spring全家桶
spring全家桶
- 1、spring是一个容器、生态、框架
-
- 1.1IOC容器(存放bean对象)
-
- 1.1.2 bean生命周期(复杂)
- 1.1.3 bean生命周期(简单):
- 1.2 AOP面向切面编程
-
- 1.2.1 相关概念:
- 1.3 JdbcTemplate
- 1.4 事物
-
- 1.4.1、事物的特性
-
- 1.4.1.1、原子性(Atomicity):
- 1.4.1.2、一致性(Consistency):
- 1.4.1.3、隔离性(Isolation):
- 1.4.1.4、持久性(Durability):
- 1.4.2、spring事物配置方式
- 1.4.3、事物的隔离级别
- 1.5 循环依赖
-
- 1.5.1、检测是否存在循环依赖
- 1.5.2、spring解决循环依赖
- 2、SpringMVC
-
- 2.1、springMVC简介
-
- 2.1.1、运行原理
- 2.1.2、SpringMVC接口解释
- 2.1.3、DispatcherServlet:
- 3、springBoot
-
- 3.1springboot简介
- 3.2、特点
- 4、springCloud
-
- 4.1、优点:
- 4.2、Spring Cloud 模块的相关介绍:
- 4.2.1、 服务治理
- 5、SSM
1、spring是一个容器、生态、框架
Spring框架为开发提供了一系列的解决方案,比如利用控制反转的核心特性,并通过依赖注入实现控制反转来实现管理对象生命周期容器化,利用面向切面编程进行声明式的事务管理,整合多种持久化技术管理数据访问,提供大量优秀的Web框架方便开发等等。Spring框架具有控制反转(IOC)特性,IOC旨在方便项目维护和测试,它提供了一种通过Java的反射机制对Java对象进行统一的配置和管理的方法。Spring框架利用容器管理对象的生命周期,容器可以通过扫描XML文件或类上特定Java注解来配置对象,开发者可以通过依赖查找或依赖注入来获得对象。Spring框架具有面向切面编程(AOP)框架,SpringAOP框架基于代理模式,同时运行时可配置;AOP框架主要针对模块之间的交叉关注点进行模块化。Spring框架下的事务管理、远程访问等功能均可以通过使用SpringAOP技术实现。
spring首先是一个框架,在我们整个开发流程中,所有的框架生产几乎全都依赖于spring,spring帮我们起到了一个IOC容器的作用,用来承载整体的bean对象,帮我们进行了对象的创建到销毁的整个生命周期的管理。在使用spring的时候可以使用配置文件也可以使用注解的方式来进行相关实现,在程序启动后,把配置文件或者注解定义好的那些bean对象转换成beanDefination,要完成整个beanDefination的解析到加载的过程,获得完整的对象之后,下一步要对beanDefination进行实例化操作,在进行实例化的时候最简单的方式是使用反射的方式来创建对象,当对象创建完成之后,之后要实现Aware、BeanPostProcessor接口的一些操作,初始化对象的一些操作
1.1IOC容器(存放bean对象)
IOC(Inversion of Control):
IOC容器控制管理bean对象,实现解耦。
控制翻转,其根本是依赖注入(Dependecy Injection),不会直接创建对象,只是把对象声明出来,在代码 中不直接与对象和服务进行连接,但是在配置文件中描述了哪一项组件需要哪一项服务,容器将他们组合起来。在一般的IOC场景中容器创建了所有的对象,并设置了必要的属性将他们联系在一起,等到需要使用的时候才把他们声明出来,使用注解就更方便了,容器会自动根据注
解把对象组合起来。
是我们在使用spring中最重要的一个方面,spring容器里面放的是一个一个的bean对象,spring在启动时通过BeanDefinitionReader读取XML配置文件或者注解(bean的定义信息)获取bean对象:
下图说明:
BeanDefinitionReader将配置文件信息解析成BeanDefinition(有$占位符),
BeanFactoryPostProcessor将此信息在解析成完整的BeanDefinition对象(将信息传入,去掉$占位符)

1.1.2 bean生命周期(复杂)
1)Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化,在堆开辟新空间,使用反射实现对象的实例化
2)Bean实例化后对将Bean的引入和值注入到Bean的属性中
3)如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
4)如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
5)如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
6)如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
7)如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
8)如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
9)此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
10)如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
参考文档:https://www.cnblogs.com/javazhiyin/p/10905294.html
1.1.3 bean生命周期(简单):
实例化 Instantiation
属性赋值 Populate
初始化 Initialization
销毁 Destruction
1)实例化(Instantiation)
//实例化是指Bean 从Bean到Object
Object wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
2)属性赋值(Populate)
3)初始化(Initialization)
初始化前: org.springFrameWork.beans.factory.config.BeanPostProcessor#postProcessBeforeInitialization
初始化中: org.springFrameWork.bean.InitializingBean#afterPropertiesSet
初始化后:org.springFrameWork.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization
4)销毁
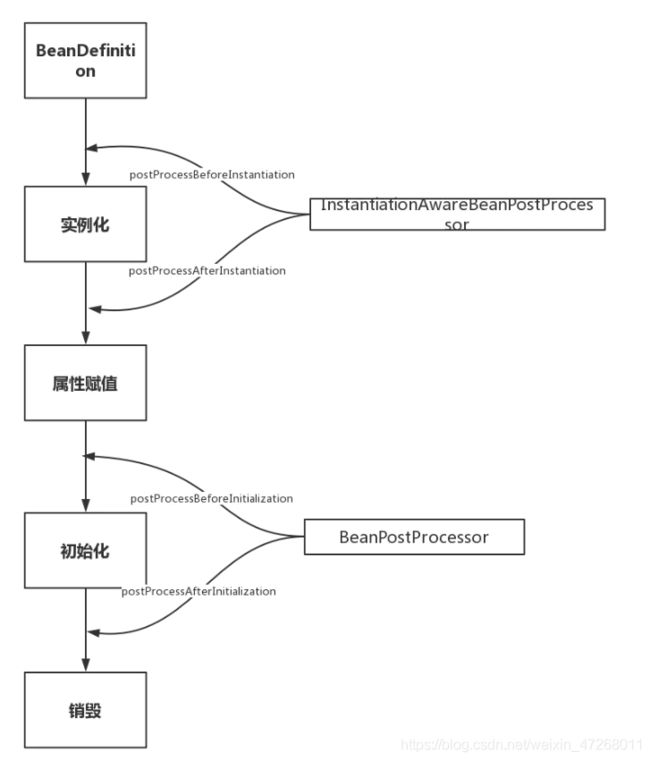
参考文档:https://www.jianshu.com/p/1dec08d290c1
1.2 AOP面向切面编程
AOP:面向切面编程,底层实现是动态代理(JDK、CGlib)
web层级设计中,web层->网关层->服务层->数据层,每一层之间也是一个切面。编程中,对象与对象之间,方法与方法之间,模块与模块之间都是一个个切面。
将方法注入到接口调用的某个地方(切点)。
1.2.1 相关概念:
1)Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些 Pointcut 以及相应的 Advice。
2)Joint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point。
3)Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方。
4)Advice(增强):Advice 定义了在 Pointcut 里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。
5)Target(目标对象):织入 Advice 的目标对象.。
6)Weaving(织入):将 Aspect 和其他对象连接起来, 并创建 Adviced object 的过程
参考文档:https://blog.csdn.net/q982151756/article/details/80513340
1.3 JdbcTemplate
JdbcTemplate是Spring对JDBC的封装,目的是使JDBC更加易于使用。JdbcTemplate是Spring的一部分。JdbcTemplate处理了资源的建立和释放。
在JdbcTemplate中执行SQL语句的方法大致分为3类:
1)execute:可以执行所有SQL语句,一般用于执行DDL语句。
2)update:用于执行INSERT、UPDATE、DELETE等DML语句。
3)queryXxx:用于DQL数据查询语句。
1.4 事物
1.4.1、事物的特性
1.4.1.1、原子性(Atomicity):
事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
1.4.1.2、一致性(Consistency):
一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
1.4.1.3、隔离性(Isolation):
可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
1.4.1.4、持久性(Durability):
一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
1.4.2、spring事物配置方式
1)编程式事物管理:是侵入性事务管理,使用TransactionTemplate或者直接使用PlatformTransactionManager,对于编程式事务管理,Spring推荐使用TransactionTemplate。
2)声明式事物管理:建立在AOP之上,其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,执行完目标方法之后根据执行的情况提交或者回滚。
声明式事务管理要优于编程式事务管理:声明式事务属于无侵入式,不会影响业务逻辑的实现,只需要在配置文件中做相关的事务规则声明或者通过注解的方式,便可以将事务规则应用到业务逻辑中。
1.4.3、事物的隔离级别
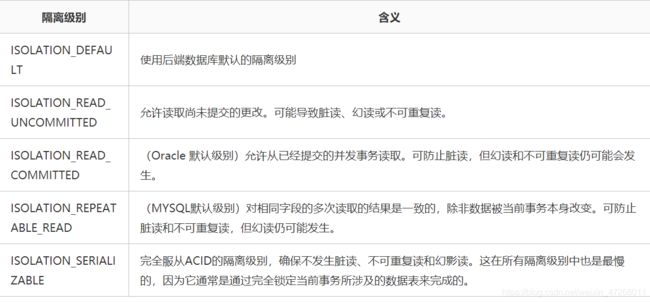
参考文档:https://www.cnblogs.com/mseddl/p/11577846.html
1.5 循环依赖
循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。
Spring中循环依赖场景有:
(1)构造器的循环依赖
(2)field属性的循环依赖。
1.5.1、检测是否存在循环依赖
Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
1.5.2、spring解决循环依赖
Spring为了解决单例的循环依赖问题,使用了三级缓存。
这三级缓存分别指:
singletonFactories : 单例对象工厂的cache
earlySingletonObjects :提前暴光的单例对象的Cache
singletonObjects:单例对象的cache。
参考文档:https://blog.csdn.net/u010853261/article/details/77940767
2、SpringMVC
2.1、springMVC简介
M:model,模型层,模型就是数据
V:view,网页、jsp,显示数据
C:controller,控制层,控制器的作用就是把不同的数据(Model),显示在不同的视图(View)上,Servlet 扮演的就是这样的角色。
Spring MVC主要由DispatcherServlet、处理器映射、处理器(控制器)、视图解析器、视图组成。
他的两个核心是两个核心:
1)处理器映射:选择使用哪个控制器来处理请求
2)视图解析器:选择结果应该如何渲染
2.1.1、运行原理

(1) Http请求:客户端请求提交到DispatcherServlet。
(2) 寻找处理器:由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller。
(3) 调用处理器:DispatcherServlet将请求提交到Controller。
(4)调用业务处理和返回结果:Controller调用业务逻辑处理后,返回ModelAndView。
(5)处理视图映射并返回模型: DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图。
(6) Http响应:视图负责将结果显示到客户端。
2.1.2、SpringMVC接口解释
(1)DispatcherServlet接口:
Spring提供的前端控制器,所有的请求都有经过它来统一分发。在DispatcherServlet将请求分发给Spring Controller之前,需要借助于Spring提供的HandlerMapping定位到具体的Controller。
(2)HandlerMapping接口:
能够完成客户请求到Controller映射。
(3)Controller接口:
需要为并发用户处理上述请求,因此实现Controller接口时,必须保证线程安全并且可重用。
Controller将处理用户请求,这和Struts Action扮演的角色是一致的。一旦Controller处理完用户请求,则返回ModelAndView对象给DispatcherServlet前端控制器,ModelAndView中包含了模型(Model)和视图(View)。
从宏观角度考虑,DispatcherServlet是整个Web应用的控制器;从微观考虑,Controller是单个Http请求处理过程中的控制器,而ModelAndView是Http请求过程中返回的模型(Model)和视图(View)。
(4)ViewResolver接口:
Spring提供的视图解析器(ViewResolver)在Web应用中查找View对象,从而将相应结果渲染给客户。
2.1.3、DispatcherServlet:
是整个Spring MVC的核心。它负责接收HTTP请求组织协调Spring MVC的各个组成部分。其主要工作有以下三项:
(1)截获符合特定格式的URL请求。
(2)初始化DispatcherServlet上下文对应WebApplicationContext,并将其与业务层、持久化层的WebApplicationContext建立关联。
(3)初始化Spring MVC的各个组成组件,并装配到DispatcherServlet中。
参考文档:https://blog.csdn.net/jianyuerensheng/article/details/51258942
3、springBoot
3.1springboot简介
用来简化spring初始搭建的过程,将配置文件转换成注解的形式,方便迅速。Spring Boot 提供了大量开箱即用(out-of-the-box)的依赖模块,例如 spring-boot-starter-redis、spring-boot-starter-data-mongodb 和 spring-boot-starter-data-elasticsearch 等。这些依赖模块为 Spring Boot 应用提供了大量的自动配置,使得 Spring Boot 应用只需要非常少量的配置甚至零配置,便可以运行起来。
3.2、特点
1)独立运行的 Spring 项目
Spring Boot 可以以 jar 包的形式独立运行,Spring Boot 项目只需通过命令“ java–jar xx.jar” 即可运行。
2) 内嵌 Servlet 容器
Spring Boot 使用嵌入式的 Servlet 容器(例如 Tomcat、Jetty 或者 Undertow 等),应用无需打成 WAR 包 。
3) 提供 starter 简化 Maven 配置
Spring Boot 提供了一系列的“starter”项目对象模型(POMS)来简化 Maven 配置。
4) 提供了大量的自动配置
Spring Boot 提供了大量的默认自动配置,来简化项目的开发,开发人员也通过配置文件修改默认配置。
5) 自带应用监控
Spring Boot 可以对正在运行的项目提供监控。
6) 无代码生成和 xml 配置
Spring Boot 不需要任何 xml 配置即可实现 Spring 的所有配置。
参考文档:http://c.biancheng.net/spring_boot/overview.html
4、springCloud
Spring Cloud 是一系列框架的有序集合,它利用 Spring Boot 的开发便利性简化了分布式系统的开发,比如服务发现、服务网关、服务路由、链路追踪等。Spring Cloud 并不重复造轮子,而是将市面上开发得比较好的模块集成进去,进行封装,从而减少了各模块的开发成本。换句话说:Spring Cloud 提供了构建分布式系统所需的“全家桶”。
4.1、优点:
1)集大成者,Spring Cloud 包含了微服务架构的方方面面。
2)约定优于配置,基于注解,没有配置文件。
3)轻量级组件,Spring Cloud 整合的组件大多比较轻量级,且都是各自领域的佼佼者。
4)开发简便,Spring Cloud 对各个组件进行了大量的封装,从而简化了开发。
5)开发灵活,Spring Cloud 的组件都是解耦的,开发人员可以灵活按需选择组件。
4.2、Spring Cloud 模块的相关介绍:
Eureka:服务注册中心,用于服务管理。
Ribbon:基于客户端的负载均衡组件,默认的负载策略是轮询。
Hystrix:容错框架,能够防止服务的雪崩效应。
Feign:Web 服务客户端,能够简化 HTTP 接口的调用。
Zuul:核心是过滤器,API 网关,提供路由转发、请求过滤等功能,是一个基于 JVM 路由和服务端的负载均衡器。
Config:分布式配置管理。
Sleuth:服务跟踪。
Stream:构建消息驱动的微服务应用程序的框架。
Bus:消息代理的集群消息总线。
4.2.1、 服务治理
Eureka 和 Zookeeper 区别:
Eureka 是基于 AP 原则构建的,而 ZooKeeper 是基于 CP 原则构建的。
注:
在分布式系统领域有个著名的 CAP 定理,即 C 为数据一致性;A 为服务可用性;P 为服务对网络分区故障的容错性。这三个特性在任何分布式系统中都不能同时满足,最多同时满足两个。
服务治理就是服务的自动化管理,其核心是服务的自动注册与发现
1)服务注册:服务实例将自身服务信息注册到注册中心
2)服务发现:服务实例通过注册中心,获取注册到其中的服务实例的信息,通过这些信息去请求题目提供的服务
3)服务剔除:服务注册中心将出问题的服务自动剔除可使用服务列表,使其不会被调用
参考文档:http://c.biancheng.net/spring_cloud/
5、SSM
Java 企业开发框架 SSM,即 Spring、SpringMVC、MyBatis 。
Spring框架:是一个轻量级 Java 开发框架,主要是为了解决企业应用开发的复杂性而创建的。
SpringMVC框架:SpringMVC 分离了 控制器、模型对象、分派器,让我们更容易进行开发定制
MyBatis框架:是一个 Java 持久层框架,用于操作数据库,消除了几乎所有的 JDBC 代码,使用简单的 XML 或 注解即可完成数据库操作。