1.27.Flink实时性、容错机制、窗口等介绍\内幕\作业调度\JobManager数据结构\1.29.Flink和Hive整合\支持的Hive版本\使用 Flink 提供的 Hive jar
1.27.Flink实时性、容错机制、窗口等介绍
1.27.1.问题导读
1.28.内幕
1.28.1.作业调度
1.28.1.1.调度
1.28.1.2.JobManager数据结构
1.29.Flink和Hive整合
1.29.1.概述
1.29.2.支持的Hive版本
1.29.3.依赖项
1.29.3.1.使用 Flink 提供的 Hive jar
1.29.3.2.用户定义的依赖项
1.29.3.3.Maven依赖
1.29.3.4.连接到Hive
1.27.Flink实时性、容错机制、窗口等介绍
1.27.1.问题导读
1.为什么flink实时性好?
2.flink通过什么机制保证数据既不重复,也不丢失?
3.flink采用什么机制通信?
4.flink有哪些窗口,他们的作用是什么?
https://www.aboutyun.com/forum.php?mod=viewthread&tid=25540
1.28.内幕
1.28.1.作业调度
1.28.1.1.调度
Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并行度为 n 的 ReduceFunction。需要注意的是 Flink 经常并发执行连续的 task,不仅在流式作业中到处都是,在批量作业中也很常见。
下图很好的阐释了这一点,一个由数据源、MapFunction 和 ReduceFunction 组成的 Flink 作业,其中数据源和 MapFunction 的并行度为 4 ,ReduceFunction 的并行度为 3 。流水线由一系列的 Source - Map - Reduce 组成,运行在 2 个 TaskManager 组成的集群上,每个TaskManager包含3个 slot,整个作业的运行如下图所示。
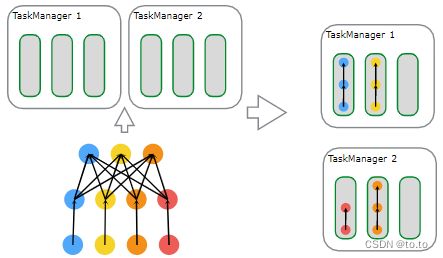
Flink 内部通过 SlotSharingGroup 和 CoLocationGroup 来定义哪些 task 可以共享一个 slot, 哪些 task 必须严格放到同一个 slot。
1.28.1.2.JobManager数据结构
在作业执行期间,JobManager 会持续跟踪各个 task,决定何时调度下一个或一组 task,处理已完成的 task 或执行失败的情况。
JobManager 会接收到一个 JobGraph,用来描述由多个算子顶点 (JobVertex) 组成的数据流图,以及中间结果数据 (IntermediateDataSet)。每个算子都有自己的可配置属性,比如并行度和运行的代码。除此之外,JobGraph 还包含算子代码执行所必须的依赖库。
JobManager 会将 JobGraph 转换成 ExecutionGraph。可以将 ExecutionGraph 理解为并行版本的 JobGraph,对于每一个顶点 JobVertex,它的每个并行子 task 都有一个 ExecutionVertex。一个并行度为 100 的算子会有 1 个 JobVertext 和 100 个 ExecutionVertex。ExecutionVertex 会跟踪子 task 的执行状态。 同一个 JobVertext 的所有 ExecutionVertex 都通过 ExecutionJobVertex 来持有,并跟踪整个算子的运行状态。ExecutionGraph 除了这些顶点,还包含中间数据结果和分片情况 IntermediateResult 和 IntermediateResultPartition。前者跟踪中间结果的状态,后者跟踪每个分片的状态。
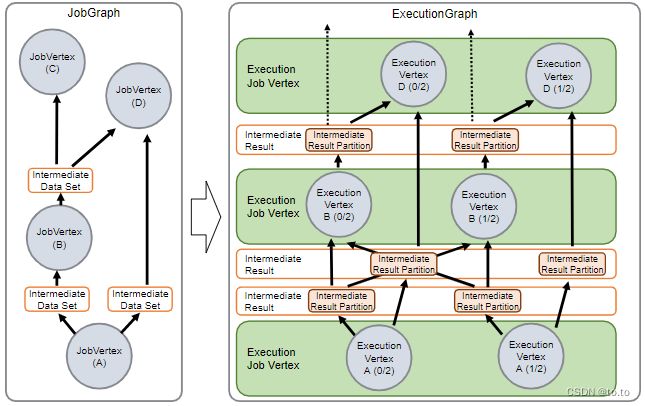
每个 ExecutionGraph 都有一个与之相关的作业状态信息,用来描述当前的作业执行状态。
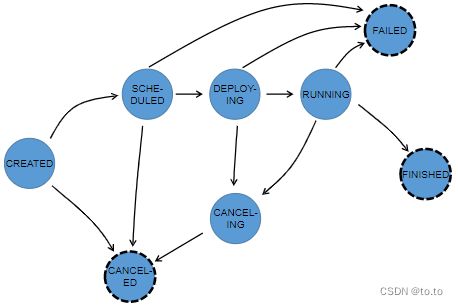
Flink 作业刚开始会处于 created 状态,然后切换到 running 状态,当所有任务都执行完之后会切换到 finished 状态。如果遇到失败的话,作业首先切换到 failing 状态以便取消所有正在运行的 task。如果所有 job 节点都到达最终状态并且 job 无法重启, 那么 job 进入 failed 状态。如果作业可以重启,那么就会进入到 restarting 状态,当作业彻底重启之后会进入到 created 状态。
如果用户取消了 job 话,它会进入到 cancelling 状态,并取消所有正在运行的 task。当所有正在运行的 task 进入到最终状态的时候,job 进入 cancelled 状态。
Finished、canceled 和 failed 会导致全局的终结状态,并且触发作业的清理。跟这些状态不同,suspended 状态只是一个局部的终结。局部的终结意味着作业的执行已经被对应的 JobManager 终结,但是集群中另外的 JobManager 依然可以从高可用存储里获取作业信息并重启。因此一个处于 suspended 状态的作业不会被彻底清理掉。

在整个ExecutionGraph 执行期间,每个并行 task 都会经历多个阶段,从 created 状态到 finished 或 failed。下图展示了各种状态以及他们之间的转换关系。由于一个task 可能会被执行多次(比如在异常恢复时),ExecutionVertex 的执行是由 Execution 来跟踪的,每个 ExecutionVertex 会记录当前的执行,以及之前的执行。
1.29.Flink和Hive整合
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connectors/hive/
1.29.1.概述
Apache Hive 已经成为了数据仓库生态系统中的核心。 它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样它也是一个数据管理平台,可用于发现,定义,和演化数据。
Flink 与 Hive 的集成包含两个层面。
一是利用了 Hive 的 MetaStore 作为持久化的 Catalog,用户可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。 例如,用户可以使用HiveCatalog将其 Kafka 表或 Elasticsearch 表存储在 Hive Metastore 中,并后续在 SQL 查询中重新使用它们。
二是利用 Flink 来读写 Hive 的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive 数仓。 您不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
1.29.2.支持的Hive版本
Flink 支持一下的 Hive 版本。
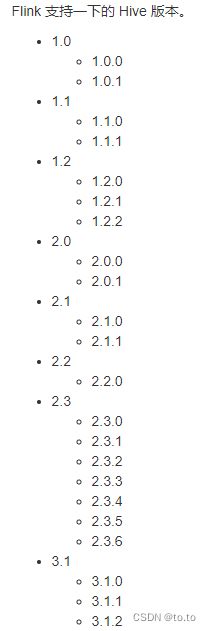
请注意,某些功能是否可用取决于您使用的 Hive 版本,这些限制不是由 Flink 所引起的:
Hive 内置函数在使用 Hive-1.2.0 及更高版本时支持。
列约束,也就是 PRIMARY KEY 和 NOT NULL,在使用 Hive-3.1.0 及更高版本时支持。
更改表的统计信息,在使用 Hive-1.2.0 及更高版本时支持。
DATE列统计信息,在使用 Hive-1.2.0 及更高版时支持。
使用 Hive-2.0.x 版本时不支持写入ORC表。
1.29.3.依赖项
要与Hive集成,您需要在Flink下的/lib/目录中添加一些额外的依赖包, 以便通过 Table API 或 SQL Client 与 Hive 进行交互。 或者,您可以将这些依赖项放在专用文件夹中,并分别使用 Table API 程序或 SQL Client 的-C或-l选项将它们添加到 classpath 中。
Apache Hive 是基于 Hadoop 之上构建的, 首先您需要 Hadoop 的依赖,请参考 Providing Hadoop classes:
export HADOOP_CLASSPATH=hadoop classpath
有两种添加 Hive 依赖项的方法。第一种是使用 Flink 提供的 Hive Jar包。您可以根据使用的 Metastore 的版本来选择对应的 Hive jar。第二个方式是分别添加每个所需的 jar 包。如果您使用的 Hive 版本尚未在此处列出,则第二种方法会更适合。
注意:建议您优先使用 Flink 提供的 Hive jar 包。仅在 Flink 提供的 Hive jar 不满足您的需求时,再考虑使用分开添加 jar 包的方式。
1.29.3.1.使用 Flink 提供的 Hive jar
下表列出了所有可用的 Hive jar。您可以选择一个并放在 Flink 发行版的/lib/ 目录中。

1.29.3.2.用户定义的依赖项
您可以在下方找到不同Hive主版本所需要的依赖项。
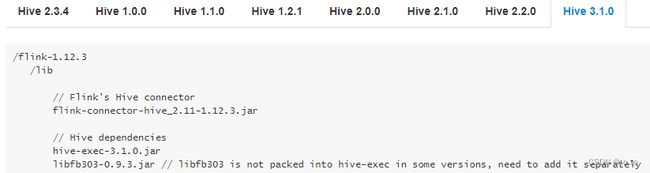
在内部使用过程中,hive是Ambari+hdp中的集成好的,所以可以将hive-exec,libfb303的包拷贝到flink的安装目录下的lib目录中。截图如下:
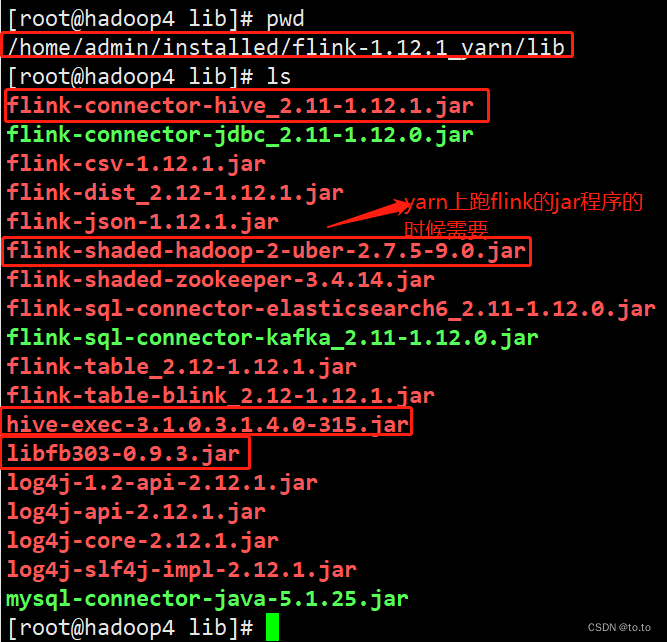
即:
flink-connector-hive_2.11-1.12.1.jar
flink-shaded-hadoop-2-uber-2.7.5-9.0.jar
hive-exec-3.1.0.3.1.4.0-315.jar
libfb303-0.9.3.jar
1.29.3.3.Maven依赖
如果您在构建自己的应用程序,则需要在 mvn 文件中添加以下依赖项。 您应该在运行时添加以上的这些依赖项,而不要在已生成的 jar 文件中去包含它们。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-hive_2.11artifactId>
<version>1.12.3version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.11artifactId>
<version>1.12.3version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>${hive.version}version>
<scope>providedscope>
dependency>
1.29.3.4.连接到Hive
通过TableEnvironment或者YAML配置,使用Catalog 接口 和 HiveCatalog连接到现有的 Hive 集群。
请注意,虽然 HiveCatalog 不需要特定的 planner,但读写Hive表仅适用于 Blink planner。因此,强烈建议您在连接到 Hive 仓库时使用 Blink planner。
以下是如何连接到Hive的示例:
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/opt/hive-conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
// set the HiveCatalog as the current catalog of the session
tableEnv.useCatalog("myhive");
下表列出了通过 YAML 文件或 DDL 定义 HiveCatalog 时所支持的参数。
| 参数 | 必选 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| type | 是 | (无) | String | Catalog 的类型。 创建 HiveCatalog 时,该参数必须设置为’hive’。 |
| name | 是 | (无) | String | Catalog 的名字。仅在使用 YAML file 时需要指定。 |
| hive-conf-dir | 否 | (无) | String | 指向包含 hive-site.xml 目录的 URI。 该 URI 必须是 Hadoop 文件系统所支持的类型。 如果指定一个相对 URI,即不包含 scheme,则默认为本地文件系统。如果该参数没有指定,我们会在 class path 下查找hive-site.xml。 |
| default-database | 否 | default | String | 当一个catalog被设为当前catalog时,所使用的默认当前database。 |
| hive-version | 否 | (无) | String | HiveCatalog 能够自动检测使用的 Hive 版本。我们建议不要手动设置 Hive 版本,除非自动检测机制失败。 |
| hadoop-conf-dir | 否 | (无) | String | Hadoop配置文件目录的路径。目前仅支持本地文件系统路径。我们推荐使用 HADOOP_CONF_DIR环境变量来指定 Hadoop 配置。因此仅在环境变量不满足您的需求时再考虑使用该参数,例如当您希望为每个HiveCatalog单独设置 Hadoop配置时。 |