c++11线程池的实现原理及回调函数的使用
关于线程池
简单来说就是有一堆已经创建好的线程(最大数目一定),初始时他们都处于空闲状态。当有新的任务进来,从线程池中取出一个空闲的线程处理任务然后当任务处理完成之后,该线程被重新放回到线程池中,供其他的任务使用。当线程池中的线程都在处理任务时,就没有空闲线程供使用,此时,若有新的任务产生,只能等待线程池中有线程结束任务空闲才能执行。
线程池优点
线程本来就是可重用的资源,不需要每次使用时都进行初始化。因此可以采用有限的线程个数处理无限的任务。既可以提高速度和效率,又降低线程频繁创建的开销。比如要异步干的活,就没必要等待。丢到线程池里处理,结果在回调中处理。频繁执行的异步任务,若每次都创建线程势必造成不小的开销。像java中频繁执行的异步任务,就new Therad{}.start(),然后就不管了不是个好的办法,频繁调用可能会触发GC,带来严重的性能问题,类似这种就该使用线程池。
还比如把计算任务都放在主线程进行,那么势必会阻塞主线程的处理流程,无法做到实时处理。使用多线程技术是大家自然而然想到的方案。在上述的场景中必然会频繁的创建和销毁线程,这样的开销相信是不能接受的,此时线程池技术便是很好的选择。
另外在一些高并发的网络应用中,线程池也是常用的技术。陈硕大神推荐的C++多线程服务端编程模式为:one loop per thread + thread pool,通常会有单独的线程负责接受来自客户端的请求,对请求稍作解析后将数据处理的任务提交到专门的计算线程池。
实现原理及思路
大致原理是创建一个类,管理一个任务队列,一个线程队列。然后每次取一个任务分配给一个线程去做,循环往复。任务队列负责存放主线程需要处理的任务,工作线程队列其实是一个死循环,负责从任务队列中取出和运行任务,可以看成是一个生产者和多个消费者的模型。
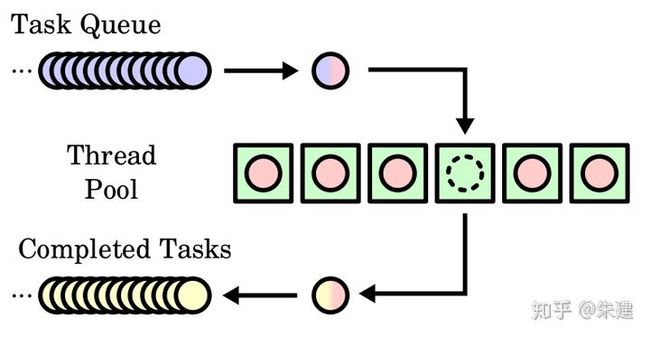
c++11虽然加入了线程库thread,然而 c++ 对于多线程的支持还是比较低级,稍微高级一点的用法都需要自己去实现,还有备受期待的网络库,至今标准库里还没有支持,常用asio替代。感谢网上大神的奉献,这里贴上源码并完善下使用方法,主要是增加了使用示例及回调函数的使用。
使用举例
#include
#include
#include
#include
#include "threadpool.h"
using namespace std;
using namespace std::chrono;
//仿函数示例
struct gfun {
int operator()(int n) {
printf("%d hello, gfun ! %d\n" ,n, std::this_thread::get_id() );
return 42;
}
};
class A {
public:
static std::string Bfun(int n, std::string str, char c) {
std::cout << n << " hello, Bfun ! "<< str.c_str() <<" " << (int)c <<" " << std::this_thread::get_id() << std::endl;
return str;
}
};
int main() {
cout << "hello,this is a test using threadpool" < > results;
//lambada表达式 匿名函数线程中执行
pool.commit([] {
std::cout << "this is running in pool therad " << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
});
//仿函数放到线程池中执行
std::future fg = pool.commit(gfun{},0);
std::future gh = pool.commit(A::Bfun, 999,"mult args", 123);
//回调函数示例,模拟耗时操作,结果回调输出
auto fetchDataFromDB = [](std::string recvdData,std::function cback) {
// Make sure that function takes 5 seconds to complete
std::this_thread::sleep_for(seconds(5));
//Do stuff like creating DB Connection and fetching Data
if(cback != nullptr){
std::string out = "this is from callback ";
cback(out);
}
return "DB_" + recvdData;
};
//模拟,回调
fetchDataFromDB("aaa",[&](std::string &result){
std::cout << "callback result:" << result << std::endl;
return 0;
} );
//把fetchDataFromDB这一IO耗时任务放到线程里异步执行
//
std::future resultFromDB = std::async(std::launch::async, fetchDataFromDB, "Data0",
[&](std::string &result){
std::cout << "callback result from thread:" << result << std::endl;
return 0;
});
//把fetchDataFromDB这一IO耗时操作放到pool中的效果
pool.commit(fetchDataFromDB,"Data1",[&](std::string &result){
std::cout << "callback result from pool thread:" << result << std::endl;
return 0;
});
for(int i = 0; i < 8; ++i) {
results.emplace_back(
pool.commit([i] {
std::cout << "hello " << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "world " << i << std::endl;
return i*i;
})
);
}
for(auto && result: results){
std::cout << result.get() << ' ';
}
std::cout << std::endl;
}
以下是具体实现过程:
#pragma once
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include
#include
#include
#include
//#include
//#include
#include
#include
namespace me
{
using namespace std;
//线程池最大容量,应尽量设小一点
#define THREADPOOL_MAX_NUM 16
//#define THREADPOOL_AUTO_GROW
//线程池,可以提交变参函数或拉姆达表达式的匿名函数执行,可以获取执行返回值
//不直接支持类成员函数, 支持类静态成员函数或全局函数,Opteron()函数等
class ThreadPool
{
using Task = function; //定义类型
vector _pool; //线程池
queue _tasks; //任务队列
mutex _lock; //同步
condition_variable _task_cv; //条件阻塞
atomic _run{ true }; //线程池是否执行
atomic _idlThrNum{ 0 }; //空闲线程数量
public:
inline ThreadPool(unsigned short size = 4) { addThread(size); }
inline ~ThreadPool()
{
_run=false;
_task_cv.notify_all(); // 唤醒所有线程执行
for (thread& thread : _pool) {
//thread.detach(); // 让线程“自生自灭”
if(thread.joinable())
thread.join(); // 等待任务结束, 前提:线程一定会执行完
}
}
public:
// 提交一个任务
// 调用.get()获取返回值会等待任务执行完,获取返回值
// 有两种方法可以实现调用类成员,
// 一种是使用 bind: .commit(std::bind(&Dog::sayHello, &dog));
// 一种是用 mem_fn: .commit(std::mem_fn(&Dog::sayHello), this)
template
auto commit(F&& f, Args&&... args) ->future
{
if (!_run) // stoped ??
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f(args...)); // typename std::result_of::type, 函数 f 的返回值类型
auto task = make_shared>(
bind(forward(f), forward(args)...)
); // 把函数入口及参数,打包(绑定)
future future = task->get_future();
{ // 添加任务到队列
lock_guard lock{ _lock };//对当前块的语句加锁 lock_guard 是 mutex 的 stack 封装类,构造的时候 lock(),析构的时候 unlock()
_tasks.emplace([task](){ // push(Task{...}) 放到队列后面
(*task)();
});
}
#ifdef THREADPOOL_AUTO_GROW
if (_idlThrNum < 1 && _pool.size() < THREADPOOL_MAX_NUM)
addThread(1);
#endif // !THREADPOOL_AUTO_GROW
_task_cv.notify_one(); // 唤醒一个线程执行
return future;
}
//空闲线程数量
int idlCount() { return _idlThrNum; }
//线程数量
int thrCount() { return _pool.size(); }
#ifndef THREADPOOL_AUTO_GROW
private:
#endif // !THREADPOOL_AUTO_GROW
//添加指定数量的线程
void addThread(unsigned short size)
{
for (; _pool.size() < THREADPOOL_MAX_NUM && size > 0; --size)
{ //增加线程数量,但不超过 预定义数量 THREADPOOL_MAX_NUM
_pool.emplace_back( [this]{ //工作线程函数
while (_run)
{
Task task; // 获取一个待执行的 task
{
// unique_lock 相比 lock_guard 的好处是:可以随时 unlock() 和 lock()
unique_lock lock{ _lock };
_task_cv.wait(lock, [this]{
return !_run || !_tasks.empty();
}); // wait 直到有 task
if (!_run && _tasks.empty())
return;
task = move(_tasks.front()); // 按先进先出从队列取一个 task
_tasks.pop();
}
_idlThrNum--;
task();//执行任务
_idlThrNum++;
}
});
_idlThrNum++;
}
}
};
}
#endif //https://github.com/lzpong/
另一种实现
// A simple thread pool class.
// Usage examples:
//
// {
// ThreadPool pool(16); // 16 worker threads.
// for (int i = 0; i < 100; ++i) {
// pool.Schedule([i]() {
// DoSlowExpensiveOperation(i);
// });
// }
//
// // `pool` goes out of scope here - the code will block in the ~ThreadPool
// // destructor until all work is complete.
// }
//
// // TODO(cbraley): Add examples with std::future.
#include
#include
#include
#include
#include
#include
#include
#include
// This file contains macros that we use to workaround some features that aren't
// available in C++11.
// We want to use std::invoke if C++17 is available, and fallback to "hand
// crafted" code if std::invoke isn't available.
//#if __cplusplus >= 201703L
//#define INVOKE_MACRO(CALLABLE, ARGS_TYPE, ARGS) std::invoke(CALLABLE, std::forward(ARGS)...)
//#elif __cplusplus >= 201103L
// Update this with http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2014/n4169.html.
#define INVOKE_MACRO(CALLABLE, ARGS_TYPE, ARGS) CALLABLE(std::forward(ARGS)...)
//#else
//#error ("C++ version is too old! C++98 is not supported.")
//#endif
namespace cb
{
namespace impl
{
// This helper class simply returns a std::function that executes:
// ReturnT x = func();
// promise->set_value(x);
// However, this is tricky in the case where T == void. The code above won't
// compile if ReturnT == void, and neither will
// promise->set_value(func());
// To workaround this, we use a template specialization for the case where
// ReturnT is void. If the "regular void" proposal is accepted, this could be
// simpler:
// http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0146r1.html.
// The non-specialized `FuncWrapper` implementation handles callables that
// return a non-void value.
template
struct FuncWrapper
{
template
std::function GetWrapped(FuncT&& func, std::shared_ptr> promise, ArgsT&&... args)
{
// TODO(cbraley): Capturing by value is inefficient. It would be more
// efficient to move-capture everything, but we can't do this until C++14
// generalized lambda capture is available. Can we use std::bind instead to
// make this more efficient and still use C++11?
return [promise, func, args...]() mutable { promise->set_value(INVOKE_MACRO(func, ArgsT, args)); };
}
};
template
void InvokeVoidRet(FuncT&& func, std::shared_ptr> promise, ArgsT&&... args)
{
INVOKE_MACRO(func, ArgsT, args);
promise->set_value();
}
// This `FuncWrapper` specialization handles callables that return void.
template <>
struct FuncWrapper
{
template
std::function GetWrapped(FuncT&& func, std::shared_ptr> promise, ArgsT&&... args)
{
return [promise, func, args...]() mutable {
INVOKE_MACRO(func, ArgsT, args);
promise->set_value();
};
}
};
} // namespace impl
class ThreadPool
{
public:
// Create a thread pool with `num_workers` dedicated worker threads.
explicit ThreadPool(int num_workers) : num_workers_(num_workers)
{
assert(num_workers_ > 0);
// TODO(cbraley): Handle thread construction exceptions.
workers_.reserve(num_workers);
for (int i = 0; i < num_workers; ++i)
{
workers_.emplace_back(&ThreadPool::ThreadLoop, this);
}
}
// Default construction is disallowed.
ThreadPool() = delete;
// Get the number of logical cores on the CPU. This is implemented using
// std::thread::hardware_concurrency().
// https://en.cppreference.com/w/cpp/thread/thread/hardware_concurrency
static unsigned int GetNumLogicalCores()
{
// TODO(cbraley): Apparently this is broken in some older stdlib
// implementations?
const unsigned int dflt = std::thread::hardware_concurrency();
if (dflt == 0)
{
// TODO(cbraley): Return some error code instead.
return 16;
}
else
{
return dflt;
}
}
// The `ThreadPool` destructor blocks until all outstanding work is complete.
~ThreadPool()
{
// TODO(cbraley): The current thread could help out to drain the work_ queue
// faster - for example, if there is work that hasn't yet been scheduled this
// thread could "pitch in" to help finish faster.
{
std::lock_guard scoped_lock(mu_);
exit_ = true;
}
condvar_.notify_all(); // Tell *all* workers we are ready.
for (std::thread& thread : workers_)
{
thread.join();
}
}
// No copying, assigning, or std::move-ing.
ThreadPool& operator=(const ThreadPool&) = delete;
ThreadPool(const ThreadPool&) = delete;
ThreadPool(ThreadPool&&) = delete;
ThreadPool& operator=(ThreadPool&&) = delete;
// Add the function `func` to the thread pool. `func` will be executed at some
// point in the future on an arbitrary thread.
void Schedule(std::function func)
{
ScheduleAndGetFuture(std::move(func)); // We ignore the returned std::future.
}
// Add `func` to the thread pool, and return a std::future that can be used to
// access the function's return value.
//
// *** Usage example ***
// Don't be alarmed by this function's tricky looking signature - this is
// very easy to use. Here's an example:
//
// int ComputeSum(std::vector& values) {
// int sum = 0;
// for (const int& v : values) {
// sum += v;
// }
// return sum;
// }
//
// ThreadPool pool = ...;
// std::vector numbers = ...;
//
// std::future sum_future = ScheduleAndGetFuture(
// []() {
// return ComputeSum(numbers);
// });
//
// // Do other work...
//
// std::cout << "The sum is " << sum_future.get() << std::endl;
//
// *** Details ***
// Given a callable `func` that returns a value of type `RetT`, this
// function returns a std::future that can be used to access
// `func`'s results.
template
auto ScheduleAndGetFuture(FuncT&& func, ArgsT&&... args) -> std::future
{
using ReturnT = decltype(INVOKE_MACRO(func, ArgsT, args));
// We are only allocating this std::promise in a shared_ptr because
// std::promise is non-copyable.
std::shared_ptr> promise = std::make_shared>();
std::future ret_future = promise->get_future();
impl::FuncWrapper func_wrapper;
std::function wrapped_func =
func_wrapper.GetWrapped(std::forward(func), std::move(promise), std::forward(args)...);
// Acquire the lock, and then push the WorkItem onto the queue.
{
std::lock_guard scoped_lock(mu_);
WorkItem work;
work.func = std::move(wrapped_func);
work_.emplace(std::move(work));
}
condvar_.notify_one(); // Tell one worker we are ready.
return ret_future;
}
// Wait for all outstanding work to be completed.
void Wait()
{
std::unique_lock lock(mu_);
if (!work_.empty())
{
work_done_condvar_.wait(lock, [this] { return work_.empty(); });
}
}
// Return the number of outstanding functions to be executed.
int OutstandingWorkSize() const
{
std::lock_guard scoped_lock(mu_);
return work_.size();
}
// Return the number of threads in the pool.
int NumWorkers() const { return num_workers_; }
void SetWorkDoneCallback(std::function func) { work_done_callback_ = std::move(func); }
private:
void ThreadLoop()
{
// Wait until the ThreadPool sends us work.
while (true)
{
WorkItem work_item;
int prev_work_size = -1;
{
std::unique_lock lock(mu_);
condvar_.wait(lock, [this] { return exit_ || (!work_.empty()); });
// ...after the wait(), we hold the lock.
// If all the work is done and exit_ is true, break out of the loop.
if (exit_ && work_.empty())
{
break;
}
// Pop the work off of the queue - we are careful to execute the
// work_item.func callback only after we have released the lock.
prev_work_size = work_.size();
work_item = std::move(work_.front());
work_.pop();
}
// We are careful to do the work without the lock held!
// TODO(cbraley): Handle exceptions properly.
work_item.func(); // Do work.
if (work_done_callback_)
{
work_done_callback_(prev_work_size - 1);
}
// Notify a condvar is all work is done.
{
std::unique_lock lock(mu_);
if (work_.empty() && prev_work_size == 1)
{
work_done_condvar_.notify_all();
}
}
}
}
// Number of worker threads - fixed at construction time.
int num_workers_;
// The destructor sets `exit_` to true and then notifies all workers. `exit_`
// causes each thread to break out of their work loop.
bool exit_ = false;
mutable std::mutex mu_;
// Work queue. Guarded by `mu_`.
struct WorkItem
{
std::function func;
};
std::queue work_;
// Condition variable used to notify worker threads that new work is
// available.
std::condition_variable condvar_;
// Worker threads.
std::vector workers_;
// Condition variable used to notify that all work is complete - the work
// queue has "run dry".
std::condition_variable work_done_condvar_;
// Whenever a work item is complete, we call this callback. If this is empty,
// nothing is done.
std::function work_done_callback_;
};
} // namespace cb 引用:
基于C++11的线程池(threadpool),简洁且可以带任意多的参数 - _Ong - 博客园
c++简单线程池实现 - 渣码农 - 博客园
C++实现线程池_折线式成长的博客-CSDN博客_c++ 线程池
基于C++11实现线程池的工作原理 - 靑い空゛ - 博客园
线程池的C++实现 - 知乎