redis
关系型数据库
- 一、定义
-
- 区别
- redis
-
- 定义
- redis优点
- redis为什么这么快
- 总结
-
- 非关系数据库
- 关系型数据库
一、定义
一个结构化的数据库,创建在关系模型基础上
一般面向记录
Oracle、MySQL、SQL Server、Microsoft Access、DB2
非关系型数据库
除了主流的关系型数据库外的数据库,都认为是非关系型
Redis、MongBD、Hbase、CouhDB:
区别
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。关系型数据天然就是表格式的,因此存储在数据表
和列中。数据表可以彼此关联协作存储,也很容易提取数据。
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)展方式不同
sQL和NosQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
要支持更多并发量,sQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多克服。虽然sgL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限个表,这都需要通过提高计算机性能来。
而NosgL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
关系:纵向比如说硬件中添加内存
非关:横向天然分布式
3、对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的sQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NosL,数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
#非关系型数据库产生背景
可用于应对web2.0纯动态网站类型的三高问题。
(1) High performance——对数据库高并发读写需求
(2) Huge storage——对海量数据高效存储与访问需求
(3) High scalability && High Availability—对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给web2.o的数据库发展带来新的思路。让关系数据库关注在关系上,非关系型数据库关注在存储上。例如,在读写分离的MysQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
MySQL 高热数据—》redis
web—>redis—>mysql
cpu---->内存/缓存---->磁盘
关系非关系相结合
redis
定义
Redis (远程字典服务器)是一个开源的、使用c语言编写的NosQL数据库。Redis
基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。即:在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若cPu资源比较紧张,采用单进程即可。
redis优点
(1)具有极高的数据读写速度:数据读取的速度最高可达到110000 次/s,数据写入速度最高可达到 81000次/s。
(2)支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Sorted Sets等数据类型操作。
(3)支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性: Redis 所有操作都是原子性的。
(5)支持数据备份:即master-salve模式的数据备份。
Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。除此之外,Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录。
redis为什么这么快
1.Redis是一款纯内存结构,避免了磁盘I/o等耗时操作。
2、Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
3、采用了i/o多路复用机制,大大提升了并发效率。
注:在Redis 6.0
中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的
总结
非关系数据库
1.数据保存在缓存中,利于读取速度/查询数据
2.架构位置灵活
3.分布式、扩展性高
关系型数据库
1.安全性高(持久化)
2.事务处理能力强
3.任务控制能力强
4.可以做日志备份、恢复、容灾能力强
关系数据库
实例----》数据库----》表(table)----》记录行(row)、数据字段(column)------》存储数据
非关系型数据库
实例----》数据库------》集合-----》(collection)------》键值对(key-value)
注意:非关系型数据库不需要手动建数据库和集合
redis基于内存运行并支持持久化
用key-value键值对存储形式
优点
具有极高的数据读写速度
支持丰富的数据类型·
支持数据的持久化·
原子性
支持数据备份
yum -y install gcc gcc-c++ make

tar -xf redis-5.0.7.tar.gz -c /opt/
cd redis-5.0.7

make & make install

配置文件
vim /etc/redis/6379.conf
redis-cli -h 192.168.10.23 -p 6379

redis-cli -h 127.0.0.1

redis-bbenchmark -h 192.168.10.23 -p 6379 -c 110 -n 100000

redis-benchmark -h 192.168.10.23 -p 6379 -q -d 100

set:存放数据,命令格式为set key value
get:获取数据,命令格式为get key
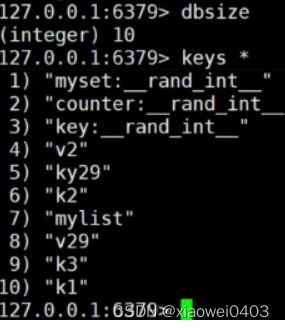
keys * #查看当前数据库中所有键
keys v* #查看当前数据库中以v开头的数据
keys v? #查看当前数据库中以v开头后面包含任意一位数据
keys v?? #查看当前数据库中以v开头后面包含任意二位数据
exists teacher #判断teacher键是否存在
1 #teacher值存在
redis-cli -h 127.0.0.1
set ky29 taotao

get ky29
keys *

keys k*

keys k?

exists ky29 判定键值是否存在

type k2 判定字符类型

keys *
rename v5 v2

get v1
get v2
rename v1 v2

get v1

exists v1
exists v2

dbsize 查key个数
config set requirepass 123456 设置密码

auth 123456
config get requirepass 查看密码

redis默认情况下包含16个数据库(库之间独立)
select 5 切换库

flushdb
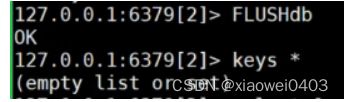
flushall 清空所有数据库的数据