群分成了不同的进程完成独立的事
MapReduce是计算框架,代码层次上的组件,没有集群说
搭建集群
安装采用的三台centos7虚拟机,
搭建教程看的下面链接的教程
教程
搭建时记得看好自己C盘存储够不够(内存满了就装C盘

集群前知识(在解压后,安装前观看):
bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
sbin目录:存放启动或停止Hadoop相关服务的脚本
share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
完全分布式模式(下面用的完全分布式):多台服务器组成分布式环境。生产环境使用。

然后之间相互调用好像是用的ssh,(可能
所以还需要创建免密的ssh环境
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件:

自定义配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置.
记得有些坑
配置节点的时候:有slaves和workers,其实都是一个东西,但是可能因为政治正确在3.0之后改成了workers,但是好像slaves还保留着的
配置的时候只在workers里配置节点就行,(虽然说我的节点名还是slave)
相同的情况在mysql,redis,python等也发生了
sbin/start-dfs.sh启动不能用root,要用他前面设置的所有者
需要在这里写上java_home
vi etc/hadoop/hadoop-env.sh
echo $JAVA_HOME #查自己的java_home
#加入下面这句,按照自己的java_home改,
export JAVA_HOME=/usr/local/jdk8/jdk1.8.0_341

这里必须用创建的那个用户所有者来,不能用root
关键词:修改文件所有者
sudo chown -R lkw ./

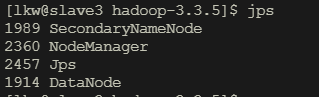
输入jps查看有哪些java进程
集群1启动

内存快爆了
集群2启动:
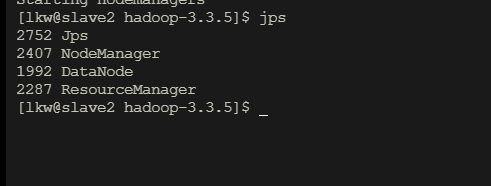
集群3启动:
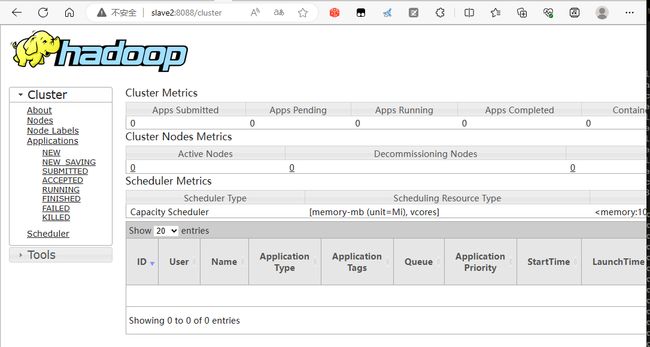
网页也启动成功

处理集群崩溃
仅限新手测试处理,不适用于生产环境
先杀死集群,(或者重开机也行
删除历史数据
面试题:

HDFS概述
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统中的一个分布式文件系统。它旨在处理大规模数据集的存储和处理,并提供高容错性、高吞吐量和可扩展性。
HDFS的设计灵感来自于Google的GFS(Google File System),它通过将数据分布在集群中的多个机器上实现数据的可靠性和并行处理能力。
HDFS具有以下主要特点:
-
分布式存储:HDFS将大文件分成多个数据块,然后将这些数据块分布在多个计算节点上的本地磁盘上。这种分布式存储方式提供了数据的冗余和高可靠性。
-
数据冗余和容错性:HDFS通过在集群中多个节点上存储数据的多个副本来提供数据的容错性。如果某个节点发生故障,系统可以自动从其他节点上的副本中恢复数据。
-
高吞吐量:HDFS被优化用于大数据集的批处理工作负载,它具有高吞吐量的特性。它可以并行读取和写入大量数据,适用于数据处理和分析。
-
扩展性:HDFS可以水平扩展以适应不断增长的数据量。通过添加更多的计算节点,可以增加存储容量和处理能力,而无需中断运行。
-
简单性:HDFS的设计简单且易于使用。它提供了类似于传统文件系统的接口,使开发人员能够以类似于本地文件的方式进行文件操作。
HDFS广泛应用于大数据处理场景,它与Hadoop生态系统中的其他工具(如MapReduce、Spark等)紧密结合,为大规模数据处理和分析提供基础设施。
缺点:
不适合低延时数据访问
简单的来说
就是文件系统
缺点:
无法高效的大量小文件存储(1.因为存储空间碎片化,增加了磁盘寻址和数据定位开销,2.同时任务调度也会变多,任务切换开销变大
解决方法:1.合并小文件,2.直接存数据库去,3.hadoop归档工具HAR等)
不支持并发写入,文件随机修改(1.因为采用了主从1架构限制了并发写入,保证一致性。 2.并发写入和随机修改会导致数据碎片化以及数据不连续,3.hadoop的主要关注点不是为了这个,而是为了大规模数据读取,转换和分析)
**解决方法:**Apache HBase作为Hadoop生态系统中的分布式数据库
HDFS的架构组成

1.NameNode
处理客户端请求
配置副本策略
管理数据块映射信息
管理HDFS的名称空间
总的来说,就是一个老板
2.DataNode
存储数据快
管理数据块
总的来说,就是一个仓管
3.Client
文件切分
从NameNode获取文件各种信息
从DataNode存储或者取出数据
总的来说,就是一个销售
4.NameNode
并不是nameNode的热备,老板挂掉,他不能代替老板,只能辅助恢复NameNode
可以为NameNode分担工作量
总的来说,相当于秘书
HDFS文件块大小
默认2.x/3.x的文件块大小是128M
1.x中是64M
设太大会导致数据读取时间变超大,不利于程序处理这段数据
设太小增加寻址时间
HDFS的Shell操作(重点)
基本语法
下面两个一样
hadoop fs (具体命令)
hdfs dfs (具体命令)
#查询命令,但是到真查询还得谷歌
hadoop fs -help (具体命令)
hadoop fs:这是Hadoop文件系统Shell命令的入口点,用于执行各种文件和目录操作。
hadoop fs -ls :列出指定路径下的文件和目录。
hadoop fs -mkdir :创建一个新的目录。
hadoop fs -put :将本地文件或目录上传到HDFS。
(hadoop fs -copyFromLocal 也是本地文件上传,但是上面的简洁
hadoop fs -copyToLocal 下载到本地)
hadoop fs -get :从HDFS下载文件或目录到本地。
hadoop fs -rm :删除指定的文件或目录。
hadoop fs -cat :显示文件的内容。
hadoop fs -mv :移动文件或目录。
hadoop fs -tail :查看一个文件末尾1kb的数据
hadoop fs -du :查看一个文件或文件夹大小信息
hadoop jar:用于执行Hadoop作业(Job)。
hadoop jar :运行指定的Hadoop作业,其中是Hadoop作业的JAR文件路径,是作业的主类,和分别是输入和输出的HDFS路径。
hadoop dfsadmin:用于管理HDFS集群的命令。
hadoop dfsadmin -report:显示HDFS集群的整体状态和报告信息。
hadoop dfsadmin -safemode :管理HDFS的安全模式。
hadoop dfsadmin -refreshNodes:刷新集群节点列表。
hadoop dfsadmin -setBalancerBandwidth :设置数据均衡器的带宽限制。
hadoop job:用于查看和管理Hadoop作业。
hadoop job -list:列出当前运行的Hadoop作业。
hadoop job -status :显示指定作业的状态和进度信息。
hadoop job -kill :终止指定的Hadoop作业。