手机银行:背后有1600个微服务?

本文素材来自外网,由Matt Heath & Suhail Patel 分享。
由老G先生整理部分文字。
编辑:强哥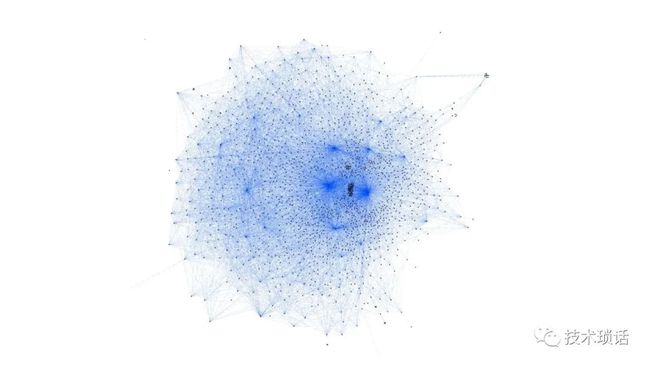
 My name is Suhail. I am joined by Matt. We're both engineers at Monzo. We spend our time working on the underlying platform powering the bank.
My name is Suhail. I am joined by Matt. We're both engineers at Monzo. We spend our time working on the underlying platform powering the bank.
We think that all of these complexities about scaling our infrastructure and making sure that servers are provisioned and databases are available, should be dealt by a specific team so that engineers who are working on the product can focus on building a great bank and not have to worry about their infrastructure. They can essentially focus.
400w Monzo bank account





Heath: Five years ago, a group of people decided to build a bank from the ground up. There are a lot of reasons for that. We wanted to build something that's a bit different, how people manage their money easily, simply.
That means you're competing in a space of, honestly, quite a large number of quite big, very well established banks. When we were trying to work out how we would approach that problem, we wanted to build something that was flexible, and could let our organization flex and scale as we grew. The real question is, with that in mind, where do you start?
I occasionally suggest this would be the approach. You just open your text editor. Start with, new bank file. Then go from there.
Five years ago, I didn't know anything about banking. It's an interesting problem to start from something where you need to work out and understand the domain. Also, work out how you're going to provide the technology underneath that.


With those four main things in mind, we wanted to work out, what are the technology choices that we will make to drive those things. We made a few quite early on.
We use Go as our primary programming language. There's lots of reasons for that. Ultimately, as a language goes, it's quite simple. It's statically typed. It makes it quite easy for us to get people on board. If you're using a language that not many people know, you have to get people up to speed on how to do that. Honestly, if you're working in a company where you have quite a large framework, you already have that problem. You have to get people to understand how your toolset works, and how your framework works, and how they can be effective within your organization.
Go also has some interesting things such as a backwards compatibility guarantee. We've been using Go from the very early versions of Go 1. Every time a new version of Go comes out, it has a guarantee that we can recompile our code, and we basically get all of the improvements. What that means is the garbage collector, for example, has improved several orders of magnitude over the time that we've had our infrastructure running. Every time we recompile it, test that it still works. Then we just get those benefits for free.
The other things that we chose early on, were emphasizing distributed technologies. We didn't want to be in a world where you have one really resilient system, and then a second backup system, and a big lever that you pull but you don't pull very often. Because if you don't exercise those failover modes, how can you know that they work reliably?
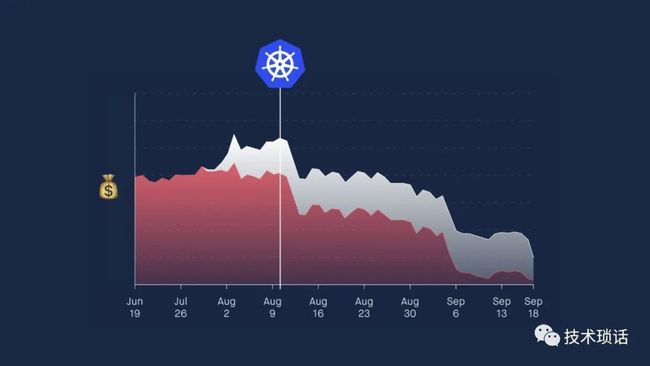
We wanted to pick distributed technologies from very early on. We use Cassandra as our database. Back in 2015 Kubernetes wasn't really an option, so we actually used Mesos. Then a bit later in 2016, we revised that, looked around, and it was clear that Kubernetes was the emerging market leader.
Before we expanded into our current account, we switched over to Kubernetes. The thing that we were taking from that is providing an abstraction. An abstraction from underlying infrastructure for our engineers who were building banking systems on top of that.
I think the first version of Kubernetes we've run in production was version 1.2.
For anyone who has used those versions of Kubernetes, that was an interesting time. There were many benefits to moving to Kubernetes. We actually saved loads of money quite quickly.
We had lots of machines that were running Jenkins worker pools, and loads of other things that we couldn't easily run on our Mesos cluster. By moving to Kubernetes, we could use the spare capacity on the cluster to do all of our build jobs and various other things. We could more tightly pack our applications. That saved us a load of money. We shut down loads of other infrastructure.

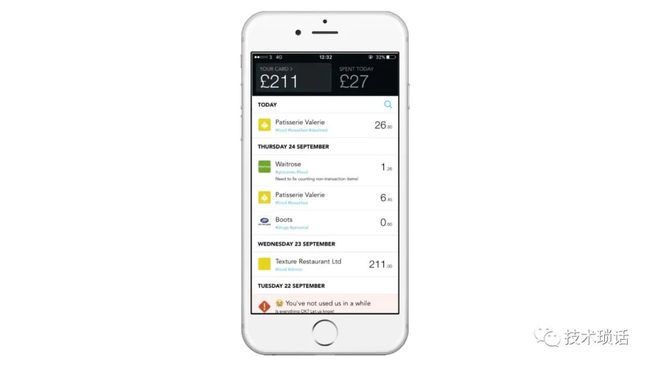
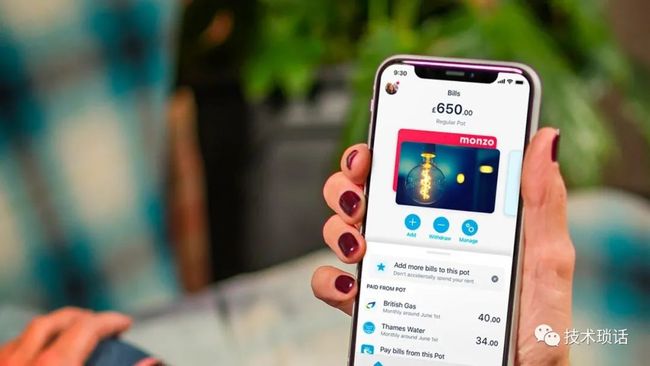


We started off in the early days with a really basic product.
We didn't even have debit cards to start with. Then slowly from that point, we've iterated and added more and more features.
We've added Pots so that you can organize your money.
You can pay directly out of them.
You can save money through those.
You can pick how to do that in the app.
Or, you can have your salary paid a day early.
You'll get a prompt in the app if you're eligible.
Then you can sort that into the Pots so you can segregate all of your money for bills just straight away.
You just never see it.
Your bill money goes over here.
You pay your bills straightaway.
All of these are provided by an API.
This part is relatively straightforward. We have many product features.
We have many aspects of our API that we need to build.
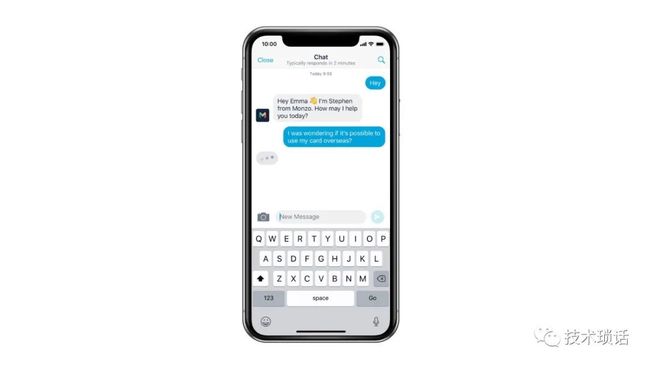





很明显,随着时间的推移,我们公司做的事情越来越多。这意味着我们构建的系统数量增加了。目前,我们有1600个微服务,它们都很小。我们使用了限界上下文(BC),它们对自己所做的事情非常关注。这使我们能够灵活,因为不同的小组可以操作这个代码库的一小部分。随着我们组织的发展,我们拥有更多的团队,他们可以专注于越来越小的领域。
这些系统负责为我们的银行提供一切动力。从支付网络、转移资金、维护分户账、打击欺诈、金融犯罪到提供世界一流的客户支持。所有这些都是我们在基础设施中作为服务构建的系统。
这就是我们如何从一个相对简单的产品发展到一个乍看起来非常复杂的系统。在这个特定的图表中,我们根据拥有和维护这些系统的团队对区域进行了颜色编码。您可以看到,公司内有不同团队拥有的服务。

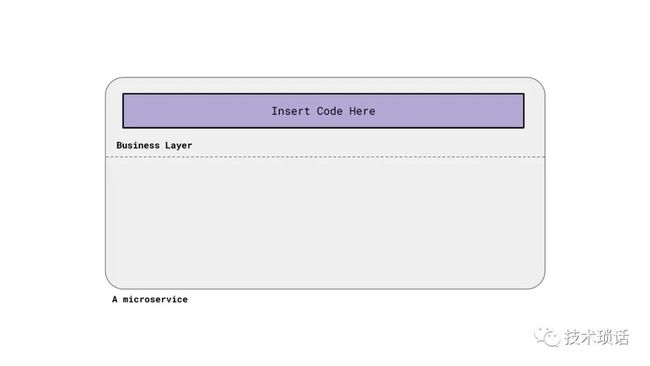

Patel: You want to add a microservice? Where do you get started? You start with a blank canvas. This is the surface area that engineers are typically exposed to. They put their business logic in a well-defined box. The surrounding portion makes sure that it works and is production ready, and provides all the necessary interfaces and integrations with the rest of our infrastructure. One of our biggest decisions as an organization, was our approach to writing microservices for all of our business functions. Each of these units, or each of these microservices of business logic are built on a shared core. Our goal is to reduce variance as much as we can of each additional microservice we add. If a microservice gets really popular, we can scale it independently.
Engineers are not rewriting core abstractions like marshaling of data, or HTTP servers, or integration with metric systems for every new service that they add. They can rely on a well-defined and well-tested and well-supported set of libraries, and tooling, and infrastructure that we provide.
ps:Business Layer 背后有大量的RPC处理和数据服务处理,如何解耦?
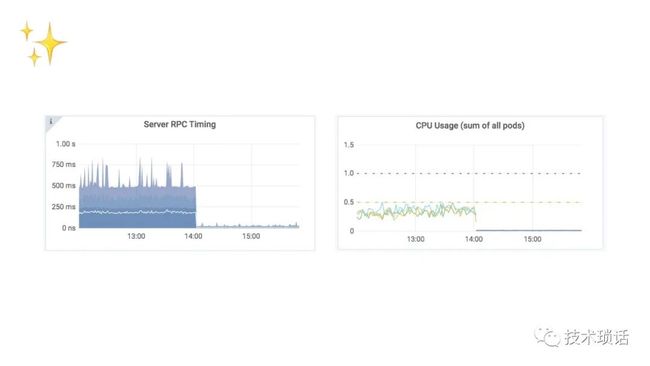
When we make an improvement or fix a bug in the shared library layer, every service can benefit, usually, without needing a single line of code change within the business logic. Here's an example, where we made some improvements to reduce the amount of CPU time of unmarshaling data between Cassandra our primary datastore, and Go, which is what we use to write all of our microservices. Some of our services saw a significant CPU and latency drop. This work has cascading and global improvements across the platform. It's a free speed improvement for anyone who's working on business logic. Everyone loves a free speed improvement.
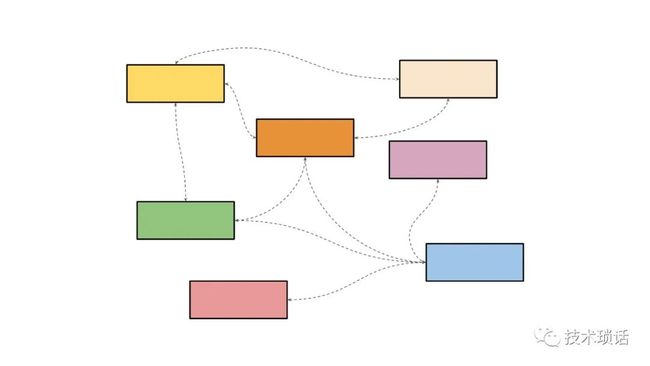
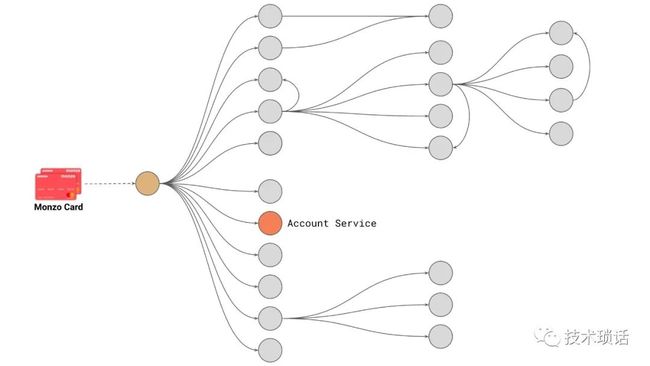

How can we compose services together to form a cohesive product, or offering, or service? We take a problem and subdivide it into a set of bounded context. The whole premise behind this is the single responsibility principle. Take one thing, do it correctly and do it well. Each service provides a well-defined interface. Ideally, we have safe operations. Consider that if you are going to expose this interface to the public world, what tunable parameters would you want to expose to the world? You don't want to provide every particular node, because that means that you might have lots of different permutations that you need to support.
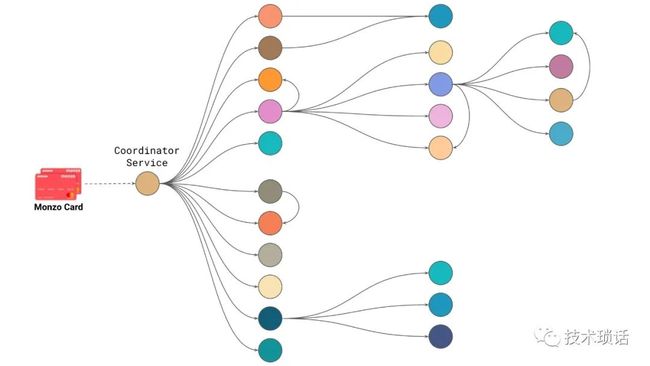
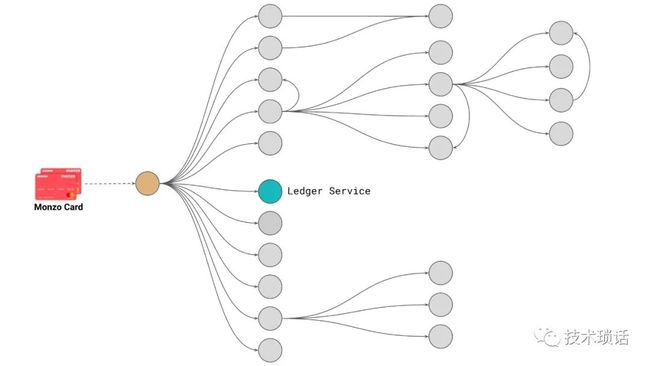
As a particular example, here's a diagram of all the services that get involved when you tap your Monzo card at a payment terminal. Quite a few distinct components are involved in real-time when you make a transaction to contribute to the decision on whether a payment should be accepted, or rejected, or something in between. All of this needs to work as one cohesive unit to provide that decision. Part of that is calling key services, like our account service, which deals with the abstraction of accounts all across Monzo. It's not just providing bank accounts, but accounts as a whole, as a singular abstraction at Monzo. Also, the ledger service, which is responsible for tracking all money movements, no matter in what currency, or what environment, is responsible. It is a singular entity that's responsible for tracking all money movements all across Monzo.
This diagram is actually the maximal set of services. In reality, not every service gets involved in every invocation on every transaction. Many of these are there to support the complexity of receiving payments, for example. There is different validation and work we need to do to support chip-and-PIN versus contactless, versus if you swipe your card if you're in the U.S., or occasionally, if you're in the UK and the card term was broken. A service will only get called if it needs to get involved with a particular type of transaction. This thing is still really complex because accepting payments is really complex. Why do we have such granularity? We want to break down the complexity and minimize the risk of change. For example, if we want to change the way contactless payments work, we're not affecting the chip-and-PIN system or the magstripe system, so we can fall back to those if we get it wrong.
简言之,还是单一职责划分服务。


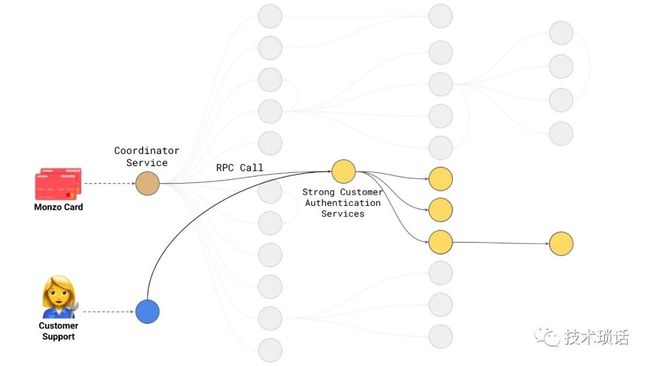
2019年9月,一项名为“强力客户认证”的欧盟立法生效,旨在提高支付安全性,减少欺诈金额。该法规的重点是在支付时增加一个双因素认证层。为了成功付款,客户需要三个要素中的两个。我们必须改变我们的支付流程,才能做到合规,就像大多数其他银行一样。
由于这个需求,把强用户认证服务进行了加强,关于用户认证的逻辑不用散落,都在这个服务中提供。
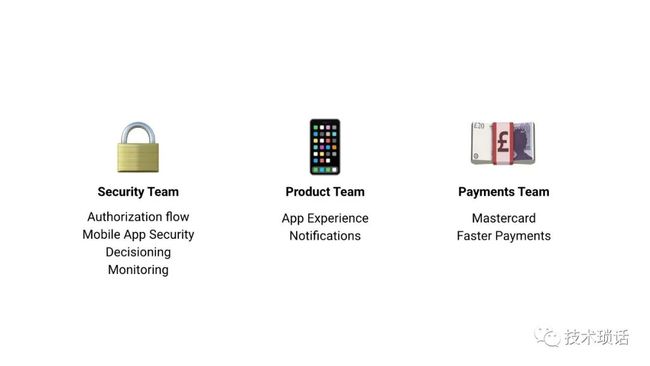

同时,架构是演进的。比如我们的ID生成服务3-4年都没怎么变过。
有时候我们发现过早的拆分了一些东西,其实并没有业务规模的发展,还要修改2个地方,我们又把他们合并起来。
同时,还有关注旧业务下线导致的服务优化和下线,比如我们曾经有预付卡业务,现在没有了。如果这些逻辑仍然侵入到一些处理环节,就很麻烦。

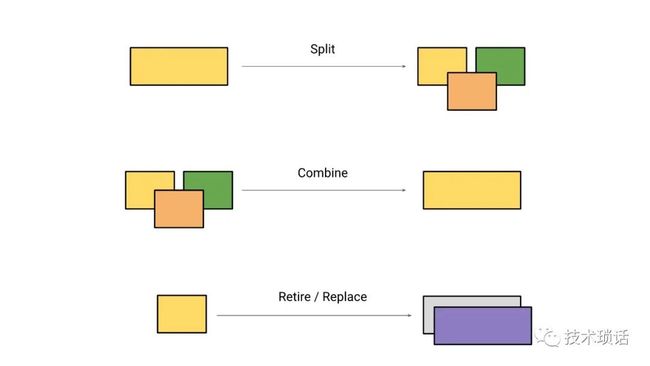

我认为迭代过程是我们在Monzo通常关注的事情,实际上,无论是从基础设施的角度,还是从产品的角度。我们特别喜欢亨里克·克尼伯格(Henrik Kniberg)的一幅漫画,它讲述的是,我们正试图迭代构建一个更好的产品。
即使在刚开始的时候,如果我们试图建立一家银行,而没有足够的客户反馈,那么我们可能最终会遇到一些不能真正满足客户需求的问题。通过不断地与人们交谈,通过做一些小的改变,然后不断迭代。避免YY。
ps:
乔布斯说,他从来不做市场调研。如果亨利·福特在发明汽车之前去做市场调研,他得到的答案一定是消费者希望得到一辆更快的马车。意即消费者不知道自己想要什么,企业要靠自己的直觉创造伟大的产品并引领消费者需求。
but,现实是并没有那么多创造性的伟大产品。MVP强调快速迭代和反馈。

Patel: There's been a few instrumental components that have allowed this ecosystem to flourish at Monzo. We've talked about how we compose microservices and how we develop a set of robust libraries.
The other key layer is our core platform. The team we work on focuses on providing components like Kubernetes, and Cassandra, so that we can host and deploy and develop containers. Cassandra for data storage. Etcd for distributed locking. Components like Prometheus for instrumentation.
We provide these components as services so that engineers can focus on building a bank rather than having lots of different teams doing individual operational work with many different components. Even with these components that we've specified, we provide well-defined interfaces and abstractions rather than surfacing the full implementation details about each of these components.
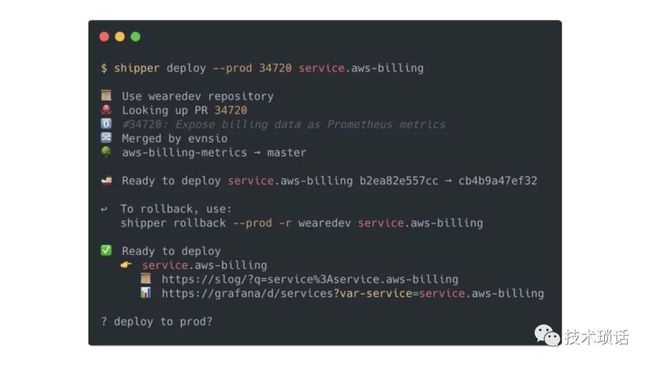
One key superpower we've been able to leverage is reducing the barrier of deployments. Engineers can ship to production from their very first week. Just today, right about now, we would have had hundreds of deployments of various services all across Monzo. Once code goes through automatic validation and gets peer reviewed, and is approved and merged into the mainline, it's ready to be deployed to production. We've built a bespoke deployment tool called Shipper, which handles all of the complexities like rolling deployments in Kubernetes and running migrations in Cassandra.
It deals with services that might look unhappy so that you can roll them back, and deployments going bad. All this means is that we can build and roll out changes in minutes using a single command. Every engineer is empowered to do this at Monzo. Engineers shouldn't be expected to know complex things like Kubernetes and Cassandra. They don't have to write YAML or write CQL commands, which are hand strewn, to deploy their services.

Even really simple things and core things like standardizing service naming. Nobody is deploying a service with innuendo names. Each service is well described in its naming. Service structure, the way we restructure files, where do you put particular files within your code, is all standardized. The vast majority of services use a standardized service generator. All this code is generated up front and the sub-structure is generated up front. No matter what team I go into, I know where I can find the database code. It will be in the dao folder.
I know where I can find the routing logic. It will be in the handler folder. Queue consumers will be in the consumer folder. This allows for much easier collaboration and onboarding for engineers onto different teams.
At Monzo, engineers move around teams really often. We are really a flexible and growing organization. Having this standardization across all the teams is really important. Once you get used to the structure in one area, you can be a power user across the entire repository, across all of our services.


If you're working in a language like Go, you can build parsers and understand your existing code, and extract information from code. Go provides this to you right from the standard library. As we've standardized our service structure, we've been able to build tooling and can operate across all of our services. For example, this tool on-screen called service query, which can print out all of the API endpoints for a given service, and prompt it straight from the code. Even if it's not been well defined in the Protocol Buffers, which is definitely an anti-pattern, it can extract that information directly from the code.
We can use the same tooling to do static analysis and validation when you submit a pull request. That means a cognitive overhead for an engineer to peer review, and make sure that this change is safe and potentially backwards and forwards compatible is all delegated to automated tooling. We've reduced the risk of engineers breaking changes when they are deploying their code. Violations are automatically detected and can be rectified during the pull request

Every single Go service using our libraries gets a wealth of metrics built for free. Engineers can go to a common fully templated dashboard, type in their service name, and within the first minute of deploying a new service, have up to date visualizations and metrics about how many HTTP calls they're making. How many Cassandra calls they might be making. How many locks they are taking, CPU information. A wealth of information. This also feeds into automated alerting. If a team has deployed a service, and has not quite figured out the correct thresholds, they can fall back on automated alerting, which we already have, so that if a service is really degrading and causing potential impact, the automated alerting will catch that beforehand. Alerts are automatically routed to the right team which owns the service. When a service is first built, before it's even merged into the mainline, each service has to have a team owner assigned to it.
This is categorized specifically in a code owner's file, which is monitored and automated by GitHub.
This means that we have good visibility and ownership across our entire set of services.

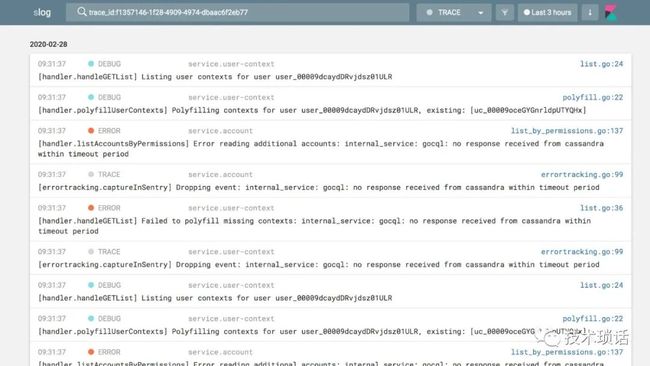
Similarly, we've spent a lot of time on our backend to unify our RPC layer, so when a service calls another service, to communicate with each other. This means that trace IDs and context parameters are parsed across service boundaries. From there, we can use technologies like OpenTracing and OpenTelemetry, and open-source tools like Jaeger to provide rich traces of each hop. Here, you can narrow down how long each hop took, and the dependencies on external services and systems. We've baked in Cassandra integration and etcd integration right into the library so that we can visualize all of that in Jaeger. It's not just about RPCs, you also want to trace your queries to the database, what actual query was made, how long did it take? Sometimes engineers want to follow a request path through service boundaries, and see logs in a unified view. By having consistent trace IDs which are propagated, we can tag logs automatically on our backend, which makes it really easy for querying what happened between service boundaries. You can log information and see in detail what every single request went through.
There is nothing unique about our platform, which makes this exclusive to Monzo. We leverage the same open-source tools like Prometheus, Grafana, The Elastic Stack, and OpenTelemetry to collect, aggregate, and visualize this data. You can do the same on your platform.







Heath: By standardizing on that small set of technology choices, we can, as a group, collectively improve those tools.
Engineers can focus on the business problem at hand.
Our overall underlying systems get progressively better over time. That means we can focus on the business problem. We don't have to think about the underlying infrastructure all the time. At the same time, our platform teams can continuously work on that, and raise that bar of abstraction continuously, so that as we go, things get easier.

Patel: Breaking down the complexity into bite-sized chunks means that each service is simpler and easy to understand. The granularity and ownership of services reduces the contention between teams, while risk is reduced as we can make small, isolated changes to specific sections of our systems. All of this is in aid of reducing the barriers to make changes. It allows us to serve our customers better, which is ultimately what we want to do as an organization. We want engineers to feel empowered to work on new and innovative functionality and deliver a better product to customers.

加入技术琐话粉丝群,公众号回复:技术群。
下载“100页ppt讲清楚云原生 ” ppt,公众号回复:高磊。
下载本ppt,公众号回复:1600。往期推荐:
字节跳动:超复杂调用网下的服务治理新思路
程序员的天花板
蚂蚁P9: 自研分布式数据库OB对HTAP的探索
严重宕机!Facebook服务中断近7小时
深度分析:Facebook大故障究竟是什么原因
……
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。
